

Лабораторная работа №2. «Определение закона распределения экспериментальных данных о качестве технологического процесса обработки данных»
Постановка задачи. Основной целью решения задачи является получение практических навыков в моделировании закона распределения экспериментальных данных о качестве технологического процесса в АИС, а также закрепление теоретических сведений, полученных в лекционном курсе.
Решение задачи базируется на применении средств теории вероятностей и математической статистики [2,3]. В работе посредством последовательных вычислительных процедур должен быть установлен статистический закон распределения, которому подчиняются экспериментальные данные о дефектах технологического процесса обработки данных АИС. Необходимые вычисления выполняются программными средствами диалоговой системы STADIA. На основе результатов вычисления определяется закон распределения, в соответствии с которым выполняются последующие вычисления в процессе моделирования и улучшения качества технологического процесса обработки данных.
В практике экспериментального исследования АИС надежность и достоверность результатов исследования в значительной мере зависят от точности экспериментальных данных случайной выборки, полученной в ходе наблюдения и сбора данных о дефектах, возникающих на различных этапах технологического процесса обработки данных АИС. При этом очень часто возникает необходимость ответить на следующие вопросы: какова вероятность тех событий, которые отражает статистическая структура дефектов, т.е. экспериментальные данные? Каковы точность, надежность вычислительных результатов, получаемых на основе обработки экспериментальных данных? Какая методика вычислений позволит получить адекватную модель исследуемого технологического процесса обработки данных или какого-либо другого вида ИР? Обоснованность этих вопросов обусловливается многими причинами. Одной из них является то, что АИС и ее компоненты, в частности технологический процесс обработки данных, в силу своего человеко-машинного характера относятся к классу вероятностных систем. Разумеется, собранные экспериментальные данные и результаты их обработки будут отражать вероятностный характер технологии обработки данных, а качество модели ИС зависит от уровня надежности, достоверности результатов расчетов, которые определяются уровнем надежности исходных экспериментальных данных. Для повышения надежности результатов вычислений и улучшения качества моделирования необходимо определить характер экспериментальных данных путем выявления закона, которому подчиняются экспериментальные данные о дефектах.
Расчетные работы по моделированию ИР, как правило, базируются на наборе исходных экспериментальных данных, в частности на оценках описательной статистики (см. ЛР №1). Надежность последних увязывается с определением закона распределения вероятностей, которому подчиняются случайные числа выборки.
В качестве исходных экспериментальных данных выступает выборка по дефектам полноты данных в документах. Такими дефектами являются отсутствие (пропуски) необходимых чисел, слов, показателей и других обязательных элементов документов, текстов, файлов, сообщений, зафиксированных на различных носителях или передаваемых по каналам связи.
Приведем последовательность получения исходных данных для экспериментальной оценки качества обработки информации реальной ИС корпоративного уровня.
На первом этапе производятся учет и прием первичных документов – заполненных учетных бланков (УБ), поступающих от подчиненных предприятий в ИВЦ организации; взята выборка объемом 101 пачка УБ. Дефектной считается та пачка, которая поступала с опозданием, после срока, установленного организацией. Каждая пачка регистрировалась случайным событием в ведомости дефектов отдельной строкой. На данном этапе также выявлялись дефекты по полноте – отсутствие значений показателей в УБ. Объем выборки в данном случае составил 250 УБ. Дефекты по достоверности на данном этапе не проявились.
На втором этапе (прием УБ после их индексирования (кодирования) в ИВЦ) путем анализа УБ и журнала регистрации приема УБ от предприятий методом случайных чисел была взята выборка объемом 164 пачки УБ за определенный период. Техническими условиями по плану-графику установлено время кодирования – 200 УБ за рабочую смену, поэтому как дефектные идентифицировались те пачки УБ, время кодирования которых превысило установленное. На данном этапе дефектов по полноте обнаружено не было, а дефекты по достоверности не выявлялись.
