

Лабораторна робота №4
Апроксимація експериментальних даних
Мета роботи: Вивчення можливостей пакету Excel при розв’язанні завдань обробки експериментальних даних.
Одним з поширених завдань в науці, техніці, економіці є апроксимація експериментальних даних. Апроксимацією називається процес підбору емпіричної формули j(х) для встановленої з експерименту функціональної залежності у= f(х). Емпіричні формули служать для аналітичного представлення дослідних даних. Можливість підібрати параметри рівняння так, щоб його розв’язування співпало з даними експерименту, часто є доказом (чи спростуванням) теорії.
Задача апроксимації складається з двох частин:
встановлення виду залежності у=f(х) і, відповідно, виду емпіричної формули (лінійна, квадратична, логарифмічна тощо);
визначення чисельних значень невідомих параметрів обраної емпіричної формули, для яких наближення до заданої функції виявляється найкращим.
Excel має спеціальний апарат для графічного аналізу моделей, у тому числі побудови апроксимаційних залежностей (ліній тренда P (x)) з даної таблиці {xi, yi}, які наближено відображають функціональний зв'язок y = f (x).
Лінії тренда зазвичай використовуються в задачах прогнозування. Такі завдання вирішують за допомогою методів регресійного аналізу, за допомогою якого можна показати тенденцію зміни рядів даних, екстраполювати їх (тобто продовжити лінію тренда вперед або назад за межі відомих даних). Можна також побудувати лінію змінного середнього, яка згладжує випадкові флуктуації, ясніше демонструє модель і простежує тенденцію зміни даних.
Лініями тренду можна доповнити ряди даних, представлені на лінійчатих діаграмах, гістограмах, графіках, біржових, точкових і бульбашкових діаграмах. Не можна доповнити лініями тренда ряди даних на об'ємних, пелюсткових, кругових і кільцевих діаграмах.
Excel дозволяє вибрати один з п'яти типів лінії тренда – лінійний, логарифмічний, експонентний, степеневий або поліноміальний (2...6 ступеня) і перевірити (за різними критеріями), який з типів найкраще підходить в даній ситуації.
Степінь наближення апроксимації експериментальних даних вибраною функцією можна оцінити за величиною коефіцієнта детермінації R2, автоматичне обчислення якого вбудовано в діалогове вікно линия тренда. При кількох придатних варіантах типів апроксимуючої функції, вибирається функція з більшим коефіцієнтом детермінації (ближчим до 1).
Критерієм
може служити і квадратичне відхилення
![]() ,
яке зазвичай використовується в методі
найменших квадратів при апроксимації
табличних функцій.
Чим менше значення
квадратичного відхилення
порівняно з іншими функціями, серед
яких вибирають шукане наближення,
тим краще лінія тренда апроксимує ряд
даних.
,
яке зазвичай використовується в методі
найменших квадратів при апроксимації
табличних функцій.
Чим менше значення
квадратичного відхилення
порівняно з іншими функціями, серед
яких вибирають шукане наближення,
тим краще лінія тренда апроксимує ряд
даних.
апроксимація даних. Розглянемо наступне математичне завдання з апроксимації експериментальних даних. Відомі значення деякої функції f(х):
x |
x1 |
x2 |
… |
xn |
f(x) |
y1 |
y2 |
… |
yn |
Необхідно побудувати аналітичну залежність y = f(x), що найбільш точно описує результати експерименту. Побудуємо функцію y = f(x, a0, a1, ..., ak) так, щоб сума квадратів відхилень виміряних значень yi від розрахункових f(xi, a0, a1, ..., ak) була найменшою (рис. 1).

Рисунок 1
Математично це завдання рівносильне наступним: знайти значення параметрів a0, a1, a2, ...,ak, при яких функція набувала б мінімального значення.
![]()
Це завдання зводиться до розв’язання системи рівнянь:
![]()
Якщо параметри ai входять в залежність y = f(x, ao, a1, ., ak) лінійно, то ми отримаємо систему лінійних рівнянь:
![]()
розв’язавши систему, знайдемо параметри ao, a1, ..., ak і отримаємо залежність y = f(x, ao, a1, ..., ak).
