

Овчаренко_8
.pdf•Назад на — количество периодов, на которое линия тренда проектируется в прошлое, или в направлении к оси Y;
•Установить ^-пересечение — точка, в которой линия тренда должна пересекать ось Y по указанию пользователя;
•Показывать уравнение на диаграмме — на диаграмме будет выведена аналитическая форма записи уравнения линии тренда;
•Поместить на диаграмму величину достоверности аппроксимации
(R-квадрат) — коэффициент детерминации.
Наряду с линиями тренда на графике временного ряда могут быть изображены планки погрешностей.
Планки погрешностей, используются во многих инженерных и статистических задачах для показа возможной погрешности значений эмпирического ряда (диапазон отклонений "плюс-минус" либо в одну из сторон). Дополнить планками погрешностей ряды данных можно только для диаграмм: с областями, линейчатых, гистограмм, графиков, точечных. Y-
планки погрешностей отображаются вдоль оси значений Y (XY-точечные диаграммы могут выводить также Х-планки погрешностей вдоль оси X).
•Для одного и того же ряда может быть построено произвольное число
линии тренда, при этом для каждой из них может быть выведена аналитическая форма уравнения и оценка — R2.
При перемещении ряда данных планки погрешностей перемещаются автоматически, при изменении значений элементов данных автоматически заново вычисляются величины погрешностей и соответствующим образом изменяются их планки.
Для вставки планок погрешностей следует активизировать диаграмму и выделить ряд данных, выполнить команду Формат, Выделенный ряд, на вкладке Погрешности указать параметры погрешностей — тип планок и вариант их расчета:
Фиксированное значение — за величину ошибки принимается заданное постоянное значение погрешностей;
Относительное значение (%) — для каждой точки данных вычисляется отклонение на заданный процент;
Стандартное отклонение — вычисляется стандартное отклонение, которое затем умножается на заданное число (коэффициент кратности);
Стандартная погрешность — постоянная для всех элементов данных величина ошибки;
Пользовательская погрешность — вводится произвольный массив значений отклонений в положительную и/или отрицательную сторону (можно ввести ссылку на блок ячеек).
Пример.
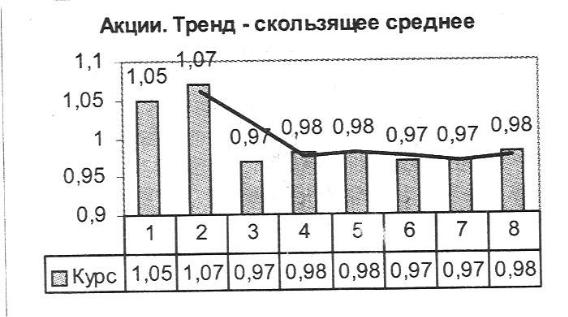
Тренды для показателя Курс_ЦБ применительно к акциям (рис. 6.12), векселям (рис. 6.13) и облигациям (рис. 6.14).
Тип тренда подбирается с учетом формы ряда и значения коэффициента достоверности аппроксимации. В данном случае наиболее предпочтительной является скользящая средняя, которая позволяет устранить случайные колебания и выявить основную тенденцию курса ценных бумаг.
Для продолжения числового ряда на рабочем листе согласно тренду используется средство автозаполнения, которое требует выполнения следующих действий:
•ввести исходные значения элементов ряда;
•выделить исходный блок ячеек — значения элементов ряда;
•установить курсор на маркер автозаполнения — в правый нижний угол выделенного блока ячеек;
•нажать правую кнопку мыши и протянуть вниз на соответствующее количество ячеек для прогноза;
•отпустить кнопку мыши и выполнить команду короткого меню
Линейное/Экспоненциальное приближение.
Рис. 6.12. Тренд курса акций.
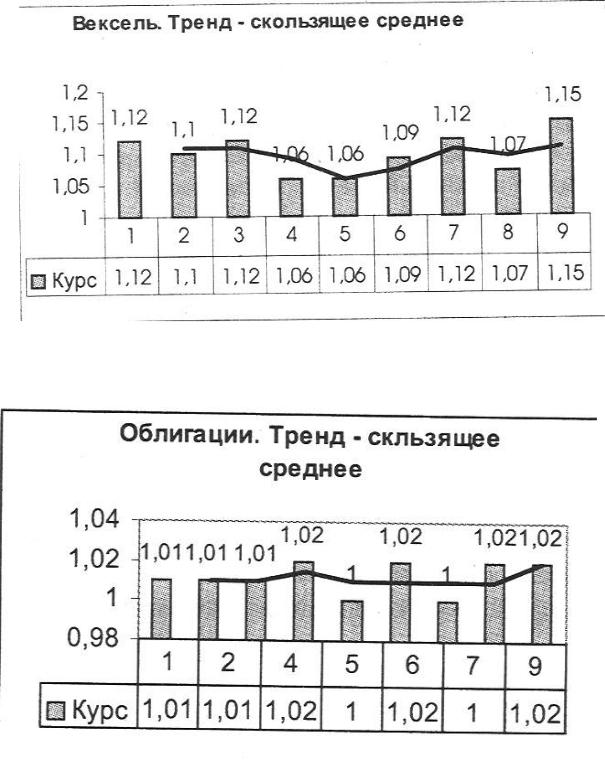
Рис. 6.13. Тренд курса векселей.
