

1. Для информации существуют свои единицы измерения информации. Если рассматривать сообщения информации как последовательность знаков, то их можно представлять битами, а измерять в байтах, килобайтах, мегабайтах, гигабайтах, терабайтах и петабайтах.
Бит
Единицей измерения количества информации является бит – это наименьшая (элементарная) единица.
1бит – это количество информации, содержащейся в сообщении, которое вдвое уменьшает неопределенность знаний о чем-либо.
Байт
Байт – основная единица измерения количества информации.
Байтом называется последовательность из 8 битов.
Байт – довольно мелкая единица измерения информации. Например, 1 символ – это 1 байт.
Производные единицы измерения количества информации
1 байт=8 битов
1 килобайт (Кб)=1024 байта =210 байтов
1 мегабайт (Мб)=1024 килобайта =210 килобайтов=220 байтов
1 гигабайт (Гб)=1024 мегабайта =210 мегабайтов=230 байтов
1 терабайт (Гб)=1024 гигабайта =210 гигабайтов=240 байтов
Запомните, приставка КИЛО в информатике – это не 1000, а 1024
Методы измерения количества информации
Итак, количество информации в 1 бит вдвое уменьшает неопределенность знаний. Связь же между количеством возможных событий N и количеством информации I определяется формулой Хартли:
N=2i.
Алфавитный подход к измерению количества информации
При этом подходе отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка, т.е. его алфавит можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет в себе каждый символ:
I=log2N.
Вероятностный подход к измерению количества информации
Этот подход применяют, когда возможные
события имеют различные вероятности
реализации. В этом случае количество
информации определяют по формуле
Шеннона:
 , где I – количество информации, N –
количество возможных событий,
, где I – количество информации, N –
количество возможных событий,
Pi – вероятность i-го события.
Единицы измерения информации служат для измерения объёма информации — величины, исчисляемой логарифмически.[1] Это означает, что когда несколько объектов рассматриваются как один, количество возможных состояний перемножается, а количество информации — складывается. Не важно, идёт речь о случайных величинах в математике, регистрах цифровой памяти в технике или в квантовых системах в физике.
Чаще всего измерение информации касается объёма компьютерной памяти и объёма данных, передаваемых по цифровым каналам связи.
Первичные единицы
Сравнение разных единиц измерения информации. Дискретные величины представлены прямоугольниками, единица «нат» — горизонтальным уровнем. Чёрточки слева — логарифмы натуральных чисел.
Объём информации можно представлять как логарифм[2] количества возможных состояний.
Наименьшее целое число, логарифм которого положителен — это 2. Соответствующая ему единица — бит — является основой исчисления информации в цифровой технике.
Единица, соответствующая числу 3 (трит) равна log23≈1,585 бита, числу 10 (хартли) — log210≈3.322 бита.
Такая единица как нат (nat), соответствующая натуральному логарифму применяется в инженерных и научных расчётах. В вычислительной технике она практически не применяется, так как основание натуральных логарифмов не является целым числом.
В проводной технике связи (телеграф и телефон) и радио исторически впервые единица информации получила обозначение бод.
Единицы, производные от бита
Целые количества бит отвечают количеству состояний, равному степеням двойки.
Особое название имеет 4 бита — ниббл (полубайт, тетрада, четыре двоичных разряда), которые вмещают в себя количество информации, содержащейся в одной шестнадцатеричной цифре.
Следующей по порядку популярной единицей информации является 8 бит, или байт (о терминологических тонкостях написано ниже). Именно к байту (а не к биту) непосредственно приводятся все большие объёмы информации, исчисляемые в компьютерных технологиях.
Такие величины как машинное слово и т. п., составляющие несколько байт, в качестве единиц измерения почти никогда не используются.
Килобайт
Для измерения больших количеств байтов служат единицы «килобайт» = [1024] байт и «Кбайт»[3] (кибибайт, kibibyte) = 1024 байт (о путанице десятичных и двоичных единиц и терминов см. ниже). Такой порядок величин имеют, например:
Сектор диска обычно равен 512 байтам то есть половине килобайта, хотя для некоторых устройств может быть равен одному или двум кибибайт.
Классический размер «блока» в файловых системах UNIX равен одному Кбайт (1024 байт).
«Страница памяти» в процессорах x86 (начиная с модели Intel 80386) имеет размер 4096 байт, то есть 4 Кбайт.
Объём информации, получаемой при считывании дискеты «3,5″ высокой плотности» равен 1440 Кбайт (ровно); другие форматы также исчисляются целым числом Кбайт.
[править]
Мегабайт
Основная статья: Мегабайт
Единицы «мегабайт» = 1000 килобайт = [1 000 000] байт и «мебибайт»[3] (mebibyte) = 1024 Кбайт = 1 048 576 байт применяются для измерения объёмов носителей информации.
Объём адресного пространства процессора Intel 8086 был равен 1 Мбайт.
Оперативную память и ёмкость CD-ROM меряют двоичными единицами (мебибайтами, хотя их так обычно не называют), но для объёма НЖМД десятичные мегабайты были более популярны.
Современные жёсткие диски имеют объёмы, выражаемые в этих единицах минимум шестизначными числами, поэтому для них применяются гигабайты.
Гигабайт
Единицы «гигабайт» = 1024 мегабайт = [1048576] килобайт = [1073741824] байт и «Гбайт»[3] (гибибайт, gibibyte) = 1024 Мбайт = 230 байт измеряют объём больших носителей информации, например жёстких дисков. Разница между двоичной и десятичной единицами уже превышает 7 %.
Размер 32-битного адресного пространства равен 4 Гбайт ≈ 4,295 Мбайт. Такой же порядок имеют размер DVD-ROM и современных носителей на флеш-памяти. Размеры жёстких дисков уже достигают сотен и тысяч гигабайт.
Для исчисления ещё больших объёмов информации имеются единицы терабайт и тебибайт (1012 и 240 байт соответственно), петабайт и пебибайт (1015 и 250 байт соответственно) и т. д.
Что такое «байт»?
В принципе, байт определяется для конкретного компьютера как минимальный шаг адресации памяти, который на старых машинах не обязательно был равен 8 битам (а память не обязательно состоит из битов — см., например: троичный компьютер). В современной традиции, байт часто считают равным восьми битам.
В таких обозначениях как байт (русское) или B (английское) под байт (B) подразумевается именно 8 бит, хотя сам термин «байт» не вполне корректен с точки зрения теории.