Лінійна функція (лінія регресії)
Необхідно визначити параметри функції y = ax+b. Для цього складемо функцію S:
![]()
Диференціюємо вираз по a і b, сформуємо систему лінійних рівнянь, розв’язавши яку отримаємо наступні значення параметрів:
![]()
Підібрана пряма називається лінією регресії y на x, a і b – коефіцієнтами регресії. Чим менше величина
![]()
тим більш обґрунтовано припущення, що таблична залежність описується лінійною функцією.
Існує показник, що характеризує тісноту лінійного зв'язку між x та y. Це коефіцієнт кореляції. Він розраховується за формулою:
![]()
Коефіцієнт кореляції r та коефіцієнт регресії a пов'язані співвідношенням:
![]()
де Dy, Dx – середньоквадратичне відхилення значень x та y.
Значення коефіцієнта кореляції задовольняє співвідношенню -1≤ r ≤1. Чим менше відрізняється абсолютна величина r від одиниці, тим ближче до лінії регресії розташовуються експериментальні точки. Якщо коефіцієнт кореляції дорівнює нулю, то змінні x і y називаються некорельованими. Якщо r = 0, то це означає лише те, що між x і y не існує лінійному зв'язку, але між ними може існувати залежність, відмінна від лінійної.
Для того, щоб перевірити, чи значимо відрізняється від нуля коефіцієнт кореляції, можна використати критерій Стьюдента, який розраховується за формулою:
![]()
Значення t порівнюється із значенням, узятим із таблиці розподілу Стьюдента відповідно до рівня значущості a та числом ступенів свободи n-2. Якщо t більше за табличний, то коефіцієнт кореляції значимо відмінний від нуля.
Обчислення коефіцієнтів регресії здійснюється за допомогою функції ЛИНЕЙН(): ЛИНЕЙН(Значения_y; Значения_x; Конст; статистика).
Значения _y – масив значень y.
Значения _x – необов'язковий масив значень x, якщо масив х опущений, то припускається, що це масив {1;2;3;...} такого ж розміру, як і Значения_y.
Конст – логічне значення, яке вказує, чи потрібно, щоб константа b дорівнювала 0. Якщо Конст має значення ИСТИНА або опущене, то b обчислюється звичайним способом. Якщо аргумент Конст має значення ЛОЖЬ, то b приймається рівним 0 і значення a підбираються так, щоб виконувалося співвідношення y = ax.
Статистика – логічне значення, яке указує, чи треба повернути додаткову статистику по регресії. Якщо аргумент статистика має значення ИСТИНА, то функція ЛИНЕЙН повертає додаткову регресійну статистику. Якщо аргумент статистика має значення ЛОЖЬ або опущений, то функція ЛИНЕЙН повертає тільки коефіцієнт a і постійну b.
Для обчислення безлічі точок на лінії регресії використовується функція ТЕНДЕНЦиЯ: ТЕНДЕНЦиЯ(Значения_y; Значения_x; Новые_значения_x; Конст).
Значения_y – масив значень y, які вже відомі для співвідношення y = ax + b.
Значения_x – масив значень x.
Новые_значения_x – новий масив значень, для яких ТЕНДЕНЦИЯ повертає відповідні значення y. Якщо Новые_значения_x опущені, то припускається, що вони співпадають з масивом значень х.
Конст – логічне значення, яке вказує, чи потрібно, щоб константа b дорівнювала 0. Якщо Конст має значення ИСТИНА або опущене, то b обчислюється звичайним способом. Якщо Конст має значення ЛОЖЬ, то b приймається рівним 0, і значення а підбираються так, щоб виконувалося співвідношення y = ax.
Необхідно пам'ятати, що результатом функцій ЛИНЕЙН, ТЕНДЕНЦИЯ являється безліч значень – масив.
Для розрахунку коефіцієнта кореляції використовується функція КОРРЕЛ, що повертає значення коефіцієнта кореляції: КОРРЕЛ (Массив 1;Массив 2).
Массив 1 – масив значень х.
Массив 2 – масив значень y.
Массив 1 і Массив 2 повинні мати однакову кількість точок даних.
Квадратична функція. Необхідно визначити параметри функції y = ao + a1x + a2x2.
Складемо функцію:
![]()
Для цієї функції запишемо систему рівнянь:

Для знаходження параметрів ao, a1, a2 необхідно розв’язати систему лінійних алгебраїчних рівнянь.
