

Лабораторная работа №1. «Анализ основных параметров качества аис»
Постановка задачи. Основной целью решению задачи является получение практических навыков в моделировании процесса изучения существенных характеристик функционального состояния исследуемой АИС как наиболее распространенного класса ИР, а также закрепления теоретических значений, полученных в лекционном курсе.
Решение задачи базируется на применении средств системного анализа, теории вероятностей и математической статистики. Работа состоит в том, чтобы на основе собранного статистического материала выполнить анализ функционального состояния АИС программными средствами диалоговой системы STADIA. На основе анализа вырабатываются стратегия и тактика рационализации функционирования АИС.
В ходе исследования реально функционирующей АИС методом прямого наблюдения обнаружены и зафиксированы в «Ведомости дефектов» ошибки по достоверности документной информации, допущенные на различных этапах технологии АИС. Дефекты по достоверности могут иметь различные модификации, например замена истинного символа (символов) на другой (ошибочный), транспозиция («наползание») цифр показателя, пропуск реквизита–основания показателя, сбой программы, откат компьютера и др.
В технологии АИС обнаружение и исправление дефектов, в частности по достоверности, снижает эффективность использования временных, финансовых, трудовых и иных ресурсов. Это отрицательно влияет на качество АИС, например, на ее выходные характеристики – производительность АИС, себестоимость обработки документов и др.
В данном примере выборка дефектов по достоверности представлена во временной шкале измерения – в минутах. В каждый дефект как случайное событие представлен количеством минут, затраченных на обнаружение и исправление дефекта по достоверности. Исходные статистические данные идентифицируем как переменную х1, состоящую из 30 значений: 3, 1, 5, 2, 4, 6, 1, 4, 2, 5, 6, 4, 6, 45, 2, 4, 3, 7, 5, 4, 6, 4, 3, 5, 4, 5, 3, 5, 4, 3.
Основные этапы решения. Решение данной задачи состоит из нескольких этапов:
1. Ввод статистических экспериментальных данных. В нашем случае применяется ППСА STADIA. Ввод данных производится посредством набора на клавиатуре экспериментальных данных, указанных выше, в форме электронной таблицы или матрицы данных. Данные по каждой переменной записываются в соответствующий вектор-столбец матрицы (в нашем примере в столбец х1 электронной таблицы (рис.1.1)).
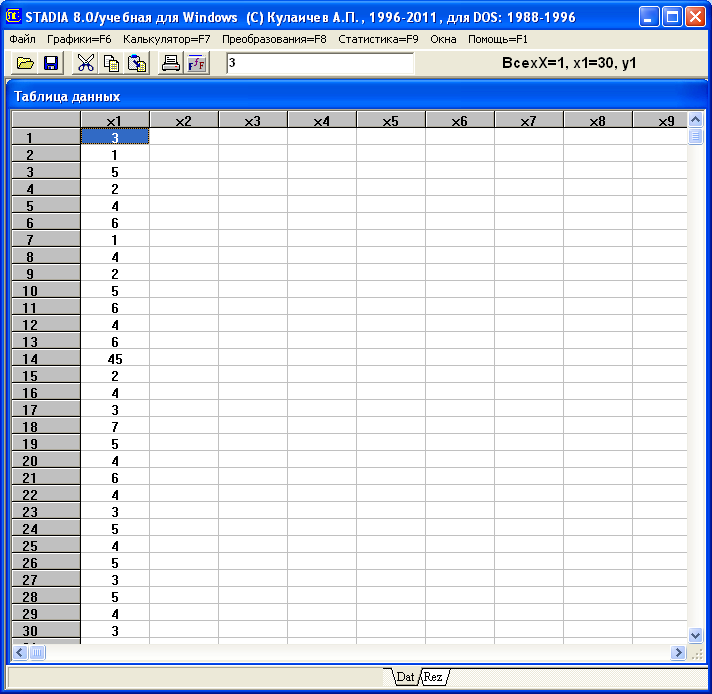
Рис. 1.1 Ввод исходных данных
2. Получение описательной статистики основных параметров АИС по достоверности. Для расчета значений описательной статистики щелкнуть мышкой по меню «Статистика». В появившемся подокне «Статистические методы» в подменю «Параметрические тесты» щелкнуть мышкой по опции «Описательная статистика» (рис. 1.2) появится подокно «Анализ переменных».

