

8.2.3. Иерархический кластерный анализ
Из всех методов кластерного анализа самыми распространенными являются иерархические агломеративные методы. Сущность этих методов заключается в том, что на первом шаге каждый объект выборки рассматривается как отдельный кластер. Процесс объединения кластеров происходит последовательно: на основании матрицы расстояний или матрицы сходства объединяются наиболее близкие объекты. Если матрица сходства первоначально имеет размерность т т, то полностью процесс кластеризации завершается за т – 1 шагов, в итоге все объекты будут объединены в один кластер. Последовательность объединения легко поддается геометрической интерпретации и может быть представлена в виде графа-дерева (дендрограммы). На дендрограмме указываются номера объединяемых объектов и расстояние (или иная мера сходства), при котором произошло объединение (рис. 8.12).
Дендрограмма на рисунке показывает, что в данном случае на первом шаге были объединены в один кластер объекты n2 и n3. Расстояние между ними 0,15. На втором шаге к ним присоединился объект п1. Расстояние от первого объекта до кластера, содержащего объекты n2 и n3, было 0,3 и т. д.

Рис. 8.12. Пример дендрограммы иерархического агломеративного кластерного анализа
Множество методов иерархического кластерного анализа различаются не только используемыми мерами сходства (различия), но и алгоритмами классификации. Из них наиболее распространены: метод одиночной связи, метод полных связей, метод средней связи, метод Уорда.
Метод одиночной связи. Алгоритм образования кластеров следующий: на основании матрицы сходства (различия) определяются два наиболее схожих или близких объекта, они и образуют первый кластер. На следующем шаге выбирается объект, который будет включен в этот кластер. Таким объектом будет тот, который имеет наибольшее сходство хотя бы с одним из объектов, уже включенных в кластер. Например, имеется матрица евклидовых расстояний между объектами (табл. 8.9).
Таблица 8.9. Матрица евклидовых расстояний
|
№ п/п |
1 |
2 |
3 |
4 |
|
1 |
0 |
2,06 |
4,03 |
2,50 |
|
2 |
|
0 |
2,24 |
4,12 |
|
3 |
|
|
0 |
6,32 |
|
4 |
|
|
|
0 |
В
первый кластер будут включены первый
и второй объекты, так как расстояние
между ними минимальное (d12
= 2,06). На следующем
шаге к этому кластеру будет подключен
третий объект, так как расстояние
![]() .
.
На последнем шаге в кластер будет включен четвертый объект. Это показано на графике (рис. 8.13).
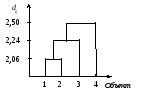
Рис. 8.13. Дендрограмма кластеризации четырех предприятий
При совпадении данных на основании одинаковых мер сходства (различия) будет идти образование сразу нескольких кластеров.
К достоинствам этого метода следует отнести нечувствительность алгоритма к преобразованиям исходных переменных и его простоту. Недостатками являются необходимость постоянного хранения матрицы сходства и невозможность определения по результатам кластеризации, сколько же кластеров можно образовать в исследуемой совокупности объектов.
Метод полных связей. Включение «нового» объекта в кластер происходит только в том случае, если расстояние между всеми объектами не больше некоторого заданного уровня С (рис. 8.14).

а)
б)
Рис. 8.14. Определение состава кластера при различных уровнях сходства наблюдаемых объектов: если задано предельное расстояние С=0,5, то третий объект не будет включен в кластер S, так как d23<0,5, а d13>0,5 (a); если задано предельное расстояние 0,7, то третий объект будет включен в кластер S, так как d13<0,7 и d23<0,7 (б)
Метод средней связи. Для решения вопроса о включении нового объекта в уже существующий кластер вычисляется среднее значение меры сходства, которое затем сравнивается с заданным пороговым уровнем. Для примера на рис. 8.14 в случае а) среднее расстояние (d13 + d23)/2 = (0,65 + 0,32)/2 = 0,485 < 0,5 – третий объект будет включен в кластер S; в случае б) среднее расстояние (d13 + d23) / 2 = = (0,64 + 0,57)/2 = 0,605 < 0,7, значит, третий объект будет включен в кластер S.
Если речь идет об объединении двух кластеров, то вычисляют расстояние между их центрами и сравнивают его с заданным пороговым значением. Рассмотрим геометрический пример с двумя кластерами (рис. 8.15).
Каждый кластер содержит по три объекта. Чтобы решить вопрос об объединении этих двух кластеров, нужно определить их центры тяжести и расстояние между ними. Звездочками (*) отмечены центры тяжести