Кубічна функція. Необхідно визначити параметри многочлена третього ступеня y = ao + a1 x + a2 x2 + a3 x3. Складемо функцію S:
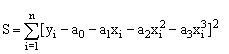
Система рівнянь для знаходження параметрів ao, a1, a2, a3 має вигляд:
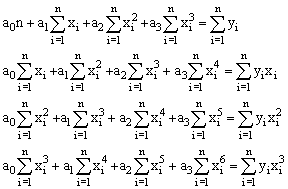
Для знаходження параметрів ao, a1, a2, a3 необхідно розв’язати систему чотирьох лінійних алгебраїчних рівнянь. Якщо в якості аналітичної залежності виберемо многочлен k-ого ступеня y = ao+a1x+...+ak xk, то система рівнянь для визначення параметрів ai набуде вигляду:
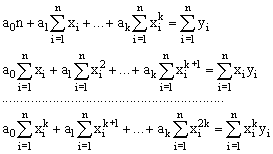
функція y = a xb. Для знаходження параметрів функції y=axb проведемо логарифмування функції y:
lny=lna+blnx
Зробимо заміну Y=lny; X=lnx. Отримаємо лінійну залежність Y=A+bX. Знайдемо коефіцієнти лінії регресії a і b. визначаємо a = eA. Ми визначили значення всіх параметрів функції y=axb.
функція y = aebx. Логарифмуємо вираз y = aebx:
lny=lna+bxlne ;
Проведемо заміну Y=lny; A=lna. Знову отримуємо лінійну залежність Y=bx+A. Знайдемо A і b. Потім визначимо a = eA. Нижче приведені заміни змінних, які перетворюють функції виду y=f(x, a, b) до лінійної залежності Y=Ax+B.
-
Y = f(x,a,b)
Заміна

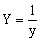
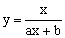
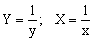

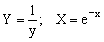
функція y =axbecx. Логарифмуємо вираз y=axbecx:
lny=lna+blnx+cxlne
Зробимо заміну Y=ln(y); A=ln(a). Після заміни вираз набуває вигляду: Y=A+blnx+cx. Для цієї функції складемо функцію S:
![]()
Параметри A, b і c слід вибрати так, щоб функція S була мінімальною. Після елементарних перетворень отримаємо систему трьох лінійних алгебраїчних рівнянь для визначення коефіцієнтів A, b і c:

Розв’язавши систему, отримаємо значення A, b, c. Після чого обчислюємо a=eA.
Кілька незалежних змінних. У тих випадках, коли змінна y залежить від декількох незалежних змінних y = f(x1, x2, ..., xn), підхід з побудовою лінії тренда не дає рішення. Тут можуть бути використані наступні спеціальні функції MS Excel:
ЛИНЕЙН і ТЕНДЕНЦиЯ для апроксимації лінійних функцій виду: y=a0+a1x1+a2x2+…+anxn.
ЛГРФПРИБЛ і РОСТ для апроксимації функцій виду: y = a0a1x1a2x2 ... anxn.
Функції ЛИНЕЙН і ЛГРФПРИБЛ служать для обчислення невідомих коефіцієнтів a0, a1, ..., an, а також коефіцієнтів детермінації (R2), значень Фішера, стандартних похибок коефіцієнтів ai і ряду інших показників. Обидві функції мають однакові параметри: ЛИНЕЙН(известные_значения_y;известные _значения_x;конст;статистика), де
известные_значения_y – безліч значень y;
известные_значения_x - безліч значень x1, x2, ..., xn. Причому, якщо масив известные_значения_y має один стовпець, то кожний стовпець масиву известные_значения_x інтерпретується як окрема змінна, а якщо масив известные_значения_y має один рядок, то тоді кожен рядок масиву известные_значения_x інтерпретується як окрема змінна;
конст - логічне значення, яке вказує, чи потрібно, щоб константа a0 дорівнювала 0 (для функції ЛИНЕЙН) або 1 (для функції ЛГРФПРИБЛ). При цьому, якщо константа має значення ИСТИНА чи опущена, то a0 обчислюється звичайним чином, а якщо константа має значення ЛОЖЬ, то a0 вважається рівним 0 або 1;
статистика - логічне значення, яке вказує, чи потрібно обчислювати додаткову статистику по регресії, якщо введено значення ИСТИНА, то додаткові параметри обчислюються, якщо ЛОЖЬ, то ні.