Рис. 1.2 Структура подокна «Статистические методы»
Из субполя «Переменные» переменную х1 необходимо переслать в субполе «Для анализа». Для этого сначала нужно выделить переменную х1, щелкнув по ней однократно левой клавишей мышки, а затем щелкнуть левой клавишей по кнопке Стрелка вправо и поместить переменную х1 в субполе «Для анализа».
Чтобы устранить повторы в операционном решении последующих задач, в частности числа рисунков, дадим некоторые пояснения по интерфейсу. В данном подокне кнопки Стрелка влево и Стрелка вправо служат для пересылки переменных из одного субполя в другое. Нажатие кнопки «Все» реализует команду по перемещению всех переменных в необходимое субполе. Для вычисления и вывода статистических оценок необходимо кликнуть кнопку Утвердить, после чего получим результат расчета по переменной х1 (рис. 1.3). Под рубрикой «ОПИСАТЕЛЬНАЯ СТАТИСТИКА. Файл» приведены краткие данные, которые в нашей задаче следует понимать так: Переменная – х1, Размер [выборки] (число значений по переменной х1) – 30, Диапазон значений – от 1 до 45 мин., Среднее [выборочное значение] – 5,367 мин., Ошибка – 1,394, Дисперсия – 58, 31, Стандартное отклонение – 7,636, Сумма [всех значений данных переменной х1] – 161.
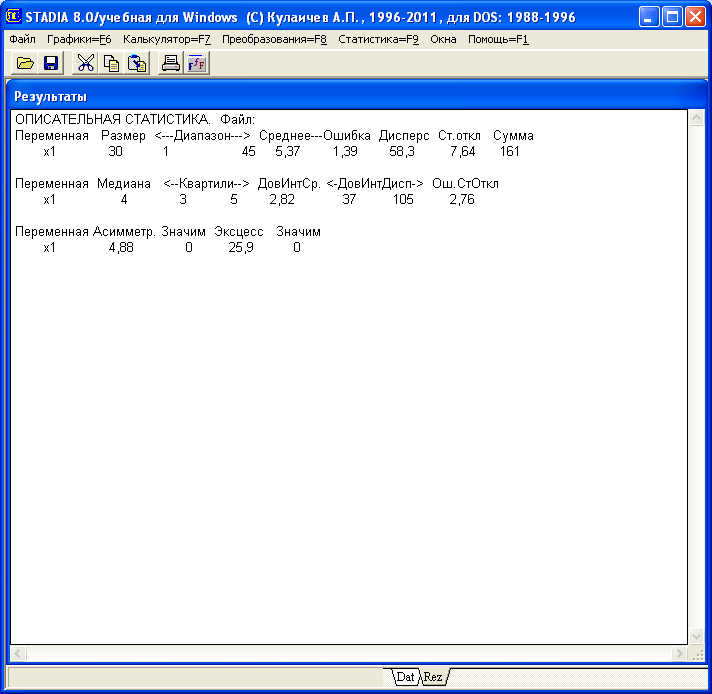
Рис. 1.3 Результаты расчета статистических оценок и дополнительной статистики
Если необходимо получить дополнительные статистические оценки, нужно кликнуть в подокне “Confirm” кнопку YES, в противном случае – кнопку NO. В нашей задаче после активизации кнопки YES получаем результаты с набором дополнительных статистических оценок по переменной х1 (рис. 1.3).
При необходимости записи оценок по параметрам «Среднее», «Стандартное отклонение» и «Сумма в матрицу данных», т.е. в электронную таблицу данных, нужно кликнуть в подокне “Confirm” кнопку YES, в противном случае – кнопку NO.
В рубрике «ОПИСАТЕЛЬНАЯ СТАТИСТИКА» в ходе исследования даются основные параметры, характеризующие собранные данные о дефектах по достоверности, в частности: выборочное среднее значение, разброс значений или стандартное отклонение, характеристики формы распределений значений – мода, медиана, асимметрия, эксцесс, квартили и т.д.