На третьем этапе (компьютерный ввод УБ и обработки документации) была взята выборка объемом 200 УБ и дефекты по своевременности и полноте не обнаружены.Дефекты по достоверности регистрировались отдельной строкой в ведомости.
На четвертом этапе обработки (выдача исходных (результатных) документов абонентам ИС) взята выборка объемом 4806 УБ, в которой были выявлены только дефекты по достоверности – 10 ошибочных символов.
В технологических процессах обработки данных АИС на обнаружение и исправление указанных дефектов расходуются временные, трудовые, аппаратные, программные и финансовые ресурсы. В данной выборке из 30 чисел каждое число представляется дефектом по полноте и измеряется в минутах: 9, 12, 11, 14, 16, 11,14, 12, 15, 12, 14,12, 13, 11, 14, 13, 10, 15, 13, И, 12, 10, 12, 13, 12, 14, 11, 13, 16, 13.
Основные этапы решения. Решение данной задачи состоит из нескольких этапов.
1. Ввод статистических экспериментальных данных. Компьютерный ввод экспериментальных данных в объеме 30 чисел (см. ЛР №1) выполняется в соответствии с регламентом ввода, указанным в ЛР №1. В результате процедуры ввода в электронной таблице в столбце xl размещаются 30 значений, формирующих переменную х 1. При отсутствии ошибок ввода следует приступить к следующему этапу.
2. Проверка распределения экспериментальных данных на нормальность. Общепринятой формой представления выборочного распределения является гистограмма. При ее построении диапазон изменения выборочных значений разбивают на равные интервалы и подсчитывают число значений, попадающих в каждый интервал. При графическом представлении гистограммы на каждом интервале строится прямоугольник высотой, пропорциональной числу выборочных значений, попавших в интервал.
