

Овчаренко_8
.pdf6. Использование методов статистической обработки в среде EXCEL для задач бизнес-анализа
Для исследования экономической информации задач бизнес-анализа широко используются статистические методы обработки. Электронная таблица EXCEL содержит набор встроенных функций категории Статистические, а также предоставляет специальные информационные технологии, выполняемые в среде Пакета анализа. Команда меню СЕРВИС, Надстройки позволяет выбрать Пакет анализа. После установки Пакета анализа изменяется состав команд меню режима СЕРВИС — появляется новая команда Анализ данных.
6.1. Описательная статистика
Массивы экономических показателей характеризуются значениями средних величин различного вида, вариацией ряда, моментами распределения (начальные, центральные) и формой (законом) распределения.
Статистика различает два вида моментов случайной величины определенной степени:
•начальный — математическое ожидание случайной величины (mi);
•центральный — математическое ожидание отклонения случайной величины от математического ожидания (Mi).
В описательной статистике применяются следующие оценочные показатели значений случайной величины:
• средняя арифметическая — начальный момент первого порядка, математическое ожидание значений случайной величины при большом числе испытаний — x ;
• средняя квадратическая — начальный момент второго порядка—
xср.кв. ;
•средняя кубическая — начальный момент третьего порядка — xср.куб.;
•средняя геометрическая для оценки средних темпов роста случайных величин, нахождения значения признака, равноудаленного от минимального и максимального значения — xср.геом.;
•средняя гармоническая для определения средней суммы обратных величин — хср.гарм.;
Между средними величинами существует соотношение:
хср.гарм≤ xср.геом≤ x ≤ xср.кв≤ xср.куб
Для измерения рассеивания значений признака относительно математического ожидания используются другие показатели:
•Дисперсия — второй центральный момент, математическое ожидание квадрата отклонения случайной величины от ее математического ожидания.
•Среднее квадратическое отклонение — корень квадратный из дисперсии случайной величины.
Чем выше значения указанных величин, тем больше вариация случайной величины. Среднеквадратическое отклонение имеет ту же размерность, что и случайная величина, что облегчает сопоставление вариации значений.
•Средняя квадратическая ошибка средней с учетом размера выборки.
•Средний модуль отклонения — среднее значение абсолютной величины разности случайной величины и средней.
•Максимум (хmax ) — максимальное значение.
•Минимум (xmin) — минимальное значение.
•Наибольшее (k-e) — предшествующее максимуму значение с номером k.
•Наименьшее (k-e) — следующее после минимума минимальное значение с номером k.
•Интервал (I) — интервал значений случайной величины, равный
I= xmax − xmin .
•Мода — значение случайной величины, плотность вероятности которого максимальна.
•Медиана — значение случайной величины, при котором площадь, ограниченная кривой распределения, делится пополам
•Квартили распределения — подмножество данных с одинаковым числом элементов:
•0 — минимальное значение случайной величины;
•1 — первая четверть (квартиль), или 25% массива значений случайной величины;
•2 —медиана, вторая четверть, или 50% массива значении случайной величины;
•3 — третья четверть, или 75% массива значений случайной величины;
•4 — максимальное значение случайной величины.
•Доверительный интервал для значений случайной величины и заданного уровня надежности (альфа) значений. Если альфа = 0.05, для

нормальной кривой это значение равно |
x ±1,96 |
σ |
(т.е. в 95% случаев |
|
|
n |
|
значение случайной величины находится в указанном интервале, где σ — среднеквадратическое отклонение, п — число наблюдений).
•Форма распределения случайной величины, в том числе:
♦Степень асимметричности ряда или плотности распределения вероятности случайной величины относительно ее математического ожидания — асимметрия. Если распределение симметрично, то все центральные моменты нечетного порядка, в том числе и коэффициент асимметрии, равны нулю;
♦Крутизна ряда или плотности распределения вероятности — эксцесс, определяется через четвертый центральный момент. Для нормального распределения эксцесс равен 0, положителен для крутых кривых распределения и отрицателен для плоских по сравнению с нормальной плотностью распределения кривых.
•Сумма значений случайной величины.
•Среднее значение случайной величины.
Указанные показатели описательной статистики в EXCEL вычисляются по принятым в статистике формулам, с которыми можно ознакомиться в режиме справки к статистическим функциям.
6.1.1. Информационная технология описательной статистики на базе Пакета анализа
Исходные данные для анализа могут быть представлены на рабочем листе в виде списка значений. Как правило, для идентификации массива значений используются названия столбцов — метки, а также создаются именованные блоки.
