

Адаптивный алгоритм Хафмана
Является практичным, однопроходным, не требующим передачи таблицы кодов.
Его суть в использовании адаптивного алгоритма,
т.е. алгоритма, который при каждом сопоставлении символу кода, кроме того,
изменяет внутренний ход вычислений так, что в следующий раз этому же символу может быть сопоставлен другой код,
т.е. происходит адаптация алгоритма к поступающим для кодирования символам/.
При декодировании происходит аналогичный процесс.
Алгоритм кодирования:
в начале работы алгоритма дерево кодирования содержит только один специальный символ, всегда имеющий частоту 0 - <ESC>;
каждый символ кодируют 8-битным числом, т.е. числом от 0 до 255 (Расширенный ASCII код);
как при кодировании, так и при декодировании необходимо как-то упорядочивать структуру дерева, по этому:
требуется располагать листья дерева в порядке возрастания частот;
и затем в порядке возрастания стандартных кодов символов;
узлы собираются слева направо без пропусков;
левые ветви помечаются 0, а правые – 1.
Пример 4: Рассмотрим процесс построения кодов по адаптивному алгоритму Хаффмена для сообщения ACCBCAAABC, которое соответствует выборке 10-и значений д.с.в. Х, которая может принимать три значения: А, В, С с заданными вероятностями рА=0,4 , рВ=0,4 , рС=0,4.
входные данные |
код |
длина кода |
номер дерева |
метод получения |
|
|
|
А |
‘A’ |
8 |
1 |
добавление узла |
|
|
|
С |
0‘C’ |
9 |
2 |
добавление узла |
|
|
|
С |
1 |
1 |
3 |
упорядочивание |
|
|
|
В |
00‘B’ |
10 |
4 |
добавление узла |
Код <esc> =00 |
|
|
С |
1 |
1 |
5 |
не меняется |
|
|
|
А |
001 |
3 |
6 |
не меняется |
|
|
|
А |
01 |
2 |
7 |
упорядочивание |
|
|
|
А |
01 |
2 |
8 |
упорядочивание |
|
|
|
В |
001 |
3 |
9 |
не меняется |
|
|
|
С |
01 |
2 |
|
|
|
|
|
длина кода сообщ. |
41 |
|
|
|
|
||
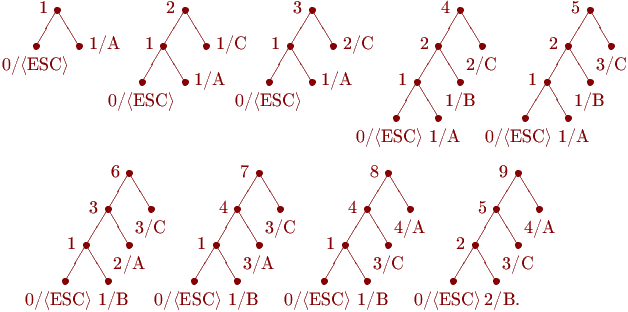
Для 4 дерева символ «В» сначала рисуется над «С», затем это дерево перерисовывается таким образом, чтобы символы, встречающиеся чаще, располагались выше в строящемся дереве.
Аналогично для 6 дерева после поступления символа «В» часть дерева перерисовывается
Если бы в алфавите было 4 символа, то при его поступлении код <esc> =000 и т.д.
Здесь средняя длина кодируемого сообщения L1(ACCBCAAABC)=4.1 бит/сим.
Если не использовать алгоритм сжатия, то пришлось бы каждый раз передавать весь код каждого из символов и средняя кодируемого сообщения L1(ACCBCAAABC)=8 бит/сим.
Пример 5: Теперь рассмотрим процесс декодирования сообщения 'A'0'C'100'B'1001010100101.
Здесь и далее символ в апострофах означает восемь бит, представляющих собой запись двоичного числа, номера символа, в таблице ASCII+.
В начале декодирования дерево Хаффмена содержит только escape-символ с частотой 0.
С раскодированием каждого нового символа дерево заново перестраивается.
входные данные |
символ |
теперь его код |
длина кода |
номер дерева |
метод получения |
‘A’ |
А |
A1ESC0 |
8 |
1 |
добавление узла |
0‘C’ |
С |
1 |
9 |
2 |
добавление узла |
1 |
С |
A01C1 ESC00 |
1 |
3 |
упорядочивание |
00‘B’ |
В |
A001B01C1 ESC000 |
10 |
4 |
добавление узла |
1 |
С |
A001B01C1 ESC000 |
1 |
5 |
не меняется |
001 |
А |
A01B001C1 ESC000 |
3 |
6 |
не меняется |
01 |
А |
A01B001C1 ESC000 |
2 |
7 |
упорядочивание |
01 |
А |
A1B001C01 ESC000 |
2 |
8 |
упорядочивание |
001 |
В |
A1B001C01 ESC000 |
3 |
9 |
не меняется |
01 |
С |
A1B001C01 ESC000 |
2 |
|
|