Во французском языке используются обозначения o, Ko, Mo и т. д. (от слова octet) дабы подчеркнуть, что речь идёт именно о 8 битах.
Чему равно «кило»?
Основная статья: Двоичные приставки
Долгое время разнице между множителями 1000 и 1024 старались не придавать большого значения. Во избежание недоразумений следует чётко понимать различие между:
двоичными кратными единицами, обозначаемыми согласно ГОСТ 8.417-2002 как «Кбайт», «Мбайт», «Гбайт» и т. д. (два в степенях кратных десяти);
единицами килобайт, мегабайт, гигабайт и т. д., понимаемыми как научные термины (десять в степенях, кратных трём),
эти единицы по определению равны, соответственно, 103, 106, 109 байтам и т. д.
В качестве терминов для «Кбайт», «Мбайт», «Гбайт» и т. д. МЭК предлагает «кибибайт», «мебибайт», «гибибайт» и т. д., однако эти термины критикуются за непроизносимость и не встречаются в устной речи.
В различных областях информатики предпочтения в употреблении десятичных и двоичных единиц тоже различны. Причём, хотя со времени стандартизации терминологии и обозначений прошло уже несколько лет, далеко не везде стремятся прояснить точное значение используемых единиц.
В английском языке для «киби»=1024 иногда используют прописную букву K, дабы подчеркнуть отличие от обозначаемой строчной буквой приставки СИ кило. Однако, такое обозначение не опирается на авторитетный стандарт, в отличие от российского ГОСТа касательно «Кбайт».
2. С точки зрения программиста, данные — это часть программы, совокупность значений определённых ячеек памяти, преобразование которых осуществляет код. С точки зрения компилятора, процессора, операционной системы, это совокупность ячеек памяти, обладающих определёнными свойствами (возможность чтения и записи (необяз.), невозможность исполнения).
Контроль за доступом к данным в современных компьютерах осуществляется аппаратно.
В соответствии с принципом фон Неймана, одна и та же область памяти может выступать как в качестве данных, так и в качестве исполнимого кода.
Типы данных
Традиционно выделяют два типа данных — двоичные (бинарные) и текстовые.
Двоичные данные обрабатываются только специализированным программным обеспечением, знающим их структуру, все остальные программы передают данные без изменений.
Текстовые данные воспринимаются передающими системами как текст, записанный на каком-либо языке. Для них может осуществляться перекодировка (из кодировки отправляющей системы в кодировку принимающей), заменяться символы переноса строки, изменяться максимальная длина строки, изменяться количество пробелов в тексте.
Передача текстовых данных как бинарных приводит к необходимости изменять кодировку в прикладном программном обеспечении (это умеет большинство прикладного ПО, отображающего текст, получаемый из разных источников), передача бинарных данных как текстовых может привести к их необратимому повреждению.
Данные в объектно-ориентированном программировании
Могут обрабатываться функциями объекта, которому принадлежат сами, либо функциями других объектов, имеющими для этого возможность.
Данные в языках разметки
Имеют различное отображение в зависимости от выбранного способа представления.
Данные в XML
В теории множеств
В отличие от операций над элементами множества, представляют собой множество (название и элементы множества)
Операции с данными
Для повышения качества данные преобразуются из одного вида в другой с помощью методов обработки. Обработка данных включает операции:
1) ввод (сбор) данных — накопление данных с целью обеспечения достаточной полноты для принятия решений;
2) формализация данных — приведение данных, поступающих из разных источников, к одинаковой форме, для повышения их доступности;
3) фильтрация данных — это отсеивание «лишних» данных, в которых нет необходимости для повышения достоверности и адекватности;
4) сортировка данных — это упорядочивание данных по заданному признаку с целью удобства их использования;
5) архивация — это организация хранения данных в удобной и легкодоступной форме;
6) защита данных — включает меры, направленные на предотвращение утраты, воспроизведения и модификации данных;
7) транспортировка данных — приём и передача данных между участниками информационного процесса;
8) преобразование данных — это перевод данных из одной формы в другую или из одной структуры в другую.
Кодирование данных
Код – система условных обозначений или сигналов.
Длина кода – количество знаков, используемых для представления кодируемой информации
Кодирование данных – это процесс формирования определенного представления информации.
Декодирование – расшифровка кодированных знаков, преобразование кода символа в его изображение
Двоичное кодирование – кодирование информации в виде 0 и 1.
В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Любой способ кодирования характеризуется наличием основы (алфавит, система координат, основание системы счисления и т.д.) и правил конструирования информационных образов на этой основе. Кодирование числовых данных осуществляется с помощью системы счисления.
Двоичное кодирование
Представление информации в двоичной системе использовалось человеком с давних времен. Так,жители островов Полинезии передавали необходимую информацию при помощи барабанов: чередование звонких и глухих ударов. Звук над поверхностью воды распространялся на достаточно большое расстояние, таким образом «работал» полинезийский телеграф. В телеграфе в XIX–XX веках информация передавалась с помощью азбуки Морзе – в виде последовательности из точек и тире. Часто мы договариваемся открывать входную дверь только по «условному сигналу» – комбинации коротких и длинных звонков.
Самюэл Морзе в 1838 г. изобрел код – телеграфную азбуку – систему кодировки символов короткими и длинными посылками для передачи их по линиям связи, известную как «код Морзе» или «морзянка». Современный вариант международного «кода Морзе» (International Morse) появился совсем недавно – в 1939 году, когда была проведена последняя корректировка.
Своя система существует и в вычислительной технике - она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски - binary digit или сокращенно bit (бит). Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т.п.).
Кодирование чисел
Вопрос о кодировании чисел возникает по той причине, что в машину нельзя либо нерационально вводить числа в том виде, в котором они изображаются человеком на бумаге. Во-первых, нужно кодировать знак числа. Во-вторых, по различным причинам, которые будут рассмотрены ниже, приходится иногда кодировать и остальную часть числа.
Кодирование целых чисел производиться через их представление в двоичной системе счисления: именно в этом виде они и помещаются в ячейке. Один бит отводиться при этом для представления знака числа (нулем кодируется знак "плюс", единицей - "минус").
Для кодирования действительных чисел существует специальный формат чисел с плавающей запятой. Число при этом представляется в виде: N = M * qp, где M - мантисса, p - порядок числа N, q - основание системы счисления. Если при этом мантисса M удовлетворяет условию 0,1 <= | M | <= 1 то число N называют нормализованным.
