

1.4.1. Конвейеризация
Большинство
современных процессоров являются
конвейерными. На рис. 6 [10] приведен
простой пятиступенчатый конвейер для
32-разрядного
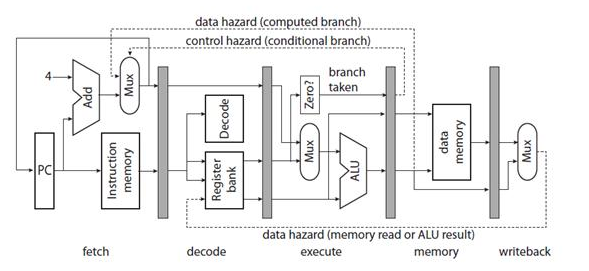
Рис. 6. Простой конвейер
процессора, где:
fetch – ступень выборки команды;
decode – ступень декодирования команды;
execute – ступень выполнения команды;
memory – ступень чтения или записи в память;
writeback – ступень обратной записи;
РС – счетчик команд;
Add –устройство сложения;
Mux – мультиплексор;
Instruction memory – память команды;
Decode – устройство декодирования;
Zero? – устройство определения равенства 0 операнда;
Register bank – банк регистров;
ALU – арифметико-логическое устройство;
Data memory – память данных;
data hazard (memory read or ALU result) - риск сбоя данных при чтении памяти или результата ALU;
data hazard (computed branch) - риск сбоя данных при безусловном переходе;
control hazard (conditional branch) - риск сбоя управления;
branch taken –переход по команде ветвления.
Затененные прямоугольники на рисунке – регистры-защелки, синхронизированные тактовой частотой процессора. По фронту тактового сигнала данные на их входах запоминаются, а выходы остаются неизменными до прихода следующего фронта, что дает возможность схемам, находящимся между защелками, установить свое значение.
На ступени выборки команды РС задает адрес памяти команд, которая содержит кодированные 32-разрядные слова команд. На этой ступени РС увеличивается на 4 (байта), указывая на адрес следующей команды, за исключением команд условного перехода, которые сами обеспечивают установку нового адреса в РС.
На ступени декодирования из команды извлекаются адреса регистров, по которым их банка регистров выбираются данные.
На ступени выполнения, выбранные из банка регистров или из РС (для команд безусловного перехода) данные преобразуются с помощью ALU.
На ступени памяти выполняются операции записи или чтения по адресу, указанному в регистре банка.
На ступени обратной записи выполняется запоминание результата в регистровом файле.
В случае DSP добавляется одна или две ступени для выполнения умножения и вычисления адресов двух портовой памяти с помощью отдельных ALU. Двух портовая память допускает одновременный доступ к двум операндам.
Оборудование конвейера между регистрами-защелками функционирует параллельно. Следовательно, мы видим, что одновременно выполняется пять команд каждая на своей ступени. Это легко визуализировать с помощь таблицы распределения на рис. 7.
Слева на рисунке показаны одновременно используемые аппаратные
ресурсы. Регистровый банк появляется три раза, т.к. в цикле команды могут быть два чтения и одна запись в банк регистров.
Таблица распределения показывает последовательность команд A, B, C, D, E программы. В цикле 5 выбирается Е в то время как D читает из банка регистров, С использует ALU, В читает или записывает в память данных, а А записывает результат в банк регистров. Запись А происходит в цикле 5, а чтение В в цикле 3. Таким образом значение прочитанное В не может быть значением, записываемым А. Это вызывает риск сбоя данных при чтении (на рис.6. отмечено пунктирной линией). Обычно программист предполагает А выполняется перед В и результат А доступен В, что в действительности не так.

Рис.7. Таблица распределения для конвейера на рис. 6
В компьютерных архитектурах проблема рисков сбоя решается различными путями. Простейшее решение известно как явный конвейер, когда риски просто документируются и программист (или компилятор) должен учитывать их. Например, где В читает регистры, записанные А, компилятор должен вставить три пустые команды (ничего не делают) между А и В для обеспечения записи перед чтением. Эти пустые команда образуют «пузыри», распространяющиеся по конвейеру.
Более сложное решение основано на взаимоблокировке, когда аппаратура декодирует В и обнаруживает, что В читает регистр записываемый А (риск сбоя), то выполнение В задерживается на три такта пока А не завершит ступень обратной записи. Это иллюстрирует рис. 8.
Задержку можно уменьшить до двух тактов, если реализовать чуть более сложную логику продвижения команд в конвейере, которая обнаруживает запись А в туже ячейку из которой читает В, а затем напрямую обеспечивает данными В перед их обратной записью. Это автоматизация введения
«пузырей».
Еще более сложной техникой является выполнение с изменением последовательности, когда аппаратура обнаруживает риск сбоя и вместо задержки выполнения В продолжает выборку С и если С не читает регистры записываемые А или В и не записывает регистры читаемые В, тогда продолжается выполнение С перед В. Это уменьшает число «пузырей».

Рис.8. Таблица распределения для конвейера на рис. 6 с взаимоблокировкой когда В
читает регистр, записываемый А.
Другая разновидность рисков сбоя конвейера на рис. 6 – риск сбоя управления выборкой команд. Команда условного перехода изменяет РС, если определенный регистр равен 0. В этом случае, если А является командой условного перехода, она достигает ступени чтения или записи в память перед тем как изменяет РС. Следующие за А команды будут выбраны, декодированы, но в какой то момент времени выясняется что их не нужно было исполнять.
Существует несколько способов преодоления рисков сбоя управления выборкой команд. При задержанном переходе просто документируется, что команда перехода занимает столько-то тактов. Программист (или компилятор) должен обеспечить, чтобы команды, следующие за командами перехода, были пустыми или делали полезную работу, не зависящую от ветвления. Взаимоблокировка обеспечивает автоматическое введение «пузырей» как рисках сбоя данных.
Наиболее сложный способ преодоления рисков сбоя управления выборкой команд это спекулятивное выполнение команд. Аппаратура предполагает что переход, вероятно, будет иметь место и начинает выполнять предполагаемые команды. Если предположение не оправдалось, приходится удалять побочные результаты (такие как запись в регистры), вызванные спекулятивным выполнением команд.
За исключение явной конвейеризации и задержанных переходов все остальные способы вносят вариативность во время выполнения команд. Анализ времени выполнения программы может стать очень трудным в случае длинного конвейера с замысловатым продвижением и спекулятивным выполнением.
Явные конвейеры наиболее характерны для DSP, которые часто используются в задачах, где важно точное время. Изменение порядка выполнения и спекулятивное выполнение характерны в процессорах общего назначения, где время имеет значение в общем смысле. Разработчику встроенных систем необходимо понимать требования приложения и не останавливаться на процессорах, для которых неочевидна точность расчета времени выполнения программ.