Для запуска процедуры проверки распределения на нормальность необходимо через меню «Статистика» обратиться к подменю «Статистические методы» и в разделе «Параметрические тесты» кликнуть кнопку 2=Гистограмма/нормальность, после чего появится подокно «Гистограмма».
В этом подокне программа предлагает пользователю число интервалов гистограммы (в нашем случае — 6) с указанием левой и правой границ. Пользователь имеет возможность по своему усмотрению изменить число интервалов. Но поскольку программный модуль определяет рациональное число интервалов, то целесообразно согласиться с предлагаемым программой числом интервалов.
Далее следует кликнуть кнопку Утвердить, после чего появится окно Результаты, содержащее данные по гистограмме и тесту нормальности, а также подокно «Confirm» с вопросом Сохранить гистограмму в матрице данных? (рис. 2.1).
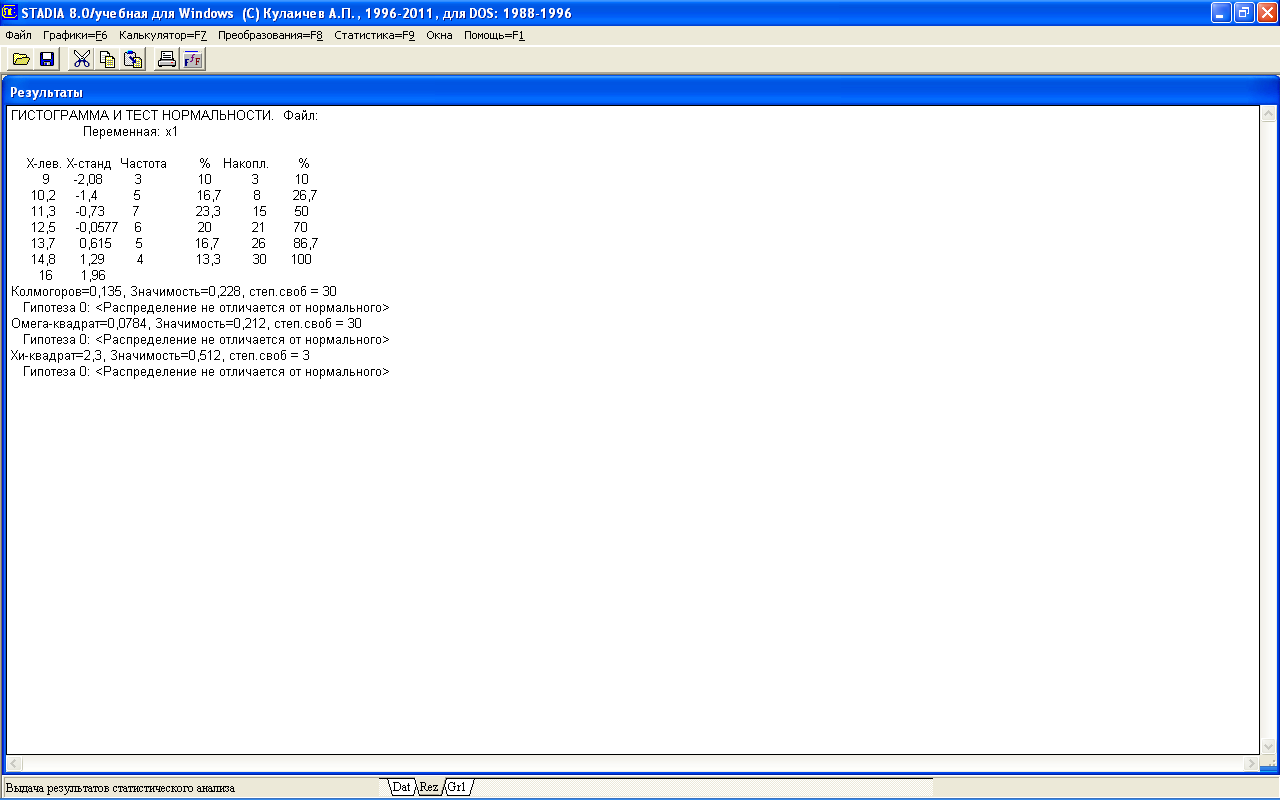
Рис. 2.1 Окно «Результаты», отображающее данные по гистограмме и тесту нормальности
Для получения полного состава данных по проверке экспериментальных данных на нормальность надо кликнуть кнопку Yes, после чего появится гистограмма (рис. 2.2).
В подокне «ПОСМОТРИТЕ ГРАФИК» нужно кликнуть кнопку Оставить, чтобы сохранить гистограмму в окне Grl.
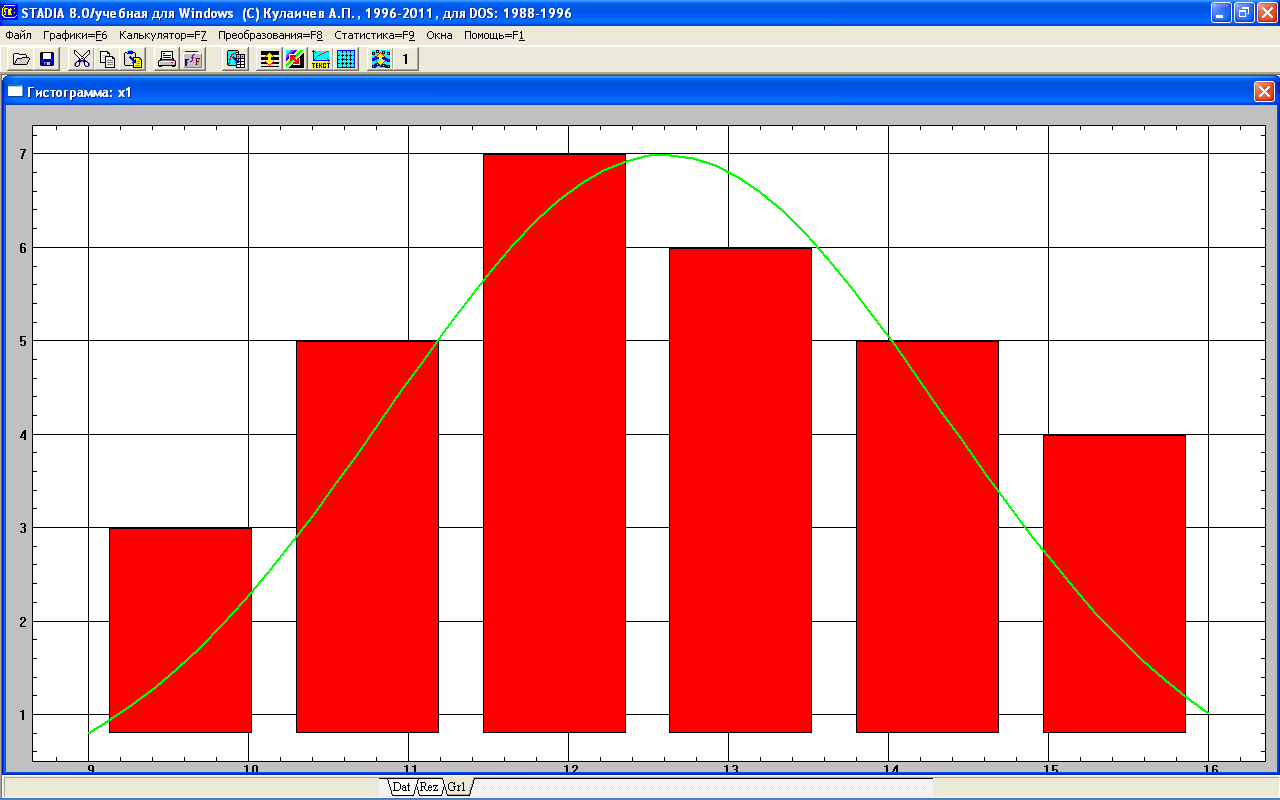
Рис. 2.2 Гистограмма дефектов по показателю полноты данных
Под записью Переменная: xl для каждого интервала гистограммы на экран выводятся значения: Х-лев — левая граница интервала в исходных единицах; Х-станд — значения в единицах стандартного отклонения; Частота — число выборочных значений, попавших в интервал; % — доля выборочных значений, %; Накопл. — накопленное число выборочных значений, включая текущий интервал; % — накопленная доля выборочных значений, включая текущий интервал.
Затем проводится проверка нулевой гипотезы об отсутствии различий между выборочным распределением и нормальным и расчет трех статистик (критериев):
-
