

Библиотеки
COM-объекты помещаются в библиотеки. Чаще всего это файл с расширением DLL, но иногда библиотеки помещаются в EXE- или OCX-модули. Расширение OCX всего лишь говорит о том, что в библиотеке находится элементы управления ActiveX, по существу это тоже DLL. EXE-формат (исполняемый файл) используется в двух случаях: 1) когда надо создать отдельный COM-сервер, не требующий при своей работе наличия MTS или COM+, 2) когда создается настольное Windows-приложение, которое должно поддерживать Automation (выставлять некоторую объектную модель, доступную из других приложений).
Так вот, кроме того, что библиотека должна быть помещена в какой-нибудь исполняемый файл, она еще должна быть специальным образом описана и зарегистрирована на компьютере, где ее предполагается использовать.
В теле библиотеки содержится описание входящих в нее объектов. На основании такого описания MIDL генерирует библиотеку типов. Как и другие объекты в COM, библиотеки должны иметь свой уникальный идентификатор (GUID). В применении к библиотеке он называется LibID. В случае DLL библиотека типов прилинковывается к DLL, а в случае с EXE обычно поставляется отдельно в файле с расширением TLB или OLB. Как бы там ни было, библиотека типов регистрируется в системе, и с ее помощью можно получать информацию о любом элементе библиотеки. С помощью библиотеки типов можно даже сгенерировать MIDL-описание для всех элементов библиотеки. В поставку MS Visual Studio входит утилита «OLE View», позволяющая просматривать библиотеки типов и получать MIDL-описание.
6
Модель сервера бд.
Применительно к этой модели исп-ся так наз-ый механизм процедур. ХП программируются либо на языке SQL либо на языке процедурного расширения непроцедурного языка SQL. Эти процедуры являются разделяемыми между приложениями клиентов, хранятся и выполняются на сервере БД. Т.о., а отличие от SQL-сервера, для данной модели характерным является не передача SQL-запроса, а передача вызова ХП.
После вызова процедуры осуществляется обращение к командам на языке SQL. Осущ-ся обработка данных по заданному бизнес-правилу, и обработанные данные передаются клиенту.
Т.е. преимущества данной модели состоят:
1) в уменьшении сетевого трафика.
2) создании заранее запрограммированных разделяемых процедур обработки, которые м.б. использованы всеми клиентами сети.
3) возможность использ централизованного администрирования прикладного обеспечения.
Процедура является разделяемой, она может использоваться одновременно, т.к. написание процедур сложно, то этим занимается администратор БД, а не клиенты.
