

2.3.Адаптивный линейный нейрон
Структура предложенного Б. Видроу нейрона «ADALINE» (ADAptive LInear NEuron) – ФН МакКаллока–Питтса (рис. 2.1) с функцией активации типа signum (табл. 2.1), т.е.
![]() (2.11)
(2.11)
Обучение – с учителем путем подбора wij в процессе минимизации целевой функции
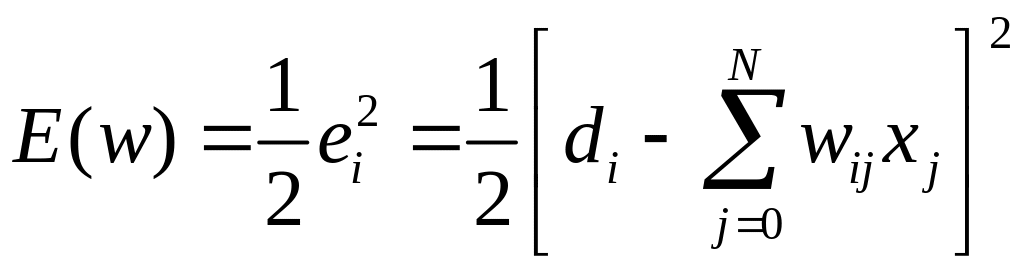 (2.12)
(2.12)
с использованием градиентных методов, поскольку в E(w) входят только линейные члены. Уточнение wij – либо дискретно согласно
![]() (2.13)
(2.13)
либо аналогово – путем решения разностного уравнения
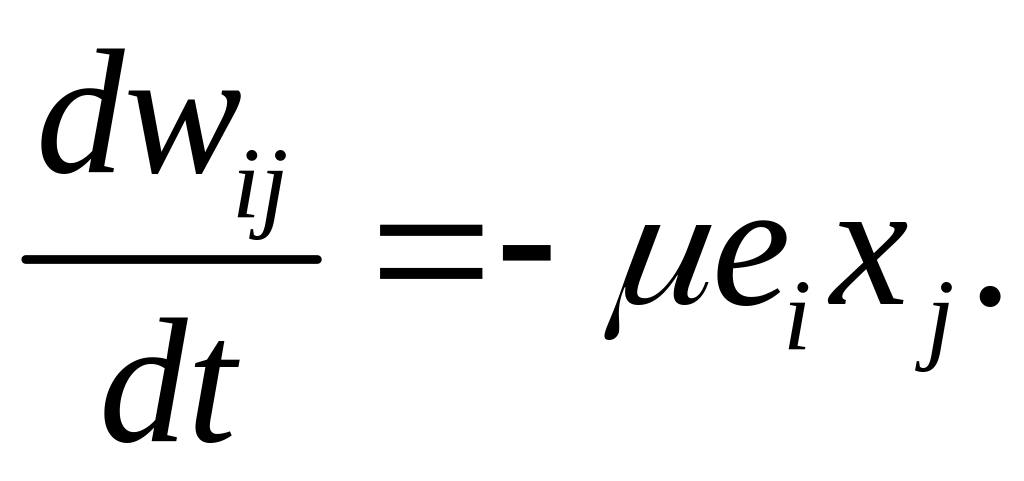 (2.14)
(2.14)
Нейроны типа «ADALINE» имеют относительно простую схемную реализацию, включающую интеграторы, сумматоры и элементы задержки. В практических приложениях эти нейроны всегда используются группами, образуя слои, называемые « MADALINE» (Many ADALINE), где каждый нейрон обучается по правилам (2.13), (2.14).
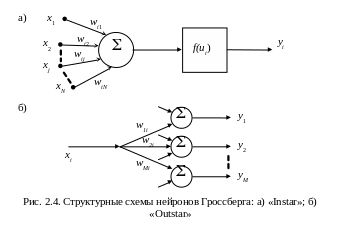
2.4.«Instar» и «Outstar» Гроссберга
Структуры
«Instar»
и «Outstar»,
предложенные С. Гроссбергом (рис. 2.4
а,б), представляют собой взаимодополняющие
элементы: «Instar»
адаптирует веса связей нейрона к входным
сигналам (компонентам
=
[х1,
х2,
…, хN]),
а «Outstar»
– к выходным (компонентам
![]() =
[y1,
y2,
…, yM]).
=
[y1,
y2,
…, yM]).
Функции активации – чаще всего линейные (табл. 2.1).
