


Тема 4. Прогнозирование на основе многофакторных регрессионных моделей
Многофакторная регрессионная модель – это регрессионная мо-
дель, отражающая влияние на прогнозируемый показатель нескольких факторов. Многофакторную модель в общем виде можно представить уравнением:

 = f( x1, x2, x3 ...xn) = f (x),
= f( x1, x2, x3 ...xn) = f (x),
где 

 – прогнозируемый показатель (зависимая переменная);
– прогнозируемый показатель (зависимая переменная);
x1, x2…, xi ...xn – факторы, влияющие на изменения прогнозируемого показателя.
Исходная информация при этом представляется несколькими динамическими рядами.
В моделировании применяются следующие функции для построения уравнения множественной регрессии:
• линейная 
 = а+b1х1+b2х2+b3х3+b4х4+b5х5+b6х6+…+bnxn;
= а+b1х1+b2х2+b3х3+b4х4+b5х5+b6х6+…+bnxn;
|
степенная y |
|
a0 x1 |
b1 |
x2 |
x3 |
|
...xn |
e |
; |
|
|
|
|
|
|
|
|
|
||||
• |
ˆ |
= |
|
b2 |
|
|
b3 |
|
|
|
bn |
|
|
|
|
|
|
|
|
|
|
|
|
|
показательная y |
|
a0b1 |
|
b2 |
b3 |
...bn |
e |
; |
|
|
|
|
|
|||||||||
• |
|
|
ˆ |
= |
|
|
|
x1 |
|
x2 |
|
x3 |
|
xn |
|
|
|
|
|
|
|
|
|
• |
гиперболическая yˆ = |
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
+e |
||||||
a |
0 |
+b x |
+b x |
2 |
+b x |
3 |
+... +b x |
n |
|||||||||||||||
|
экспоненциальная y |
|
|
|
1 |
1 |
2 |
|
3 |
n |
; |
||||||||||||
|
|
|
|
e |
a0 |
+b1x1 |
+b2 x2 +b3x3 +...+bn xn +e |
и т.д. |
|
|
|||||||||||||
• |
|
|
|
|
ˆ |
= |
|
|
|
|
|
||||||||||||
На практике наиболее часто используется множественная линейная регрессионная модель.
Если в модель включаются два или более тесно взаимосвязанных фактора, то наряду с уравнением регрессии появляется и другая линейная зависимость. Подобное явление, называемое мультиколлинеарностью.
Мультиколлинеарность – попарная корреляционная зависимость между факторами. Она присутствует, если коэффициент парной корреляции rхiхj ≥ 0,7. Поэтому обязательным условием при построении модели является анализ факторов на мультиколлинеарность и её устранение.
Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных коэффициентов.
28

Если бы факторы не коррелировали между собой, то определитель матрицы парных коэффициентов был бы равен единице. Например, для модели у = а0+а1х1+а2х2+е
rx1x1 |
rx1x2 |
= |
1 |
0 |
=1. |
r |
r |
|
0 |
1 |
|
x2 x1 |
x2 x2 |
|
|
|
|
И наоборот, если все факторы коррелированы, т.е. между ними существует линейная зависимость, то определитель этой матрицы равен 0 или на примере:
rx1x1 |
rx1x 2 |
= |
1 |
1 |
= 0. |
r |
r |
|
1 |
1 |
|
x 2 x1 |
x 2 x 2 |
|
|
|
|
Значит можно сделать вывод, что чем ближе к 0 определитель такой матрицы, тем сильнее линейная зависимость между факторами.
Метод исключения переменных – используют для устранения мультиколлинеарности. Он заключается в том, что высоко коррелированные объясняющие переменные устраняются из регрессии, и она заново оценивается.
Процедура отбора главных факторов включает обязательно следующие этапы:
1.Производится анализ значения коэффициентов парной корреляции rхiхj между факторами xi и xj.
2.Выявленные попарнозависимые факторы анализируются по тесноты взаимосвязи объясняющих факторов с результативной переменной.
|
|
Образец решения задачи контрольной работы: |
|
|
||||||||||||
|
|
По приведенным в табл. 3.7 данным построить уравнение |
||||||||||||||
многофакторной линейной регрессии, если а = |
|
α |
, b1 = |
α |
−10, b2 = |
|||||||||||
11,5 |
8 |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
1 |
+0,79, b3 = 0,1− |
1 |
, b4 = |
1 |
+ 0,5, b5 = |
|
1 |
+0,4 |
. |
|
|
|
|
|
|
α |
|
|
α |
|
|
|
|
|
||||||||
α |
α |
|
|
|
|
|
|
|||||||||
Таблица 3.9
Фактические значения х
29