При выполнении команды Сервис, Анализ данных вызывается диалоговое окно Анализ данных, в котором выбирается режим Описательная статистика (рис. 6.1); в одноименном диалоговом окне задаются установки:

Рис. 6.1. Диалоговое окно режима Описательная статистика.
Входной интервал — блок ячеек, содержащий значения исследуемого экономического показателя. Можно указать один или несколько смежных столбцов/строк ячеек, содержащих числовые данные для анализа, которые находятся в произвольном месте (этот же, другой лист этой или любой открытой рабочей книги);
Группирование — определяет ориентацию блока исходных данных на рабочем листе (по строкам или по столбцам);
Метки — наличие имен в блоке ячеек.
Вывод результатов описательной статистики осуществляется по месту указания (блок ячеек на листе с исходными данными, другой лист или новая рабочая книга).
Вывод описательной статистики осуществляется на тот же рабочий лист — указывается начальная ячейка выходного диапазона, на новый лист, для которого можно указать имя, или в новую рабочую книгу. Содержание вывода определяется установками:
Итоговая статистика — полный вывод показателей описательной статистики;
Уровень надежности — указывается процент надежности данных для вычисления доверительного интервала;
k-ый наименьший — порядковый номер наименьшего после минимального значения;
k-ый наибольший — порядковый номер наибольшего после максимального значения.
6.1.2. Информационная технология использования статистических функций EXCEL
EXCEL содержит статистические встроенные функции для расчета показателей описательной статистики:
СРЗНАЧ — среднее арифметическое значений массива, который может состоять из нескольких интервалов ячеек — максимум 30. При вычислении не учитываются ячейки диапазона, которые содержат пустые или текстовые значения (ноль является учитываемым значением).
СРЗНАЧА — среднее арифметическое значении массива. Помимо чисел в расчете могут участвовать текст и логические значения, такие как ИСТИНА (интерпретируется как 1) и ЛОЖЬ (интерпретируется как 0).
СРГЕОМ — средняя геометрическая величина массива или интервала положительных чисел.
СРГАРМ — средняя гармоническая величина множества данных. СЧЕТ — количество чисел в интервалах или массивах ячеек ДИСП — дисперсия по выборке для массива чисел (блока ячеек).
ДИСПР — дисперсия для генеральной совокупности:
СРОТКЛ — среднее абсолютных значений отклонений точек данных от среднего
СТАНДОТКЛОН — стандартное отклонение по выборке. СТАНДОТКЛОНП — стандартное отклонение по выборке по
генеральной совокупности.
МАКС и МИН — максимальное и минимальное значения из списка аргументов.
МЕДИАНА — медиана для массива чисел. Если количество чисел четное, функция МЕДИАНА возвращает среднее двух чисел, находящихся в середине множества.
МОДА — мода для массива чисел. Если множество данных не содержит одинаковых данных, то функция МОДА возвращает значение ошибки #Н/Д (нет данных).
СКОС — асимметрия распределения относительно среднего. Если имеется менее трех точек данных или стандартное отклонение равно нулю, то функция дает ошибку #ДЕЛ/0!.
ЭКСЦЕСС — эксцесс множества данных: Для нормального распределения эксцесс равен 3. Если задано менее четырех точек данных или
если стандартное отклонение выборки равняется нулю, то функция ЭКСЦЕСС возвращает значение ошибки #ДЕЛ/0! (деление на нуль).
КВАРТИЛЬ — квартиль множества данных. Массив не должен содержать более 65536 точек данных, принимает значения 0—4.
ДОВЕРИТ — доверительный интервал для среднего генеральной совокупности с заданным уровнем надежности (например, 95%).
Для удобства ввода формул следует массивы значений объявлять как именованные блоки.
Пример.