Кодирование текста
Для кодирования букв и других символов, используемых в печатных документах, необходимо закрепить за каждым символом числовой номер – код. В англоязычных странах используются 26 прописных и 26 строчных букв (A … Z, a … z), 9 знаков препинания (. , : ! " ; ? ( ) ), пробел, 10 цифр, 5 знаков арифметических действий (+,-,*, /, ^) и специальные символы (№, %, _, #, $, &, >, <, |, \) – всего чуть больше 100 символов. Таким образом, для кодирования этих символов можно ограничиться максимальным 7-разрядным двоичным числом (от 0 до 1111111, в десятичной системе счисления – от 0 до 127).
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части – растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пиксела содержит информации о его цвете.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения – линия. Каждый элемент векторного изображения является объектом, который описывается с помощью математических уравнении. Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Кодирование звука
На компьютере работать со звуковыми файлами начали в 90-х годах. В основе цифрового кодирования звука лежит – процесс преобразования колебаний воздуха в колебания электрического тока и последующая дискретизация аналогового электрического сигнала. Кодирование и воспроизведение звуковой информации осуществляется с помощью специальных программ (редактор звукозаписи).
Временная дискретизация – способ преобразования звука в цифровую форму путем разбивания звуковой волны на отдельные маленькие временные участки где амплитуды этих участков квантуются (им присваивается определенное значение).
Это производится с помощью аналого-цифрового преобразователя, размещенного на звуковой плате. Таким образом, непрерывная зависимость амплитуды сигнала от времени заменяется дискретной последовательностью уровней громкости. Современные 16-битные звуковые карты кодируют 65536 различных уровней громкости или 16-битную глубину звука (каждому значению амплитуды звук. сигнала присваивается 16-битный код)
Качество кодирование звука зависит от:
глубины кодирования звука - количество уровней звука
частоты дискретизации – количество изменений уровня сигнала в единицу
В чем разница между кодированием и шифрованием?
Шифрование - это способ изменения сообщения, обеспечивающее сокрытие его содержимого. Кодирование - это преобразование обычного, понятного, текста в код. При этом подразумевается, что существует взаимно однозначное соответствие между символами текста и символьного кода - в этом принципиальное отличие кодирования от шифрования.
Структура данных — программная единица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных в вычислительной технике. Для добавления, поиска, изменения и удаления данных структура данных предоставляет некоторый набор функций, составляющих её интерфейс. Структура данных часто является реализацией какого-либо абстрактного типа данных.
При разработке программного обеспечения большую роль играет проектирование хранилища данных и представление всех данных в виде множества связанных структур данных.
Хорошо спроектированное хранилище данных оптимизирует использование ресурсов (таких как время выполнения операций, используемый объём оперативной памяти, число обращений к дисковым накопителям), требуемых для выполнения наиболее критичных операций.
Структуры данных формируются с помощью типов данных, ссылок и операций над ними в выбранном языке программирования.
Различные виды структур данных подходят для различных приложений; некоторые из них имеют узкую специализацию для определённых задач. Например, B-деревья обычно подходят для создания баз данных, в то время как хеш-таблицы используются повсеместно для создания различного рода словарей, например, для отображения доменных имён в интернет-адреса компьютеров.
При разработке программного обеспечения сложность реализации и качество работы программ существенно зависит от правильного выбора структур данных. Это понимание дало начало формальным методам разработки и языкам программирования, в которых именно структуры данных, а не алгоритмы, ставятся во главу архитектуры программного средства. Большая часть таких языков обладает определённым типом модульности, позволяющим структурам данных безопасно переиспользоваться в различных приложениях. Объектно-ориентированные языки, такие как Java, C# и C++, являются примерами такого подхода.
Многие классические структуры данных представлены в стандартных библиотеках языков программирования или непосредственно встроены в языки программирования. Например, структура данных хэш-таблица встроена в языки программирования Lua, Perl, Python, Ruby, Tcl и др. Широко используется стандартная библиотека шаблонов STL языка C++.
Фундаментальными строительными блоками для большей части структур данных являются массивы, записи (см. конструкцию struct в языке Си и конструкцию record в языке Паскаль), размеченные объединения (см. конструкцию union в языке Си) и ссылки. Например, структура данных двусвязный список, может быть построена с помощью записей и зануляемых ссылок, а именно, каждая запись будет предоставлять блок данных (узел, node), содержащий ссылки на «левый» и «правый» узлы, а также сами хранимые данные.
1.1.1.Основные типы данных.
Данные, хранящиеся в памяти ЭВМ представляют собой совокупность нулей и едениц (битов). Биты объединяются в последовательности: байты, слова и т.д. Каждому участку оперативной памяти, который может вместить один байт или слово, присваивается порядковый номер (адрес).
Какой смысл заключен в данных, какими символами они выражены - буквенными или цифровыми, что означает то или иное число - все это определяется программой обработки. Все данные необходимые для решения практических задач подразделяются на несколько типов, причем понятие тип связывается не только с представлением данных в адресном пространстве, но и со способом их обработки.
Любые данные могут быть отнесены к одному из двух типов: основному (простому), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач.
Данные простого типа это - символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из элементарных данных формируются структуры (сложные типы) данных.
Некоторые структуры:
Массив(функция с конечной областью определения) - простая совокупность элементов данных одного типа, средство оперирования группой данных одного типа. Отдельный элемент массива задается индексом. Массив может быть одномерным, двумерным и т.д. Разновидностями одномерных массивов переменной длины являются структуры типа кольцо, стек, очередь и двухсторонняя очередь.
Запись(декартово произведение) - совокупность элементов данных разного типа. В простейшем случае запись содержит постоянное количество элементов, которые называют полями. Совокупность записей одинаковой структуры называется файлом. (Файлом называют также набор данных во внешней памяти, например, на магнитном диске). Для того, чтобы иметь возможность извлекать из файла отдельные записи, каждой записи присваивают уникальное имя или номер, которое служит ее идентификатором и располагается в отдельном поле. Этот идентификатор называют ключом.
Такие структуры данных как массив или запись занимают в памяти ЭВМ постоянный объем, поэтому их называют статическими структурами. К статическим структурам относится также множество.
Имеется ряд структур, которые могут изменять свою длину - так называемые динамические структуры. К ним относятся дерево, список, ссылка.
Важной структурой, для размещения элементов которой требуется нелинейное адресное пространство является дерево. Существует большое количество структур данных, которые могут быть представлены как деревья. Это, например, классификационные, иерархические, рекурсивные и др. структуры.