критерия Колмогорова, который реагирует на наибольшую разность между распределениями, обычно появляющуюся вблизи максимума функции плотности вероятности, поэтому он плохо адаптирован к выявлению различий на концах («хвостах») распределений;
-
критерия омега-квадрат, который является более равномерным, учитывает различия между распределениями на всем интервале выборочных значений, однако он менее исследован в плане составления таблиц критических значений и предельных аппроксимаций для распределений различных типов;
-
критерия хи-квадрат, который также довольно равномерно учитывает различия во всем диапазоне выборочных значений, однако требует большей осторожности при применении к непрерывным распределениям, поскольку его результаты существенно зависят от объема выборки и разбиения выборочного пространства на интервалы.
По каждому критерию определены три параметра — собственно значения критерия, значимость и степень свободы.
Проверка выборочного распределения на нормальность может быть выполнена несколькими способами, которые дополняют друг друга:
-
визуальный способ в качестве предварительной субъективной оценки — по виду гистограммы выборочного распределения, которая сравнивается с представленной кривой плотности вероятности нормального распределения;
-
проверка нулевой гипотезы соответствия распределений по коэффициентам асимметрии и эксцесса (см. ЛР №1); в математической статистике индикатором для проверки нулевой гипотезы наряду с другими данными служит уровень значимости Р. Нулевая гипотеза может быть принята при Р>0,05. В нашем случае уровни значимости Р по критериям Колмогорова, омега-квадрат и хи-квадрат соответственно равны 0,2281, 0,2124, 0,5119, что указывает на возможность принятия нулевой гипотезы о соответствии экспериментальных данных нормальному закону распределения;
-
проверка соответствия формы распределений по критериям Колмогорова, омега-квадрат и хи-квадрат.