Значение α |
Х1 |
Х2 |
Х3 |
Х4 |
Х5 |
102-122 |
115 |
75,5 |
56,1 |
25,2 |
3343 |
124-144 |
123 |
78,5 |
61,8 |
21,8 |
3001 |
146-166 |
74 |
78,4 |
59,1 |
25,7 |
3101 |
168-184 |
111 |
77,7 |
63,3 |
17,8 |
3543 |
186-206 |
113 |
84,4 |
64,1 |
15,9 |
3237 |
208-228 |
110 |
75,9 |
57 |
22,4 |
3330 |
230-250 |
119 |
76 |
50,7 |
20,6 |
3808 |
252-268 |
146 |
67,5 |
57,1 |
25,2 |
2415 |
270-278 |
113 |
78,2 |
62 |
20,7 |
3295 |
280-300 |
0,8 |
78,1 |
61,8 |
17,5 |
3504 |
Рассчитать значения результативного показателя на следующие 2 периода.
На основе матрицы парных коэффициентов корреляции (табл.3.8) (рассчитать) выявить и устранить мультиколлинеарные факторы. После их устранения построить уравнение регрессии по новым данным регрессионного анализа, характеризующее зависимость результирующего показателя (y) от факторных (xi) в линейной форме.
|
|
|
|
|
Таблица 3.10 |
||
|
|
|
|
|
|
|
|
|
x1 |
x2 |
x3 |
x4 |
x5 |
y |
|
x1 |
1 |
|
|
|
|
|
|
x2 |
0,8154 |
1 |
|
|
|
|
|
x3 |
100/α |
90/α |
1 |
|
|
|
|
x4 |
0,0673 |
0,7628 |
0,2211 |
1 |
|
|
|
x5 |
0,00041 |
0,0034 |
0,068 |
0,024 |
1 |
|
|
y |
0,59033 |
0,76313 |
0,4001 |
0,2973 |
-0,004 |
1 |
|
Рассчитать прогнозные значения результативного показателя по скорректированной многофакторной модели на следующие 2 периода, если:
|
Изменение хi в текущем периоде по срав- |
Фактическое |
|||||
Период |
|
нению с предыдущим, % |
|
значение |
|||
х1 |
х2 |
х3 |
|
х4 |
х5 |
переменной |
|
|
|
||||||
|
|
у |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
30 |
|
|
|
13 |
+5 |
0 |
0 |
0 |
+2,3 |
2020 |
14 |
0 |
+7,1 |
0 |
0 |
0 |
2760 |
Оценить точность прогноза, рассчитав ошибку прогноза для обоих случаев. Сделать выводы.
Решение.
Пусть α = 302.
1. уравнение многофакторной регрессии будет выглядеть сле-
дующим образом: 
 = 26,26 + 27,75х1 + 0,79х2 + 0,1х3 + 0,5х4 + 0,4х5.
= 26,26 + 27,75х1 + 0,79х2 + 0,1х3 + 0,5х4 + 0,4х5.
Рассчитаем прогнозные значения Y:
Период |
|
Х1 |
|
Х2 |
Х3 |
|
Х4 |
|
Х5 |
|
|
|||
13 |
113*1,05 |
78,6 |
|
58,6 |
19,7 |
3056*1,023 |
|
4647,12 |
|
|||||
|
|
= 118,65 |
|
= 3126,29 |
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
||||
14 |
113 |
78,6*1,071 |
58,6 |
19,7 |
3056 |
|
4466,62 |
|
||||||
|
|
= 84,18 |
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
Определим ошибку прогноза по формуле: |
|
|
|
, |
|
||||||||
|
|
|
|
|
|
|
|
|
|
, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
Проверим модель на наличие мультиколлинеарности и при необ- |
|||||||||||||
ходимости устраним ее. |
|
|
|
|
x5 |
|
|
|
||||||
|
|
|
x1 |
|
x2 |
|
x3 |
|
x4 |
|
|
y |
|
|
|
x1 |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
x2 |
|
0,815 |
|
1 |
|
|
|
|
|
|
|
|
|
|
x3 |
|
100/302 |
|
90/302 = |
|
1 |
|
|
|
|
|
|
|
|
|
= 0,331 |
|
0,298 |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
x4 |
|
0,067 |
|
0,763 |
|
0,221 |
|
1 |
|
1 |
|
|
|
|
x5 |
|
0,041 |
|
0,034 |
|
0,068 |
|
0,024 |
|
|
|
|
|
|
y |
|
0,590 |
|
0,754 |
|
0,400 |
|
0,297 |
|
-0,004 |
|
1 |
|
Найдем пары мультиколлинеарных факторов, которые удовлетворяют условию rхiхj ≥ 0,7. Условию удовлетворяют следующее пары
факторов: |
= 0,815 и |
= 0,763. |
Из каждой пары необходимо исключить фактор, имеющий наименьшее значение rхiy.
31