Результаты обработки данных представляются в виде соответствующих экранов – исходных данных, результатов вычислений и построенных графиков. Вызов и смена экранов выполняются щелчком мышки по соответствующей надписи (Dat, Rez) в нижней командной линейке экрана.
Приведем краткие определения и пояснения некоторых понятий описательной статистики. Полное описание и порядок вычисления значений оценок в ППСА STADIA изложены в [2,3].
Выборочное среднее – среднее выборочное значение, вычисляемое как сумма всех значений, деленная на их число.
Медиана m – выборочное значение, которое делит выборку пополам: число выборочных значений, меньших m, равно числу выборочных значений, больших m. При симметричном распределении значений переменной выборочное среднее обычно близко к значению медианы.
Квартили – два выборочных значения, которые относительно медианы делят выборку на четыре равные части.
Стандартное, или среднеквадратическое, отклонение показывает, насколько сильно выборочные значения разбросаны относительно среднего. Для нормально распределенных данных в границах двух стандартных отклонений относительно среднего значения размещается несколько более 95% наблюдений. Эта оценка используется в экспериментальных исследованиях ИР для обозначения лабораторной нормы.
Дисперсия – близка к квадрату стандартного отклонения, но в отличие от него дисперсия обладает свойством аддитивности: сумма дисперсий нескольких выборок равна дисперсии объеденной выборки.
Ошибка среднего – характеристика точности вычисления среднего значения с учетом разброса выборочных значений и объема выборки. Для нормально распределенных данных в границы двух ошибок с вероятностью 95% попадет оцениваемое среднее значение генеральной совокупности, что соответствует 95%-ному доверительному интервалу среднего.
Доверительны интервал – для некоторой выборочной оценки (среднего, дисперсии, доли и др.) – диапазон значений наблюдаемой случайной переменной, который с заданной (доверительной) вероятностью содержит неизвестное генеральное значение оцениваемой характеристики этой переменной. Например, среднее выборочное значение оценивается (вычисляется) по ограниченной выборке из потенциально бесконечной генеральной совокупности, которая априори содержит неизвестную случайную ошибку, т.е. отклонение от генерального среднего. Ошибка будет статистически уменьшаться при увеличении объема выборки при снижении заданной точности такого предсказания (доверительная вероятность). Так, 95%-ный доверительный интервал относительно вычисленного выборочного среднего означает, что в этом диапазоне с вероятностью 95% содержится оцениваемое генеральное среднее. Доверительные интервалы могут служить эффективным средством количественной проверки статистических гипотез.
Асимметрия и эксцесс характеризуют степень не симметрии выборочного распределения относительно среднего значения и степень выраженности его центрального пика. Для нормального закона распределения эти показатели имеют следующие значения: асимметрия = 0 (события распределены симметрично относительно среднего значения выборки), эксцесс = 3.
3. Визуализация данных. Для выбора тактики дальнейшего анализа целесообразно применить графическое представление – визуализацию данных посредством отображения переменной х1 на графике. Для этого в главном окне STADIA кликнуть мышкой меню «Графики», после чего появится подокно «Графики данных» (рис. 1.4). Затем в группе опций «Научные» кликнуть кнопку «1=функции: Y=f(X)», после чего появится подменю «Графики данных».