Рис. 8.15. Объединение двух кластеров по методу средней связи
Если расстояние между центрами (dS1,S2) меньше заданного уровня, то кластеры S1 и S2 будут объединены в один.
Метод Уорда. Данный метод предполагает, что на первом шаге каждый кластер включает один объект. Первоначально объединяются два ближайших кластера. Для них определяются средние значения каждого признака и рассчитывается сумма квадратов отклонений Vk:
|
|
(8.11) |
где k – номер кластера;
i– номер объекта;
j – номер признака;
пk – количество объектов в k-м кластере;
р – количество признаков, характеризующих каждый объект.
В дальнейшем на каждом шаге работы алгоритма объединяются те объекты или кластеры, которые дают наименьшее приращение величины Vk. Метод Уорда приводит к образованию кластеров приблизительно равных размеров с минимальной внутрикластерной вариацией. В итоге все объекты оказываются объединенными в один кластер.
Алгоритм иерархического кластерного анализа можно представить в виде последовательности процедур.
Шаг 1. Значения исходных переменных нормируются одним из способов, указанных в разд. 8.2.2.
Шаг 2. Рассчитывается матрица расстояний или матрица мер сходства.
Шаг 3. Находится пара самых близких кластеров. По выбранному алгоритму объединяются эти два кластера. Новому кластеру присваивается меньший из номеров объединяемых кластеров.
Шаг 4. Шаги 2, 3 и 4 повторяются до тех пор, пока все объекты не будут объединены в один кластер, или до достижения заданного «порога» сходства.
Мера сходства для объединения двух кластеров в шаге 3 определяется четырьмя методами.
Метод «ближайшего соседа» – степень сходства оценивается по степени сходства между наиболее схожими (ближайшими) объектами этих кластеров (рис. 8.16).

Рис. 8.16. Определение расстояния между кластерами методом «ближайшего соседа»
Пусть d1 и d2 – евклидовы расстояния, тогда если d1 > d2, то S войдет в кластер U по d2.
Метод «дальнего соседа» – степень сходства оценивается по степени сходства между наиболее отдаленными (несхожими) объектами кластеров, тогда S войдет в кластер U по d1.
Метод средней связи – степень сходства оценивается как средняя величина степеней сходства между объектами кластеров. В этом случае S войдет в кластер U по d=1/2(d1 +d2).
Метод медианной связи – расстояние между любым кластером S и новым кластером, который получился в результате объединения кластеров р и q, определяется как расстояние от центра кластера S до середины отрезка, соединяющего центры кластеров р и q (рис.8.17).