Функції ТЕНДЕНЦІЯ і РІСТ дозволяють знаходити точки, що лежать на апроксимуючих кривих для значень коефіцієнтів a1, ..., an, знайдених функціями ЛИНЕЙН і ЛГРФПРИБЛ.
Практичне завдання 1. Відомо, що найбільш сильний вплив на бронхіальної-легеневі захворювання надає чадний газ – оксид карбону. За даними статистики щодо середньої концентрації чадного газу в атмосфері і щодо захворюваності астмою (число хронічних хворих на 1000 жителів) були отримані такі дані:
ССО, мг/м3 |
2 |
2,5 |
2,9 |
3,2 |
3,6 |
3,9 |
4,2 |
4,6 |
5 |
Р, хв./тис. осіб |
19 |
20 |
32 |
34 |
51 |
55 |
90 |
108 |
171 |
За допомогою табличного процесора MS Excel знайдіть коефіцієнт кореляції, підберіть аналітичний вид функціональної залежності захворюваності мешканців міста від якості повітря за величиною достовірності апроксимації (R2). Вичисліть очікувані значення числа хронічних хворих на 1000 жителів при середньої концентрації чадного газу в атмосфері 5,5 мг/м3.

Рисунок 2
Введіть таблицю значень в лист Excel. Для розрахунку значення коефіцієнта кореляції в комірку M2 запишіть наступну формулу: = КОРРЕЛ(B1:J1;B2:J2). Величина коефіцієнта кореляції r = 0,911 свідчить про тісний взаємозв'язок між концентрацією оксиду карбону в атмосфері і захворюваністю на астму.
Побудуйте за даними таблиці точковий графік. Робочий лист буде мати вигляд зображений на рис. 2.
Для здійснення апроксимації експериментальних даних в контекстному меню, що з’явиться при клацанні правої кнопки миші на діаграмі, виберіть пункт Добавить линию тренда. У діалоговому вікні Линия тренда на вкладці Тип виберіть апроксимуючу функцію Линейная. На вкладці Параметры (рис. 3) задайте додаткові параметри:
показувати рівняння на діаграмі;
помістити на діаграму величину достовірності апроксимації (R^2).
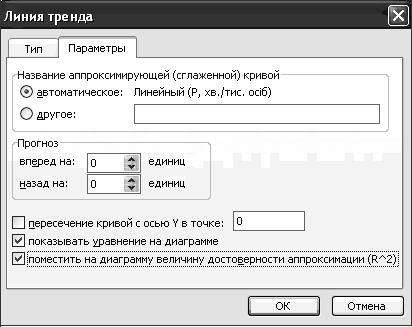
Рисунок 3
Натисніть Ок. В результаті на діаграмі (рис. 4а) з’явиться лінія тренда, аналітичний вид функціональної залежності захворюваності мешканців міста від якості повітря і величина достовірності апроксимації (R2).
Аналогічно підберіть аналітичний вид функціональної залежності і за іншими типами лінії тренда (квадратичної, логарифмічної, експоненціальної тощо). За найбільшою величиною достовірності апроксимації R^2 (ближчим до 1) виберіть аналітичний вид функціональної залежності. Найкраще підходить для опису експериментальних даних експоненціальний вид функціональної залежності(R^2=0,9716). Тому вираз для визначення рівня захворюваності на астму в залежності від якості повітря буде мати вигляд: у=3,4302е0,7555х.