Рассмотрим первую пару = 0,815.
= 0,815.  = 0,59;
= 0,59;  = 0,754.
= 0,754.
< , следовательно, факторный признак х1 следует исклю-
чить из модели, т.к. он имеет наименьшее значение rхiy в рассматриваемой паре.
Рассмотрим вторую пару |
= 0,763. |
 = 0,754;
= 0,754;
 = 0,297.
= 0,297.
 <
<  , следовательно, факторный признак х4 следует исклю-
, следовательно, факторный признак х4 следует исклю-
чить из модели, т.к. он имеет наименьшее значение rхiy в рассматриваемой паре.
Итак, из модели исключаем х1 и х4, модель примет вид:

 = 26,26 + 0,79х2 + 0,1х3 + 0,4х5.
= 26,26 + 0,79х2 + 0,1х3 + 0,4х5.
Рассчитаем скорректированные прогнозные значения Y:
Период |
Х2 |
Х3 |
Х5 |
Y |
13 |
78,6 |
58,6 |
3056*1,023 |
1344,73 |
|
= 3126,29 |
|||
|
|
|
|
|
14 |
78,6*1,071 = |
58,6 |
3056 |
1321,0222 |
|
84,18 |
|||
|
|
|
|
Определим ошибку прогноза по формуле:  ,
,
,
.
Вывод: Более качественной является трехфакторная регрессионная модель, так как позволяет получить меньшие значения ошибки прогноза.
Тема 5. Прогнозирование на основе трендовых моделей Временной ряд – это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов време-
ни.
Любой временной ряд включает два обязательных элемента: 1) время t, 2) значение показателя, или уровень ряда yi.
Количественные значения показателя во временном ряду называются уровнями, где y1 – начальный уровень ряда, а yn – конечный
32
уровень ряда. Уровни расположены в хронологическом порядке через равные промежутки времени.
Основные компоненты временного ряда
Каждый уровень временного ряда формируется под воздействием большого числа факторов, имеющих разный временной характер действия, которые можно разделить на три группы:
1.длительные, постоянно действующие факторы, оказывающие на изучаемое явление определяющее влияние и формирующие основную тенденцию ряда. Они будут составлять трендовую компоненту T.
2.кратковременные, периодические факторы, формирующие циклические (или сезонные) колебания ряда. Они будут составлять циклическую (или сезонную) компоненту S.
3.случайные факторы, отражаемые случайными изменениями уровней ряда. Они будут составлять случайную компоненту Е.
Методы прогнозирования временных рядов Экстраполяция – нахождение уровней за пределами изучаемого
ряда, т.е. продление в будущее тенденции, наблюдавшейся в прошлом.
Нахождение по имеющимся данным за определенный период времени некоторых недостающих значений признака внутри этого признака называется интерполяцией.
При прогнозировании на основе временных рядов могут использоваться различные методы в зависимости от исходной информации.
Статистические методы прогнозирования
Статистические методы прогнозирования связаны с выявлением основной тенденции развития явления.
Основная тенденция (тренд) – плавное и устойчивое изменение уровня явления во времени, свободное от случайных колебаний [8].
Наиболее простой метод статистического прогнозирования предполагает использование средних характеристик ряда динамики:
среднего абсолютного прироста и среднего темпа роста.
Этот метод основан на предположении о равномерном изменении уровней. Если в базовом периоде цепные показатели динамики не имели резких колебаний, то экстраполяцию можно делать с по-
33

