

Сортировка методом прямого обмена
В основе алгоритма лежит обмен соседних элементов массива. Каждый элемент массива, начиная с первого, сравнивается со следующим и если он больше следующего, то элементы меняются местами. Таким образом, элементы с меньшим значением продвигаются к началу массива (всплывают), а элементы с большим значением к концу массива (тонут), поэтому этот метод иногда называют “пузырьковым”. Этот процесс повторяется на единицу меньше раз, чем элементов в массиве.
На рис. 17 показан пример сортировки массива. Буквой (“а”) обозначено исходное состояние массива и перестановки на первом проходе, буквой (“б”) состояние после перестановок на первом проходе и перестановки на втором проходе и так далее.
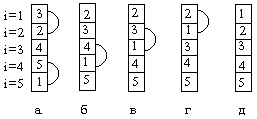
Рис.17. Процесс сортировки массива.
Ниже представлена программа сортировки массива целых чисел по возрастанию. Для демонстрации процесса сортировки программа выводит массив после каждого цикла обменов.
CONST
size = 5 ;
VAR
A : Array[1..5] of Integer ;
i : Integer ; { счетчик циклов}
k : Integer ; { текущий индекс элемента массива ]
buf : Integer ;
BEGIN
WriteLn( ‘ Сортировка массива пузырьковым методом’) ;
Write(‘ Введите’,size:3,’ целых в одной строке через пробел ‘) ;
For k := 1 to size do read(A[k]);
writeln(‘ Сортировка ‘) ;
for i := 1 to size-1 do begin
for k := 1 to size-1
do begin
if A[k] > A[k+1]
then begin
{обменяем k-ый и (k+1)-ый элементы}
buf := A[k} ;
A[k] := A[k+1] ;
A[k+1] := buf ;
end ;
end ;
for k := 1 to size do write(A[k],’ ‘) ;
writeln ;
end ;
writeln(‘ Массив отсортирован ‘) ;
END.
Поиск в массиве
При решении многих задач возникает необходимость, содержит ли массив определенную информацию. Задачи такого типа называются поиском в массиве.
Для организации поиска в массиве могут быть использованы различные алгоритмы. Наиболее простой это алгоритм простого перебора. Поиск осуществляется последовательным сравнением элементов массива с образцом до тех пор, пока не будет найден элемент, равный образцу, или не будут проверены все элементы. Алгоритм простого перебора применяется, если элементы массива не упорядочены.
Ниже приведен текст программы поиска в массиве целых чисел. Перебор элементов массива осуществляет инструкция REPEAT, в теле которой инструкция IF сравнивает текущий элемент массива с образцом и присваивает переменной naiden значение TRUE, если текущий элемент равен образцу. Цикл завершается, если в массиве обнаружен элемент, равный образцу (naiden=TRUE), или если проверены все элементы массива. По завершении цикла, по значению переменной found можно определить, успешен поиск или нет.
VAR
massiv : array[1..10] of integer ; { массив целых }
obrazec : integer ; { образец для поиска }
naiden : boolean ; { признак совпадения с образцом }
i : integer ;
BEGIN
writeln(‘Введите 10 целых чисел в одной строке через пробел’) ;
for i := 1 to 10 do read(massiv[i]) ;
writeln(‘Введите образец для поиска (целое число)’) ;
readln(obrazec) ;
{ поиск простым перебором }
naiden := FALSE ; { совпадений нет }
i := 1 ; { проверяем с первого элемента массива }
repeat
if massiv[i] = obrazec
then naiden := TRUE { совпадение с образцом }
else i := i + 1 ; { переход к следующему элементу }
until ( i > 10 ) or (naiden) ; { завершим, если совпадение с образцом или }
{ проверен последний элемент массива }
if naiden
then writeln(‘Совпадение с элементом номер’, i:3,‘.’, ‘ Поиск успешен.’}
else writeln (‘Совпадений с образцом нет.’) ;
END.