Централизованное администрирование приложений.
Настройка приложений осуществляется централизованно – рассылка настроек с сервера на все клиенты.
8
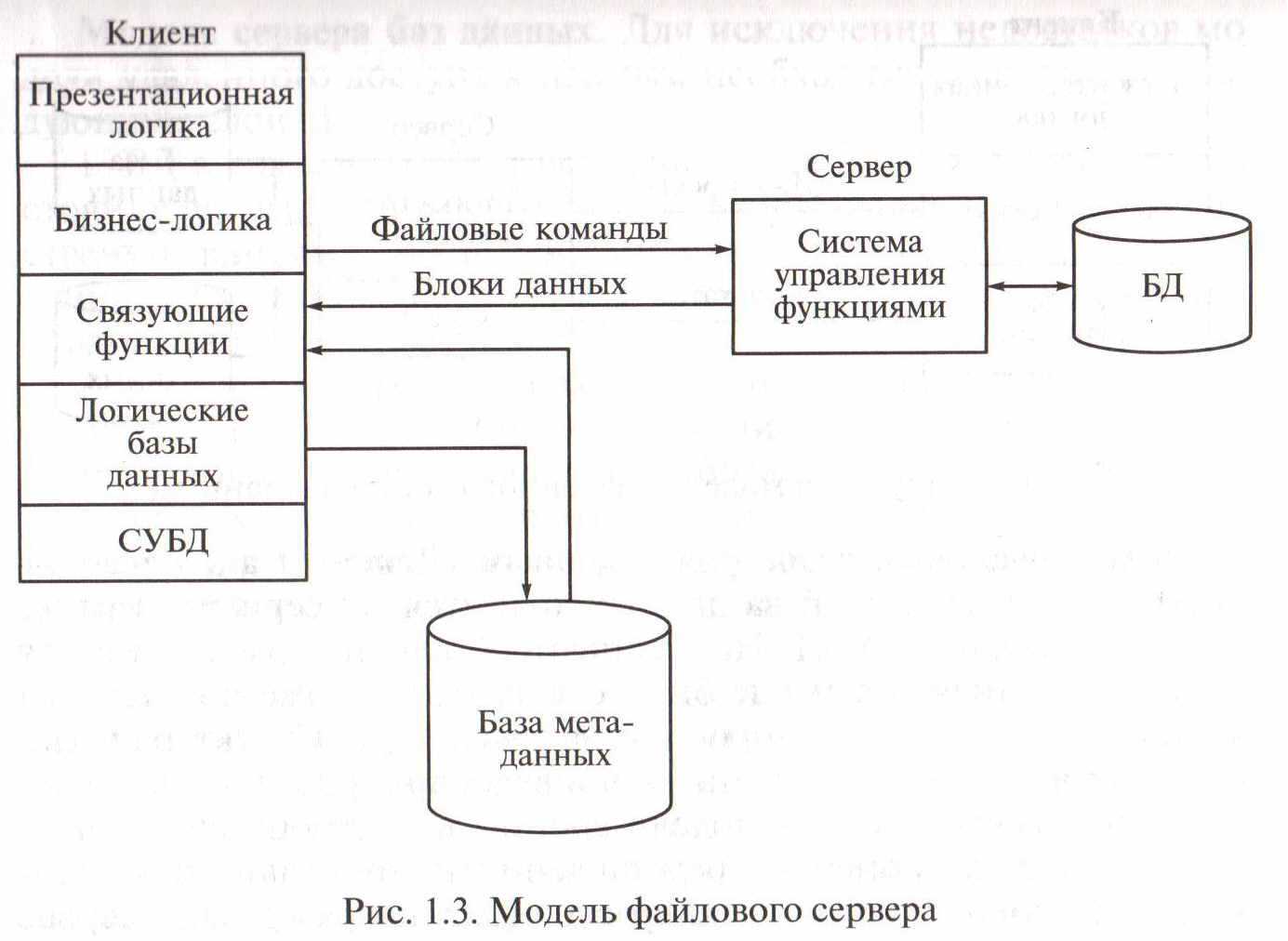
Модель удаленного упр-я данными, или модель файлового сервера (FS). В этой модели презентационная логика и бизнес-логика располагаются на клиентской части. На сервере располагаются файлы с данными и поддерживается доступ к этим файлам. Ф-ии упр-я инфо-ми ресурсами в этой модели находятся на клиентской части.
В этой модели файлы БД хранятся на сервере, клиент обращается к серверу с файловыми командами, а механизм упр-я всеми инфо-ми ресурсами - собственно база метаданных (выбранных данных) - находится на комп клиента.
Достоинство данной модели состоит в том, что приложение разделено на два взаимодействующих процесса. При этом сервер(серверный процесс) может обслуживать множество клиентов, к-ые обращаются к нему с запросами. Собственно СУБД должна находиться в этой модели на компьютере клиента.
Алгоритм выполнения клиентского запроса сводится к следующему.
1. Запрос формулируется в командах языка манипулирования данными (ЯМД).
2. СУБД переводит этот запрос в последовательность файловых команд.
3. Каждая файловая команда вызывает перекачку блока инфо на комп клиента, а СУБД анализирует полученную инфо, и если в полученном блоке не содержится ответ на запрос, принимается реш-е о перекачке след блока инфо и Т.д.
4. Перекачка инфо с сервера на клиентский комп производится до тех пор, пока не будет получен ответ на запрос клиента.
недостатки:
. высокий сетевой трафик, кот-й связан с передачей по сети множества блоков и файлов, необходимых приложению;
. узкий спектр операций манипулирования с данными, опр-ый только файловыми командами;
. отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы).
Р
9
аспределенные БД реализуются в локал или глобал КС. При этом части одной логической БД располагаются в разных узлах сети, возможно на разнотипных комп с различными ОС. Даже данные одной таблицы реляционной СУБД могут физически храниться в разных узлах сети, размещенных, например, в разных городах страны. Причем пользователи любого узла такой распределенной СУБД имеют доступ к данным всех остальных узлов.Такое распределение данных позволяет, например, хранить в узле сети те данные, к-ые наиб часто исп-ся в этом узле. Такой подход облегчает и ускоряет работу с этими данными и оставляет возможность работать с остальными данными БД, хотя для доступа к ним требуется потратить нек-ое время на передачу данных по сети.
