

Языки и грамматики
Пусть А - алфавит (это обычное множество каких-либо элементов), элементы называются символами алфавита. В данном случае алфавит это немножко не то что мы под ним понимаем, - это произвольное непустое множество элементов призвольного типа (например, алфавит Z - алфавит целых чисел).
Подмножество множества конечных цепочек символов называется языком над алфавитом. Естественно, что над заданным алфавитом можно построить бесконечное множество языков. Рассмотрим пример алфавита построения алфавита арифметических выражений:
А = {a,b,+,-,(,)} - алфавит из 6 символов (сразу заметим, что символ "," не является сиволом алфавита А). Соответственно, нашему языку принадлежат выражения вида: a, a+b, (a)+b-a, но не принадлежат, например, такие (a, (), -a+b. Последнее не принадлежит языку потому, что перед a стоит унарный минус, что недопустимо (чтобы это выражение было в языке необходимо ввести в алфавит унарный плюс и унарный минус.
Грамматика:
Метаалфавит - это какой либо другой алфавит, не пересекающийся с А, состоящий из метасимволов. При этом один из метасимволов выделяется отдельно и называется главным. Существует множество методов задания грамматики. Мы рассмотрим только один способ задания грамматики. В этой грамматике используются предложения вида:
метасимвол ::= цепочка символов и метасимволов
Символ ::= означает "по определению есть", и не является символом ни
алфавита, ни метаалфавита. Зададим метаалфавит: М = {c,d,e} (считаем, что c - главный)
Зададим грамматику для нашего примера:
e::=+
e::=-
d::=a
d::=b
c::=d
c::=(c)
c::=cec
Один и тот же язык можно описать с помощью разных грамматик. Если заменить символ c на c::=cecec - язык не измениться, а грамматика измениться. Однако, как можно заметить, что этот способ задания грамматики является рекурсивным и может зациклится. Чтобы избежать этой ситуацию введем грамматику без зацикливаний - так называемую нотацию Бэкуса-Наура. В ней дополнительно нужны следующие символы:
1) | - или, благодаря этому оператору можно намного проще и короче
задавать нотации. Например, символ e задается e::=+|-
2) <название метасимвола> - для более естественной записи. В нашем
случае нам необходим метаалфавит М = {<знак>,<переменная>,
<формула>}, считаем, что <формула> - главный метасимвол.
Перепишем нотацию:
<знак>::=+|-
<переменная>::=a|b
<формула>::=<переменная> | (<формула>) | <формула><знак><формула>
Это также грамматика, но записанная по-другому. Форма представления в ней рекурсивная, но отсутствуют такие необходимые элементы как циклы, которые очень важны при нисходящем разборе.
Расширение нотации Бэкуса-Наура.
Нотации Бэкуса-Наура достаточно для изображения синтаксиса языка, но она не дает возможности написать грамматику для метода нисходящего разбора. Для этого нам не хватает понятия цикла.
Введем дополнительные символы:
1) {} - выбор одной из альтернатив;
{a|b} - выбирается либо a, либо b
2) [] - выбор одной из альтернатив, либо пусто;
[a|b] - выбирается либо a, либо b, либо пусто
3) {}* - цикл 1 или более раз;
{a|b}* - слово произвольной длины из символов a и b
4) []* - цикл 0 или более раз;
[a|b]* - слово произвольной длины из символов a и b или пусто
Пример:
Необходимо написать грамматику для формулы. В формулу входят:
имена переменных, десятичные числа;
круглые скобки;
знаки операций (с учетом приоритета и ассоциативности):






 +(1),-(1)
*
/ +(2),-(2)
+(1),-(1)
*
/ +(2),-(2)
(a) (б) (в) (г)
Прежде чем составлять грамматику напишем несколько неверных предложений с наиболее употребимыми ошибками:
<формула> ::= <операнд Р>[{+|-}<формула>]
В данном предложении операция может быть вычислена только после вычисления формулы, т.е. операции будут вычисляться справа на лево, что не отвечает левой ассоциативности.
<формула> ::= <формула>[{+|-}<операнд P>]
Данное предложение леворекурсивно, но при нисходящем разборе произойдет зацикливание.
Теперь напишем верную грамматику.
<формула> ::= <операнд P>[{+|-}<операнд P>]*
<операнд P> ::= <операнд D>[/<операнд P>]
<операнд D> ::= <операнд M>[*<операнд M>]*
<операнд M> ::= <операнд E>|{+|-}<операнд M>
<операнд E> ::= <число>|<переменная>|(<формула>)
Таким образом мы реализовали формулу, как совокупность чисел и переменных с определенными операциями, части которой соединены скобками.
