

Овчаренко_8
.pdfгде число — значение, для которого определяется процентное содержание;
значимость — количество значащих цифр в величине процентного содержания.
Например, если 1,15 — максимальное значение в массиве, то значение функции ПРОЦЕНТРАНГ равно 100,00%.
Функция ПЕРСЕНТИЛЬ возвращает k-ую персентиль для значений массива:
ПЕРСЕНТИЛЬ(массив;k),
где k — значение процентранга для искомого значения, задается в интервале от 0 до 1 включительно, кратное 1/(n — 1), в противном случае производится интерполяция.
Например, если в массиве 1,15 — максимальное значение, то для него процентранг равен 100%.
Тогда ПЕРСЕНТИЛЬ(Курс_ЦБ;100%) = 1,15.
Функция КВАРТИЛЬ вычисляет квартиль множества данных:
КВАРТИЛЬ(массив;часть),
где часть — тип возвращаемого значения: 0 — минимальное значение в массиве; 1 — первая квартиль (25% персентиль); 2 — медиана массива (50% персентиль); 3 — третья квартиль (75% персентиль); 4 — максимальное значение в массиве.
Например, КВАРТИЛЬ(Курс_ЦБ;4) = 1,15.
Ниже приведена таблица результатов, полученных различными информационными технологиями ранжирования применительно к массиву
Курс_ЦБ:
Результаты Пакета анализа |
Статистические функции |
|||||
|
|
|
|
|
|
|
Бочка |
Столбец |
Ранг |
Процент |
РАНГ |
ПРОЦЕНТ |
ПЕРСЕН |
РАНГ |
ТИЛЬ |
|||||
17 |
1,15 |
1 |
100,00% |
1 |
100,00% |
1,15 |
9 |
1,12 |
2 |
88,00% |
2 |
88,00% |
1,12 |
11 |
1,12 |
2 |
88,00% |
2 |
88,00% |
1,12 |
15 |
1,12 |
2 |
88,00% |
2 |
88,00% |
1,12 |
10 |
1,1 |
5 |
84,00% |
5 |
84,00% |
1,1 |
14 |
1,09 |
6 |
80,00% |
6 |
80,00% |
1,09 |
2 |
1,07 |
7 |
72,00% |
7 |
72,00% |
1,07 |
16 |
1,07 |
7 |
72,00% |
7 |
72,00% |
1,07 |
12 |
1,06 |
9 |
64,00% |
9 |
64,00% |
1,06 |
13 |
1,06 |
9 |
64,00% |
9 |
64,00% |
1,06 |
1 |
1,05 |
11 |
60,00% |
11 |
60,00% |
1,05 |
21 |
1,02 |
12 |
44,00% |
12 |
44,00% |
1,02 |
23 |
1,02 |
12 |
44,00% |
12 |
44,00% |
1,02 |
25 |
1,02 |
12 |
44,00% |
12 |
44,00% |
1,02 |
26 |
1,02 |
12 |
44,00% |
12 |
44,00% |
1,02 |
18 |
1,01 |
16 |
32,00% |
16 |
32,00% |
1,01 |
19 |
1,01 |
16 |
32,00% |
16 |
32,00% |
1,01 |
20 |
1,01 |
16 |
32,00% |
16 |
32,00% |
1,01 |
22 |
1 |
19 |
24,00% |
19 |
24,00% |
1 |
24 |
1 |
19 |
24,00% |
19 |
24,00% |
1 |
4 |
0,98 |
21 |
12,00% |
21 |
12,00% |
0,98 |
5 |
0,98 |
21 |
12,00% |
21 |
12,00% |
0,98 |
8 |
0,98 |
21 |
12,00% |
21 |
12,00% |
0,98 |
3 |
0,97 |
24 |
0,00% |
24 |
0,00% |
0,97 |
6 |
0,97 |
24 |
0,00% |
24 |
0,00% |
0,97 |
7 |
0,97 |
24 |
0,00% |
24 |
0,00% |
0,97 |
6.3. Гистограмма и функция распределения случайной величины
Значения ряда экономических показателей, имеющих случайный характер, можно охарактеризовать с помощью функции распределения вероятности случайной величины. Наиболее часто для этого осуществляется построение гистограмм, по оси абсцисс задается интервал значений, по оси ординат — частота значений, попадающих в интервал При построении
гистограмм выбирается количество и длина интервалов числовой оси Для определения числа интервалов чаще всего используется формула Стержесса
(Sturgess):
k =1+3.32 Lg n =1.44 Ln n +1.