Основной особенностью распределенной базы данных является ее "прозрачность" для пользователей и разработчиков приложений. Т.е. пользователи и разработчики представляют распределенную БД в виде нек-ой единой логической локал БД, не задумываясь о физическом расположении ее компонент. Все приложения создаются так, как будто бы они работают с этой единой логической локал БД. Отладка приложений также может выполняться на локал БД.
Перенесение частей этой локал БД в различные узлы сети может выполняться в более позднее время администратором БД и оно не влечет за собой изменения приложений. Более того, пользователи и разработчики приложений могут даже не знать о том, где теперь физически размещены данные, с к-ми они работают. Поиск и пересылку удаленных данных автоматически выполняют программные средства СУБД.
Конечно для того, чтобы реализовать такой простой для конечного пользователя и разработчика механизм представления распределенной БД, необходимо решить множество проблем. Наиболее очевидные из них связаны с обеспечением целостности и непротиворечивости данных распределенной БД, реализацией механизма поддержки "прозрачности" распределенной БД, реализацией единого механизма работы с частями БД, находящимися в СУБД различного типа и расположенными на разнотипных комп с различными ОС, обеспечением приемлемого быстродействия прикладной системы и т.д.
Распределенная СУБД обеспечивает пользователям доступ к инфо независимо от того, какое оборудование и какое прикладное ПО исп-ся в узлах сети. Пользователи при этом не обязаны знать, где физически размещаются данные и как надо выполнять физический доступ к ним. Распределенная СУБД позволяет выполнять горизонтальное и вертикальное "расщепление" таблиц и помещать данные одной таблицы в различных узлах сети. Запросы к данным распределенной БД формулируются так, как будто база данных локальна. При обработке транзакций и выполнении операций копирования/восстановления распределенной БД обеспечивается целостность всей БД.
Протоколы управления БД, например протокол двухфазной фиксации изменений, реализуют механизмы блокировки, обеспечивающие непротиворечивость данных. Средства глобальной оптимизации запросов автоматически выбирают наилучший способ выполнения в локальной или глобальной сети сложных транзакций, а специальные мониторы позволяют получать инфор о параметрах выполняющихся в разных узлах процессов и на основе этой инфо выполнять настройку системы с целью обеспечения максимальной производительности работы.
13
Храни́мая процеду́ра — объект БД, представляющий собой набор SQL-инструкций, к-ый компилируется один раз и хранится на сервере. ХП очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры и локальные переменные, в них могут производиться числовые вычисления и операции над символьными данными, результаты к-ых могут присваиваться переменным и параметрам. В ХП могут выполняться стандартные операции с БД (как DDL, так и DML). Кроме того, в ХП возможны циклы и ветвления, то есть в них могут использоваться инструкции упр-я процессом исполнения.
Сохраняемые процедуры похожи на опр-ые пользователем ф-ии (UDF). Основное различие заключается в том, что пользовательские ф-ии можно использовать как и любое др выражение в SQL запросе, в то время как сохраняемые процедуры должны быть вызваны с помощью функции CALL:
CALL процедура(…)
или
EXECUTE процедура(…)
Сохраняемые процедуры могут возвращать множества рез-в, то есть рез-ты запроса SELECT. Такие множества рез-в могут обрабатываться, используя курсоры, другими сохраненными процедурами, возвращая указатель результирующего множества, либо же приложениями. Сохраняемые процедуры могут также содержать объявленные переменные для обработки данных и курсоров, к-ые позволяют организовать цикл по нескольким строкам в таблице. Стандарт SQL предоставляет для работы выражения IF, LOOP, REPEAT, CASE и многие др. Сохраняемые процедуры могут принимать переменные, возвращать результаты или изменять переменные и возвращать их, в зависимости от того, где переменная объявлена.
15
Агрегатные функции MySQL
Ф-ии, применяемые совместно с конструкцией GROUP BY, часто называют агрегатными или суммирующими функциями. Они предназначены для вычисления одного значения для каждой группы, создаваемой конструкцией GROUP BY. Агрегатные функции позволяют опр-ть кол-во строк, входящих в группу, подсчитать ср зн-е или получить сумму зн-ий столбцов. Результирующее зн-е рассчитывается только для зн-ий, не равных NULL(исключение составляет лишь функция COUNT(*), к-ая подсчитывает общее кол-во строк). Данные ф-ии допустимо использовать и в запросах без группировки: в этом случае вся выборка выступает как одна большая группа.