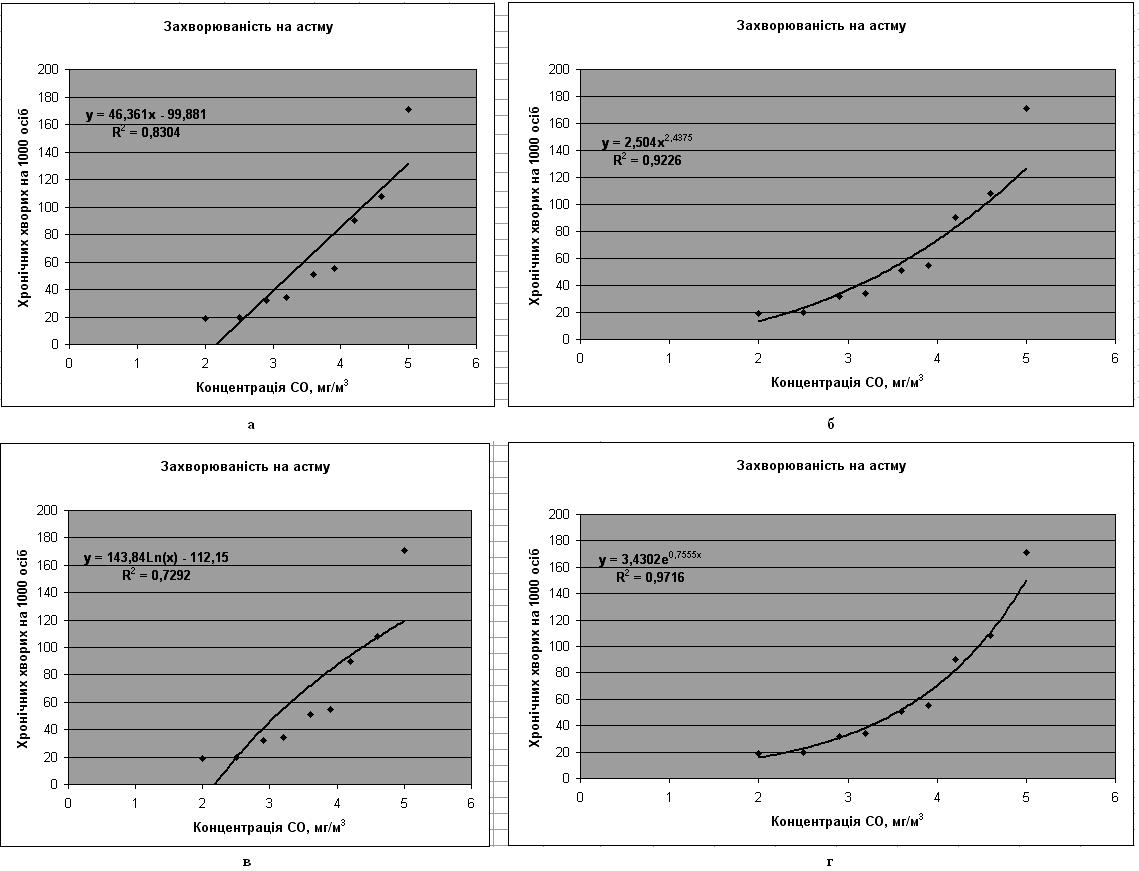
Рисунок 4
Для обчислення очікуваного значення числа хронічних хворих при концентрації чадного газу в атмосфері 5,5 мг/м3 продовжить лінію тренда на вибраній діаграмі.
|
продовження лінії тренду за межі області даних, наведених у вихідній таблиці, називається екстраполяцією. При проведенні екстраполяції не слід занадто далеко віддалятися від області експериментальних даних, оскільки можливість застосування будь регресійної моделі обмежена, особливо, за межами експериментальної області. Наприклад, якщо С = 9 мг/м3, то захворюваність, згідно отриманої залежності, повинна дорівнювати приблизно 1000 хворих. У таких крайніх випадках система знаходиться в не рівноважній, невизначеній ситуації. Точки, поблизу яких різко посилюється хаотичний розвиток системи, називаються точками біфуркації. Модель перестає бути адекватною ситуації. Потрібні нові експериментальні дані і, можливо, нова модель. |
Для здійснення екстраполяції на діаграмі експериментальних даних двічі клацніть на лінії тренда і на вкладці Параметры виберіть додатковий параметр прогноз вперед на 0,5 одиниць (цей параметр визначає, на яку кількість одиниць вперед (назад) необхідно продовжити лінію тренду.
Для форматування лінії тренда (можна змінити товщину лінії, колір, тип маркера тощо) двічі клацніть по ній і в меню, що з’явилося, виберіть потрібний формат.
