

Устройство управления. Принципы построения арифметико-логического устройства. Микропроцессорная память, регистры. Команды, процедуры их выполнения и способы адресации.
Организация системы прерывания программы.
Внешние сигналы микропроцессора.
Входящее в микропроцессор устройство управления (УУ) выполняет две основные функции: управление выполнением операций и выборку команд программы в необходимой последовательности, их дешифрацию и обработку составляющих их частей. В применяющихся в настоящее время МП используются два типа устройств управления выполнением операций.
В первом типе устройств управления процессом обработки информации все п управляющих входов АЛУ объединяются в n-разрядную шину, на которую для выполнения того или иного действия над данными на каждом шаге программы подается n-разрядная микрокоманда. Единичное или нулевое значение i-го разряда микрокоманды обеспечивает соответственно выработку или отсутствие i-го управляющего сигнала. Этими устройствами организации управления может быть реализован любой алгоритм выполнения программы.
Рассмотренный способ управления называется микропрограммным, структурная схема его приведена на рис. 5.1, а.

Рис. 5.1 Микропрограммная (а) и жесткая (б) схемы организации управления
процессом обработки информации
В состав устройства управления выполнением операций (УУВО) входят управляющее запоминающее устройство (ЗУ), дешифратор микрокоманд и схема управления их выполнением. В управляющем ЗУ для всех видов команд хранится набор составляющих их микрокоманд (МК), называемый микропрограммой. Последовательная выборка микрокоманд из управляющего ЗУ и их выполнение обеспечивает обработку информации, соответствующую коду команды. Сначала команда подается на вход управляющего ЗУ. Происходит выборка первой МК микропрограммы, относящейся к этой команде, которая поступает на дешифратор МК и схему управления ее исполнением. Всякая микрокоманда состоит из двух частей: операционной, которая определяет вид действий, и адресной, которая обеспечивает формирование адресной части следующей МК.
Дешифратор расшифровывает код операционной части, вырабатывает управляющие сигналы, которые подаются на обрабатывающую часть МП. Схема управления выполнением МК по коду адресной части МК и признакам условий, которые вырабатываются обрабатывающей частью микропроцессора, формирует адрес следующей МК, подаваемый на управляющее ЗУ. После выполнения всех микрокоманд, образующих команду, вырабатывается сигнал выборки следующей команды.
Микропрограммный способ управления позволяет легко вносить изменения в систему команд МП: для введения новой команды достаточно записать в ЗУ микропрограмму ее исполнения. Недостатком микропрограммного способа управления является необходимость обращения к управляющему ЗУ в каждом такте выполнения микропрограммы, что ограничивает скорость работы МП быстродействием управляющего ЗУ.
Во втором типе устройства управления процессом обработки информации (рис. 5.1, б) управляющий блок расшифровывает поступившую команду и в соответствии с ее кодом вырабатывает управляющие сигналы в необходимой последовательности. Управляющий блок построен таким образом, что расшифровке поддаются только те команды, которые входят в систему команд данного МП. Любая другая команда не будет расшифрована, а, следовательно, и исполнена. Такой способ организации управления получил название схемного, или жесткого, управления. Микропроцессоры с такой организацией управления носят название микропроцессоров с фиксированной системой команд.
В отличие от микропрограммного управления дешифратор команд и схема управления их выполнением не только расшифровывают код команды, но и вырабатывают нужную последовательность управляющих сигналов в течение нескольких тактов работы АЛУ, необходимых для выполнения команды. Обращение к следующей команде происходит после выполнения предыдущей по адресу, определяемому признаками условий, вырабатываемыми АЛУ. Жесткость - невозможность введения новой команды без существенного изменения схемы МП и сложность структуры этого типа управления является основным его недостатком, а высокое быстродействие - главным преимуществом.
Как и в обычных ЭВМ, команды, составляющие программу, размещаются в определенном порядке во внешнем по отношению к микропроцессору запоминающем устройстве команд (ЗУК). Микропроцессор должен обеспечить выборку команд в нужной последовательности, их дешифрацию, выполнение некоторых действий в соответствии с содержанием определенных частей команд (их называют полями команд) и передачу кода, устанавливающего вид выполняемой операции, в УУВО.
Для выполнения этих функций в МП должны быть предусмотрены специальные устройства: программный счетчик (ПС), который хранит текущий адрес команды; регистр команд (РК), предназначенный для приема и хранения поступающих из ЗУК команд; схема выдачи адресов команд и содержимого ПС на адресную шину МП; схемы приема данных и команд с внешней шины данных на РК. Структура МП, содержащая все указанные устройства, представлена на рис. 5.2. В МП имеются две шины данных: А и В. Адрес команды, подлежащей выполнению, хранится в программном счетчике (ПС). Отсюда он поступает через блок усилителей буфера адреса (БА) на шину адреса и по ней — на адресные входы ЗУК.

Рис. 5.2. Структура микропроцессора с обрабатывающей и
управляющей частями
Команда, выбранная на ЗУК, поступает на буфер данных (БД), а затем на регистр команд (РгК). Код команды расшифровывается дешифратором команд (ДшК), который анализирует отдельные поля команды и передает код выполняемой операции в УУВО. Последний вырабатывает последовательность управляющих сигналов, соответствующую коду операции, которая обеспечивает выполнение нужных действий обрабатывающей частью микропроцессора.
Если в процессе выполнения команды требуется обращение к РОН, то ДшК выдает адрес требуемого регистра в блоке РОН. Если Для выполнения команды следует обратиться к внешнему по отношению к МП запоминающему устройству, то соответствующий адрес поступает на шину адреса через БА. В процессе выполнения команды содержимое программного счетчика (ПС) изменяется: в нем формируется адрес следующей команды.