мощью следующих способов:
•с помощью среднего абсолютного прироста.
Скорость изменения уровней временного ряда за определенный отрезок времени характеризуется средним абсолютным приростом. Предполагая его стабильным, прогноз можно дать в виде следующей экстраполяции:
yn′+k = yn + k × y ,
где yn′+k - прогнозируемый уровень,
k - период экстраполяций (год, два,....),
уn - последний уровень динамического ряда, y - средний абсолютный прирост, y = ynn−−1y0 .
Использование в экстраполяции среднего абсолютного прироста относится в прогнозировании к классу «наивных» моделей, т.к. предполагается, что развитие явления происходит по арифметической прогрессии, но чаще всего развитие явления следует по иному пути. Вместе с тем в ряде случаев этот метод может найти применение как предварительный прогноз, если у исследователя нет временного ряда: информация дана лишь на начало и конец периода предыстории.
•с помощью среднего темпа роста.
Прогнозное значение уровня, исходя из среднего коэффициента роста, можно получить по формуле:
yn′′+k = yn ×(K p )к ,
где K P - средний темп роста в коэффициентах, К р = n−1 yn .
y0
Данный прием экстраполяции предполагает, что уровни временного ряда изменятся в геометрической прогрессии, что не всегда соответствует реальности. Кроме того, формула расчета среднего коэффициента роста ориентирована на достижение конечного (yn) уровня временного ряда. И если на конце временного интервала уровень резко изменился (рост сменился спадом) и оказался ниже начального (у0), то прогноз распространится на будущую тенденцию падения, которой на самом деле не было.
При наличии тенденции во временном ряду его уровни можно
34

рассматривать как функцию времени:
yt = f (t) ,
где yt - уровни динамического ряда, вычисленные по соответствую-
щему аналитическому уравнению на момент времени t. Уравнение, которое выражает зависимость уровней динамиче-
ского ряда от фактора времени t , называется уравнением тренда. Выбор типа модели зависит от цели исследования и должен быть
основан на теоретическом анализе, выявляющем характер развития явления, а также на графическом изображении ряда динамики (линейной диаграмме).
Например, простейшими моделями, выражающими тенденцию развития, являются:
•линейная функция – прямая уˆt = a0 + a1t ,
•показательная функция уˆt =a0a1t ,
•кривая 2-го порядка (парабола) уˆt = a0 + a1t + a2t 2 ,
где а0, а1, а2 – параметры уравнения, t – время.
После выбора вида кривой (прямая, показательная функция, парабола 2-го порядка и др.) рассчитываются ее параметры.
При использовании полиномов разных степеней оценка параметров производится по методу наименьших квадратов (МНК): строится система нормальных уравнений, число которых соответствует числу параметров полинома. Так для линейного тренда система нормальных уравнений следующая:
na0 +a1∑t =∑ya0 ∑t +a1∑t2 =∑yt
где n - число уровней ряда динамики,
t - условное обозначение фактора времени порядковыми номерами (Отсчет времени начинается с 1 (например, если рассчитывается уравнение тренда по данным за январь, февраль, март
..., декабрь 2012 года, то время t, которое вводится в качестве независимой переменной, будет обозначено следующим образом: январь - 1, февраль - 2, март - 3, ...декабрь - 12)), у - фактические уровни ряда динамики.
На основе найденного уравнения кривой модели тренда рассчитываются выровненные уровни ряда, таким образом, технически вы-
35