При вычислении величины k производится округление до большего целого.
Для дискретных и непрерывных случайных величин часто используется кумулятивная функция распределения — вероятность того, что случайная величина не превосходит заданного значения, — которая принимает значения в интервале от 0 до 1 (0%—100%).
6.3.1. Информационная технология построения гистограмм в Пакете анализа
Данные для построения гистограммы должны быть представлены на рабочем листе в виде блока исходных данных и блока карманов — интервала отрезков Оба блока могут располагаться по столбцам или по строкам.
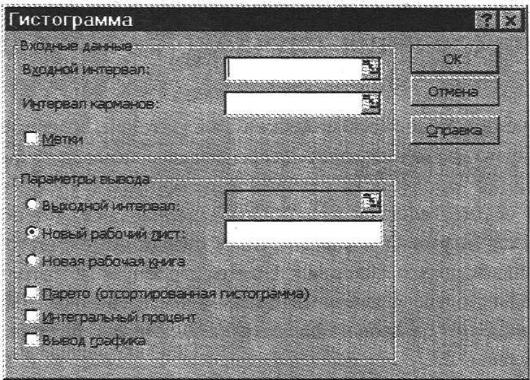
Команда Сервис, Анализ данных вызывает диалоговое окно Инструменты анализа, в котором выбирается режим Гистограмма. В диалоговом окне (рис. 6.3) задаются параметры:
Рис. 6.3. Диалоговое окно режима Гистограмма.
Входной интервал — блок ячеек;
Метки — если имя столбца или строки входит во входной интервал; Интервал карманов (отрезков) — блок ячеек, содержащих граничные
значения отрезков, для которых определяются частоты (вероятности) попадания случайной величины. Если интервал карманов не задается, автоматически создается набор равных отрезков в диапазоне от минимума до максимума;
Вывод графика — вывод гистограммы ряда распределения полученной частоты (вероятности) случайной величины. Значения ряда находятся в столбце Частота;
Интегральный процент — вычисление интегральной функции распределения. Результатом работы этого режима является появление в выходном блоке третьего столбца с именем Интегральный %, на гистограмме отображается соответствующий числовым данным столбца график функции распределения.
Парето — значения частот в выходной таблице и на гистограмме отображаются в порядке их убывания.
Вывод результатов анализа осуществляется в произвольное место: тот же рабочий лист, новый рабочий лист или новая рабочая книга. Выходная таблица содержит столбцы:
Карман — граничные значения отрезков; Частота—значения частоты попадания случайной величины в
соответствующий карман, при этом граница строится с включением значения отрезка "слева". При достаточном объеме выборки частота попадания в отрезок принимается за вероятность распределения;
Интегральный % — значения функции распределения вероятности (в процентном выражении).
Пример.
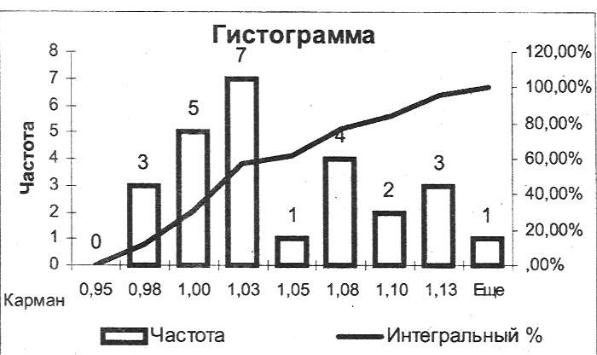
Частотный анализ значений Курса_ЦБ выполняется с использованием режима Гистограмма. Карманы созданы автоматически, использованы установки: Парето, Интегральный процент, Вывод графика.
Три столбца слева связаны с возрастающими значениями карманов. Три столбца справа связаны с убыванием значений в столбце Частота. График (рис. 6.4) отражает информацию первых трех столбцов таблицы, соответствующую возрастанию значений интервалов. Для 57,69% ценных бума! курс не превышает 1,05. Для второго графика (рис. 6.5) использованы правые три столбца таблицы, информация упорядочена по убыванию частотных характеристик. Так, наибольшая частота попадания в интервал 1,0— 1,03; затем в интервал 0,98—1,0 и т.д.