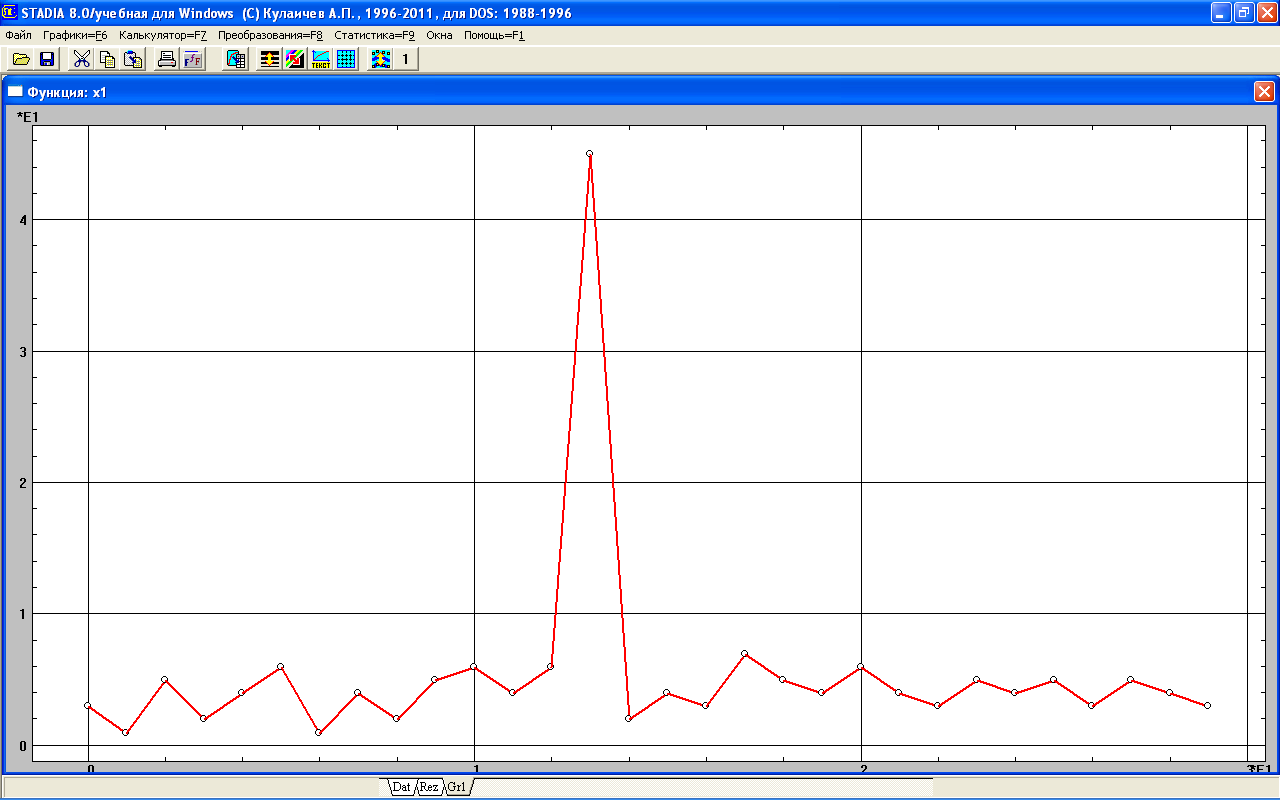
Рис. 1.4 График распределения переменной х1
В появившемся подокне «Графики данных» в субполе «Переменные» выделить мышкой переменную х1 и переслать ее в субполе «На графике», это позволить проанализировать значения переменной х1. Как видно из графика, распределение переменной х1 в основном равномерно, но одно значение (45 мин), которое не согласуется с общим характером выборки, заходит за границы переменной. Наличие подобного значения – выброса, или флуктуации, - как правило, искажает картину экспериментальных данных и может снизить качество моделирования. Для его устранения в моделировании применяют способ фильтрации данных, или преобразования данных.
4. Преобразование данных. Данные в электронной таблице необходимо просмотреть и скорректировать, например, удалить или сгладить высокоамплитудные выбросы. Так, в нашем случае 14-1 дефект продолжительностью 45 мин явно не репрезентативен, поэтому его значение целесообразно заменить на близкое к значению средней выборочной, полученному в результате вычислений. Вычисленное нами среднее выборочное равно 5,367, заменим в электронной таблице значение 45 на округленное значение 5. По отфильтрованным данным путем реализации описанных выше последовательных команд получим более адекватные статистические оценки (рис.1.5).
