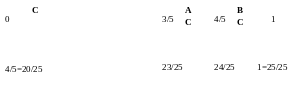Арифметическое кодирование
Принципиальное отличие арифметического кодирования от рассмотренных ранее методов в его непрерывности, т.е. в ненужности блокирования.
Код здесь строится не для отдельных значений д.с.в. или их групп фиксированного размера, а для всего предшествующего сообщения в целом.
Эффективность арифметического кодирования растет с ростом длины сжимаемого сообщения (для кодирования Хаффмена или Шеннона-Фэно этого не происходит).
Хотя арифметическое кодирование дает обычно лучшее сжатие, чем кодирование Хаффмена, оно пока используется на практике сравнительно редко, т.к. оно появилось гораздо позже (разработанно в 70-х годах XX века) и требует больших вычислительных ресурсов.
При сжатии заданных данных, например, из файла все рассмотренные методы требуют двух проходов. Первый для сбора частот символов, используемых как приближенные значения вероятностей символов, и второй для собственно сжатия.
Используя метод арифметического кодирования можно достичь почти оптимального представления для заданного набора символов и их вероятностей.
Алгоритм кодирования заключается:
в построении отрезка, однозначно определяющего данную последовательность значений д.с.в.;
затем для построенного отрезка находится число, принадлежащее его внутренней части и равное целому числу, деленному на минимально возможную положительную целую степень двойки;
это число и будет кодом для рассматриваемой последовательности.
Пример 1: Имеется алфавит состоящий из трех символов – А, В, С и их вероятностей -рА=1/5, рВ=1/5, рС=3/5. Нам необходимо зашифровать сообщение «ВАС»
0 шаг: Упорядочиваем алфавит в порядке убывания вероятностей символов, т.к. символу с большей вероятностью нужен более короткий код. (ЭТОТ ШАГ для удобства)
-
С
А
В
3/5
1/5
1/5
1 шаг: Располагаем на интервале [0,1] граничные точки отрезков пропорциональные вероятностям соответствующих символов алфавита.
2 шаг: Первый символ в кодируемом сообщении это символ «В», поэтому располагаем на интервале [4/5,1] граничные точки отрезков пропорциональные вероятностям соответствующих символов алфавита.
Пересчитываем значения граничных точек символов алфавита на новом интервале [4/5,1].
Правая граница символа «С» 4/5+(3/5*1/5)=23/25
а теперь словами озвучим эту формулу – к началу нового интервала (4/5) прибавляем длину пропорционального отрезка «С» (это длина С на предыдущем шаге умноженная на его масштаб).
Левая граница символа «А» 4/5+(3/5*1/5)=23/25,
а теперь словами озвучим эту формулу – к началу нового интервала (4/5) прибавляем длину пропорционального отрезка «А» (это место точки А на предыдущем шаге умноженное на его размер = вероятность).
Левой граница символа «В»= правой границе символа «А» = 23/25+(1/5*1/5)=24/25.
т.е. к началу нового интервала (23/25) прибавляем длину пропорционального отрезка «В» (это длина В на предыдущем шаге умноженная на его масштаб, вер-ть),
либо это = 4/5+(4/5*1/5)=24/25
к началу (4/5) прибавляем длину пропорционального отрезка до «В» (это место точки В на предыдущем шаге умноженное на его размер = вероятность).