В качестве исходной статистической информации рассматривается база данных (список EXCEL) о котировке ценных бумаг на бирже, приведенная выше. Для удобства восприятия излагаемой информационной технологии эти данные приведены повторно. Для соответствующих столбцов списка целесообразно создать именованные блоки, включающие метки столбцов:
Дата |
Код вида |
Код |
Номинал |
Эмиссия |
Спрос |
Курс ЦБ |
|
ЦБ |
эмитент |
ЦБ |
ЦБ |
ЦБ |
|
01.02.98 |
A |
П1 |
1000 |
10 |
10 |
1,05 |
01.02.98 |
A |
П1 |
1500 |
2 |
2 |
1,07 |
16.08.98 |
A |
П1 |
1200 |
6 |
4 |
0,97 |
03.02.98 |
A |
П2 |
500 |
4 |
3 |
0,98 |
12.06.98 |
A |
П2 |
500 |
4 |
3 |
0,98 |
12.02.98 |
A |
П3 |
100 |
6 |
4 |
0,97 |
22.06.98 |
A |
П3 |
100 |
6 |
4 |
0,97 |
15.07.98 |
A |
П3 |
500 |
4 |
3 |
0,98 |
12.02.98 |
B |
П1 |
5000 |
3 |
3 |
1,12 |
22.06.98 |
B |
П1 |
5000 |
3 |
3 |
1,10 |
17.08.98 |
B |
П1 |
5000 |
3 |
3 |
1,12 |
21.02.98 |
B |
П2 |
10000 |
2 |
2 |
1,06 |
23.06.98 |
B |
П2 |
500 |
2 |
2 |
1,06 |
23.02.98 |
B |
П3 |
2000 |
1 |
1 |
1,09 |
02.03.98 |
B |
П3 |
15000 |
1 |
1 |
1,12 |
01.07.98 |
B |
П3 |
500 |
1 |
1 |
1,07 |
01.08.98 |
B |
П3 |
500 |
1 |
1 |
1,15 |
02.03.98 |
O |
П1 |
5000 |
5 |
5 |
1,01 |
05.07.98 |
O |
П1 |
2000 |
5 |
5 |
1,01 |
12.08.98 |
O |
П1 |
1000 |
5 |
5 |
1,01 |
04.03.98 |
O |
П2 |
500 |
6 |
4 |
1,02 |
05.06.98 |
O |
П2 |
2000 |
5 |
3 |
1,00 |
12.07.98 |
O |
П3 |
500 |
6 |
4 |
1,02 |
13.08.98 |
O |
П3 |
2000 |
5 |
3 |
1,00 |
06.03.98 |
O |
П3 |
1000 |
3 |
2 |
1,02 |
13.07.98 |
O |
П3 |
1000 |
3 |
2 |
1,02 |
В качестве массива значений для описательной статистики взят Курс_ЦБ котировки ценных бумаг. Использованы технология Пакета анализа, статистические функции для аналогичных вычислений. Результаты расчетов сведены в таблицу, в которой показаны формулы, которые должны быть введены в ячейки.
Описательная статистика для |
Функции |
||
массива КУРС ценных бумаг |
|||
(Курс_ЦБ) |
|
|
|
Среднее |
1,037 |
= СРЗНАЧ(Курс_ЦБ) |
|
|
|
|
|
Стандартная ошибка |
0,011 |
= СТАНДОТКЛОЩ(Курс ЦБ)/ |
|
|
|
КОРЕН Ь(СЧЕТ( КурсЦБ)) |
|
Медиана |
1,020 |
= МЕДИАНА(курс) или |
|
|
|
=КВАРТИЛЬ(курс;2) |
|
Мода |
1,020 |
= МОДА(курс) |
|
Стандартное |
0,054 |
= СТАНДОТКЛОН(курс) |
|
отклонение |
|||
|
|
||
Дисперсия выборки |
0,003 |
= ДИСП(курс) |
|
|
|
|
|
Эксцесс |
-0,841 |
= ЭКСЦЕСС(курс) |
|
Асимметричность |
0,537 |
= СКОС(курс) |
|
Интервал |
0,180 |
= МАКС(курс)-МИН(курс) |
|
Минимум |
0,970 |
= МИН(курс) или |
|
=КВАРТИЛЬ(курс;0) |
|||
|
|
|
|
Максимум |
1,150 |
= МАКС(курс) или |
|
|
|
=КВАРТИЛЬ(курс;4) |
|
Сумма |
26,970 |
= СУММ(курс) |
|
Счет |
26,000 |
= СЧЁТ(курс) |
|
Наибольший(1) |
1,150 |
- |
|
|
|
|
|
Наименьший(1) |
0,970 |
- |
|
Уровень надежности |
0,022 |
=ДОВЕРИТ(0,05;СТАНДОТКЛОН(курс); |
|
(95,0%) |
|
СЧЁТ(курс)) |
|
|
|
|
|

Для вычисления показателей средней геометрической — одинаково отстоящей от максимума и минимума — и средней гармонической — средней обратных величин — использованы формулы:
Формула |
Результат |
=СРГЕОМ(Курс_ЦБ) |
1,035977 |
|
|
=СРГАРМ(Курс_ЦБ) |
1,034667 |
|
|
6.2. Ранжирование числовых данных
Ранжирование больших массивов числовых данных обеспечивает упорядочение данных и получение для них таких статистических оценок, как ранг и персентилъ. Ранг — это номер значения случайной величины в наборе данных, который присваивается согласно следующим правилам:
•каждое уникальное значение имеет уникальный ранг;
•группа из одинаковых значений (w) получает одинаковый ранг, равный рангу первого числа группы (R). Число, следующее за этой группой, получает ранг, равный R + т;
•максимальное значение в наборе данных имеет ранг, равный 1; минимальное значение в наборе данных имеет наибольшее значение ранга, равное количеству чисел в наборе (п) при отсутствии одинаковых значений или (n-k-l) при наличии k одинаковых минимальных значений. Значение ранга позволяет установить процент чисел в массиве, не превосходящих указанное значение (с заданным рангом) — процентранг {Т). Процентранг вычисляется по формуле:
для разных чисел: |
T = |
(n − R) |
100% , |
|
(n −1) |
||||
|
|
|
для одинаковых чисел: T = (n − R −(k −1)) 100% .