3. Система счисле́ния — символический метод записи чисел, представление чисел с помощью письменных знаков.
Система счисления:
даёт представления множества чисел (целых и/или вещественных);
даёт каждому числу уникальное представление (или, по крайней мере, стандартное представление);
отражает алгебраическую и арифметическую структуру чисел.
Системы счисления подразделяются на позиционные, непозиционные и смешанные.
Чем больше основание системы счисления, тем меньшее количество разрядов (то есть записываемых цифр) требуется при записи числа в позиционных системах счисления.
Позиционные системы счисления
Основная статья: Позиционная система счисления
В позиционных системах счисления один и тот же числовой знак (цифра) в записи числа имеет различные значения в зависимости от того места (разряда), где он расположен. Изобретение позиционной нумерации, основанной на поместном значении цифр, приписывается шумерам и вавилонянам; развита была такая нумерация индусами и имела неоценимые последствия в истории человеческой цивилизации. К числу таких систем относится современная десятичная система счисления, возникновение которой связано со счётом на пальцах. В средневековой Европе она появилась через итальянских купцов, в свою очередь заимствовавших её у мусульман.
Под позиционной системой счисления обычно понимается b-ричная система счисления, которая определяется целым числом b > 1, называемым основанием системы счисления. Целое число x в b-ричной системе счисления представляется в виде конечной линейной комбинации степеней числа b:
, где ak — это целые числа, называемые цифрами, удовлетворяющие неравенству .
Каждая степень bk в такой записи называется весовым коэффициентом разряда. Старшинство разрядов и соответствующих им цифр определяется значением показателя k (номером разряда). Обычно для ненулевого числа x требуют, чтобы старшая цифра an − 1 в его b-ричном представлении была также ненулевой.
Если не возникает разночтений (например, когда все цифры представляются в виде уникальных письменных знаков), число x записывают в виде последовательности его b-ричных цифр, перечисляемых по убыванию старшинства разрядов слева направо:
Например, число сто три представляется в десятичной системе счисления в виде:
Наиболее употребляемыми в настоящее время позиционными системами являются:
1 — единичная[1] (счёт на пальцах, зарубки, узелки «на память» и др.);
2 — двоичная (в дискретной математике, информатике, программировании);
3 — троичная;
8 — восьмеричная;
10 — десятичная (используется повсеместно);
12 — двенадцатеричная (счёт дюжинами);
16 — шестнадцатеричная (используется в программировании, информатике);
60 — шестидесятеричная (единицы измерения времени, измерение углов и, в частности, координат, долготы и широты).
4. Файл (англ. file — папка, скоросшиватель) — концепция в вычислительной технике: сущность, позволяющая получить доступ к какому-либо ресурсу вычислительной системы и обладающая рядом признаков:
фиксированное имя (последовательность символов, число или что-то иное, однозначно характеризующее файл);
определённое логическое представление и соответствующие ему операции чтения/записи.
Может быть любой — от последовательности бит до базы данных с произвольной организацией или любым промежуточным вариантом.
Первому случаю соответствуют операции чтения/записи потока и/или массива (то есть последовательные или с доступом по индексу), второму — команды СУБД. Промежуточные варианты — чтение и разбор всевозможных форматов файлов.
В информатике используется следующее определение: файл — поименованная совокупность байтов произвольной длины, находящихся на носителе информации.
В отличие от переменной, файл (в частности, его имя) имеет смысл вне конкретной программы. Работа с файлами реализуется средствами операционных систем.
Ресурсами, доступными через файлы, в принципе, может быть что угодно, представимое в цифровом виде. Чаще всего в их перечень входят:
области данных (необязательно на диске);
устройства (как физические, так и виртуальные);
потоки данных (в частности, вход или выход процесса);
сетевые ресурсы;
объекты операционной системы.
Файлы первого типа исторически возникли первыми и распространены наиболее широко, поэтому часто «файлом» называют и область данных, соответствующую имени.
В большинстве файловых систем имя файла используется для указания к какому именно файлу производится обращение. В различных файловых системах ограничения на имя файла сильно различаются:
В FAT16 и FAT12 размер имени файла ограничен 8 символами (3 символа расширения).
В VFAT ограничение 255 байт.
В FAT32, HPFS имя файла ограниченно 255 символами
В NTFS имя ограничено 255 символами Unicode
В ext2/ext3 ограничение 255 байт.
Помимо ограничений файловой системы, интерфейсы операционной системы дополнительно ограничивают набор символов, который допустим при работе с файлами.
Для MS-DOS в имени файла допустимы только заглавные буквы, цифры. Недопустимы пробел, знак вопроса, звёздочка, символы больше/меньше, символ вертикальной черты.[1] При вызове системных функций именами файлов в нижнем или смешанном регистре, они приводятся к верхнему регистру.
Для Microsoft Windows в имени файла разрешены заглавные и строчные буквы, цифры, некоторые знаки препинания, пробел. Запрещены символы > < | ? * / \ : ".
Для GNU/Linux (с учётом возможности маскировки) разрешены все символы, кроме / и нулевого байта.
Большинство операционных систем требуют уникальности имени файла в одном каталоге, хотя некоторые системы допускают файлы с одинаковыми именами (например, при работе с ленточными накопителями).
Атрибуты
В некоторых файловых системах предусмотрены атрибуты (обычно это бинарное значение «да»/«нет», кодируемое одним битом). Практически атрибуты не влияют на возможность доступа к файлам, для этого в некоторых файловых системах существуют права доступа.Название атрибута перевод значение файловые системы операционные системы
READ ONLY только для чтения в файл запрещено писать FAT32, FAT12, FAT16, NTFS, HPFS, VFAT DOS, OS/2, Windows
SYSTEM системный критический для работы операционной системы файл FAT32, FAT12, FAT16, NTFS, HPFS, VFAT DOS, OS/2, Windows
HIDDEN скрытый файл скрывается от показа, пока явно не сказано обратное FAT32, FAT12, FAT16, NTFS, HPFS, VFAT DOS, OS/2, Windows
ARCHIVE архивный (требующий архивации) файл изменён после резервного копирования или не был скопирован программами резервного копирования FAT32, FAT12, FAT16, NTFS, HPFS, VFAT DOS, OS/2, Windows
Операции, связанные с открытием файла
В зависимости от операционной системы те или иные операции могут отсутствовать.