Рис. 8.17. Определение расстояний между кластерами методом медианной связи
Использование различных алгоритмов объединения в иерархических агломеративных методах приводит к различным кластерным структурам и сильно влияет на качество проведения кластеризации. Поэтому алгоритм должен выбираться с учетом имеющихся сведений о существующей структуре совокупности наблюдаемых объектов или с учетом требований оптимизации математических критериев.
Если алгоритм иерархического кластерного анализа реализуется в программе для ЭВМ, то оценка сходства между кластерами дается только на основании значений dUS. Рассмотрим алгоритм иерархического кластерного анализа на примере.
Пример 8.5. Необходимо провести классификацию пяти предприятий, каждое из которых характеризуется тремя переменными: Х1 – среднегодовая стоимость основных производственных фондов, млрд руб.; Х2 – материальные затраты на 1 руб. произведенной продукции, к.; X3 – объем произведенной продукции, млрд руб. Значения переменных приведены в табл. 8.10.
Таблица 8.10. Исходные данные к примеру 8.5
|
Номер предприятия |
X1 |
X2 |
X3 |
|
1 |
120,0 |
94,0 |
164,0 |
|
2 |
85,.0 |
75,2 |
92,0 |
|
3 |
145,0 |
81,0 |
120,0 |
|
4 |
78,0 |
76,8 |
86,0 |
|
5 |
70,0 |
75,9 |
104,0 |
|
Среднее
значение ( |
99,6 |
80,6 |
113,2 |
|
Среднее квадратическое отклонение (σ) |
28,4 |
10,9 |
27,9 |
Перед тем как вычислять матрицу расстояний, нормируем исходные данные по формуле
|
|
|
Матрица значений нормированных переменных будет:
 .
.
Классификацию проведем при помощи иерархического агломеративного метода. Для построения матрицы расстояний воспользуемся евклидовым расстоянием. Тогда, например, расстояние между первым и вторым объектами
![]() .
.
Первоначальная матрица расстояний характеризует расстояния между отдельными объектами, каждый из которых на первом шаге является отдельным кластером:
 .
.
Как видно по элементам матрицы D0, наиболее близкими являются объекты n4 и n5 (d45 = 0,71). Объединим их в один кластер и присвоим ему номер S4. Пересчитаем расстояния всех оставшихся объектов (кластеров) до кластера S4, получим новую матрицу расстояний D1.
 .
.
В матрице D1 расстояния между кластерами определены по алгоритму «дальнего соседа». Тогда расстояние между объектом п1 и кластером S4
|
|
|
В матрице D1 опять находим самые близкие кластеры. Это будут S2 и S4, поскольку d24 = 1,93. Следовательно, на этом шаге объединяем кластеры S2 и S4; получим новый кластер, содержащий объекты n2, n4, n5. Присвоим ему номер S2. Теперь имеем три кластера S1{l}, S2{2,4,5}, S3{3}. Пересчитываем расстояния d12 и d23 получаем матрицу d2:
|
|
|
|
|
|
|
|
|
 .
.На следующем шаге объединяем кластеры S1 и S3 (d13 = 2,16) в один кластер и присваиваем ему номер S1. Теперь имеем только два кластера:
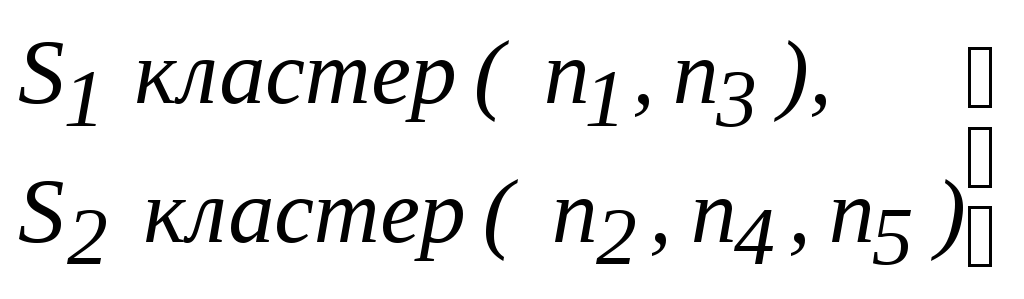 ,
,
![]() ;
;
|
|
(8.17) |
И, наконец, на последнем шаге объединяем кластеры S1 и S2 на расстоянии 4,49. Представим результаты классификации в виде дендрограммы (рис.8.18). Дендрограмма свидетельствует о том, что кластер S2 более однороден по составу входящих объектов, так как в нем объединение происходит при меньших расстояниях, чем в кластере S1.

Рис. 8.18. Дендрограмма кластеризации пяти объектов
Кроме рассмотренных агломеративных (объединяющих) методов иерархического кластерного анализа существуют методы, противоположные им по логическому построению процедур классификации. Они называются иерархические дивизимные (разделяющие) методы. Основной исходной посылкой дивизимных методов является то, что первоначально все объекты принадлежат одному кластеру (классу).

Рис. 8.19. Дендрограмма иерархического дивизимного алгоритма
В процессе классификации по определенным правилам постепенно от этого кластера отделяются группы схожих между собой объектов. Таким образом, на каждом шаге количество кластеров возрастает, а мера расстояния между кластерами уменьшается. Дендрограмма для дивизимных иерархических методов изображена на рис. 8.19.
Пример 8.6. Пусть дана следующая матрица расстояний между объектами:
 .
.
Проведем классификацию по дивизимному алгоритму.
Наиболее удаленными являются объекты п1 и n2; оценим расстояния оставшихся объектов до первого и второго объектов:
d31< d32 – объект n3 ближе к п1,
d41 > d42 – объект n4 ближе к n2,
d51 > d52 – объект n5 ближе к n2.
Итак, получили теперь два кластера: S1{l,3} и S2{2,4,5}. В каждом из них анализируем расстояния между объектами. На очередном шаге происходит разделение того кластера, где достигается максимум расстояния между объектами: d13= 2,16, d25 = 1,93, d24 = 1,92, d45 = 0,71. Наибольшее расстояние d13 = 2,16, следовательно, объекты п1 и n3 выделяем в отдельные кластеры. В кластере S2 {2,4,5} ищем максимальное расстояние max {d24,d25,d45}= 1,93. На следующем шаге из этого кластера выделяем объект n2, и, наконец, на последнем шаге разделяем кластер S3 {4,5} на два кластера на расстоянии 0,71.

Рис. 8.20. Дендрограмма кластеризации объектов по иерархическому дивизимному методу
Как видно из этого примера, дивизимный алгоритм не требует пересчета матрицы расстояний на каждом шаге классификации в отличие от агломеративных методов, что способствует снижению трудоемкости расчетов.