Рис. 6.14. Тренд курса облигаций.
6.7. Информационная технология прогнозирования с использованием статистических функций.
6.7.1. Функция ЛИНЕЙН.
Функция ЛИНЕЙН аппроксимирует имеющиеся данные линейной функцией, возвращает массив, который описывает полученную прямую:
y = m1 x1 + m2 x2 +... +b или y = mx +b
Синтаксис функции:
ЛИНЕЙН(известные__значения_у;известные_значения_х;конст; статистика),
где известные_значения_у — множество значений у (массив может содержать один столбец или одну строку);
известные_значения_х — необязательное множество значений х
(массив {1;2;3;...});
конст — ИСТИНА (или опущено) для вычисления b; ЛОЖЬ для b =0; статистика — ИСТИНА для вывода регрессионной статистики:
{тп;тп—l;...;ml;b:sen;sen—l;...;sel;seb:r2;sey:F;df:ssreg;ssresid}.
Разделитель двоеточие (:) означает, что элементы массива располагаются в отдельной строке;
тn, тn-1, ..., тi — коэффициенты линейного уравнения регрессии для независимых переменных;
b — свободный член уравнения регрессии;
se1, se2, ..., sen — стандартные значения ошибок для коэффициентов m1, т2 ,.., тn;
seb — стандартное значение ошибки для постоянной b (seb = #Н/Д, если конст имеет значение ЛОЖЬ);
r2 — коэффициент детерминированности, нормированный от 0 до 1;
sey — стандартная ошибка для оценки у;
F — F-статистика для оценки взаимосвязи зависимой и независимой переменных;
df — степени свободы для нахождения F-критических значений в статистической таблице, определения уровня надежности регрессионной модели;
ssreg — регрессионная сумма квадратов;
ssresid — остаточная сумма квадратов. Данная функция может быть использована и для построения уравнения прямой. Любую прямую можно задать ее наклоном и у-пересечением.
При наличии одной независимой переменной х можно вычислить:
• наклон прямой (т):
ИНДЕКС(ЛИНЕЙН(известные_значения_у;известные_значения_х);1);
• Y-пересечение (b):
ИНДЕКС(ЛИНЕЙН(известные_значения_у;известчые_значения_х);2).
Пример.
Построить уравнение линейной регрессии для следующих исходных данных:
Вид |
|
|
|
|
|
|
ценной |
Номинал |
Эмиссия |
Спрос |
Курс |
ЛИНЕЙН |
|
бумаги |
|
|
|
|
|
|
Акция |
100 |
2300 |
1670 |
0,92 |
0,000058651 |
0,89154488 |
|
|
|
|
|
|
|
Акция |
1000 |
200 |
80 |
0,87 |
0,000020072 |
0,03902396 |
|
|
|
|
|
|
|
Акция |
100 |
1500 |
2000 |
1,05 |
0,680979056 |
0,05671679 |
|
|
|
|
|
|
|
Акция |
2000 |
300 |
250 |
0,97 |
8,538361748 |
4 |
|
|
|
|
|
|
|
Акция |
150 |
3000 |
3500 |
1,12 |
0,027466155 |
0,01286718 |
|
|
|
|
|
|
|
Акция |
250 |
2100 |
1890 |
0,97 |
|
|
|
|
|
|
|
|
|
Создаются именованные блоки курс и спрос. Выделяется блок ячеек размерностью 2 столбца и 5 строк, вводится формула массива с параметрами:
{=ЛИНЕЙН(Курс;Спрос;ИСТИНА;ИСТИНА)}.
Уравнение регрессии: Y = 0,89154488 + 0,000058651X.
6.7.1. Функция ТЕНДЕНЦИЯ
Функция ТЕНДЕНЦИЯ возвращает предсказанные значения в соответствии с линейным трендом для заданного массива новые_значения _х, аппроксимируя прямой линией (по методу наименьших квадратов) массивы
известные_значения_у и известные_значения_х: ТЕНДЕНЦИЯ(известные_значения_у;известнь1е_значения_х;новые_значения_х;конст).