Рассмотренные структуры обрабатывающей и управляющей частей предполагают наличие двух внутренних шин: А и В (рис. 5.2). Существуют микропроцессоры с одной, двумя и тремя внутренними шинами. Количество шин существенно влияет на структуру и характеристики МП.

Рис 5.3. Структура обрабатывающей части микропроцессора с трех-(а) и одношинной (б) организацией
При трехшинной организации МП (рис. 5.3, а) возможно выполнение логических и арифметических операций за один такт работы МП. Так, при выполнении команды «сложить содержимое регистров Рг1 и Рг2, результат поместить в регистр РгЗ» в течение одного такта работы процессора содержимое Рг1 по шине А поступает в АЛУ, где складывается с содержимым регистра Рг2, поступившим в АЛУ по шине В. Результат сложения по шине С записывается в регистр РгЗ.
При двухшинной организации МП (см. рис. 5.2) та же команда будет выполняться за два такта: такт 1 - загрузка РгБ содержимым регистра Рг1; такт 2-загрузка РгСдв содержимым Рг2, сложение в АЛУ данных, занесенных в РгБ и РгСдв, и засылка результата в регистр РгЗ.
Возможна одношинная организация МП (рис. 5.3, б). Однако выполнение операций в таком МП усложняется, усложняется также и архитектура МП прежде всего за счет введения дополнительных буферных регистров. Рассмотренная выше команда в МП с одношинной организацией выполняется уже за три такта: такт 1 - загрузка РгБ содержимым регистра Рг1; такт 2 - загрузка РгСдв содержимым регистра Рг2; такт 3 - сложение данных, содержащихся в РгБ и РгСдв, и запись результата в регистр РгЗ.
Основной недостаток трехшинной организации - большая площадь, занимаемая шинами на кристалле микросхемы МП. Так, при одношинной организации МП площадь, занимаемая шиной, составляет 3-10% всей площади кристалла, при двухшинной -6-20%, при трехшинной - 16-25%.
Шины. При вставке в разъем материнской платы контроллер подключается к шине — магистрали передачи данных между оперативной памятью и контроллерами. Шины расширения обычных ПК конструктивно оформляются в виде щелевых разъемов (слотов) на системной плате. На современных материнских платах существуют два вида слотов расширения: PCI, AGP, ранние модели оснащались разъемом расширения ISA.
Шина ISA (Industry Standard Architecture – стандартная промышленная архитектура) для контроллеров низкоскоростных устройств (то есть для обмена данными с клавиатурой, мышью, дисководами для дискет, модемом, звуковой картой и т.д.).
Шина PCI (Peripheral Component Interconnect – связь периферийного оборудования) для обмена данными с высокоскоростными устройствами — (жесткими дисками, видеоконтроллером и т.д.). Этот разъем был выпущен фирмой Intel в 1993г.
Шина AGP (Accelerated Graphics Port – ускоренный графический порт). Этот разъем также был изобретен в фирме Intel, но в 1996 году, и предназначен исключительно для видеокарт. Наиболее распространенный в настоящее время разъем AGP 4х и AGP 8х. (PCI-Express, 16x)
Разъемы шин. Каждый контроллер может быть подключен лишь к той шине, на которую он рассчитан. Поэтому разъемы различных шин сделаны разными, чтобы их нельзя было перепутать. При покупке контроллеров следует знать, разъемы каких шин имеются в Вашем компьютере, так как иначе купленный контроллер окажется бесполезен.
Замечание. Обычно материнская плата содержит 3-4 разъема шины ISA и 3-4 разъема шины PCI. В компактных моделях системных блоков число разъемов может быть меньше, а в компьютерах, предназначенных для использования в качестве серверов локальной сети — больше.
Контроллеры портов ввода-вывода. Одним из контроллеров, которые присутствуют почти в каждом компьютере, является контроллер портов ввода-вывода. Часто этот контроллер интегрирован в состав материнской платы. Контроллер портов ввода-вывода соединяется кабелями с разъемами на задней стенке компьютера, через которые к компьютеру подключаются принтер, мышь и некоторые другие устройства. Порты ввода-вывода бывают следующих типов:
• параллельные (обозначаемые LPT1-LPT4), к соответствующим разъемам на задней стенке компьютера (имеющим 25 гнезд, обыкновенно подключаются принтеры;
• последовательные (обозначаемые СОМ1-СОМЗ). К соответствующим разъемам на задней стенке компьютера (имеющим 9 или 25 штырьков) обычно подсоединяются мышь, модем и другие устройства;
• игровой порт - к его разъему (имеющему 15 гнезд), подключается джойстик.
Как правило, контроллер портов компьютера поддерживает один параллельный и два последовательных порта.
Замечание. Параллельные порты выполняют ввод и вывод с большей скоростью, чем последовательные (за счет использования большего числа проводов в кабеле).
Разъемы шины USB. В некоторых новых компьютерах имеются разъемы универсальной последовательной шины USB. Разъемы и кабели шины USB похожи на телефонные. По-видимому, скоро будут выпущены модели клавиатур, мышей, принтеров, модемов, дисководов компакт-дисков, сканеров и т.д., подключаемые к шине USB. При этом к каждому устройству, подключенному к шине USB, можно подключать другие USB-устройства (всего может быть подключено до 127 устройств). Для этого, по-видимому, каждое (или почти каждое) USB-устройство будет иметь два или три разъема USB. USB-устройства можно будет подсоединять и отсоединять при работающем компьютере. Возможно, в недалеком будущем в компьютерах вместо разъемов клавиатуры, портов и джойстика будут иметься только два-три маленьких разъема USB.