Обучение – по правилам Гроссберга: для «Instar» (рис. 2.4 а) –
![]() (2.15)
(2.15)
для «Outstar» (рис. 2.4 б) –
![]() (2.16)
(2.16)
Входные
данные для обучения (компоненты
),
как правило, выражаются в нормализованной
форме, когда
![]() ,
а
,
а
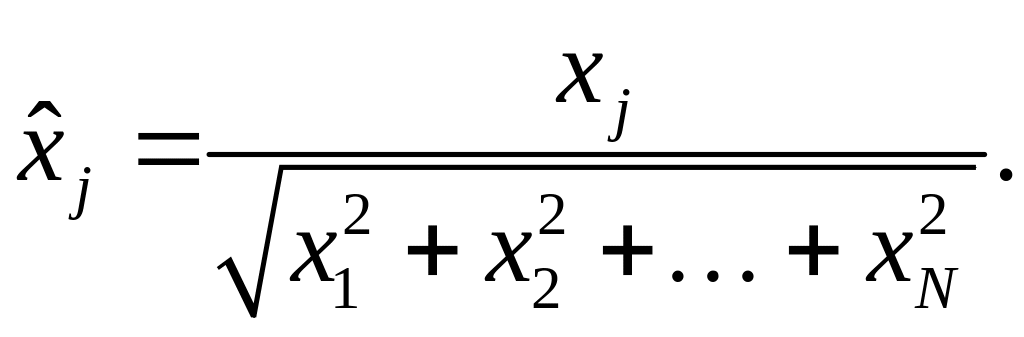
«Instar» и «Outstar» существенно отличаются от предыдущих типов нейронов прежде всего тем, что могут обучаться как с учителем (в этом случае yi=di), так и без него.
2.5.Модель нейрона Хебба
В процессе исследования свойств нервных клеток Д. Хебб заметил, что связь между двумя клетками усиливается, если обе клетки активируются одновременно, и предложил формальное правило обучения, в соответствии с которым вес wij нейрона изменяется пропорционально произведению его входного и выходного сигналов. Правило Хебба может применяться для НС различных типов с любыми функциями активации отдельных нейронов.
Структурная схема нейрона Хебба аналогична стандартной структуре ФН (рис. 2.1), обучение – по правилу Хебба
![]()
где для обучения с учителем
![]() (2.17)
(2.17)
а для обучения без учителя
![]() (2.18)
(2.18)
При обучении по Хеббу веса wij могут принимать сколь угодно большие значения, поскольку на каждой итерации текущее значение wij(t) суммируется с его приращением wij. Обеспечить сходимость процесса обучения возможно: 1) введением коэффициента забывания
![]() (2.19)
(2.19)
где при рекомендуемом < 0,1 нейрон сохраняет бóльшую часть информации, накопленной в процессе обучения, и получает возможность стабилизировать wij на определенном уровне; 2) использованием для обучения линейных нейронов, где стабилизации не происходит даже при введении , модифицированного правила Хебба–Ойя, согласно которому
![]() , (2.20)
, (2.20)
что приводит к ограничению |w|=1, обеспечивающему конечность значений весовых коэффициентов.
2.6.Нейроны типа wta
Нейроны типа WTA (Winner Takes All – Победитель получает все) представляют группу конкурирующих между собой нейронов, получающих одни и те же входные сигналы xj (рис. 2.5). Сравнением выходных значений сумматоров (2.4) определяется нейрон – победитель с максимальной величиной ui, на его выходе устанавливается сигнал yi =1, остальные (проигравшие) нейроны переходят в состояние 0, что блокирует процесс уточнения их весовых коэффициентов. Веса же победившего нейрона уточняются по упрощенному (ввиду бинарности значений выходных сигналов) правилу Гроссберга
![]() (2.21)
(2.21)
с нормализацией xj и wij.
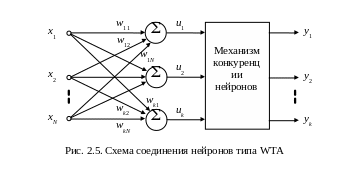
Следствием этой конкуренции становится самоорганизация процесса обучения, ибо уточнение весов происходит таким образом, что для каждой группы близких по значениям обучающих побеждает свой нейрон, который при функционировании распознает именно эту категорию . Серьезной проблемой при обучении WTA остается проблема «мертвых» нейронов, которые после инициализации ни разу не победили в конкурентной борьбе, ибо их наличие уменьшает число прошедших обучение нейронов, соответственно увеличивая общую погрешность распознавания данных. Для решения проблемы используют модифицированное обучение, основанное на штрафовании (временной дисквалификации) наиболее активных нейронов.