Обычно выделяют дополнительные сущности, связанные с работой с файлом:
хэндлер файла, или дескриптор (описатель). При открытии файла (в случае, если это возможно), операционная система возвращает число (или указатель на структуру), с помощью которого выполняются все остальные файловые операции. По их завершению файл закрывается, а хэндлер теряет смысл.
файловый указатель. Число, являющееся смещением относительно нулевого байта в файле. Обычно по этому адресу осуществляется чтение/запись, в случае, если вызов операции чтения/записи не предусматривает указание адреса. При выполнении операций чтения/записи файловый указатель смещается на число прочитанных (записанных) байт. Последовательный вызов операций чтения таким образом позволяет прочитать весь файл не заботясь о его размере.
файловый буфер. Операционная система (и/или библиотека языка программирования) осуществляет кэширование файловых операций в специальном буфере (участке памяти). При закрытии файла буфер сбрасывается.
режим доступа. В зависимости от потребностей программы, файл может быть открыт на чтение и/или запись. Кроме того, некоторые операционные системы (и/или библиотеки) предусматривают режим работы с текстовыми файлами. Режим обычно указывается при открытии файла.
режим общего доступа. В случае многозадачной операционной системы возможна ситуация, когда несколько программ одновременно хотят открыть файл на запись и/или чтение. Для регуляции этого существуют режимы общего доступа, указывающие на возможность осуществления совместного доступа к файлу (например, файл в который производится запись может быть открыт для чтения другими программами — это стандартный режим работы log-файлов).
Операции
Открытие файла (обычно в качестве параметров передается имя файла, режим доступа и режим совместного доступа, а в качестве значения выступает файловый хэндлер или дескриптор), кроме того обычно имеется возможность в случае открытия на запись указать на то, должен ли размер файла изменяться на нулевой.
Закрытие файла. В качестве аргумента выступает значение, полученное при открытии файла. При закрытии все файловые буферы сбрасываются.
Запись — в файл помещаются данные.
Чтение — данные из файла помещаются в область памяти.
Перемещение указателя — указатель перемещается на указанное число байт вперёд/назад или перемещается по указанному смещению относительно начала/конца. Не все файлы позволяют выполнение этой операции (например, файл на ленточном накопителе может не «уметь» перематываться назад).
Сброс буферов — содержимое файловых буферов с незаписанной в файл информацией записывается. Используется обычно для указания на завершение записи логического блока (для сохранения данных в файле на случай сбоя).
Получение текущего значения файлового указателя.
[править]
Операции, не связанные с открытием файла
Операции, не требующие открытия файла оперируют с его «внешними» признаками — размером, именем, положением в дереве каталогов. При таких операциях невозможно получить доступ к содержимому файла, файл является минимальной единицей деления информации.
В зависимости от файловой системы, носителя информации, операционной системой часть операций может быть недоступна.
Список операций с файлами
Открытие для изменения файла
Удаление файла
Переименование файла
Копирование файла
Перенос файла на другую файловую систему/носитель информации
Создание симлинка или хардлинка
Получение или изменение атрибутов файла
8. Компьютерная сеть (вычислительная сеть, сеть передачи данных) — система связи компьютеров и/или компьютерного оборудования (серверы, маршрутизаторы и другое оборудование). Для передачи информации могут быть использованы различные физические явления, как правило — различные виды электрических сигналов, световых сигналов или электромагнитного излучения.
Топологии сетей.
Термин «топология», или «топология сети», характеризует физическое расположение компьютеров, кабелей и других компонентов сети. Топология — это стандартный термин, который используется профессионалами при описании основной компоновки сети. Если Вы поймете, как используются различные топологии, Вы сумеете понять, какими возможностями обладают различные типы сетей. Чтобы совместно использовать ресурсы или выполнять другие сетевые задачи, компьютеры должны быть подключены друг к другу. Для этой цели в большинстве сетей применяется кабель. Однако просто подключить компьютер к кабелю, соединяющему другие компьютеры, не достаточно. Различные типы кабелей в сочетании с различными сетевыми платами, сетевыми операционными системами и другими компонентами требуют и различного взаимного расположения компьютеров. Каждая топология сети налагает ряд условий. Например, она может диктовать не только тип кабеля, но и способ его прокладки. Топология может также определять способ взаимодействия компьютеров в сети. Различным видам топологий соответствуют различные методы взаимодействия, и эти методы оказывают большое влияние на сеть.
Базовые топологии
Все сети строятся на основе трех базовых топологий:
шина (bus);
звезда (star);
кольцо (ring).
Если компьютеры подключены вдоль одного кабеля [сегмента (segment)], топология называется шиной. В том случае, когда компьютеры подключены к сегментам кабеля, исходящим из одной точки, или концентратора, топология называется звездой. Если кабель, к которому подключены компьютеры, замкнут в кольцо, такая топология носит название кольца. Хотя сами по себе базовые топологии несложны, в реальности часто встречаются довольно сложные комбинации, объединяющие свойства нескольких топологий.
Шина
Топологию «шина» часто называют «линейной шиной» (linear bus). Данная топология относится к наиболее простым и широко распространенным топологиям. В ней используется один кабель, именуемый магистралью или сегментом, вдоль которого подключены все компьютеры сети.
Взаимодействие компьютеров 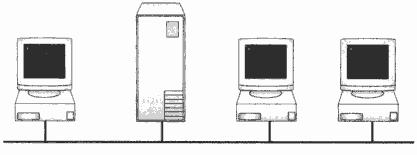
В сети с топологией «шина» компьютеры адресуют данные конкретному компьютеру, передавая их по кабелю в виде электрических сигналов. Чтобы понять процесс взаимодействия компьютеров по шине, Вы должны уяснить следующие понятия:
передача сигнала;
отражение сигнала; терминатор.
Передача сигнала
Данные в виде электрических сигналов передаются всем компьютерам сети; однако информацию принимает только тот, адрес которого соответствует адресу получателя, ' зашифрованному в этих сигналах. Причем в каждый момент времени только один компьютер может вести передачу.Так как данные в сеть передаются лишь одним компьютером, ее производительность зависит от количества компьютеров, подключенных к шине. Чем их больше, т.е. чем больше компьютеров, ожидающих передачи данных, тем медленнее сеть. Однако вывести прямую зависимость между пропускной способностью сети и количеством компьютеров в ней нельзя. Ибо, кроме числа компьютеров, на быстродействие сети влияет множество факторов, в том числе:
характеристики аппаратного обеспечения компьютеров в сети;
частота, с которой компьютеры передают данные;
тип работающих сетевых приложений;
тип сетевого кабеля;
расстояние между компьютерами в сети.