Изобразим изложенные сведения об устройстве компьютера на блок-схеме. Здесь показан вариант, когда на материнской плате, кроме контроллера клавиатуры, имеется только контроллер портов ввода-вывода, а остальные контроллеры выполнены в виде отдельных плат. Заметим, что контроллеры жестких дисков и дискет не всегда располагаются на одной плате.

Рис.5.1 Блок-схема устройства компьютера (стрелками показаны направления передачи данных)
Арифметико-логические устройства служат для выполнения арифметических и логических действий над двоичными числами и алфавитно-цифровыми кодами. Все операции, выполняемые АЛУ, делятся на группы:
- операции двоичной арифметики для чисел с плавающей точкой (запятой);
- операции десятичной арифметики;
- операции двоичной арифметики для чисел с фиксированной точкой (запятой);
- операции логические над алфавитно-цифровыми кодами.
К арифметическим операциям относят операции сложения, умножения, вычитания и деления. К логическим операциям относят операции дизъюнкции (логическое ИЛИ), конъюнкции (логическое И) и сравнения кодов.
Функционально АЛУ является блоком, обеспечивающим прием операндов, выполнение над ними арифметических действий и выдачу результата в другие блоки процессора.
В процессорах с микропрограммным управлением АЛУ управляется микропрограммно. Все микроприказы поступают на дешифратор микроприказов АЛУ, называемый схемой управления АЛУ, дешифрируются и выполняются.
На рис. 5.1 представлена упрощенная структурная схема АЛУ, содержащего блок регистров (Рг1, Рг2, ...Ргn) для хранения операндов и промежуточных результатов вычислений, сумматор (См), сдвигатель (Сдв), коммутатор (К) и устройство управления (УУ). Операнды поступают из ОП или БП через входную шину на соответствующие алгоритму выполнения операции регистры Рг1, Рг2,..., Ргn и затем на сумматоре и/или сдвигателе производятся необходимые действия; результат поступает в выходную шину.
Алгоритмы выполнения в АЛУ арифметических операций зависят от кода представления информации. Обычно в процессоре применяют два кода: прямой и дополнительный. Это объясняется тем, что операции арифметического сложения (вычитания) реализуются для отрицательных (положительных) чисел на основе применения инверсных кодов — обратного и дополнительного. Однако использование обратного кода затруднено тем, что в нем существует два представления нуля (+0) и (-0), существенно усложняющих схему управления АЛУ.
Алгоритм арифметического сложения (вычитания) чисел с фиксированной точкой составляется с включением знаковых разрядов. При возникновении переноса из знакового разряда суммы и отсутствии переноса в знаковый разряд и отсутствии переноса из него возникает переполнение разрядной сетки в случае положительной и отрицательной сумм соответственно. При отсутствии переносов из знакового разряда суммы и в него или при наличии обоих этих переносов переполнения не возникает и при 0 - знаковом разряде сумма положительна, а при 1- знаковом разряде - сумма отрицательна и представлена в дополнительном коде.
На рис. 10.2/ представлена упрощенная структурная схема АЛУ для операций сложения и вычитания n-разрядных чисел с фиксированной точкой. Отрицательные числа представлены в дополнительном коде. Операнды поступают из БП или ОП на входную ШИВх и далее на регистры РгША и РгШВ, каждый из которых связан цепями прямой и инверсной передач с регистрами РгА и РгВ соответственно. Обычно регистры РгА и РгВ называют также регистрами первого и второго операндов. Положительные операнды поступают в прямом коде (ПрКод), отрицательные - в дополнительном (ДопКод). При вычитании двух положительных операндов вычитаемое также представляется в обратном коде. На сумматоре (См) осуществляется сложение чисел, поступивших с РгА и РгВ, а результат поступает на выходной регистр сумматора РгСм и далее в выходную шину ШИВых.

Рис. 5.2 Упрощенная структурная схема АЛУ для сложения и вычитания n-разрядных чисел с фиксированной точкой
Схема управления анализирует знак полученного результата и в зависимости от этого результат в РгСм поступает в соответствующем коде.
Алгоритм операции сложения (вычитания) чисел с плавающей точкой по сравнению с предыдущим алгоритмом несколько сложнее. Упрощенная структурная схема АЛУ для сложения чисел с плавающей точкой представлена на рис. 10.3. Основное отличие от схемы, представленной на рис. 10.2, заключается в использовании специальных регистров РгШ1, РгШ2, РгПА, РгПВ, РгСмП и сумматора СмП для обработки порядков чисел. Кроме того, в состав АЛУ входит сдвигатель Сдв, обеспечивающий сдвиг мантиссы на необходимое количество разрядов влево и вправо. Мантиссы обрабатываются так же, как и числа с фиксированной точкой.
Алгоритм сложения (вычитания) чисел с плавающей точкой заключается в следующем:
1) сравниваются порядки на сумматоре СмП, в случае их неравенства порядок меньшего числа принимается равным порядку большего числа и его мантисса сдвигается вправо на число разрядов, равное разности порядков чисел (содержимое регистра РгСмП) на Сдв;
2) выполняется сложение мантисс на сумматоре См, и в результате на регистре РгСм получается мантисса результата;
3) порядок результата принимается равным порядку большего числа.
В операциях с плавающей точкой в отличие от операций с фиксированной точкой при сложении и вычитании чисел в случае выравнивания порядков может происходить потеря младших разрядов одного из операндов. Для уменьшения погрешности применяют дополнительный разряд сумматора, в который после выполнения суммирования добавляется «1», после чего результат округляется.