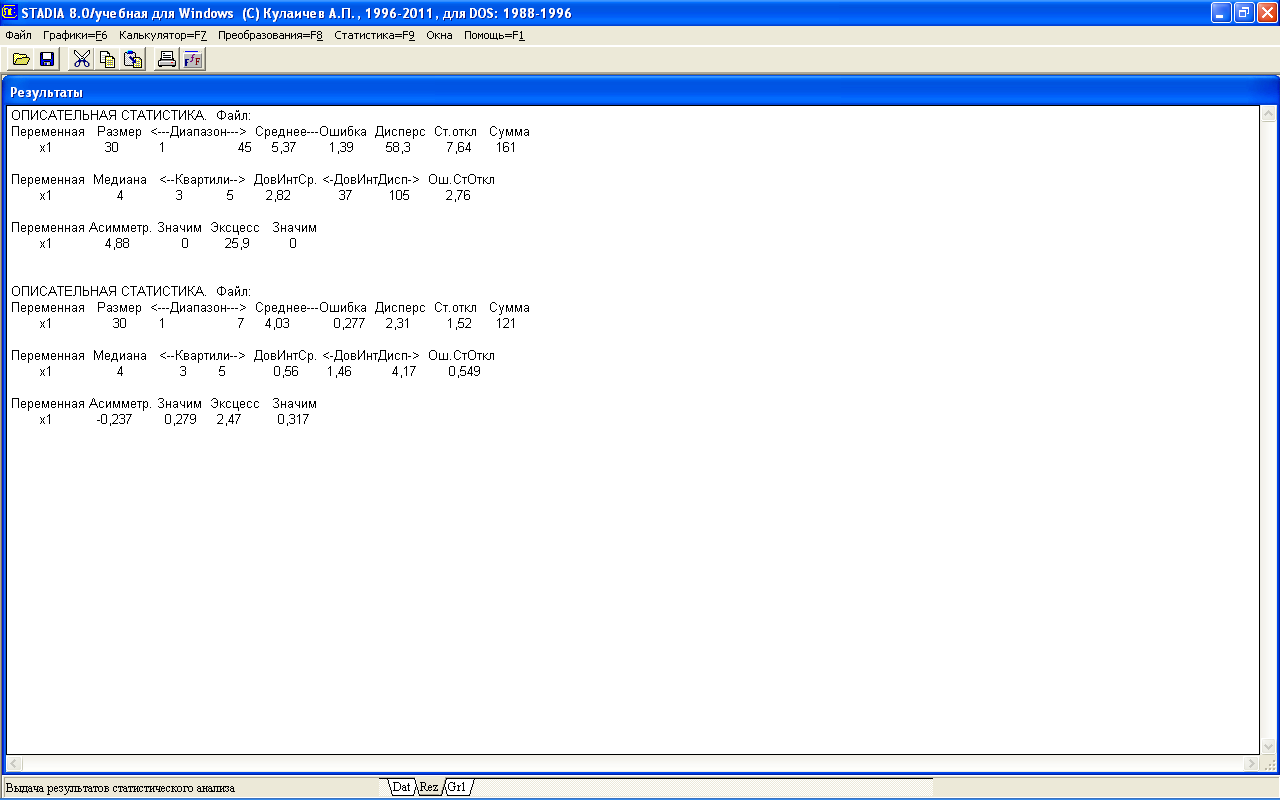
Рис.1.5 Результаты расчета описательной статистики до фильтрации и после фильтрации экспериментальных данных
Для расширения аналитической базы построим график по отфильтрованным экспериментальным данным (рис.1.6).
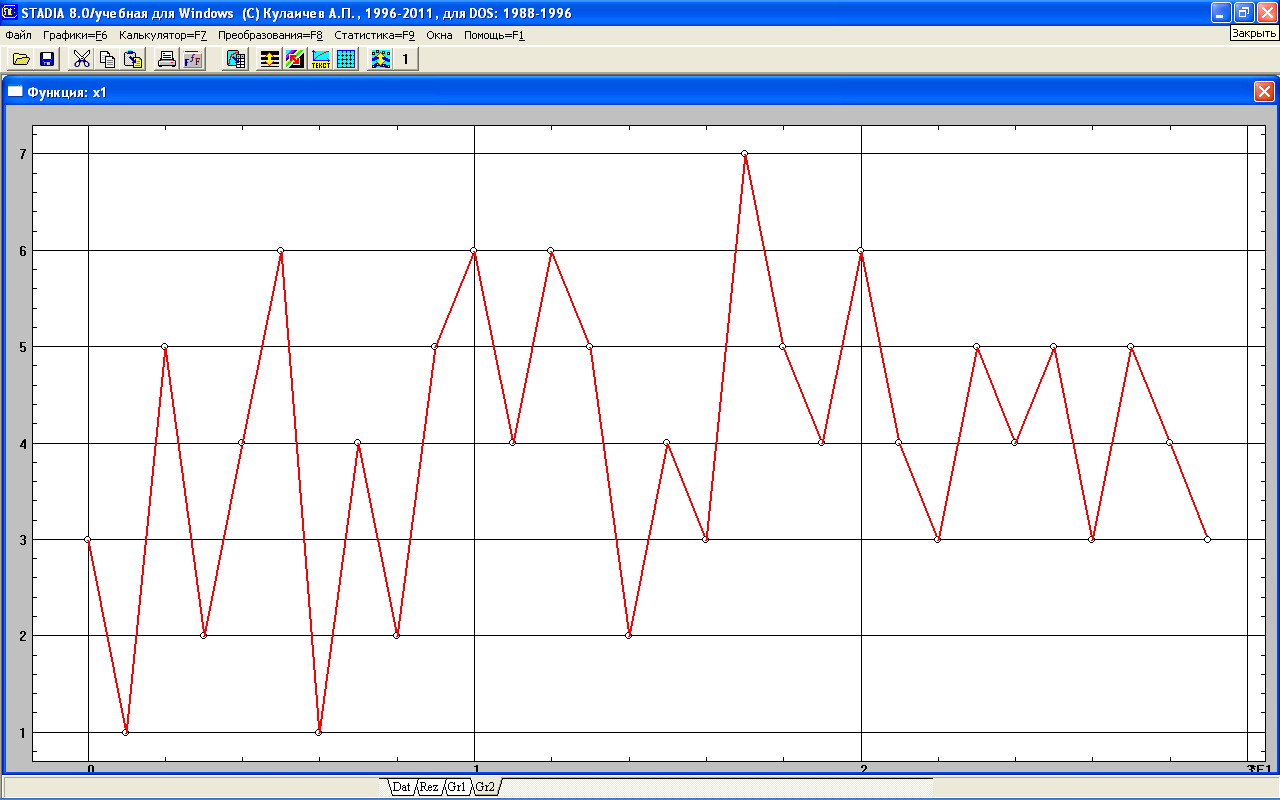
Рис. 1.6 График отфильтрованных данных переменной х1
5. Анализ функционального состояния АИС по критерию доверительности информации. Априори можно предположить следующее. Ошибки (искажения) истинного значения содержавшихся в документах данных отрицательно влияют на эффективность технологического процесса АИС. Так как в моделировании функционального состояния АИС большое значение имеет адекватность привлекаемых к моделированию данных, необходимо провести сравнительный анализ полученных экспериментальных данных до фильтрации и после.
Анализ базовых статистических оценок подтверждает, что фильтрация положительно влияет на достоверность привлекаемых к моделированию экспериментальных данных, следовательно, и на адекватность модели анализа. Например, среднее выборочное обнаружения и исправления дефекта по достоверности до фильтрации составляло 5,367 мин, а после фильтрации – 4,033 мин. Таким образом, этот показатель в результате уточнения скорректирован на 25%. Практически это означает, что в информационно-вычислительной структуре при организации технологического процесса обработки данных трудоемкость процедур диагностики и коррекции дефектов по достоверности обрабатываемых данных может быть снижена на 25%, следовательно, при определенных условиях может быть сокращена штатная численность работников, занятых в технологии обработки данных АИС.
Точность расчета среднего выборочного подтверждается следующими оценками. Если до фильтрации значение ошибки составляло 1,394, то после фильтрации стало существенно меньше 0,2774. Подобное влияние наблюдается и по таким параметрам, как дисперсия и стандартное отклонение. Дополнительные статистические оценки так же подтверждают лучшее качество отфильтрованных данных. Например, если до фильтрации значимость относительно асимметрии и эксцесса имела нулевые значения, то после фильтрации значимость стала более адекватной – соответственно 0,2795 и 0,3171. Это логично, так как значения оценок асимметрии и эксцесса для отфильтрованных данных равны соответственно 0,2369 и 2,473, что намного ближе к стандартам математической статистики (нормальное распределение): 0 для асимметрии и 3 для эксцесса, чем у данных до фильтрации – соответственно – 4,875 и 25,9.