Карман |
Частота |
Интегральный % |
Карман |
Частот |
Интегральный % |
0,95 |
0 |
0,00% |
1,03 |
7 |
26,92% |
0,98 |
3 |
11,54% |
1,00 |
5 |
46,15% |
1,00 |
5 |
30,77% |
1,08 |
4 |
61,54% |
1,03 |
7 |
57,69% |
0,98 |
3 |
73,08% |
1,05 |
1 |
61,54% |
1,13 |
3 |
84,62% |
1,08 |
4 |
76,92% |
1,10 |
2 |
92,31% |
1,10 |
2 |
84,62% |
1,05 |
1 |
96,15% |
1,13 |
3 |
96,15% |
Еще |
1 |
100,00% |
Еще |
1 |
100,00% |
0,95 |
0 |
100,00% |
Рис. 6.4. Последовательные карманы.
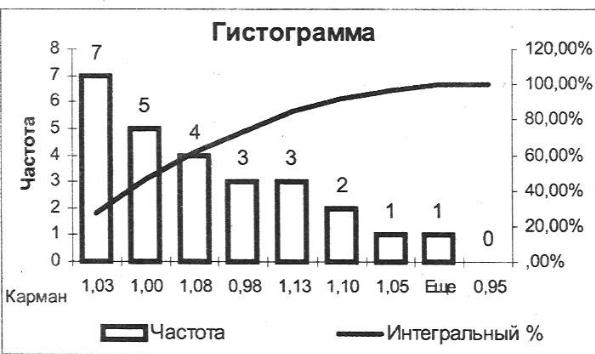
Рис. 6.5. Убывание частот попадания.
6.3.2. Информационная технология частотного анализа с использованием статистических функций
Функция ЧАСТОТА возвращает распределение частот в виде вертикального массива для множества значении и множества карманов:
ЧАСТО'ТА(массив_данных;массив_карманов),
где массив_карманов — массив или ссылка на множество интервалов, в которые 1ру11пируются значения аргумента массив_данных.
Функция ЧАСТОТА вводится как формула массива для интервала смежных ячеек, в которые нужно вернуть полученный массив распределения. Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве карманов.
Пример.
Подготовлен массив карманов произвольного размера:
0,950 |
0,975 |
1,000 |
1,025 |
1,030 |
1,050 |
1,100 |
1,125 |
1,150 |
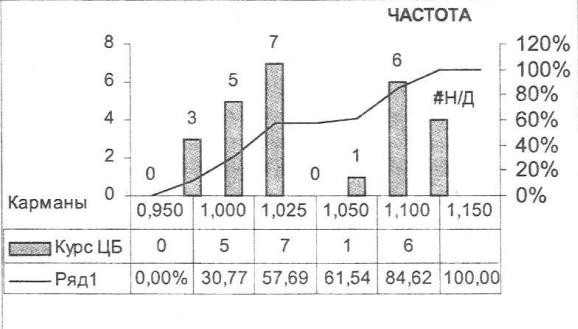
Введен массив формул ЧАСТОТА в виде: {=ЧАСТОТА(Курс_ЦБ, карман)}
в блок ячеек, высота которого по вертикали соответствует числу карманов. По результатам вычисления построены графики (рис. 6.6).
•частота попадания значений в указанные карманы (Курс_ЦБ);
•интегрального процента накопленной частоты (Ряд1).
Рис. 6.6. Частотный анализ значений для произвольных карманов.
6.4. Статистические методы изучения динамики и прогнозирования
6.4.1. Прогнозирование методом скользящего среднего
Данный метод прогнозирования применяется для процессов с незначительной вариацией средних значений для коротких периодов времени (например, для характеристики сбыта продукции, оценки запасов товаров). Все наблюдения временного ряда имеют вес, равный 1/п, безотносительно к тому, какое место они занимают в исходных данных. При достаточно больших п (n>25) добавление новых данных мало изменяет скользящую среднюю для предыдущего момента. Наиболее эффективно этот метод исследования реализуется с использованием информационной технологии
Пакета анализа, режим Скользящее среднее, хотя его возможно поддержать
и стандартными функциями обработки. При вызове режима Скользящее среднее появляется одноименное диалоговое окно, в котором задается:
Входной интервал — один столбец или строка, содержащий 4 или более ячейки данных;
Интервал — целое число, равное периоду осреднения N (по умолчанию — 3);
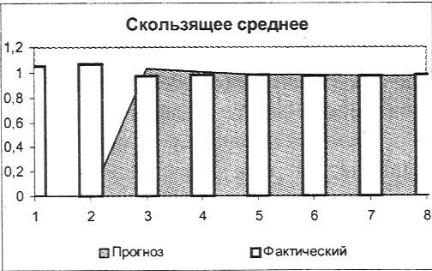
Вывод графика — автоматическая генерация графика типа гистограмма Скользящее среднее, отражает эмпирические данные (ряд Фактический) и сглаженные значения (ряд Прогноз);
Стандартные погрешности — стандартные погрешности для каждой точки ряда Прогноз, рассчитанные согласно формуле:
КОРЕНЬ(СУММКВРАЗН(блок1;блок2)/N),
где блок1 — исходные данные, блок2 — прогнозные данные; длина каждого блока — N ячеек.
