

Хранение текста
С самого своего изобретения основной задачей компьютеров стало хранение и обработка информации. Если учесть, что большая часть информации представляет собой последовательность символов, то необходимость создания строковых типов возникла достаточно быстро. В основном задачу хранения символов можно решить следующим образом:
1) Массивы символов, т.е. данные хранятся в массиве, но этот тип хранения не очень удобен, т.к. слова состоят из разного числа символов и большая часть памяти просто не используется
2) Строки - самый удобный способ хранения, но реализовать его можно по-разному:
а) строка с первым значимым символом - это массив символов, первый элемент которого содержит длину строки. В языке Turbo Pascal для компьютеров IBM PC максимальная длина такой строки составляет 256 байт. Но как легко заметить большая часть памяти теряется.
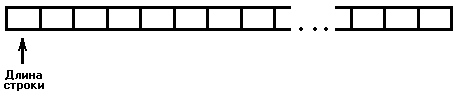
б) строка с завершающим нулевым (null) символом - это последовательность символов в конце которой стоит символ с кодом #0. Основные достоинства этого способа хранения информации - отсутствие мусора, динамическое изменение размера строки (такой тип реализован в C, в последней версии Turbo Pascal 7.0 в рамках типа PChar).

Из этого следует, что строки требуют для своего хранения на 1 байт больше, чем нужно. Т.е. если нужна строка в n символов, то ее настоящая длина в памяти будет (n+1) символ.
Арифметические данные
Обработка числовой информации на ЭВМ, как правило, происходит следующим образом. Поскольку исходные данные и результаты записываются в привычной для людей десятичной системе, а ЭВМ работает с двоичными числами, то при вводе числа переводятся в двоичную систему, после чего происходит обработка двоичных чисел, а при выводе результаты переводятся в десятичную систему. При этом на перевод чисел из одной системы в другую, естественно, тратиться время. Но если исходных данных и результатов немного, а их обработка занимает значительное время, тогда затраты на перевод не очень заметны.
Однако есть класс задач (например, коммерческие), для которых характерен ввод большого массива числовых данных с последующим применением к ним всего одной-двух арифметических операций и выводом также большого количества результатов. В этих условиях переводы чисел из десятичной системы в двоичную и обратно могут занять львиную долю общих затрат времени, что, конечно, невыгодно. С учетом этого в компьютерах предусматривается специальное представление целых чисел, при котором они фактически не отличаются от записи чисел в десятичной системе и которое потому практически не требует перевода чисел из внешнего представления во внутреннее и обратно, и предусмотрены команды арифметических операций над такими числами. Данное представление чисел называется двоично-десятичным (binary coded decimal, BCD-числа) и строятся по следующему принципу: берется десятичная запись числа и каждая его цифра заменяется на 4 двоичные цифры (от 0000 до 1001), обозначающие эту цифру в двоичной системе.
Различие между двоичными и двоично-десятичными представлениями чисел проявляется в том, что если в двоичном представлении за основу берется величина числа (независимо от того, как именно вначале оно было записано), то в двоично-десятичном представлении за основу берется запись числа, причем именно в десятичной форме (если число записать в другой системе, скажем в семеричной, то получилось бы иное представление).
Примеры представления:
Intel *86: различаются неупакованные (1 цифра - 1 байт) и упакованные
(2 цифры - 1 байт) десятичные цифры.
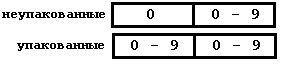
Упакуем, например, число 13 которое в двоичном виде записывается как 00001011, а в двоично-десятичном оно будет выглядеть как 00010011. Чтобы в двоично-десятичном числе был еще и знак, добавляют еще один байт, который считается знаковым. В пример приведу неупакованное девятизначное число со знаком:
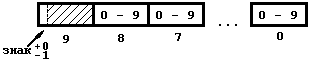
IBM-370:
Совершенно иначе десятичные данные реализованы в этих процессорах.
Н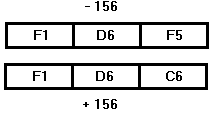 еупакованные
данные представляют собой объединение
байт размером до 16 байт. При записи
десятичное число разбивается на
десятичные цифры записи и каждая из них
записывается в отдельный байт. При этом
каждый байт в шестнадцатеричной записи
выглядит как F*(16)
, где * - десятичная цифра. При этом
последний байт является знаковым и
записывается в шестнадцатеричной
системе как D*(16)
если число отрицательное и C*(16)
если число положительное. Для примера
запишем числа +156(10)
и –156(10)
в таком виде.
еупакованные
данные представляют собой объединение
байт размером до 16 байт. При записи
десятичное число разбивается на
десятичные цифры записи и каждая из них
записывается в отдельный байт. При этом
каждый байт в шестнадцатеричной записи
выглядит как F*(16)
, где * - десятичная цифра. При этом
последний байт является знаковым и
записывается в шестнадцатеричной
системе как D*(16)
если число отрицательное и C*(16)
если число положительное. Для примера
запишем числа +156(10)
и –156(10)
в таком виде.
У пакованные
данные также представляют собой
объединение байт размером до 16 байт. В
них десятичное число записывается
немного в другом виде. Теперь в каждый
байт записывается не по одной цифре, а
по две. Последний байт, как и в прошлой
конструкции, играет роль знакового и
представляет собой шестнадцатеричную
запись *D(16)
если число знаковое и *C(16)
если беззнаковое (где * - последняя цифра
в записи числа).
пакованные
данные также представляют собой
объединение байт размером до 16 байт. В
них десятичное число записывается
немного в другом виде. Теперь в каждый
байт записывается не по одной цифре, а
по две. Последний байт, как и в прошлой
конструкции, играет роль знакового и
представляет собой шестнадцатеричную
запись *D(16)
если число знаковое и *C(16)
если беззнаковое (где * - последняя цифра
в записи числа).