Шина — пассивная топология. Это значит, что компьютеры только «слушают» передаваемые по сети данные, но не перемещают их от отправителя к получателю. Поэтому, если один из компьютеров выйдет из строя, это не скажется на работе остальных. В активных топологиях компьютеры регенерируют сигналы и передают их по сети.
Отражение сигнала
Данные, или электрические сигналы, распространяются по всей сети -- от одного конца кабеля к другому. Если не предпринимать никаких специальных действий, сигнал, достигая конца кабеля, будет отражаться и не позволит другим компьютерам осуществлять передачу. Поэтому, после того как данные достигнут адресата, электрические сигналы необходимо погасить.
Терминатор 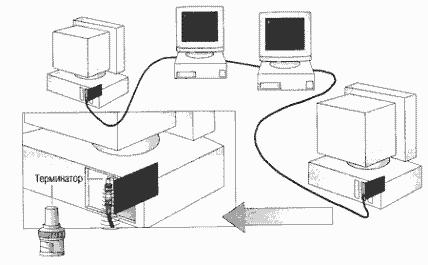
Чтобы предотвратить отражение электрических сигналов, на каждом конце кабеля устанавливают терминаторы (terminators), поглощающие эти сигналы. Все концы сетевого кабеля должны быть к чему-нибудь подключены, например к компьютеру или к баррел-коннектору — для увеличения длины кабеля. К любому свободному — неподключенному — концу кабеля должен быть подсоединен терминатор, чтобы предотвратить отражение электрических сигналов.
Нарушение целостности сети
Разрыв сетевого кабеля происходит при его физическом разрыве или отсоединении одного из его концов. Возможна также ситуация, когда на одном или нескольких концах кабеля отсутствуют терминаторы, что приводит к отражению электрических сигналов в кабеле и прекращению функционирования сети. Сеть «падает». Сами по себе компьютеры в сети остаются полностью работоспособными, но до тех пор, пока сегмент разорван, они не могут взаимодействовать друг с другом.
Звезда 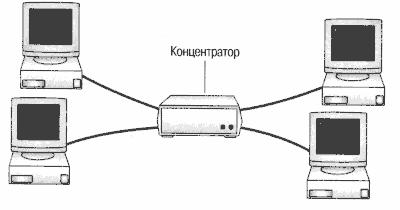
При топологии «звезда» все компьютеры с помощью сегментов кабеля подключаются к центральному компоненту, именуемому концентратором (hub). Сигналы от передающего компьютера поступают через концентратор ко всем остальным. Эта топология возникла на заре вычислительной техники, когда компьютеры были подключены к центральному, главному, компьютеру.
В сетях с топологией «звезда» подключение кабеля и управление конфигурацией сети централизованны. Но есть и недостаток: так как все компьютеры подключены к центральной точке, для больших сетей значительно увеличивается расход кабеля. К тому же, если центральный компонент выйдет из строя, нарушится работа всей сети. А если выйдет из строя только один компьютер (или кабель, соединяющий его с концентратором), то лишь этот компьютер не сможет передавать или принимать данные по сети. На остальные компьютеры в сети это не повлияет.
Кольцо
При топологии «кольцо» компьютеры подключаются к кабелю, замкнутому в кольцо. Поэтому у кабеля просто не может быть свободного конца, к которому надо подключать терминатор. Сигналы передаются по кольцу в одном направлении и проходят через каждый компьютер. В отличие от пассивной топологии «шина», здесь каждый компьютер выступает в роли репитера, усиливая сигналы и передавая их следующему компьютеру. Поэтому, если выйдет из строя один компьютер, прекращает функционировать вся сеть.
Передача маркера
Один из принципов передачи данных в кольцевой сети носит название передачи маркера. Суть его такова. Маркер последовательно, от одного компьютера к другому, передается до тех пор, пока его не получит тот, который «хочет» передать данные. Передающий компьютер изменяет маркер, помещает электронный адрес в данные и посылает их по кольцу.
Данные проходят через каждый компьютер, пока не окажутся у того, чей адрес совпадает с адресом получателя, указанным в данных. После этого принимающий компьютер посылает передающему сообщение, где подтверждает факт приёма данных. Получим подтверждение, передающий компьютер создаёт новый маркер и возвращает его в сеть. На первый взглядкажется, что передача маркера отнимает много времени, однако на самом деле маркер передвигается приктически со скоростью света. В кольце диаметром 200 м маркер может циркулировать с частотой 10 000 оборотов в секунду.
Архитектура - спецификации связи, разработанные для определения функций сети и установления стандартов различных моделей вычислительных систем, предназначенных для обмена и обработки данных.
Для стандартизации сетей Международная организация стандартов (OSI) предложила семиуровневую сетевую архитектуру. К сожалению, конкретные реализации сетей не используют все уровни международного стандарта. Однако этот стандарт дает общее представление о взаимодействии отдельных подсистем сети.
Семиуровневая сетевая архитектура
Физический уровень (Physical Layer).
Уровень управления линией передачи данных (Data Link).
Сетевой уровень (Network Layer).
Транспортный уровень (Transport Layer).
Сеансовый уровень (Session Layer).
Уровень представления (Presentation Layer).
Уровень приложений (Application Layer).
Физический уровень (Physical Layer) обеспечивает виртуальную линию связи для передачи данных между узлами сети. На этом уровне выполняется преобразование данных, поступающих от следующего, более высокого уровня (уровень управления передачей данных), в сигналы, передающиеся по кабелю.
В глобальных сетях на этом уровне могут использоваться модемы и интерфейс RS-232-C. Характерные скорости передачи здесь определяются линиями связи и для телефонных линий (особенно отечественных) обычно не превышают 2400 бод.
В локальных сетях для преобразования данных применяются сетевые адаптеры, обеспечивающие скоростную передачу данных в цифровой форме. Скорость передачи данных может достигать десятков и сотен мегабит в секунду.
Уровень управления линией передачи данных (Data Link) обеспечивает виртуальную линию связи более высокого уровня, способную безошибочно передавать данные в асинхронном режиме. При этом данные обычно передаются блоками, содержащими дополнительную управляющую информацию. Такие блоки называют кадрами.