6. Формулирование выводов. Выводы целесообразно построить в соответствии с этапами выполнения работы, сформулировав по каждому из этапов резюме по наиболее существенному аспекту этапа. Выводы должны быть связаны между собой, так же как и этапы решения задачи. Содержание выводов должно отражать, с одной стороны, последовательность решения задачи, а с другой – содержание этапа, его место и значение в комплексе работ по решению задачи. Полезно дать собственную оценку эффективности пакета STADIA в решении задачи. После формулирования выводов необходимо еще раз проверить качество полученных результатов по решению задачи.
7. Составление и оформление ответа следует выполнить в соответствии с требованиями, изложенными выше.
|
Варианты заданий |
|||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
3 |
6 |
4 |
8 |
10 |
5 |
6 |
5 |
8 |
6 |
|
7 |
7 |
4 |
4 |
8 |
8 |
10 |
4 |
9 |
5 |
|
9 |
9 |
10 |
9 |
3 |
10 |
8 |
4 |
7 |
6 |
|
9 |
10 |
5 |
5 |
9 |
6 |
9 |
10 |
5 |
9 |
|
4 |
11 |
5 |
9 |
7 |
9 |
6 |
11 |
8 |
9 |
|
2 |
11 |
10 |
1 |
6 |
5 |
9 |
8 |
10 |
10 |
|
0 |
8 |
4 |
4 |
8 |
5 |
5 |
10 |
2 |
7 |
|
37 |
10 |
3 |
8 |
9 |
2 |
8 |
8 |
9 |
5 |
|
5 |
2 |
6 |
56 |
9 |
4 |
2 |
4 |
1 |
7 |
|
1 |
2 |
11 |
9 |
2 |
2 |
4 |
11 |
9 |
2 |
|
4 |
5 |
44 |
10 |
1 |
5 |
4 |
11 |
7 |
9 |
|
0 |
5 |
2 |
8 |
11 |
4 |
9 |
8 |
5 |
3 |
|
9 |
22 |
7 |
1 |
10 |
11 |
4 |
2 |
2 |
8 |
|
7 |
25 |
7 |
3 |
6 |
9 |
4 |
11 |
5 |
10 |
|
5 |
6 |
11 |
6 |
6 |
8 |
7 |
34 |
43 |
2 |
|
3 |
5 |
11 |
5 |
7 |
10 |
8 |
7 |
7 |
10 |
|
9 |
5 |
9 |
9 |
7 |
11 |
8 |
2 |
6 |
10 |
|
6 |
9 |
6 |
6 |
8 |
66 |
2 |
5 |
6 |
9 |
|
7 |
5 |
10 |
4 |
45 |
7 |
4 |
3 |
7 |
7 |
|
7 |
9 |
10 |
7 |
5 |
4 |
1 |
6 |
2 |
8 |
|
8 |
6 |
7 |
5 |
1 |
8 |
8 |
11 |
6 |
3 |
|
4 |
8 |
10 |
3 |
1 |
3 |
2 |
4 |
5 |
9 |
|
2 |
10 |
7 |
8 |
9 |
8 |
3 |
6 |
9 |
1 |
|
1 |
4 |
7 |
9 |
1 |
10 |
1 |
10 |
5 |
9 |
|
4 |
10 |
4 |
10 |
5 |
8 |
7 |
11 |
7 |
11 |
|
1 |
7 |
3 |
4 |
6 |
4 |
10 |
10 |
10 |
1 |
|
4 |
6 |
9 |
7 |
1 |
3 |
48 |
10 |
3 |
2 |
|
4 |
10 |
4 |
8 |
6 |
6 |
4 |
8 |
6 |
47 |
|
7 |
11 |
11 |
6 |
5 |
6 |
5 |
7 |
10 |
6 |
|
3 |
6 |
7 |
10 |
8 |
11 |
10 |
7 |
2 |
9 |
Контрольные вопросы
-
Какие факторы влияют на выбор методов и средств для решения задач МИР?
-
Охарактеризуйте основные этапы решения задач МИР в их логической последовательности.
-
При каких условиях применяется фильтрация экспериментальных данных?
-
По каким критериям в ППСА STADIA статистические оценки разделены на основную и дополнительную статистику?
-
Какая связь между адекватностью модели ИР и проверкой экспериментальных данных на из согласие закону распределения?
-
Какие параметры следует привлекать для оценки эффективности АИС в моделировании ИР?
-
Как проводится проверка адекватности регрессионной модели в МИР?