равнивание ряда заключается в замене фактических уровней выровненными.
Следует обратить внимание, что сумма фактических значений у и сумма выровненных y t должны приближенно быть равны: ∑y t ≈ ∑у.
Если такого равенства нет, уравнение тренда рассчитано неверно. На основании полученных параметров уравнения тренда прово-
дится сглаживание динамического ряда периода истории, которое позволяет выделить основную тенденцию и случайные колебания.
При этом следует помнить, что даже многократное точное прогнозирование в период проверки и самообучения не дает полной гарантии того, что прогноз сбудется.
Если в ходе испытания получены удовлетворительные результаты, можно рассчитать прогноз на предстоящий период.
Образец решения задачи контрольной работы:
Имеются данные о численности собственных легковых автомобилей на 1000 человек населения по Новосибирской области на конец года (табл. 3.11, графы А, 1).
На основании имеющихся данных выполните точечный прогноз на 2012-2013 гг. с помощью статистических методов прогнозирования и с помощью линейного уравнения тренда.
Если в 2012 году число собственных легковых автомобилей на 1000 человек населения будет равно (265,7 + 100α ) штук, а в 2013 –
(271 + 100α ) штук, рассчитать ошибку прогноза по каждой из моделей. Оцените точность прогноза по каждому периоду.
Решение
Таблица 3.11 Расчет уравнения тренда ряда динамики численности собственных
легковых автомобилей на 1000 чел. населения
|
Число собств.легковых авто- |
|
2 |
yt |
− |
Годы |
мобилей на 1000 чел., шт. (у) |
t |
t |
yt |
|
А |
1 |
2 |
3 |
4 |
5 |
2007 |
196,3 |
1 |
1 |
196,3 |
203,88 |
2008 |
230,4 |
2 |
4 |
460,8 |
216,83 |
2009 |
229,9 |
3 |
9 |
689,7 |
229,78 |
|
36 |
|
|
|
|

2010 |
232,1 |
4 |
16 |
928,4 |
242,73 |
2011 |
260,2 |
5 |
25 |
1301,0 |
255,68 |
Итого |
1148,9 |
15 |
55 |
3576,2 |
1148,9 |
Пусть α = 302.
1) Прогнозирование с помощью среднего абсолютного прироста. Среднегодовой абсолютный прирост численности собственных легковых автомобилей на 1000 человек по Новосибирской области
равен:
у = |
у1 − y0 |
= 260,2 |
−196,3 |
= 63,9 |
=15,975 |
(шт.). |
|
n −1 |
−1 |
||||||
|
5 |
4 |
|
|
Тогда, прогноз численности собственных легковых автомобилей:
на 2012 г. y6′ = y5′+1 = 260,2 +1×15,975 = 276,175 (шт.) , на 2013 г.: y7′ = y5′+2 = 260,2 + 2 ×15,975 = 292,15 (шт.).
2) Прогнозирование с помощью среднего темпа роста. Средний темп роста можно рассчитать следующим образом:
yn |
260,2 |
|
K P = n−1 y |
= 5−1 196,3 |
= 4 1,3255 =1,073 или 107,3 %. |
1 |
|
|
Рассчитаем прогноз численности собственных легковых автомобилей:
на 2012 г.: y6′ = y5′+1 = 260,2×1,073 = 279,19 (шт.);
на 2013 г.: y 7′ = y 5′+2 = 260,2×(1,073)2 = 299,57 (шт.).
3) Прогнозирование на основе уравнения тренда.
Для прогнозирования по прямой следует получить уравнение:
yt =a0 + a1t.
Для расчета параметров а0 и а1 решается система нормальных уравнений:
na0 +a1∑t =∑ya0 ∑t +a1∑t2 =∑yt
где n - число уровней ряда динамики,
t - условноеобозначение фактора временипорядковыми номерами, у - фактические уровни ряда динамики.
В качестве расчетных добавим в таблицу 3.11 гр. 3 и 4. В гр. 3
37