<переменная> ::=<буква>[<буква>|<цифра>]*
<число> ::= {<цифра>}*[.{<цифра>}*][{E|e}[+|-]{<цифра>}*]
<цифра> ::= 0|1|2|3|4|5|6|7|8|9
<буква> ::= _|A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z|
a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z
В программе будет использоваться данная грамматика. Все метасимволы, кроме буквы и цифры будут реализованы как процедуры, а буква и цифра как множества.
Методология программирования.
Методологии можно классифицировать по разным признакам.
Например, по признаку внутренней структуры:
функциональные (большая программа как совокупность подпрограмм);
объектные (программа – совокупность взаимодействующих объектов);
объектно-ориентированные.
Объекты, подпрограммы и программы будем называть модулями.
Методологии:
Нисходящая (сверху - вниз), т. е. сначала пишутся модули верхних уровней иерархии, а потом нижних.
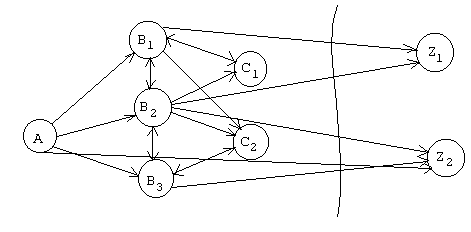
Функционирование модуля A состоит из вызовов базовых модулей и модулей B1, B2, B3. При этом могут возникать рекурсии на верх. Легко видеть, что модули каждого уровня используют средства языка, друг друга и ранее написанные модули.
При этом не нужно путать стратегию нисходящего проектирования с методом пошаговой детализации, так как метод нисходящего разбора – метод построения большой программной системы.
В методе нисходящего разбора прежде всего контролируется правильность интерфейса. И мы можем продемонстрировать работу программной системы до ее завершения. В этом случае, если средства для работы еще не написаны, то можно использовать имитаторы (заглушки).
Восходящая (снизу-вверх)
В этом случае необходимо построить модуль A на базе модулей Z.
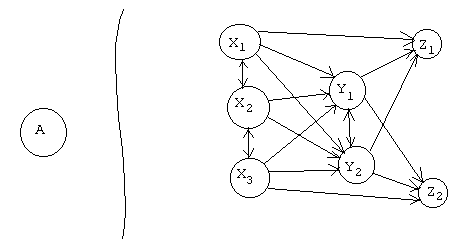
Модули каждого уровня используют модули более низких уровней и друг друга. При этом основным неудобством данного метода является отсутствие уверенности в том, что мы доберемся до A. Восходящая методология имеет смысл когда общая структура априоре известна. Например в случае разработки компилятора.
Вывод: Если создается система, имеющая подходящий аналог, то лучше использовать восходящую методологию, а в противном случае нисходящую.
3) Смешанная (реально используется на практике).
Компиляция формулы методом нисходящего разбора.
Поток – объект преобразующий формулу к виду необходимому объекту. Поток может быть глобальным к компилятору, а может быть его параметром. Гораздо удобнее когда поток не зависим от компилятора. При этом каждый метод компилятора должен иметь параметр потока, по этому разумнее передать параметр инициализирующей части компилятора, и в качестве поля запомнить имя потока.
Program CompileFormula;
uses Crt, AComp, AStream;
var DN:string;
pst:PFStreamTxt;
c:CComp;
begin
ClrScr;
writeln('Откуда формула');
read(Dn);
new(PSt,Create(DN));
c.Init(PSt);
c.Compile;
c.Done;
dispose(Pst,Destroy);
end.
Unit AComp;
interface
uses AStream;
Type PComp = ^CComp;
CComp = object
public
constructor Init(PS:PFStreamTxt);
destructor Done;virtual;
procedure Compile;
private
p:PFStreamTxt;
procedure Failure(n:word);
procedure Formula;
procedure OperandP;
procedure OperandD;
procedure OperandM;
procedure OperandE;
procedure Number;
procedure Variable;
end;
implementation
uses crt;
constructor CComp.Init;
begin
p:=ps;
end;
destructor CComp.Done;
begin
p:=nil;
end;
Procedure CComp.Compile;
begin
ClrScr;
writeln('Pro.Create');
if p^.IsEnd then Failure(1);
Formula;
if not p^.IsEnd then Failure(2);
writeln('Pro.ShowResult');
writeln('Pro.Destroy');
end;
Procedure CComp.Formula;
{Откомпилировать самую большую не пустую формулу с данной позиции в потоке}
(* <Formula>::=<OperandP>[{+,-} <OperandP>]* *)
{Нашей задачей является перевод этого выражения на язык Pascal}
var x:char;
begin
if p^.IsEnd then Failure(11); {Формула оказалась пустой - это ошибка}
OperandP; {Вызываем обработку операнда P}
while true do {Организация бесконечного цикла}
begin
if p^.IsEnd then break; {Если поток пуст, то выходим из цикла}
x:=p^.GetChar; {берем символ из потока, по грамматике он должен быть
либо + или -, поэтому далее проверяем на соответствие этому}
case x of
'+':begin p^.skip; OperandP; writeln('Pro.Add'); end;
'-':begin p^.skip; OperandP; writeln('Pro.Sub'); end;
else break; {Если не то и не другое, то выходим из цикла - может быть
это закрывающая скобка}
end;
end;
{Если поток не пуст и оставшийся символ не закрывающая скоба, то
генерируем ошибку. Обратите внимание, что сначала необходимо
проверить поток на пустоту, а уже в следующем вложенном if.