Если опущены известные_значения_х и новые_значения_х,
предполагается использование массива {1;2;3;...} такого же размера, что и
известные_значения_у. Функцию ТЕНДЕНЦИЯ можно использовать также и для аппроксимации полиномиальной кривой, проводя регрессионный анализ для той же переменной, возведенной в различные степени.
Пример.
В условиях предыдущего примера вычислить значение курса акции для заданных значений Номинал — 220, Эмиссия — 1220, Спрос — 1150;
прогнозное значение курса — 0,931.
6.7.3. Функция ПРЕДСКАЗ (уравнение линейной регрессии).
Функция ПРЕДСКАЗ возвращает предсказанное значение функции в точке х на основе линейной регрессии для массивов известных значений одной независимой переменной х и зависимой переменной у:
ПРЕДСКАЗ(х; известные_значения_у; известные_значения_х),
где х — точка данных, для которой предсказывается значение.
Данная функция обеспечивает вычисление прогнозного значения только для парной регрессии.
6.7.4. Функция НАКЛОН (линии линейной регрессии)
Функция НАКЛОН возвращает коэффициент для независимой переменной в уравнении парной регрессии, который соответствует скорости изменения значений вдоль прямой:
НАКЛОН(известные_значения_у;известные_значения_х),
где известные_значения_у — массив или интервал ячеек, содержащих числовые зависимые точки данных;
известные_значения_х — массив или интервал ячеек для независимых точек данных.
Массивы известные_значения_у и известные_значения_х должны иметь одинаковую размерность.
6.7.5. Функция ОТРЕЗОК (на оси ординат линии линейной регрессии)
Функция ОТРЕЗОК возвращает отрезок, отсекаемый на оси ординат линией линейной регрессии:
ОТРЕЗОК(известные_значения_х;известные_значения_у),
где известные^значения _у — зависимое множество данных; известные^значения _х — независимое множество данных.
6.7.6. Функция КВПИРСОН (квадрат коэффициента корреляции)
Функция КВПИРСОН возвращает квадрат коэффициента корреляции Пирсона (R2) для множеств: известные_значения_у и известные_значения_х.
Значение R-квадрат можно интерпретировать как отношение дисперсии для у к дисперсии для х.
КВПИРСОН(известные_значения_у; известные_значения_х),
где известные_значения_у — массив или интервал точек зависимых данных; известные_значения_х — это массив или интервал точек независимых
данных.
6.7.7. Функция ПИРСОН
Функция ПИРСОН возвращает коэффициент корреляции Пирсона — r, безразмерный индекс в интервале от -1 до 1 включительно, который отражает степень линейной зависимости между двумя множествами данных:
ПИРСОН(массив1 ;массив2),
где массив1 — множество независимых, а массив2 — множество зависимых значений (массивы должны иметь
одинаковую размерность).
6.7.8. Функция СТОШYX
Функция CTOШYX возвращает стандартную ошибку предсказанных значений у для каждого значения х в регрессии:
СТОШУХ(известные_значения_у;известные_значения_х),
где известные_значения_у — массив или интервал зависимых данных; известные_значения_х — массив или интервал независимых данных.
Массивы известные_значения_у и известные_значения_х должны иметь одинаковую размерность.
6.7.9. Функция РОСТ
Данная функция аппроксимирует экспериментальные данные экспоненциальной кривой вида: y = b m , вводится как массив формул в блок ячеек для чего необходимо:
•выделить ячейки, куда вводится результат вычисления функции
РОСТ;
•нажав знак равно (=), вызвать Мастера функций и выбрать в категории Статистические функцию РОСТ;
•ввести параметры функции:
РОСТ(известные_значения_у;известные_значения_х; новые_значения_х;к.онст);
• Завершить ввод формулы нажатием клавиш <Shift> + <Ctrl> + <Enter>.
Синтаксис функции:
известные_значения_у — множество исходных значений у; известные_значения_х — необязательное множество значений х для
известных у (размерность по высоте совпадает с размерностью у). Если параметр не указан, предполагается массив натуральных чисел {1;2;3;...}
размерности известные_значения_у;
новые_значения_х — новые значения х, для которых вычисляются прогнозные значения у. Если они не указаны, предполагается их совпадение с аргументом известные_значения_х. Если оба аргумента
известные_значения_х и новые_значения_х опущены, предполагается массив натуральных чисел {1;2;3;...} размерности известные_значения_у;
конст — константа; если равна ИСТИНА или опущена, для функции прогноза вычисляется коэффициент b, если константа равна ЛОЖЬ, коэффициент b равен 1.