Алгоритм операции умножения реализуется последовательным выполнением микроопераций сложения и сдвига. Произведение двух n-разрядных чисел может иметь 2n-разрядов, поэтому при выполнении операции умножения целых чисел необходимо предусмотреть возможность формирования в АЛУ произведения соответствующей длины.
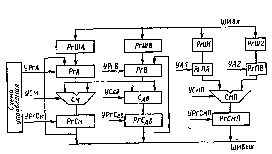
Рис 5.3. Структурная схема АЛУ для сложения и вычитания чисел
с плавающей точкой
Возможны четыре варианта схем организации операций умножения:
1. Умножение производится начиная с младших разрядов множителя со сдвигом суммы частных произведений вправо при неподвижном множимом.
2. Умножение производится начиная с младших разрядов множителя при сдвиге множимого влево и неподвижной сумме частичных произведений.
3. Умножение производится начиная со старших разрядов множителя при сдвиге суммы частичных произведений влево и неподвижном множимом.
4. Умножение производится начиная со старших разрядов множителя при сдвиге вправо множимого и неподвижной сумме частичных произведений.
Чаще всего применяется первый вариант выполнения операции умножения. Перед началом умножения (АЛУ на рис. 10.3) на соответствующие регистры поступают множимое (первый операнд) и множитель (второй операнд). Схема управления анализирует разряды множителя начиная с младшего. Если младший разряд множителя равен «1», то к содержимому регистра результата РгСм в исходном состоянии, равному «О», на сумматоре См прибавляется множи мое и результат заносится на РгСм. Затем множитель и промежуточный результат сдвигаются на один разряд вправо и далее все происходит аналогично. Если разряд множителя равен «О», то сложение не производится, а множитель и результат сдвигаются на один разряд вправо. Данная последовательность действий выполняется до тех пор, пока не будут проанализированы все разряды множителя. Знак произведения, хранящегося на регистре РгСм, определяется сложением по модулю два знаков множимого и множителя.

Рис. 5.4. Схема деления с неподвижным делителем, сдвигаемым влево делимым (очередным остатком)
Алгоритм операции деления реализуется последовательным выполнением микроопераций вычитания и сдвига. Существует два основных варианта схем организации операции деления:
Деление с неподвижным делимым (очередным остатком) и выдвигаемым вправо частным Х.
2. Деление с неподвижным делителем и сдвигаемым влево делимым (очередным остатком). Чаще всего используют второй вариант (рис. 10.4). Перед началом деления в регистр Рг1 принимается делимое (первый операнд), а в регистр Рг2 — делитель (второй операнд). Затем делимое передается из Рг1 в сумматор, а содержимое Рг1 обнуляется. Деление начинается с вычитания содержимого Рг2 (делителя) из делимого на сумматоре.
При этом если делимое или очередной остаток окажется больше делителя, то старшая цифра частного, равная «I», записывается в младший разряд Рг1. Если же очередной остаток окажется меньше делителя, то в Рг1 записывается «О», после чего содержимое регистра Рг1 и сумматора сдвигается влево на один разряд и т. д.
Таким образом, по ходу вычислений Рг1 заполняется цифрами частного. Деление прекращается после образования цифр частного во всех разрядах регистра Рг1.
Алгоритм логической операции выполняется на том же оборудовании, что и алгоритм арифметических операций, если в нем предусмотрены специальные цепи управления. Возможно также применение специальных блоков для выполнения логических операций.
В качестве примера рассмотрим реализацию функций эквивалентности, неравнозначности и Пирса. На рис. 5.5 показана схема одного разряда логического блока АЛУ, реализующего указанные функции над i разрядами чисел Х и Y. Входные данные X; и Y,. вводятся в соответствующие триггеры (Т). Заданная функция реализуется наличием определенной комбинации управляющих сигналов (1, 2, 3, 4). Так, при наличии сигналов 1 и 4 реализуется функция эквивалентности fi == XiyiVXiyi; при наличии сигналов 2 и 3—функция неравнозначности fi== (/«У-й»; при наличии сигнала 4 — функция Пирса /, == xiifi. Аналогично задаются и другие логические функции.
Время выполнения операций в АЛУ является важной характеристикой, определяющей быстродействие процессора в целом. На практике применяют два основных метода ускорения выполнения операций: аппаратный и логический (алгоритмический).
При использовании аппаратных методов сокращение затрат времени на выполнение операций достигается за счет использования более быстродействующих элементов и некоторого усложнения аппаратной реализации некоторых узлов, в результате которого уменьшается число машинных тактов. Так, в сумматорах используют дополнительные схемы, реализующие сквозной и групповой перенос, что сокращает время выполнения суммирования и вычитания, а также умножения и деления.

Рис. 5.5 Схема разряда логического блока АЛУ
При использовании логических методов уменьшение времени выполнения операций достигается за счет совершенствования алгоритмов работы микропрограмм и схем управления. Широкое распространение получили эти методы при ускорении выполнения операций умножения.
Время умножения 1у»и разрядных чисел складывается из времени tcu получения п сумм частичных произведений и времени tcaa сдвигов п, т. е. умн ==' == п((см+ сдв). Однако число сдвигов можно сделать меньше п, если анализировать сразу два, а не один разряд множителя, что и выполняет схема управления. В зависимости от них осуществляются следующие микрооперации:
00 — производится сдвиг суммы частичных произведений и множителя вправо на два разряда;
01 — множимое складывается с промежуточным результатом, и получаемая сумма сдвигается вправо на два разряда;
10—промежуточный результат сдвигается вправо на один разряд, затем к нему прибавляется множимое и полученная сумма сдвигается еще на один разряд вправо;
11 — из промежуточного результата вычитается множитель, результат сдвигается вправо на два разряда, а к следующей паре разрядов множителя добавляется «I».