3. Уточнение закона распределения. Чтобы более точно определить закон распределения случайных величин выборки, прибегают к проверке распределения на соответствие конкретному закону. Для установления закона следует кликнуть мышкой меню «Статистические методы», в подполе «Распределения и частоты» кликнуть мышкой кнопку Согласие распределений, после чего на экране появится подокно «Распределения».
Средствами ППСА STADIA можно выполнить проверку наиболее часто встречающихся в практике законов распределения: нормального, экспоненциального, Релея, Вейбулла, логистического, экстремальных значений, Эрланга, логнормального.
В диалоговом окне законов распределения нужно выбрать путем последовательной проверки и анализа распределений наиболее адекватный вид распределения для исследуемой выборки. При этом наиболее близкий закон подбирается визуально — по расстоянию от центра интервальных «сгустков» случайных величин до кривой плотности вероятности распределения. Как правило, проверку начинают с нормального распределения, для чего следует кликнуть мышкой кнопку Нормальное, после чего получим график (рис. 2.3).
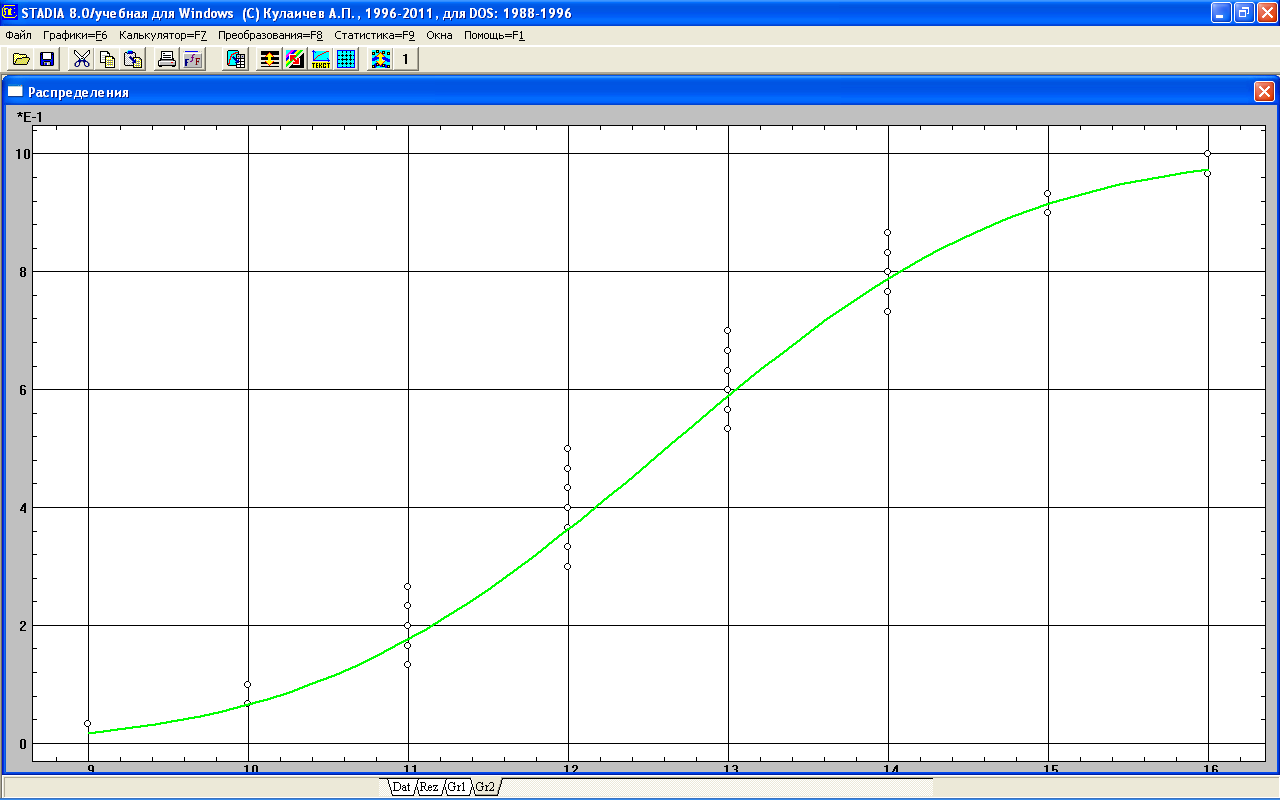
Рис.2.3 График проверки данных на соответствие нормальному закону
На графике линией отображаются теоретические параметры закона нормального распределения, а расположенными вертикально точками — интервальное распределение фактических экспериментальных (эмпирических) данных. График на рис. 2.3 довольно четко показывает совпадение теоретической функции с эмпирической функцией распределения как по центральной части гистограммы, так и на ее «хвостах», т.е. левой и правой частях распределения. Более точное заключение можно дать на основе результатов расчета статистических параметров распределения.
