

3.2.Методы обучения нейронных сетей
Чтобы
ИНС с предварительно выбранной начальной
архитектурой могла эффективно
функционировать, ее необходимо обучить,
т.е. определить оптимальные значения
величин связей wij,
обычно путем минимизации некоторого
функционала качества (функции ошибки)
![]() в процессе итерационной процедуры, где
количество итераций t
может быть весьма значительным
(t=103…108).
Функция ошибки
может быть произвольной, однако наиболее
часто используется ее представление в
виде (2.6) или (2.24). После выбора совокупности
обучающих примеров и способа вычисления
обучение ИНС превращается в задачу
многомерной оптимизации, для решения
которой могут быть использованы следующие
методы:
в процессе итерационной процедуры, где
количество итераций t
может быть весьма значительным
(t=103…108).
Функция ошибки
может быть произвольной, однако наиболее
часто используется ее представление в
виде (2.6) или (2.24). После выбора совокупности
обучающих примеров и способа вычисления
обучение ИНС превращается в задачу
многомерной оптимизации, для решения
которой могут быть использованы следующие
методы:
локальной оптимизации с вычислением частных производных 1–го и 2–го порядков (градиентные методы);
глобальной (стохастической) оптимизации (методы случайного поиска и алгоритмы искусственного отбора).
Основным критерием для сравнения эффективности различных методов обучения ИНС являются вычислительные затраты, т.е. количество циклов (время) плюс количество операций.
3.2.1.Градиентные методы
Согласно
теории, среди детерминированных методов
оптимизации наиболее эффективными
считаются градиентные методы, связанные
с разложением целевой функции
в ряд Тейлора в окрестности
![]() решения
решения
![]()
![]() (3.2)
(3.2)
где
 –
вектор градиента,
–
вектор градиента,
![]() ,
а симметричная квадратная матрица
,
а симметричная квадратная матрица
![]() производных 2–го порядка
производных 2–го порядка
 называется
гессианом.
называется
гессианом.
Выражение (3.2) можно
считать квадратичным приближением
в ближайшей окрестности w.
Точкой решения
![]() будем считать точку, где достигается
минимум
с точностью O(h3),
т.е.
будем считать точку, где достигается
минимум
с точностью O(h3),
т.е.
![]() ,
а гессиан
– положительно определен.
,
а гессиан
– положительно определен.
В
процессе нахождения минимума
направление поиска
и шаг h
подбираются таким образом, чтобы для
каждой очередной точки
![]() выполнялось условие
выполнялось условие
![]() .
Поиск продолжается, пока
.
Поиск продолжается, пока
![]() не станет меньше наперед заданной
погрешности ,
или не будет превышено максимальное
время вычислений (количество итераций).
В соответствии с этим универсальный
оптимизационный алгоритм обучения ИНС
можно представить в следующем виде
(считаем, что начальное значение
не станет меньше наперед заданной
погрешности ,
или не будет превышено максимальное
время вычислений (количество итераций).
В соответствии с этим универсальный
оптимизационный алгоритм обучения ИНС
можно представить в следующем виде
(считаем, что начальное значение
![]() известно):
известно):
Проверка оптимальности текущего значения
 ,
если «ДА», то «STOP»,
если «НЕТ», то переход к пункту 2.
,
если «ДА», то «STOP»,
если «НЕТ», то переход к пункту 2.Определение вектора направления оптимизации
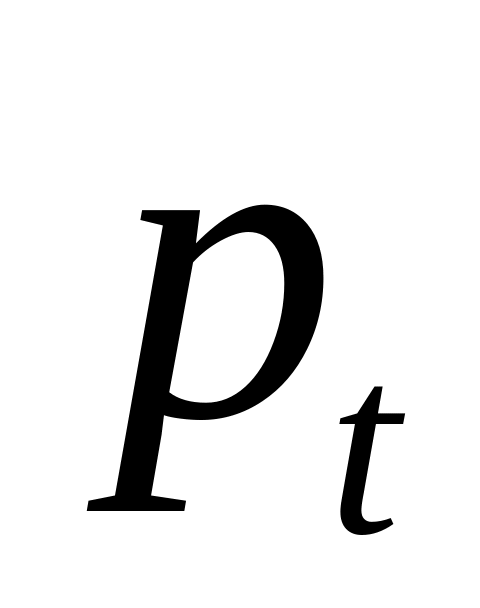 для точки
.
для точки
.Выбор шага t в направлении , при котором выполняется условие .
Определение нового решения
 и соответствующих ему
и соответствующих ему
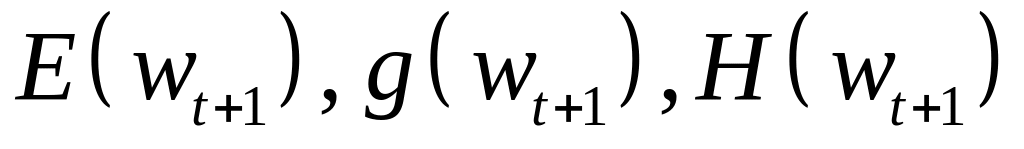 и возврат к пункту 1.
и возврат к пункту 1.
3.2.1.1. Алгоритм наискорейшего спуска (анс)
Если
в разложении (3.2) ограничиться линейным
приближением, то для выполнения
соотношения
достаточно подобрать
![]() ,
чему однозначно удовлетворяет выбор
,
чему однозначно удовлетворяет выбор
![]() (3.3)
(3.3)
в методе наискорейшего спуска. Ограничение линейным приближением в АНС не позволяет использовать информацию о кривизне , что обусловливает медленную сходимость метода (она остается линейной). Более того, вблизи точки решения, когда градиент принимает малые значения, процесс минимизации резко замедляется. Несмотря на указанные недостатки, простота и небольшие вычислительные затраты АНС сделали его одним из основных способов обучения многослойных ИНС. Повысить эффективность АНС удается путем модификации (как правило, эвристической) выражения (3.3).
Достаточно удачной разновидностью АНС является метод обучения с так называемым моментом, где приращение
![]() (3.4)
(3.4)
записывается с
учетом коэффициента момента [0,1].
Первое слагаемое (3.4) соответствует
обычному АНС, второе учитывает предыдущее
изменение весов и не зависит от величины
![]() .
Влияние
.
Влияние
![]() резко возрастает на плоских участках
,
а также вблизи точек минимума, где
значения градиента близки к нулю.
Например, для плоских участков
,
где при постоянном
резко возрастает на плоских участках
,
а также вблизи точек минимума, где
значения градиента близки к нулю.
Например, для плоских участков
,
где при постоянном
![]() приращение весов
приращение весов
![]() ,
можно записать
,
можно записать
![]() ,
откуда
,
откуда
![]() ,
что при =0,9
соответствует ускорению процесса
обучения на порядок. Аналогично, вблизи
локальных минимумов второе слагаемое
(3.4) ввиду малости
начинает доминировать над первым,
приводя к увеличению
и даже к уходу из окрестности данного
локального минимума, что может быть
использовано для целей глобальной
оптимизации. Однако для предотвращения
нестабильности алгоритма временные
возрастания
не должны превышать (4–5)%.
,
что при =0,9
соответствует ускорению процесса
обучения на порядок. Аналогично, вблизи
локальных минимумов второе слагаемое
(3.4) ввиду малости
начинает доминировать над первым,
приводя к увеличению
и даже к уходу из окрестности данного
локального минимума, что может быть
использовано для целей глобальной
оптимизации. Однако для предотвращения
нестабильности алгоритма временные
возрастания
не должны превышать (4–5)%.