Таким образом, достигается значительное ускорение операций умножения. Следует отметить, что одновременный анализ более чем- двух разрядов множителя нецелесообразен, так как приводит к резкому усложнению схемы управления.
Любой процессор ЭВМ способен выполнять лишь программу, написанную непосредственно на машинном языке в машинных кодах. Создание программ в таком виде осуществлялось программистами лишь на первых этапах развития вычислительной техники. В настоящее время программирование осуществляется на языках высокого уровня, называемых алгоритмическими, которые предоставляют программисту широкие возможности и способствуют повышению производительности его труда. Перед непосредственным выполнением ЭВМ программы на алгоритмическом языке специальные программы операционной системы, называемые трансляторами, осуществляют ее перевод с алгоритмического языка на машинный.
Функции процессора по управлению вычислительным процессом или по преобразованию информации задаются машинными командами. Существует три основных вида операций преобразования информации процессором:
арифметические операции над числами;
логические операции над алфавитно-цифровыми кодами;
операции передачи информации.
Кроме команд, служащих для преобразования информации, существуют специальные команды для управления работой процессором и ЭВМ.
В зависимости от выполняемых функций команды подразделяются на восемь групп:
1) арифметические команды для работы с числами с фиксированной точкой;
2) арифметические команды для работы с числами с плавающей точкой;
3) арифметические команды для работы с десятичными числами;
4) логические команды для работы с алфавитно-цифровыми кодами;
5) команды пересылки (передачи) информации;
6) команды управления вводом-выводом;
7) команды перехода (передачи управления);
8) команды управления режимами работы процессора и ЭВМ.
Команда состоит из кода операции (КОП), являющегося обязательным атрибутом команды, из заданной в том или ином виде информации об операндах и указания в явном или неявном виде об адресе результата. Код команды состоит из нескольких полей, каждое из которых имеет определенное функциональное значение. Таким образом определяется структура команды. Структура команды с жестко установленным значением каждого бита в каждом поле команды называется форматом.
Существуют различные варианты адресации операндов командами, в зависимости от которых различают одно-, двух-, трех-, четырехадресные, а также безадресные команды, форматы которых показаны на рис. 6.1.
Одноадресная команда содержит код операции и адрес операнда А. При этом второй операнд хранится где-либо в процессоре, заранее подготовленный предыдущей командой и готовый к участию в выполнении операции (рис. 5.6, а).
Двухадресная команда содержит код операции и адреса двух операндов - А1-и А2. Большинство команд двухадресные (рис. 5.6,6).
Трехадресная команда содержит код операции, адреса двух операндов - А1 и А2, а также адрес A3, по которому записывается результат выполнения операции (рис. 5.6,в).
Четырехадресная команда содержит код операции, адреса двух операндов - А1 и А2, адрес результата A3 и адрес следующей команды А4, подлежащей выполнению, В современных ЭВМ этот вид команд не применяется (рис. 5.6, г).
Безадресная команда содержит только код операции, который подразумевает всю недостающую информацию (рис. 5.6, д).
Информация об адресе операнда или об адресе записи результата называется адресным кодом. В общем случае адресный код отличается от исполнительного адреса, т. е. адреса памяти, по которому производится фактическое обращение.
Правильный выбор способа адресации, т.е. механизма формирования исполнительного адреса, является важным условием эффективного написания программы.


Рис. 5.1. Форматы команд Рис. 5.2. Пример базирования адреса
Различают 10 основных способов адресации. Рассмотрим их, сделав, однако, оговорку, что кроме этих способов возможны также их различные комбинации.
1. Непосредственная адресация. В команде содержится непосредственно операнд и при этом не требуется выделения ячейки памяти или регистра для его хранения. Это способ оказывается удобным для организации вычислений с применением различных констант.
2. Прямая адресация. Адрес операнда в явном виде задан в соответствующем поле команды и совпадает с исполнительным адресом.
3. Относительная адресация (базирование). Самый распространенный способ адресации. В адресном коде команды задается некоторое число (В), называемое базовым адресом, и смещение относительно этого адреса D. При этом способе адрес получается с помощью сумматора (См) согласно правилу
![]()
На рис. 2 показан пример базирования адреса. Базирование позволяет облегчить распределение памяти при составлении одной программы несколькими программистами, так как позволяет воспользоваться единой точкой отсчета.
4. Подразумеваемая адресация. В команде не содержится явных сведений об адресах операнда или результата, но они подразумеваются. Например, при выполнении операции умножения подразумевается, что результат записывается по адресу А1. Возможно также использование подразумеваемой адресации в том случае, когда операнд задается кодом команды. Например, при каждом выполнении команды «Переход по счетчику» из содержимого счетчика вычитается «1», хотя в коде команды она отсутствует.
5. Укороченная адресация. Суть ее заключается в использовании только младших разрядов адреса (при этом старшие разряды заранее подразумеваются нулевыми). Этот вид адресации используется лишь для фиксированных ячеек памяти с короткими (малыми) адресами.
6. Косвенная адресация. В адресной части команды указывается адрес ячейки памяти, в которой хранится адрес операнда или команды, т.е. косвенная адресация - это адресация адреса. В некоторых ЭВМ используется многоступенчатая косвенная адресация. В этом случае ячейки памяти содержат специальный разряд-указатель косвенной адресации (УА). Косвенная адресация широко используется в микроЭВМ, имеющих короткую разрядность (16 бит), так как позволяет преодолеть ограничения короткого формата команды. Особенно широко используется косвенная адресация в сочетании с регистровой, образуя автоинкрементную и автодекрементную адресации.