значения t возводим в квадрат (12 = 1, 22 = 4 и т.д.), в графе 4 находим произведение уt (196,3×1 = 196,3, 230,4×2 = 460,8 и т.д.). В систему нормальных уравнений подставляем данные итоговой строки, в которой предварительно произведем суммирование:
5ао+ 15а1 = 1148,9 |
× 3 |
15ао+ 55а1 = 3576,2
Умножим каждый член первого уравнения на 3, затем вычтем из второго уравнения первое:
15ао+ 45а1 = 3446,7
15а0 + 55а1 = 3576,2
10а1 = 129,5
Отсюда а1 = 12910,5 =12,95.
Подставим его значение в первое уравнение, чтобы рассчитать параметр ао:
5ао +15×12,95 = 1148,9,
5ао = 1148,9 –194,25 ,
ао = 9545,65 =190,93 .
Уравнение тренда примет вид: y t = 190,93 + 12,95 t. Подставляя в
него значения t для каждого года, найдем выровненные (теоретические) значения.
Для 2007 г. yt = 190,93 + 12,95×1 = 203,88,
для 2008г. y t = 190,93 + 12,95×2 = 216,83 и т.д. Занесем их в гр. 5
таблицы 3.9.
При этом сумма фактических значений у и сумма выровненных
y t должны приближенно быть равны: ∑ y t ≈ ∑у (1148,9 ≈ 1148,9).
Ряд выровненных значений y t характеризует тенденцию ста-
бильного возрастания числа собственных легковых автомобилей на 1000 чел. населения по Новосибирской области, при этом численность автмобилей увеличивается в среднем на 12,95 шт. в год.
Чтобы использовать уравнение тренда для экстраполяции временного ряда, в уравнение тренда подставляют продолженное значение времени. Например, для 2012 г. t = 6 (продолжим нумерацию), тогда расчетный уровень ряда динамики, соответствующий 2012 г.,
вычислим y 6 = 190,93 + 12,95×6 = 268,63 (шт.),
38

для 2013 г.: y 7 = 190,93 + 12,95×7 = 281,58 (шт.).
4) Расчет ошибки прогноза по каждой из моделей.
Представим расчеты в форме табл. 3.12. Значения прогнозируемого показателя, полученные по каждому из методов, возьмем из расчетов и занесем в соответствующие ячейки таблицы.
Далее определим ошибку прогноза по формуле:
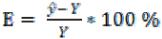 .
.
Вывод. Наиболее точные результаты прогнозирования на 20122013 гг. были получены с помощью трендовой модели, позволяющей получать наименьшие значения ошибки прогноза.
Таблица 3.12 Сравнительная таблица результатов прогнозирования
Фактические значения показателя
|
С помо- |
|
|
щью |
|
показателя |
среднего |
|
роста |
||
|
абсолют- |
|
прогнозируемого |
ного при- |
|
среднего |
||
|
Ошибка |
|
|
прогноза, |
|
|
% |
|
|
С помо- |
|
|
щью |
|
Значение |
темпа |
|
роста |
||
|
||
|
Ошибка |
|
|
прогноза, |
|
|
% |
|
|
По урав- |
Год
2012
265,7 + 302/100 = 268,72
276,175
276,175 − 268,72 *100 = 2,77 268,72
279,19
279,19 − 268,72 *100 = 3,9 268,72
268,63
2013
271 + 302/100 = 274,02
292,15
292,15 − 274,02 *100 = 6,61 274,02
299,57
299,57 − 274,02 *100 = 9,32 274,02
281,58
39