При возникновении ошибок автоматически выполняется повторная посылка кадра. Кроме того, на уровне управления линией передачи данных обычно обеспечивается правильная последовательность передаваемых и принимаемых кадров. Последнее означает, что если один компьютер передает другому несколько блоков данных, то принимающий компьютер получит эти блоки данных именно в той последовательности, в какой они были переданы.
Сетевой уровень (Network Layer) предполагает, что с каждым узлом сети связан некий процесс. Процессы, работающие на узлах сети, взаимодействуют друг с другом и обеспечивают выбор маршрута передачи данных в сети (маршрутизацию), а также управление потоком данных в сети. В частности, на этом уровне должна выполняться буферизация данных.
Транспортный уровень (Transport Layer) может выполнять разделение передаваемых сообщений на пакеты на передающем конце и сборку на приемном конце. На этом уровне может выполняться согласование сетевых уровней различных несовместимых между собой сетей через специальные шлюзы. Например, такое согласование потребуется для объединения локальных сетей в глобальные.
Сеансовый уровень (Session Layer) обеспечивает интерфейс с транспортным уровнем. На этом уровне выполняется управление взаимодействием между рабочими станциями, которые участвуют в сеансе связи. В частности, на этом уровне выполняется управление доступом на основе прав доступа.
Уровень представления (Presentation Layer) описывает шифрование данных, их сжатие и кодовое преобразование. Например, если в состав сети входят рабочие станции с разным внутренним представлением данных (ASCII для IBM PC и EBCDIC для IBM-370), необходимо выполнить преобразование.
Уровень приложений (Application Layer) отвечает за поддержку прикладного программного обеспечения конечного пользователя.
9. Что бы понять, как защитить важную информацию на компьютере, необходимо знать, какие вирусы самые опасные и как они классифицируются. Компьютерные вирусы делятся на разные группы по следующим основным признакам: операционная система (OC); среда обитания; деструктивные возможности и особенности алгоритма работы. В свою очередь, по среде обитания они делятся на: файловые; загрузочные; макро; и сетевые.
Наиболее распространенный тип вирусов – файловые вирусы, они любыми способами вписываю себя в исходный код исполняемых файлов (расширение .ехе), либо создают файлы-двойники (еще называют их компаньон-вирусы), либо используют всевозможные особенности организации самой файловой системы (еще их называют link-вирусы).
Макро-вирусы самостоятельно заражают электронные таблицы и файлы-документы нескольких популярных редакторов, что очень опасно. Наглядно никто этого не увидит, но скрытая угроза потери информации будет существовать.
Загрузочные вирусы самостоятельно записывают себя либо в сектор, где находится системный загрузчик винчестера, либо в загрузочный сектор винчестера, либо просто меняют указатель на активный. Таким образом, может быть удалена вся информация с винчестера (не важно, что это, фотографии, документы, видео и т.д.).
Сетевые вирусы постоянно используют для своего распространения по сети команды и протоколы электронной почты и компьютерных сетей. Конечной целью является так же компьютер, который полон информации для владельца вируса.
Кроме того, сегодня существует огромное количество сочетаний – к примеру, файлово-загрузочные вирусы, которые одновременно заражают как сами исполняемые файлы, так и загрузочные сектора винчестера. Такие компьютерные вирусы, обычно, имеют очень сложный алгоритм работы, очень часто применяют специальные методы проникновения в операционную систему, для этого используют полиморфик и стелс – технологии. Еще один популярный вид комбинаций – это сетевой макро-вирус, который во время своего функционирования не только заражает редактируемые документы, но и самостоятельно занимается рассылкой своей копии по электронной почте.
Операционная система, объекты которой подвержены заражению, называется вторым уровнем деления компьютерных вирусов на классы. Каждый сетевой или файловый вирус заражает исполняемые файлы определенной одной или нескольких операционных систем Windows, OS – DOS, OS/2, Win95/NT и т.д. Макро-вирусы в свою очередь заражают файлы форматов Excel, Word, Office97. Загрузочные вирусы с самого начала ориентированы на определенные форматы расположения всей системной информации в загрузочных секторах дисков.
Детально ознакомившись с каждым из видов компьютерных вирусов, можно узнать, что более действенное для надежной защиты своего компьютера, а, следовательно, и всей важно
11. Клавиатура (нем. Klaviator.от лат. clavis-ключ)-комплект, расположенных в определенном порядке рычагов-клавиш у какого-либо механизма для управления каким-либо устройством или для ввода информации. Как правило, кнопки нажимаются пальцами рук. Бывают однако и сенсорные.
Существует два основных вида клавиатур: музыкальные и алфавитно-цифровые.
Музыкальные клавиатуры
Основная статья: Музыкальная клавиатура
Клавиатуры музыкальных инструментов предназначаются для игры и имеют набор клавиш, которым соответствуют звуки определенной высоты. Диапазон у клавиатур встречается разный. Клавиатуры для пальцев рук имеются у таких инструментов как рояль, орга́н, клавесин, челеста, синтезатор, а также у баяна, аккордеона и некоторых других инструментов.
Встречаются также музыкальные инструменты с педальной клавиатурой имеющей набор клавиш для игры ногами[1].
Музыкальные инструменты имеющие клавиатуру классифицируются как клавишные музыкальные инструменты.
[править]
Алфавитно-цифровые клавиатуры
Клавиатура комплекса устройств быстродействующей телеграфной радиосвязи (КТ-2), 1936 год
Алфавитно-цифровые клавиатуры используются для управления техническими и механическими устройствами (пишущая машинка, компьютер, калькулятор, кассовый аппарат, кнопочный телефон). Каждой клавише соответствует один или несколько определённых символов. Возможно увеличить количество действий, выполняемых с клавиатуры, с помощью сочетаний клавиш. В клавиатурах такого типа клавиши сопровождаются наклейками с изображением символов или действий, соответствующих нажатию.
Ввод данных в электронное устройство с клавиатуры называется набором, в случае механической или электрической пишущей машинки говорят о печатании. Существует определённая методика набора текста, позволяющая избежать профессионального заболевания.[источник не указан 877 дней] Существуют также методики, позволяющие набирать текст, не глядя на клавиатуру, так называемый слепой метод набора.
Цифровые клавиатуры
Цифровой клавиатурой называется совокупность близко расположенных клавиш с цифрами, предназначенных для ввода чисел (например, номеров). Существует два различных варианта расположения цифр на таких клавиатурах.