7. Регистровая адресация. В адресной части команды указываются номера регистра, в которых хранятся операнды. Регистровая адресация позволяет повысить производительность процессора за счет уменьшения обращения к ОП.
8. Автоинкрементная и автодекрементная адресации. По сути, оба способа адресации являются регистровой косвенной адресацией и основаны на хранении в регистре косвенного адреса. Если производится приращение к адресу, хранящемуся в регистре, то имеет место автоинкрементная адресация; если производится уменьшение этого адреса, то имеет место автодекрементная адресация. Данные способы адресации являются эффективными лишь при адресации больших массивов данных, так как требуют дополнительных временных затрат на загрузку косвенного адреса в регистр.
9. Стековая адресация. В стековой памяти обслуживание строится по принципу «первым пришел - первым обслуживается». Однако существуют возможности программной организации стековой памяти, которая функционирует аналогично, являясь разновидностью регистровой адресации.
Один из регистров отводится под указатель стека, а за стек принимается группа ячеек памяти с последовательным адресом. При записи в стек нового слова содержимое регистра с указателем стека увеличивается на «1», а при чтении слова из стека - уменьшается на «1». Стековая адресация позволяет организовать вычисления с помощью безадресных команд, которые выбирают из стека операнды, а результаты заносят в стек.
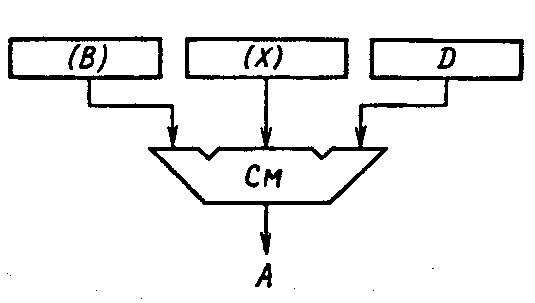
Рис. 5.7. Пример базирования и индексирования адреса
10. Индексная адресация. При обработке, массивов однотипных данных часто возникают цикличности выполнения одних и тех же программ или фрагментов программ, что приводит к необходимости организаций обработки одними и теми же командами различных операндов. Механизм индексирования служит для модификации адресных частей команд (адресов операндов). По сути, индексная адресация является развитием базирования и применяется обычно в комбинации с ним.
Для одновременного использования базирования и индексирования обычно выделяют два РОН в составе МП процессора. Принято обозначать базовый регистр буквой В, а индексный - X; хранящиеся в них адреса - соответственно (В) и (X). На рис. 5.7 показан пример использования базирования и индексирования. Индекс, база и смещение одновременно поступают на сумматор, на котором производится сложение по правилу (В) + (X) + D = А, и таким образом получается исполнительный адрес.
Операнд – элемент данных, над которым выполняется операция. Операнд команды – операнд операции, которая выполняется при интерпретации команды. Операндами являются исходные данные и результаты операции.
Рассмотренные основные способы адресации, применяемые в ЭВМ, тесно связаны с форматами машинных команд.
В разных вычислительных машинах используется различное число форматов команд. Форматы позволяют, например, обрабатывать числа с фиксированной и плавающей точкой, десятичные числа; производить логические операции над алфавитно-цифровыми кодами и т. д.
Например, некоторые форматы команд:
1. Формат RR - «регистр - регистр». Команда занимает 2 байт. Предполагается, что в этом формате операнды находятся в регистрах местной памяти R1 и R2. Результат записывается в R1, при этом значение R2 не изменяется. В командах условного перехода вместо адреса операнда А1 используется поле маски М (маска - условие выполнения перехода), а в поле R2 указывается регистр R, содержащий адрес условного перехода.
2.
Формат RX
- «регистр - индексируемая ячейка»
Команда занимает 4 байт. Адрес операнда
А1 хранится в регистре R1, а адрес
операнда А2 определяется содержимым
индексного Х2 и базового В2 регистров,
а также смещением D2
и вычисляется как А2= =(Х2)+(В2)+D2.
Смещение D
позволяет производить адресацию
относительно базового адреса лишь 4096
байт, так как поле смещения 
Рис.5.8. Форматы команд. занимает длину 12 бит, а 212 = 4096.
3. Формат RS - «регистр - память». Команда занимает 4 байт. В регистрах с адресами R1 и R3 находятся адреса операндов А1 и A3, адрес операнда А2 определяется как А2 = = (В2) + D2. Команды формата RS используются для организации передачи содержимого группы регистров с последовательными номерами R1-R3 в оперативную память, и наоборот.
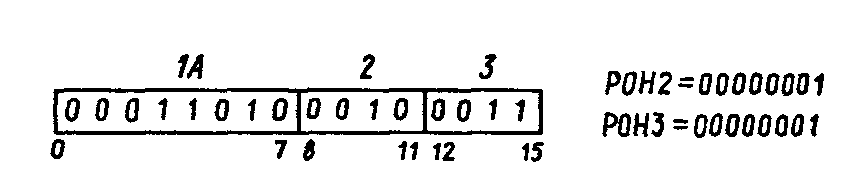
Рис 5.9. Пример выполнения команды сложения формата RR
4 Формат SI - «память - непосредственный операнд». Команда занимает 4 байт. Адрес операнда А1, находящегося в ОП, определяется как А1=B1+D1, а операнд А задается непосредственно в поле I команды. Длина обоих операндов составляет 1 байт.