Очевидно, что чем больше элементов в массиве и чем дальше расположен нужный элемент от начала массива, тем дольше будет программа искать нужный элемент.
Так как операции сравнения применимы как к числам, так и к строкам, то данный алгоритм может использоваться для поиска как в числовых, так и в строковых массивах.
На практике довольно часто проводится поиск в массиве, элементы которого упорядочены по некоторому критерию. Например, массив фамилий, как правило, упорядочен по алфавиту, массив данных о погоде упорядочен по датам наблюдений.
Для поиска в упорядоченных массивах применяют другие, более эффективные по сравнению с методом простого перебора, алгоритмы, один из которых- метод бинарного поиска.
Суть метода бинарного поиска заключается в следующем. Выбирается средний элемент упорядоченного по возрастанию массива (элемент с номером sred), с которым сравнивается образец (рис. 18).
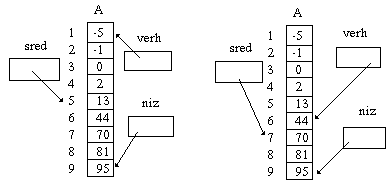
Рис.18. Выбор среднего элемента массива при бинарном поиске.
Если средний элемент равен образцу, то задача решена.
Если средний элемент меньше образца, то искомый элемент расположен выше среднего элемента (между элементами с номерами verh и sred).
Если средний элемент больше образца, то искомый элемент расположен ниже среднего (между элементами с номерами sred и niz).
После того, как определена часть массива, в которой может располагаться искомый элемент, поиск проводят в этой части, выделяя новый средний элемент. Номер среднего элемента вычисляется по формуле (niz-verh)/2+verh. Блок-схема алгоритма бинарного поиска в массиве представлена на рис. 19.
Ниже представлен текст программы бинарного поиска в массиве. В программу добавлены операторы вывода значений переменных verh, niz и sred. Выводимая информация полезна для понимания сути алгоритма. Кроме того, переменная n позволяет оценить эффективность этого алгоритма по сравнению с поиском методом простого перебора (для массивов, упорядоченных по возрастанию).
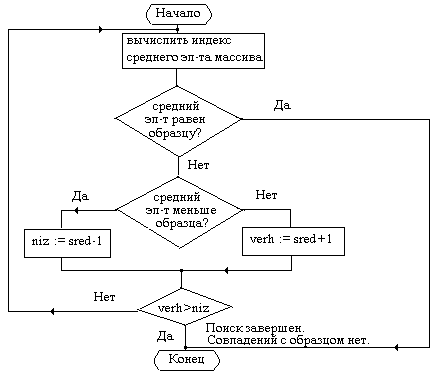
Рис.19. Блок-схема алгоритма бинарного поиска в упорядоченном
по возрастанию массиве.
VAR
A : Array[1..9] of Integer ; { массив целых }
obrazec : Integer ; { образец для поиска }
sred,verh,niz : Integer ;{номера среднего, верхнего и нижнего эл-тов массива}
naiden : Boolean ; { признак совпадения с образцом }
n : Integer ; { счетчик сравнений с образцом }
i : Integer ;
BEGIN
writeln(‘ Введите 9 целых чисел в одной строке через пробел }
for i := 1 to 9 do readln(A[i]) ;
writeln(‘Введите образец для поиска (целое число) ‘) ;
readln(obrazec) ;
verh := 1 ;
niz := 9 ;
naiden := FALSE ;
n := 0 ;
writeln(‘ verh niz sred’) ;
repeat
sred := (niz - verx) div 2 + verh ;
writeln(verh:6,niz:6,sred:6) ;
n := n + 1 ;
if A[sred]=obrazec then naiden := TRUE
else begin
if obrazec<A[sred]
then niz := sred-1
else verh := sred+1 ;
end ;
until (verh>niz) or naiden ;
if naiden
then write(‘Совпадение с элементом номер ‘,sred,’.
Выполнено ‘,n,’ сравнений.’)
else writeln(‘Образец в массиве не найден.’) ;
readln
END.