При вводе формулы РОСТ массив известные_значения_х может задаваться как массив констант прямо в строке ввода. При этом используется точка с запятой для разделения значений констант, принадлежащих одной строке, и двоеточие для разделения констант, находящихся в различных строках, например:
{1:2:3:4} — константы, представленные в разных строках, но в одном столбце;
{1;2:3;4:5;6} — константы, представленные в 3 строках и 2 столбцах. Если не задавать аргумент новые_значения_х, вычисляется массив
значений у для фактических значений х в соответствии с экспоненциальной кривой. Массив констант удобнее готовить непосредственно в ячейках, используя для этого режим автозаполнения — команда Правка, Заполнить,
Прогрессия, Арифметическая, шаг 1.
Пример.
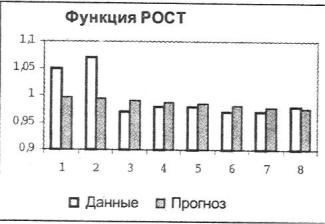
Оценить реальные данные о курсе продажи акций, выполнить их аппроксимацию экспоненциальной кривой. Получить прогноз курса акций на последующие 2 периода, используя экспоненциальное сглаживание.
Функция РОСТ должна вводиться как массив формул. Для аппроксимации исходных данных с помощью экспоненциальной кривой следует выделить блок ячеек по высоте исходного блока и ввести массив формул вида: РОСТ (курс; ; ;ЛОЖЬ). Коэффициент b уравнения сглаживания равен 1. В конце задания параметров функции нажать клавиши <Shift> + <Ctrl> + <Enter>. Результат аппроксимации показан в виде таблицы и графика на рис. 6.15:
Данные |
Прогноз |
1,05 |
0,997 |
1,07 |
0,994 |
0,97 |
0,991 |
0,98 |
0,987 |
0,98 |
0,984 |
0,97 |
0,981 |
0,97 |
0,978 |
0,98 |
0,975 |
Рис. 6.15. Функция РОСТ.
Для получения прогноза курса акций в две смежные ячейки, расположенные в одном столбце, ввести формулу вида: РОСТ (курс;;;ЛОЖЬ). Результат прогноза — 0,9968 для первого периода прогноза и 0,9937 для второго периода прогноза.
6.7.10. Функция ЛГРФПРИБЛ
Эта функция обеспечивает формирование массива значений параметров, описывающих экспоненциальную кривую, аппроксимирующую данные. Функция ЛГРФПРИБЛ возвращает массив значений и вводится как массив формул. Уравнение экспоненциальной кривой имеет следующий вид: y = b m x или y = (b (m1x1 ) (m2x 2 ) *... при наличии нескольких переменных х.
Переменные х1, х2 и т.д. — независимые, у — функция независимых значений х. Синтаксис функции:
ЛГРФПРИБЛ(известнь1е_значения_у;известные_значения_х;конст; статистика),
где известные_значения_у — множество исходных значений у;
известные_значения_х — необязательное множество значений х для известных у (размерность по высоте совпадает с размерностью у). Если параметр не указан, предполагается массив натуральных чисел {1;2;3;...}
размерности известные_значения_у;
новые_значения_х — новые значения х, для которых вычисляются прогнозные значения у. Если они не указаны, предполагается их совпадение с аргументом известные_значения_х. Если оба аргумента известные _значения_х и новые_значения_х опущены, предполагается массив натуральных чисел {1;2;3;...} размерности известные_значения_у;
конст — константа; если равна ИСТИНА или опущена, для функции прогноза вычисляется коэффициент b, если константа равна ЛОЖЬ, коэффициент b равен 1;
статистика — дополнительная статистика по регрессии, указывается ИСТИНА; если указано ЛОЖЬ или опущено, возвращаются коэффициенты m и b.
Значение у, предсказанное с помощью уравнения регрессии, может быть недостоверным, если оно находится вне диапазона значений у, которые использовались для определения уравнения. Дополнительная статистика, которую возвращает функция ЛГРФПРИБЛ, основана на следующей линейной модели:
ln y = x1 ln m1 +... + xn ln mn +ln b.
Это следует помнить при оценке дополнительной статистики, особенно значений sei и seb, которые нужно сравнивать с In тi. и In b, а не с тi и b.
Пример.
Получить дополнительную статистику для массива Курс_ЦБ по акциям при использовании экспоненциального сглаживания. Поскольку анализируется только один столбец, содержащий данные по ряду последовательных периодов, можно воспользоваться формулой: ЛГРФПРИБЛ(024:031 ;;ЛОЖЬ;ИСТИНА).
0,996835 1
0,002499 #Н/Д
0,175069 0,035689
1,485557 7
0,001892 0,008916
Формула экспоненциальной кривой: у = 0,996835\ Для одной независимой переменной х:
• значение т определяется по формуле:
ИНДЕКС(ЛГРФПРИБЛ(известные_значения_у;известные_ значения_х);1);
• значение b определяется по формуле:
ИНДЕКС(ЛГРФПРИБЛ(известные _значения_у;известные_ значения _х);2);