В телефонах используется клавиатура, в которой числовые значения клавиш возрастают слева направо и сверху вниз. Аналогичный тип клавиатуры используется в домофонах и других средствах аудиосвязи (например, в программе Skype), а также на пультах дистанционного управления (например, на пульте управления телевизором).
В калькуляторах используется клавиатура, в которой числовые значения клавиш возрастают слева направо и снизу вверх. Многие компьютерные клавиатуры справа имеют блок клавиш, в который входит клавиатура калькуляторного типа.
Компьютерная клавиатура
Основная статья: Клавиатура компьютера
Основными устройствами ввода информации от пользователя в компьютер являются мышь и клавиатура. Стандартная компьютерная клавиатура, также называемая клавиатурой PC/AT или AT-клавиатурой (поскольку она начала поставляться вместе с компьютерами серии IBM PC/AT), имеет 101 или 102 клавиши. Клавиатуры, которые поставлялись вместе с предыдущими сериями — IBM PC и IBM PC/XT, — имели 86 клавиш.[источник не указан 876 дней] Расположение клавиш на AT-клавиатуре подчиняется единой общепринятой схеме, спроектированной в расчёте на английский алфавит.
Манипуля́тор «мышь» (просто «мышь» или «мышка») — механический манипулятор, преобразующий механические движения в движение курсора на экране
Принцип действия
Мышь воспринимает своё перемещение в рабочей плоскости (обычно — на участке поверхности стола) и передаёт эту информацию компьютеру. Программа, работающая на компьютере, в ответ на перемещение мыши производит на экране действие, отвечающее направлению и расстоянию этого перемещения. В универсальных интерфейсах (например, в оконных) с помощью мыши пользователь управляет специальным курсором — указателем — манипулятором элементами интерфейса. Иногда используется ввод команд мышью без участия видимых элементов интерфейса программы: при помощи анализа движений мыши. Такой способ получил название «жесты мышью» (англ. mouse gestures).
В дополнение к детектору перемещения, мышь имеет от одной до трёх и более кнопок, а также дополнительные элементы управления (колёса прокрутки, потенциометры, джойстики, трекболы, клавиши и т. п.), действие которых обычно связывается с текущим положением курсора (или составляющих специфического интерфейса).
Элементы управления мыши во многом являются воплощением идей аккордной клавиатуры (то есть, клавиатуры для работы вслепую). Мышь, изначально создаваемая в качестве дополнения к аккордной клавиатуре, фактически её заменила.
В некоторые мыши встраиваются дополнительные независимые устройства — часы, калькуляторы, телефоны.
Ска́нер, иногда ска́ннер (англ. scanner, от scan — пристально разглядывать, рассматривать): в общем смысле — устройство или программа, осуществляющие сканирование, т.е. исследование объекта, наблюдение за ним или считывание его параметров.
Ручные сканеры
Это портативный вариант для тех, кто ведет активную бизнес-жизнь. Получаемые изображения имеют невысокое качество, но это мало смущает владельцев, которых больше интересует мобильность устройства.
Из всех видов сканеров ручной — самый недорогой и удобный. Его можно использовать отдельно от компьютера, все отсканированные изображения сохраняются на карте памяти.
Некоторые из ручных сканеров дают своему владельцу множество возможностей: отсканировать цветное изображение, ч/б, монохромное, задать глубину цвета.
Плюсы ручного сканера:
Мобильность;
Компактность;
Самодостаточность.
Минусы:
Низкое качество получаемых изображений;
Возможность перекоса при сканировании.
Планшетные сканеры
Самые распространенные устройства — это уже упомянутые выше планшетные сканеры. Столь популярными они стали за счет трех свойств, которыми обладают:
Достаточно высокого качества изображения;
Удобство в использовании;
Привлекательной стоимости.
Выглядит планшетный принтер так: плоское прямоугольное устройство с откидывающейся крышкой. Крышка поднимается, на стекло кладется документ, крышка закрывается, нажимается кнопка «сканировать». К компьютеру он подключается через USB порт.
Барабанные сканеры
Используются в основном в полиграфии для сканирования снимков и получения высококачественных изображений.
Этот аппарат — самый профессиональный из всех видов сканеров. В домашних условиях получить сканирование такого уровня невозможно, так как барабанные сканеры обладают солидными габаритами и пугающей стоимостью.
Сейчас производители планшетных сканеров стараются достичь уровня барабанных устройств, но пока им это не удалось.
Сканеры для штрих-кодов
Обзор вида сканеров был бы не полон без сканеров для штрих-кода: эти устройства вы регулярно видит в супермаркетах, когда оплачиваете на кассе покупки.
Это небольшой, похожий на лазерный пистолет сканер держит в руках кассирша, пробивая товары.
12. Монито́р — устройство, предназначенное для визуального отображения информации. Современный монитор состоит из корпуса, блока питания, плат управления и экрана. Информация (видеосигнал) для вывода на монитор поступает с компьютера посредством видеокарты, либо с другого устройства, формирующего видеосигнал.
Виды мониторов
Мониторы бывают:
· цветные и монохромные. В цветных изображение формируется светящимися точками красного, зеленого и синего люминофора, а в монохромных – точками люминофора одного цвета (чаще всего белого, зеленого или коричневого). Монохромные мониторы используются для ввода данных, в кассовых аппаратах и т.д. В большинстве приложений цветные мониторы предпочтительнее;
· различного размера - чаще всего от 14 до 21 дюйма. Размер монитора, по сложившейся традиции, определяется по величине диагонали его кинескопа. Следует иметь в виду, что диагональ поля изображения меньше на 5%-10%. В настоящее время в нашей стране наиболее распространены мониторы размером 14 дюймов, но предпочтительнее использовать мониторы с большей диагональю и соответственно с большим разрешением, т.е. наносящим меньший вред пользователю. Поэтому для пользователей, проводящих много времени за компьютером лучше иметь монитор размером не менее 17 дюймов. В издательских, конструкторских и иных применениях используются мониторы размером 20 – 21 дюйм, хотя они значительно дороже;
· с различным зерном, то есть расстоянием между центрами точек люминофора (светящегося вещества) одного цвета. Размер зерна во многом определяет качество монитора и четкость показываемого им изображения. На качественных мониторах размер зерна – 0,25-0,26 мм, на мониторах «среднего качества» - 0,28 мм, на низкокачественных мониторах – 0,31 - 0,39 мм или даже больше.
Каждый монитор обладает техническими характеристиками, которые определяют параметры и режимы его работы. От этих характеристик напрямую зависит качество, а также цена монитора.