Рассмотрим два примера выполнения команд: сложения формата RR (рис. 5.9) и записи формата RX. При выполнении команды «сложение - код операции 1А» выполняется действие 1+1=2, а при выполнении команды «запись - код операции 50» содержимое РОН 4 записывается в оперативную память по адресу 600.

Рис 5.10. Форматы команд малых и микроЭВМ
На рис.5.10 показаны основные форматы команд малых ЭВМ или микроЭВМ. Результат выполнения операции всегда помещается по адресу операнда А2. Поле адреса операнда А1 называется «источник», а поле адреса операнда А2 — «приемник». Адресные поля разбиваются на две части по три разряда: в правой указывается номер регистра, а в левой - тип адресации (указатель адресации УА). В зависимости от местоположения операндов команды делятся на три группы: 1) регистр - регистр; 2) регистр - память; 3) память - память Наличие в командах полей указателя адресации (УА), определяющих функции, выполняемые указанными в команде регистрами, позволяет реализовать команды, аналогичные форматам RR, RS, RX, и SI и т.д.
В процессе выполнения программы МП получает сигналы, предупреждающие о возникновении ситуации, требующей с его стороны соответствующей реакции. Эти сигналы получили название сигналов прерывания. Сигналы прерываний используются для того, чтобы снизить непроизводительные потери времени, например, при передаче информации; сигнализировать о возникших отклонениях в работе, таких, как изменение в режиме питания, неисправность некоторых подсистем и др.; при поступлении информации одновременно от нескольких внешних устройств, при работе с низкоскоростными периферийными устройствами т. д.
Поскольку моменты возникновения прерываний заранее не известны, в каждом случае возникновения прерывания блок прерываний (БПр) выставляет в процессор специальные сигналы, называемые запросами на прерывание. Запросы на прерывание могут возникать как внутри ВМ (внутренние прерывания), так и вне ее (внешние прерывания).
Система прерывания ВМ позволяет осуществить идею мультипрограммирования -выполнения одним процессором одновременно большого числа программ за счет организации передачи управления от одной программы к другой.
В некоторых ВМ используются прерывания типа приостановка, когда по соответствующему событию производится на некоторое время остановка хода вычислений. Например, по запросу канала ввода-вывода для передачи информации в ОП приостанавливается процессор и, после того как канал передаст всю информацию, процессор продолжит вычисления.
Сигнал прерывания вызывает в процессоре включение «механизма» передачи управления (рис. 5.11), причем этот сигнал может поступать как от внешних, так и от внутренних источников.

Рис. 5.11 «Механизм» передачи управления прерыванием программ
Классификация видов прерываний показана на рис. 5.12.
Прикладные прерывания временно устанавливаются пользователем при многопрограммной работе МП для указания приоритета выполнения прикладных программ (при появлении необходимости выполнения более приоритетной программы текущая менее приоритетная программа прерывается).
Псевдопрерывания используются для запоминания важных фиксированных адресов, которые могут быть использованы в программах, в частности, при условных и безусловных передачах управления (запоминание адресов передачи управления как векторов прерывания возможно благодаря аналогии выполнения прерывания и обращения к процедурам).
Аппаратные прерывания инициируются при обращениях к МП со стороны внешних устройств (таймера, клавиатуры, дисководов, принтера и т. д.) с требованием уделить им внимание и выполнить совместно с ними те или иные процедуры. Прерывания от таймера, например, повторяются 18 раз в каждую секунду, от клавиатуры - при каждом программно не запланированном нажатии некоторых клавиш и т.п. Аппаратные прерывания не координируются с работой программы и могут быть весьма разнообразны. Для их систематизации и определения очередности выполнения при одновременном возникновении нескольких из них обычно используется контроллер прерываний.

Рис.5.12 Классификация видов прерываний в МП
Программные прерывания — это обычные процедуры, которые вызывает текущая программа для выполнения предусмотренных в ней стандартных подпрограмм, чаще всего подпрограмм - служебных функций работы с внешними устройствами, то есть фактически программные прерывания ничего не прерывают. Программные прерывания делятся на две большие группы, вызывающие служебные функции:
- базовой системы ввода-вывода - прерывания BIOS;
- операционной системы - прерывания DOS.
Программы обработки прерываний DOS, в отличие от программ обработки прерываний BIOS, не встроены в ПЗУ и для разных операционных систем могут быть разными. К программным прерываниям можно отнести также прерывания при пошаговом исполнении программы, при работе с контрольным остановом и т. д.
Технические прерывания (или, иначе, прерывания от схем контроля) возникают при появлении отказов и сбоев в работе технических средств (аппаратуре) ВМ. Большинство технических прерываний не маскируются, то есть они разрешаются всегда, а некоторые из них относятся к категории «аварийных» (например, отключение питания), и при их возникновении даже не запрашивается причина прерывания, а просто, по возможности, спасаются важные промежуточные результаты — записываются в безопасное место, в НЖМД, например.
Логические прерывания возникают при появлении ошибок в выполняемых программах (деление на 0, потеря значности мантиссы, нарушение защиты памяти и т. п.). Многие из логических прерываний также относятся к категории немаскируемых.
Основными функциями системы прерываний программ, являются:
1) запоминание состояния (вектора прерываемой программы;
2) передача управления программам обработки прерываний;
3) восстановление состояния прерванной программы и возврат к ней.
Важными характеристиками системы прерывания являются глубина возможных прерываний и приоритет прерываний. Запросы на прерывание поступают в БПр в произвольные моменты времени, причем не только одновременно, но и в процессе выполнения обработки другого прерывания. Если при выполнении программы обработки прерываний система не реагирует на последующие прерывания, то система называется системой прерывания с единственным уровнем. В такой системе удовлетворение запросов на прерывание осуществляется только после завершения функционирования программы, вызванной другим прерывателем.