Пример.
Результаты обработки ряда Курс_ЦБ для акций при использовании скользящего среднего представлены в выходной таблице, которая содержит два столбца:
•значение скользящей средней (Прогноз) — вычисляется как среднее значение для указанного количества ячеек;
•стандартная погрешность (Ошибка).
Рис. 6.7. Скользящее среднее курса ценных бумаг.
Прогноз |
Ошибка |
#Н/Д |
#Н/Д |
#Н/Д |
#Н/Д |
1,03 |
#Н/Д |
1,01 |
#Н/Д |
0,98 |
0,0380 |
0,98 |
0,0160 |
0,97 |
0,0047 |
0,97 |
0,0058 |
Константа #Н/Д означает Неопределенные данные, поскольку среднее значение и стандартная ошибка вычисляются для блока ячеек, величина которого равна периоду. Выходным данным соответствует одноименный график. Диаграмма скользящей средней показывает различие сглаженных и фактических значений данных. По оси абсцисс показаны номера учетных точек, по оси ординат — значения показателей Курс (прогноз) и Курс (фактический). Сглаженное значение показывает тенденцию изменения курса ЦБ.
6.4.2. Прогнозирование методом экспоненциального сглаживания
Экспоненциальная средняя обладает большей временной устойчивостью по сравнению со скользящей средней, в ее определении участвуют все наблюдения исходного ряда, но с разными весовыми коэффициентами. При этом зависимость очередного прогнозируемого значения от непосредственно предшествующих значений более сильна, чем от значений начального периода. Вычисление оценки эмпирического временного ряда производится по формуле:
|
|
Yi = (1−α) Yi −1 +α yi , |
где Yi |
— |
прогнозное значение для i-го периода; |
Yi-1 |
— |
прогнозное значение для (i—1)-го периода; |
yi |
— |
фактическое значение i-гo периода; |
0<α<1 — коэффициент экспоненциальною сглаживания.
Чем больше величина α, тем сильнее сказывается колебание ряда, и наоборот: чем меньше α, тем более система инерционна к фактическому значению и более учитывает прогнозное значение предыдущею периода.

При выполнении команды СЕРВИС, Анализ данных выбирается режим Экспоненциальное сглаживание, появляется одноименное диалоговое окно (рис. 6.8), в котором задается:
Входной интервал — один столбец или одна строка, содержащие четыре или более ячейки;
Фактор затухания — константа (1— α) сглаживания; по умолчанию при α = 0,3, (1 — а) = 0,7;
Метки — указываются, если строка или столбец входного интервала содержат метки;
Вывод графика — автоматическая генерация диаграммы для фактических и прогнозируемых значении;
Стандартные погрешности — значения погрешностей про-1ноза, рассчитываются с помощью формулы:
КОРЕНЬ(СУММКВРАЗН(блок1;блок2)/3).
Рис. 6.8. Диалоговое экспоненциалъное сглаживание.
Пример.
Для курса ЦБ на примере акций выполнено |
|
|
||||||
Прогноз |
Ошибка |
|||||||
экспоненциальное сглаживание. В результате получены |
||||||||
таблица и графики. |
|
|
|
#Н/Д |
#Н/Д |
|||
Выходная |
таблица |
содержит сглаженные по |
1,05 |
#Н/Д |
||||
1,06 |
#Н/Д |
|||||||
экспоненте значения показателя (Прогноз) и |
||||||||
1,00 |
#Н/Д |
|||||||
вычисленные погрешности (Ошибка). Константа #Н/Д в |
0,99 |
0,0565 |
||||||
столбце означает |
неопределенные данные, |
поскольку |
0,98 |
0,0554 |
||||
0,97 |
0,0129 |
|||||||
сглаженное |
значение |
вычисляется |
с |
учетом |
||||
0,97 |
0,0077 |
|||||||