Для дальнейшего отображения графика на рабочем листе Grl электронной таблицы в верхнем окне «ПОСМОТРИТЕ ГРАФИК» надо кликнуть мышкой кнопку Оставить, после чего в рабочем листе «Результаты» появится отображение результатов расчетов по проверке соответствия экспериментальных данных параметрам закона нормального распределения (рис. 2.4).
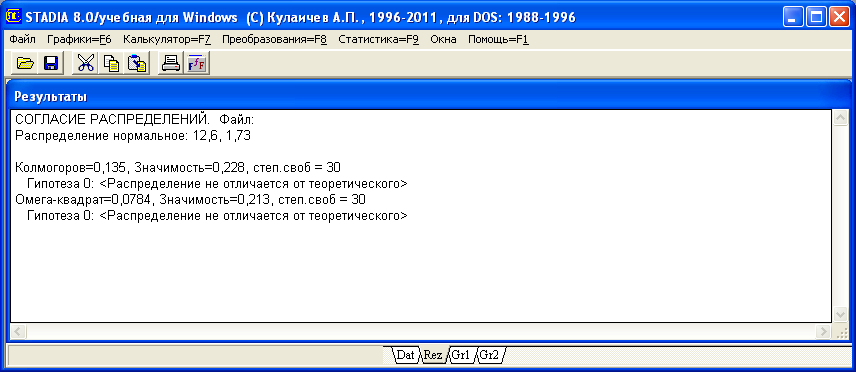
Рис.2.4 Подокно «Результаты» с отображением оценок соответствия данных закону нормального распределения
В рубрике «Распределение нормальное» даны два параметра — среднее выборочное значение (в нашей задаче время обнаружения и исправления дефекта по полноте данных) 12,6 мин и оценка по ошибке среднего выборочного 1,734; это незначительная ошибка. Тот факт, что распределение экспериментальных данных не отличается от теоретического закона нормального распределения данных, подтверждается оценками по критериям Колмогорова и омега-квадрат.
Следует проверить, отвечает ли распределение эмпирических данных другим законам. Вернемся в подокно «Распределение» и выполним проверку соответствия закону экспоненциального распределения. Для этого нужно кликнуть мышкой кнопку Экспоненциальное, после чего появится соответствующий график (рис. 2.5). Из графика видно, что теоретическая линия закона экспоненциального распределения пересекается только с одним из средних интервалов значений эмпирических данных, на «хвостах» гистограммы наблюдается резкое расхождение. Поэтому можно сделать вывод, что в данном случае соответствие маловероятно.