Практичне завдання 2. В результаті експерименту була виявлена таблична залежність наступного виду:
X |
0,15 |
0,16 |
0,17 |
0,18 |
0,19 |
0,20 |
Y |
4,4817 |
4,4930 |
5,4739 |
6,0496 |
6,6859 |
7,3891 |
Виберіть і побудуйте апроксимуючу залежність квадратичного типу, графіки табличної і підібраної аналітичної залежності. Вичисліть очікувані значення в точках: x1 = 0,12, x2 = 0,25, x3 = 0,28.
Рішення задачі можна розбити на наступні етапи:
Введення вихідних даних і побудова точкового графіку;
Додавання до цього графіку лінії тренду (тип – поліноміальний 2 ступеня).
На рис. 5 зображена отримана діаграма.
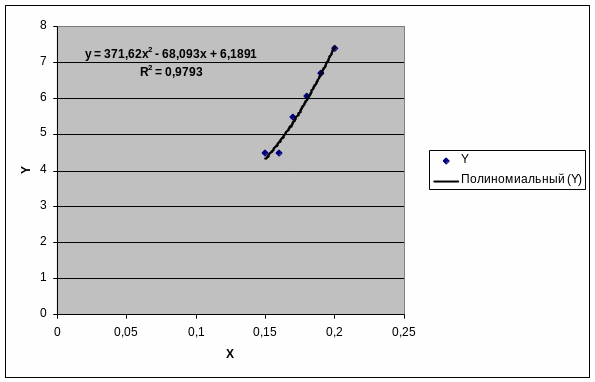
Рисунок 5
Для розрахунку очікуваних значень в точках 0,12, 0,25, 0,28 введіть ці значення в комірки I1:K1. У комірку I2 введіть формулу підібраної апроксимуючої залежності: =371,62*B4^2-68,093*B4+6,1891). Скопіюйте її в комірки J2, K2.
Додайте отримані розрахункові значення на діаграму. Для цього на діаграмі виділіть експериментальні значення, клацніть правою кнопкою миші і виберіть команду Исходные данные. Додайте ряд Розраховані значення (рис. 6). В результаті діаграма прийме вигляд зображений на рис. 7.
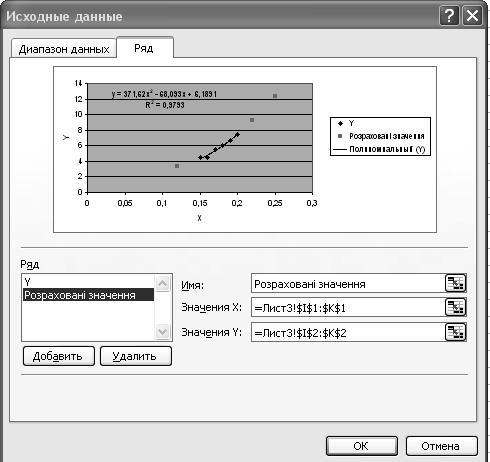
Рисунок 6

Рисунок 7
Практичне завдання 3. В результаті експерименту була виявлена залежність наступного виду:
Середньорічний вміст Нітрогену в річці (тис. тонн): 20.0, 19.2, 16.44, 16.44, 14.0, 18.0, 16.44, 18.05, 18.16, 15.0, 16.80, 14.0, 15.09, 14.75, 15.0, 16.44, 16.0, 15.77, 14.73, 14.27.
середньорічний улов риби (тис. тонн): 39.26, 34.22, 32.30, 35.80, 37.23, 39.0, 35.8, 36.42, 37.23, 37.45, 35.58, 32.80, 37.30, 38.58, 39.26, 38.55, 35.58, 35.58, 35.55, 33.22, 33.22.
За величиною коефіцієнта кореляції з'ясуйте, чи є закономірність між вмістом Нітрогену в річці і уловом риби. підберіть аналітичний вид функціональної залежності за величиною достовірності апроксимації (R2).
Практичне завдання 4. Використовуючи статистичні дані за чисельністю населення (таблиця 3.1), побудувати лінійний графік ЧислСтат (Рік). Виділивши лінію графіку, побудувати різні лінії тренду, що виражають залежність чисельності населення від часу: Вставка – Линия тренда (чи, навівши курсор на лінію графіку, клацнути правою клавішею миші; у контекстно-залежному меню, що з'явилося, вибрати Добавить линию тренда).