Запросы могут производить обобщенное групповое зн-е полей точно также как и зн-е одного пол. Это делает с помощью агрегатных ф-ий. Агрегатные ф-ии производят одиночное зн-е для всей группы таблицы. Имеется список этих ф-ий:
* COUNT - производит номера строк или не-NULL значения полей которые выбрал запрос.
* SUM - производит арифметическую сумму всех выбранных значений данного пол.
* AVG - производит усреднение всех выбранных значений данного пол.
* MAX - производит наибольшее из всех выбранных значений данного пол.
* MIN - производит наименьшее из всех выбранных значений данного пол.
Пр. вывести студ с мах таб№
Select max(tabnom) from student
Подсчитать кол-во студ в гр
Select count(nomstud) nam grup from students,grup where students.nomgrup=grup.nomgrup drop be nomgrup
17
Наборы данных представляют собой объекты, содержащие таблицы данных, в которых можно временно хранить данные для их использования в приложении. Если ваше приложение требует работы с данными, можно загрузить их в набор данных. Данные для работы приложения в этом случае будут храниться в локальной памяти. Можно работать с данными в наборе данных, даже если приложение отключается от базы данных. Набор данных хранит информацию об изменениях своих данных. Так что обновления можно отслеживать и отправлять обратно в базу данных, когда ваше приложение вновь подключится к ней.
Заполнение набора данных
По умолчанию набор данных не содержит данных. Заполнение набора данных фактически означает загрузку данных в отдельные объектыDataTable, составляющие набор данных. Таблицы данных заполняются путем выполнения запросов адаптера таблиц или выполнением команд адаптера данных (например SqlDataAdapter). При заполнении набора данных возникают различные события, проверяются ограничения, и т. д. Дополнительные сведения о загрузке данных в набор данных содержатся в разделе Выборка данных в приложение.
Сохранение данных из набора данных обратно в БД
При внесении изменений в записи набора данных эти изменения должны быть записаны в базу данных. Для записи изменений из набора данных в базу данных необходимо вызвать метод Update адаптера таблицы или адаптера данныхDataAdapter, который выполняет обмен данными между набором данных и соответствующей базой данных.
Навигация по записям в наборах данных
Так как наборы данных представляют собой полностью отсоединенные от базы данных контейнеры данных, то они (в отличие от наборов записей ADO) не поддерживают понятие текущей записи. Вместо этого доступны все записи в наборе DataSet в любой момент.
Так как не существует текущей записи, то не существует и специального свойства, которое бы указывало на текущую запись, а также методов и свойств для перемещения от одной записи к другой (см. замечание ниже). Можно осуществлять доступ к отдельным таблицам из набора данных как к объектам; каждая таблица представляет собой коллекцию строк. С ней можно работать как с любой другой коллекцией, т. е. обращаться к строкам с помощью индексов коллекции или операторов, определенных для коллекций в используемом языке программирования.
18
Назначение и преимущества хранимых процедур[3]
Хранимые процедуры позволяют повысить производительность, расширяют возможности программирования и поддерживают функции безопасности данных.
Вместо хранения часто используемого запроса, клиенты могут ссылаться на соответствующую хранимую процедуру. При вызове хранимой процедуры её содержимое сразу же обрабатывается сервером.
Кроме собственно выполнения запроса, хранимые процедуры позволяют также производить вычисления и манипуляцию данными — изменение, удаление, выполнять DDL-операторы (не во всех СУБД!) и вызывать другие хранимые процедуры, выполнять сложную транзакционную логику. Один-единственный оператор позволяет вызвать сложный сценарий, который содержится в хранимой процедуре, что позволяет избежать пересылки через сеть сотен команд и, в особенности, необходимости передачи больших объёмов данных с клиента на сервер.
В большинстве СУБД при первом запуске хранимой процедуры она компилируется (выполняется синтаксический анализ и генерируется план доступа к данным). В дальнейшем её обработка осуществляется быстрее. В СУБД Oracle выполняется интерпретация хранимого процедурного кода, сохраняемого в словаре данных. Начиная с версии Oracle 10g поддерживается так называемая естественная компиляция (native compilation) хранимого процедурного кода в Си и затем в машинный код целевой машины, после чего при вызове хранимой процедуры происходит прямое выполнение её скомпилированного объектного кода.