

Арифметическое сжатие
В материалах лекции 7 дана краткая характеристика алгоритма арифметического кодирования и, как недостаток, указывалось на сложность и объем вычислений, связанных с не целыми числами. В настоящее время данный алгоритм находит все более широкое применение, поскольку закончился срок патентных ограничений и его эффективность выше эффективности алгоритма Хаффмана на 10% в среднем.
Арифметическое сжатие – достаточно эффективный метод, в основе которого лежит идея представления кодируемого текста (последовательности) в виде дроби таким образом, чтобы текст был представлен как можно компактнее. Для примера рассмотрим построение такой дроби на интервале [0, 1], причем 0 – включая в интервал, а 1 – исключая. Разобьем интервал на подинтервалы с длинами, соответствующими вероятностям появления символов в тексте. Рассмотрим, как сжимается текст в соответствии с процедурами данного алгоритма, выбрав случайный отрывок текста: “ВОН ВОРОНА”. Распишем вероятности появления каждого символа в тексте в порядке убывания и соответствующие символам поддиапазоны в виде таблицы.
|
Символ |
Частота |
Вероятность |
Диапазон |
|
О |
3 |
0,3 |
(0,0; 0,3) |
|
B |
2 |
0.2 |
(0,3; 0,5) |
|
H |
2 |
0,2 |
(0,5; 0,7) |
|
Р |
1 |
0,1 |
(0,7; 0,8) |
|
А |
1 |
0,1 |
(0,8; 0,9) |
|
“ “ |
1 |
0,1 |
(0,9; 1,0) |
Для простоты обсуждения считаем, что эта таблица известна в кодере и декодере. Квантование заключается в уменьшении рабочего интервала. Для первого символа в качестве рабочего интервала берется (0, 1). Разобьем его на диапазоны в соответствии с частотами символов в таблице. В качестве следующего рабочего интервала берется диапазон, соответствующий текущему кодируемому символу. Его длина пропорциональна вероятности появления символа в потоке данных. Считываем следующий символ. В качестве исходного берем рабочий интервал, полученный на предыдущем шаге, и опять разбиваем его в соответствии с таблицей диапазонов. Длина рабочего интервала уменьшается пропорционально вероятности текущего символа, а точка начала сдвигается вправо пропорционально началу диапазона этого символа. Новый построенный диапазон берется в качестве рабочего и т. д. Графически процесс кодирования представлен на рис. 6.
h0
l1
h1 O B H P A





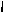


1
l2
h2
O







H







Рис. 6 Графическое представление процедур арифметического кодирования
И
l0 0
Исходный рабочий интервал (0, 1)
Символ “В ” (0,3; 0,5) получаем (0,3000; 0,5000).
Символ “О” (0,0; 0,3) получаем (0,3000; 0,3600).
Символ “Н” (0,5; 0,7) получаем (0,3300; 0,3420)
Символ “ “ (0,9; 1,0) получаем (0,3408; 0,3420).
Таким образом, окончательная длина интервала равна произведению вероятностей всех встретившихся символов, а его начало зависит от порядка следования символов в потоке. Если обозначить диапазон символа с как [a[c]; b[c]), а интервал для i –го кодируемого символа потока как [li, hi), то алгоритм сжатия может быть записан следующим образом
while L0=0; h0=1; i=0;
(not DataFile.EOF( ) {
c=DataFile.ReadSymbol( ); i++;
li=li-1 + a[c].(hi-1 - li-1);
hi = li-1 + b[c].(hi-1 –li-1);};
Большой вертикальной чертой на рисунке обозначено произвольное число, лежащее в полученном при работе интервале [li , hi). Для последовательности “ВОH”, состоящей из четырех символов, за такое число можно взять 0,341. Этого числа достаточно для восстановления исходной цепочки, если известна исходная таблица диапазонов и длина цепочки.
Рассмотрим работу алгоритма восстановления цепочки. Каждый следующий интервал вложен в предыдущий. Это означает, что если есть число 0,341, то первым символом в цепочке может быть только “B”, поскольку только его диапазон включает это число. В качестве интервала берется диапазон “В” – [0,3;0,5) и в нем находится диапазон [a[c]; b[c]), включающий 0,341. Перебором всех возможных символов по приведенной выше таблице находим, что только интервал [0,3; 0,36), соответствующий диапазону для “O”, включает число 0,341. Этот интервал выбирается в качестве следующего рабочего и т. д. Алгоритм декомпрессии можно записать так:
l0 = 0; h0 = l; value=Fiele. Code( );
for(i=1;
i![]() =Fiele.DataLength
( ); i++) {
=Fiele.DataLength
( ); i++) {
for (для всех сj) {
li = li-1 + a [cj].(hi-1 – li-1);
hi = li -1 + b[сj].(hi -1 - li -1 );
if
(( li
![]() =value)
& & (value
=value)
& & (value
![]() hi
)) break;
hi
)) break;
};
DataFile.WriteSimbol (cj);
};
Здесь value – прочитанное из потока число (дробь), а с – записываемые в выходной поток распаковываемые символы. При алфавита из 256 символов cj внутренний цикл выполняется достаточно долго, однако его можно ускорить. Поскольку b[cj+1] = a[cj] (cм. приведенную выше таблицу диапазонов) то li для cj+1 равно hI для cj, а последовательность h i для сj строго возрастает с ростом j. То есть количество операций во внутреннем цикле можно сократить вдвое, поскольку достаточно проверять только одну границу интервала. Если в последовательности мало символов, то, отсортировав их в порядке уменьшения вероятностей, можно сократить число итераций цикла и таким образом ускоряем работу декомпрессора. Первыми будут проверяться символы с наибольшей вероятностью, (в нашем примере с вероятностью 1/2 выход из цикла произойдет уже на втором символе из шести).
Если число символов велико, существуют другие методы ускорения поиска символов.