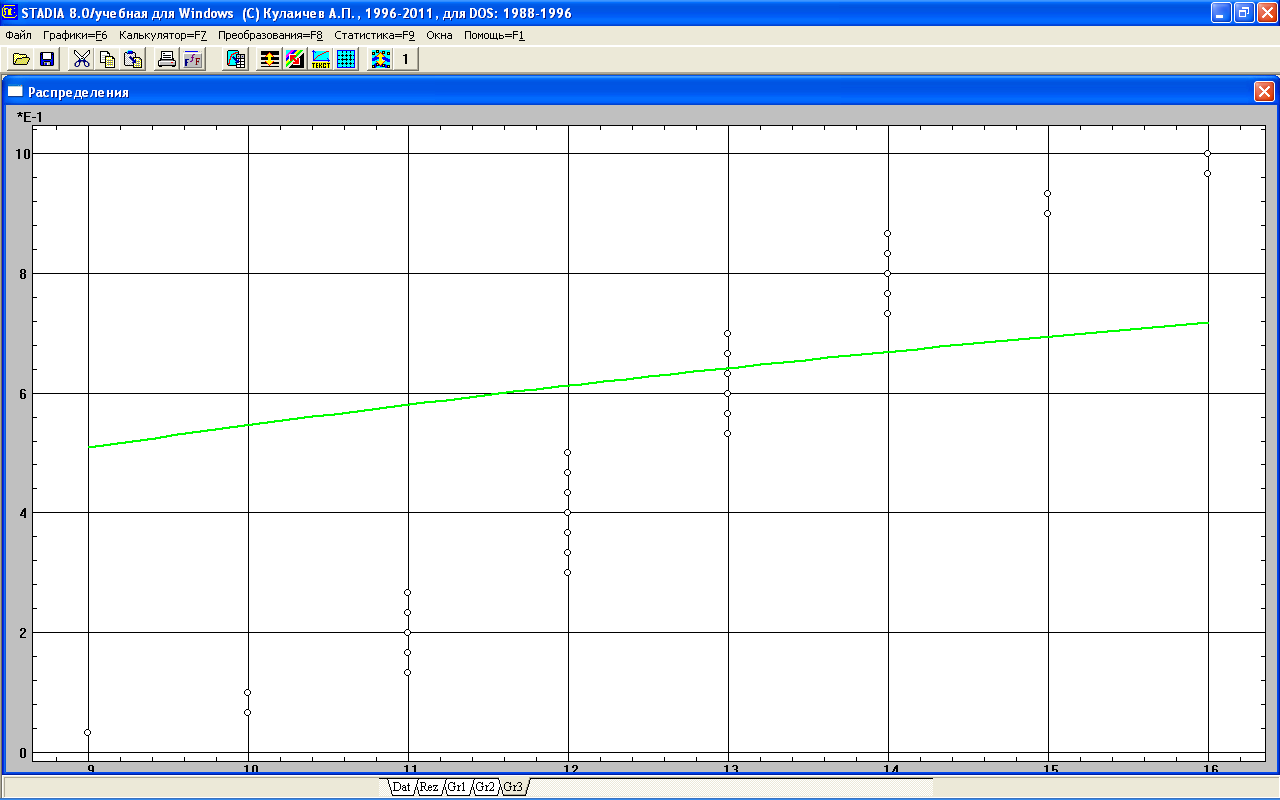
Рис. 2.5 График проверки данных на соответствие экспоненциальному закону
Чтобы подтвердить этот вывод, кликнем мышкой кнопку Оставить в подокне ПОСМОТРИТЕ ГРАФИК. В дальнейшем этот график при необходимости можно отобразить посредством кнопки рабочего листа Gr2. Одновременно с графиком в рабочем листе электронной таблицы Rez выводятся результаты расчетов статистических оценок по закону экспоненциального распределения. Кликнув мышкой кнопку Rez, получим отображение указанных результатов, которые подтверждают наше предположение, сделанное по виду графика. В соответствии с проверкой по первой гипотезе программа дала заключение «Распределение отличается от теоретического». Таким образом, распределение эмпирических экспериментальных данных не соответствует экспоненциальному закону распределения, что подтверждается также значениями оценок по критериям Колмогорова и омега-квадрат.