Если написать, например, так
if not p^.IsEnd and not (p^.GetChar in [')']) then failure (12);
то можно получить сообщение об ошибке потока, т.к. сначала
поток провериться на пустоту и независимо от того пуст он или полон
из него будет взят символ (т.е. происходи полное вычисление логических
выражений) }
if not p^.IsEnd then
if not (p^.GetChar in [')']) then failure (12);
end;
Procedure CComp.OperandP;
(* <OperandP>::=<OperandD>[ / <OperandP> ] *)
var x:char;
begin
{Если поток пуст, то генерируем ошибку}
if p^.IsEnd then Failure(21);
OperandD; {Вызываем операнд D}
{Если поток оказался не пуст, то тут возможно 2 ситуации:
1) Далее идет знак / , а за ним опять операнд P
2) Далее идет лексема не имеющая никакого отношения к операнду P}
if not p^.IsEnd then
begin
x:=p^.GetChar;
if x='/' then begin p^.skip; OperandP; writeln('Pro.Div'); end;
{Если x это / - то получаем первый случай}
end;
if not p^.IsEnd then
if not (p^.GetChar in [')','+','-']) then failure (22);
{Если далее идет не )+- то это ошибка}
end;
Procedure CComp.OperandD;
(* <OperandD>::= <OperandM> [* <OperandM>]* *)
var x:char;
begin
if p^.IsEnd then Failure(31);
OperandM;
while true do
begin
if p^.IsEnd then break;
x:=p^.GetChar;
case x of
'*':begin p^.skip; OperandM; writeln('Pro.Mul'); end;
else break;
end;
end;
if not p^.IsEnd then
if not (p^.GetChar in [')','+','-','/']) then failure (32);
end;
Procedure CComp.OperandM;
var x:char;
begin
{Полностью аналогичен Formula, правда было бы рациональнее вместо
конструкции case использовать if... , но ради сохранения стиля
оставляем все как есть}
if p^.IsEnd then Failure(41);
x:=p^.GetChar;
case x of
'+':begin p^.skip; OperandM; end;
'-':begin p^.skip; OperandM; writeln('Pro.Inv'); end;
else OperandE;
end;
if not p^.IsEnd then
if not (p^.GetChar in [')','+','-','/','*']) then failure (42);
{Обратите внимание, что число знаков увеличилось из-за того что
надо проверять еще и на все предыдущие операции}
end;
{Для работы с операндом E потребуются дополнительно константы-цифры и
константы-буквы идентификатора}
const Digits:set of char = ['0'..'9'];
Letters:set of char = ['_','A'..'Z','a'..'z'];
Procedure CComp.OperandE;
(* <OperandE>::=<Number> | <Variable> | (<Formula>) *)
var x:char;
begin
if p^.IsEnd then Failure(51); {поток не пуст?}
{берем символ из потока}
x:=p^.Getchar;
if x in digits then Number {Если x-цифра, то считываем число}
else if x in Letters then Variable {Если x-буква, то считываем идентификатор}
else if x='(' then {если x - открывающая скобка, то ...}
begin
p^.skip; Formula; {пропускаем символ, вызываем обработку формулы}
if p^.IsEnd then Failure(52) else {Если поток закончен то ошибка, иначе}
if not (p^.GetChar in [')']) then failure (53) {Считываем символ}
else p^.skip; {Если это ), то все в порядке, иначе выдаем ошибку}
end else failure(54);
end;
Procedure CComp.Variable;
(* <Variable>::=<Letters> [ <Letters>|<Digits> ]* *)
var x:char;
begin
if p^.IsEnd then Failure(61);
x:=p^.GetChar;
if not (x in Letters) then Failure(62);
{Если x - не буква, то точно ошибка}
write('Pro.LoadR(',x); p^.skip;
while true do {Бесконечный цикл, в котором считывается идентификатор}
begin
if p^.IsEnd then Break;
{Если вы хотите игнорировать символы табуляции в имени идентификатора, то
комментарий ниже необходимо убрать}
{ if p^.IsAfterSpace then break;}
x:=p^.GetChar;
if x in letters+digits then
begin
writeln(x); p^.skip;
end else break;
end;
writeln(')');
if not p^.IsEnd then Failure(52) else
if not (p^.GetChar in [')','+','-','/','*']) then failure (63);
end;
{Можно было точно так же написать считывания числа, но мы пойдем по другому пути. Следующая процедура работает по методу конечного автомата. Это очень мощный механизм организации работы. Суть данного метода в том, что в каждый момент времени фиксируется состояние алгоритма(исполнителя). Он будет находится в этом состоянии пока не произойдет фиксированное событие, изменяющее состояние алгоритма(исполнителя). В нашем случае
это будет определенный символ (или его отсутствие).