Для отдельного значения показателя выполняется оценка его относительного положения в множестве данных с помощью показателей:
• квартиль — значение признака, делящего ряд (множество данных)
на 4;
• квинтель — значение признака, делящего ряд (множество данных)
на 5;
•дециль — значение признака, делящего ряд (множество данных) на 10 равных частей;
•персентиль — значение признака, делящего ряд (множество данных) на 100 равных частей.
6.2.1. Информационная технология ранжирования данных в Пакете анализа
Команда Сервис, Анализ данных вызывает диалоговое окно
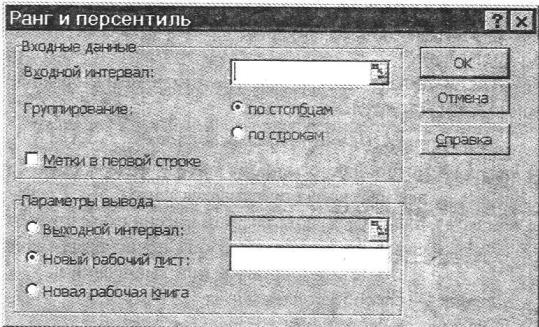
Инструменты анализа, в котором выбирается режим Ранг и персентиль.
Исходные данные представлены в виде массивов числовых данных, для которых определены имена блоков. Для выполнения ранжирования данных используется диалоговое окно (рис. 6.2), в котором указываются:
Рис. 6.2. Диалоговое окно режима Ранг и персентиль.
Входные данные — блок ячеек или имя блока. Данные могут иметь произвольную ориентацию (группирование) — по строкам или по столбцам. Если в блок включены наименования полей (метки), используется переключатель;
Параметры вывода — это блок ячеек на том же листе; новый лист; новая рабочая книга.
Выходная таблица содержит столбцы:
Точка — порядковый номер числа в наборе исходных данных; Столбец1 — столбец исходных данных, расположенных в порядке
возрастания номера ранга и убывания значения данных; Ранг — ранг числа; Процент — значение процентранга.
6.2.2. Информационная технология ранжирования с использованием статистических функций
Взаимосвязанные функции РАНГ, ПРОЦЕНТРАНГ, ПЕРСЕНТИЛЬ, КВАРТИЛЬ выполняются применительно к массиву ранжируемых данных, который указывается как именованный блок.
Функция РАНГ возвращает ранг определенного числа в указанной последовательности чисел:
РАНГ(число;ссылка;порядок),
где число — число либо ссылка на ячейку, содержащую число, для которого определяется ранг;
ссылка — блок ячеек, содержащий массив ранжируемых чисел. Блок может содержать нечисловые значения, которые игнорируются при вычислении;
порядок — способ упорядочения:
ЛОЖЬ — ранжирование в порядке убывания, ИСТИНА — в порядке возрастания значений. Например, если массив содержит значения:
1,15 1,12 1,12 1,12 1,1,
то им буду присвоены ранги при ранжировании по убыванию:
1 |
2 |
2 |
2 |
5. |
Функция ПРОЦЕНТРАНГ возвращает долю значений в массиве, не превосходящих значение заданной точки данных:
ПРОЦЕНТРАНГ(массив;число;разрядность)