Существуют системы, допускающие прерывание различной глубины. Глубина прерывания - максимально возможное число программ, которые могут прерывать друг друга. При этом глубина прерывания равна n, если допускается последовательное прерывание n программ. Глубина возможных прерываний зависит от решаемых задач и определяется организацией очередности при реализации прерываний.
Обычно каждый запрос на прерывание поступает на регистр прерываний, состоящий из триггеров прерываний - по одному триггеру на каждый тип прерываний. При поступлении запроса на прерывание соответствующий триггер устанавливается в «1», фиксируя наличие запроса на прерывание данного типа. Регистр прерываний периодически опрашивается процессором (обычно перед завершением выполнения очередной команды).
Очередность реализации запросов на прерывание устанавливается в соответствии с приоритетами заранее присвоенных каждому типу прерываний. Присвоение приоритетов представляет собой достаточно сложную проблему, при решении которой следует учитывать важность и срочность обслуживания тех или иных запросов. Обычно наивысший приоритет имеют прерывания по машинной ошибке, что объясняется бессмысленностью продолжения вычислений в этом случае. Приоритеты внешних устройств обычно устанавливаются в каналах ввода-вывода.
В определенных условиях работы ВМ может появиться необходимость динамической переоценки приоритетов, например, в управляющих системах для коррекции алгоритмов управления при изменившейся ситуации. При ограниченном количестве запросов такая переоценка реализуется схемным путем, при этом каждому типу запросов выделяется несколько каналов прерываний с различными приоритетами. Блокировкой соответствующих каналов в необходимые моменты добиваются переоценки приоритетов прерываний.
Реализация системы прерывания производится программно и аппаратно. Обычно опрос триггеров прерываний организуется аппаратно, и при наличии хотя бы одного триггера в состоянии «1» формируется общий сигнал прерывания, при появлении которого выполняемая программа прерывается и управление передается в фиксированную ячейку памяти, начиная с которой располагается программа обработки прерываний данного типа. Программа обработки прерываний, прежде чем начать непосредственно обработку прерываний, производит необходимые действия, обеспечивающие в дальнейшем переход к прерванной программе.
При наличии нескольких условий прерывания выявляется причина прерывания, обладающая наивысшим приоритетом, а затем передается управление в ячейку памяти, начиная с которой располагается программа обработки запроса данного типа.
Важное значение для оценки эффективности применения программных и аппаратных средств имеют показатели системы - время реакции системы, время потерь в системе и насыщение системы прерывания - и отвечающие им критерии:
1. Время реакции прерывания - время между появлением запросов на прерывание и началом работы программы обработки прерываний тем меньше, чем эффективнее организована работа системы прерываний. В системах, допускающих прерывания различной глубины, времена реакций существенно зависят также от временных характеристик запросов, обладающих более высоким приоритетом.
2. Время потерь характеризует непроизводительные затраты машинного времени на переключение от одной программы к другой и обратно.
3. Если в момент поступления очередного запроса данного типа предыдущий запрос этого же типа еще не обработан, то наступает насыщение системы прерывания. Данная ситуация в нормальной системе является недопустимой. Основными причинами наступления насыщения могут быть следующие две:
1) отсутствие согласования временных характеристик источников прерывания с блоком прерываний процессора;
2) одновременная работа большего, чем допускается, количества программ и внешних устройств.
Понятием, тесно связанным с системой прерываний, является понятие маски прерывания, представляющей собой двоичный код, разряд которого соответствует тому или иному классу прерываний. Маска обычно хранится в регистре маски или в каком-либо управляющем регистре и устанавливается программным путем. Состояние бита маски «1» разрешает, а состояние «О» запрещает (блокирует) прерывание данного типа.
Рассмотрим особенности системы прерываний малых ЭВМ и микроЭВМ.
В малых ЭВМ и микроЭВМ все прерывания подразделяются на два типа:
1) внутренние прерывания, к которым относятся:
а) программные прерывания по ошибочной адресации и недействительному коду операций;
б) прерывания по напряжению сети питания ниже допустимого уровня и по восстановлению его нормального уровня;
в) прерывания по разряду слежения, возникающие в том случае, если при выполнении программы разряд слежения устанавливается «1»;
2) внешние прерывания, которые вызываются периферийными устройствами.
Рассмотрим последовательно процесс передачи информации при организации прерывания МП. При поступлении импульсов от внешнего источника в МП входной регистр будет работать в режиме регистра сдвига. Допустим, что информация, поступившая на шестнадцатиразрядный РгВх, затем должна считываться в параллельном коде. Пусть при этом поступление каждого импульса на РгВх происходит за один такт. В этом случае микропроцессор сможет получать 16-разрядное слово (2 байта) через каждые 16 тактов, так как только за 16 тактов информация последовательно, импульс за импульсом, разместится во входном регистре. Естественно, что при этом между каждым поступлением нового слова будет происходить задержка в их обработке. Во время ожидания окончания поступления нового слова МП следит за состоянием РгВх и находится в бездействии.
Режим прерывания дает возможность МП использовать свободные промежутки времени для выполнения другой части программы. Когда очередное слово сформировалось в РгВх и готово для обработки, сигнал прерывания информирует об этом МП, и он выполняет ряд действий по приему поступившего слова и возвращению к прерванной части программы.
30. В каких целях используется аккумулятор в центральном процессоре?
1. для передачи данных
2. для питания
3. для выполнения вычислений
4. для индикации данных
5. для регистрации данных
31. Какой процессор не является однокристальным?