Для нашего алгоритма число возможных состояний равно 6:
1...9 . 1...9 E + 1...9
----- - ----- - - ----- -
1 2 3 4 5 6 7
1 состояние - считываются цифры (до первого нецифрового обозначения),
после чего осуществляется переход во 2 состояние
2 состояние - считывается точка(если есть) и переход в состояние 3
3 состояние - считываются цифры (до первого нецифрового обозначения),
после чего осуществляется переход во 4 состояние
4 состояние - считывается E (обозначение экспоненты) и переход в
состояние 5
5 состояние - считывается или + или - после чего переход в 6 состояние
6 состояние - считываются цифры (до первого нецифрового обозначения),
после чего осуществляется переход во 7 состояние
7 состояние - конец работы
Естественно, что если состояние не обнаруживает те символы, которые оно должно считать, то осуществляется переход в следующее состояние. Использование метода конечных автоматов в этом случае - это излишество, но оно приведено здесь с целью ознакомления с алгоритмом
}
procedure CIntr.Number;
function dig(c:char):byte;
begin
if c in digits then
dig:=ord(c)-ord('0')
else
dig:=0;
end;
var
x : char;
s : byte;
sign:shortint;
frc,
pow,num :double;
begin
if p^.IsEnd then failure(71);
x:=p^.GetChar;
if not (x in digits) then failure(72);
write('Pro.LoadR(');
s:=1;
num:=0;
pow:=0;
frc:=0.1;
sign:=1;
while s<>0 do
case s of
1 : begin
write(x);
num:=num*10+dig(x);
p^.Skip;
if p^.IsEnd then s:=0
else
begin
x:=p^.GetChar;
if x='.' then s:=2
else
if x in ['e','E'] then s:=4
else if not (x in digits) then s:=0;
end;
end;
2 : begin
write('.');
p^.Skip;
if p^.IsEnd then s:=0
else
begin
x:=p^.GetChar;
if x in digits then s:=3
else
if x in ['e','E'] then s:=4
else
failure(75);
end;
end;
3 : begin
write(x);
num:=num+frc*dig(x);
frc:=0.1*frc;
p^.Skip;
if p^.IsEnd then s:=0
else
begin
if x in ['e','E'] then s:=4
else
if not (x in digits) then s:=0;
end;
end;
4 : begin
write(x);
p^.Skip;
if p^.IsEnd then failure(76);
x:=p^.GetChar;
if x in digits then s:=6
else
if x in ['+','-'] then s:=5
else failure(77);
end;
5 : begin
write(x);
if x='-' then sign:=-1;
p^.Skip;
if p^.IsEnd then failure(78);
x:=p^.GetChar;
if x in digits then s:=6
else failure(79);
end;
6 : begin
write(x);
pow:=pow*10+dig(x);
p^.Skip;
if p^.IsEnd then s:=0
else
begin
x:=p^.GetChar;
if not (x in digits) then s:=0;
end;
end;
end;
writeln(')');
num:=num*exp(ln(10)*sign*pow);
pro^.LoadR(num);
if not p^.IsEnd then
if not (p^.GetChar in [')','+','-','*','/']) then failure(80);
end;
Procedure CComp.Failure;
{Фатальный обработчик ошибок}
begin
write('Ошибка компилятора # ',n:1,' в методе ');
case n of
1..10:writeln('Compile');
11..20:writeln('Formula');
21..30:writeln('OperandP');
31..40:writeln('OperandD');
41..50:writeln('OperandM');
51..60:writeln('OperandE');
61..70:writeln('Variable');
71..80:writeln('Number');
end;
case n of
1:writeln('Пустой текст');
11,21,31,41,51,61,71:writeln('Нет операнда');
{..и т.д.}
end;
Halt(1);
end;
begin
end.