В соответствии с описанным способом проверки стоит выполнить проверку по остальным законам распределения. Практически это расширяет представление о моделируемом ИР и позволяет принять правильное решение о стратегии и тактике моделирования.
4. Формулирование выводов выполняется по окончании проверки по всем законам распределения. В выводах должна содержаться квинтэссенция решения данной задачи.
5. Составление и оформление отчета. По окончании работы необходимо составить и оформить отчет.
|
Варианты заданий |
|||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
10 |
8 |
15 |
7 |
16 |
16 |
9 |
15 |
9 |
15 |
|
11 |
16 |
9 |
9 |
16 |
10 |
14 |
17 |
13 |
13 |
|
10 |
9 |
9 |
13 |
7 |
12 |
15 |
8 |
10 |
13 |
|
7 |
13 |
11 |
9 |
13 |
14 |
11 |
9 |
12 |
12 |
|
12 |
9 |
12 |
13 |
10 |
10 |
11 |
9 |
12 |
12 |
|
9 |
10 |
15 |
11 |
7 |
16 |
7 |
8 |
8 |
11 |
|
16 |
7 |
9 |
17 |
16 |
9 |
16 |
14 |
9 |
11 |
|
16 |
9 |
16 |
7 |
9 |
10 |
8 |
8 |
10 |
8 |
|
14 |
16 |
17 |
16 |
9 |
9 |
9 |
17 |
8 |
10 |
|
16 |
10 |
7 |
13 |
7 |
8 |
11 |
9 |
9 |
8 |
|
14 |
16 |
14 |
13 |
10 |
14 |
17 |
16 |
15 |
16 |
|
14 |
13 |
8 |
9 |
17 |
15 |
8 |
12 |
8 |
8 |
|
16 |
9 |
9 |
17 |
14 |
15 |
10 |
11 |
16 |
13 |
|
13 |
17 |
14 |
13 |
12 |
13 |
14 |
9 |
11 |
17 |
|
14 |
15 |
10 |
17 |
8 |
9 |
16 |
8 |
15 |
9 |
|
11 |
8 |
17 |
16 |
11 |
14 |
15 |
14 |
9 |
16 |
|
10 |
9 |
14 |
10 |
9 |
11 |
17 |
15 |
15 |
11 |
|
14 |
12 |
13 |
16 |
9 |
13 |
12 |
12 |
13 |
12 |
|
11 |
17 |
9 |
8 |
8 |
14 |
9 |
14 |
15 |
17 |
|
11 |
13 |
12 |
15 |
12 |
9 |
15 |
16 |
9 |
10 |
|
8 |
15 |
8 |
10 |
15 |
13 |
12 |
8 |
12 |
13 |
|
10 |
15 |
17 |
11 |
14 |
16 |
17 |
10 |
11 |
9 |
|
14 |
17 |
14 |
8 |
13 |
9 |
12 |
13 |
8 |
15 |
|
13 |
14 |
14 |
15 |
10 |
8 |
9 |
11 |
11 |
14 |
|
12 |
10 |
10 |
11 |
10 |
15 |
15 |
11 |
14 |
16 |
|
10 |
9 |
10 |
9 |
15 |
8 |
12 |
7 |
17 |
11 |
|
12 |
12 |
11 |
15 |
16 |
16 |
13 |
8 |
15 |
11 |
|
13 |
15 |
9 |
7 |
14 |
8 |
9 |
12 |
13 |
10 |
|
13 |
9 |
8 |
10 |
12 |
15 |
7 |
8 |
14 |
11 |
|
15 |
19 |
13 |
9 |
9 |
16 |
16 |
11 |
15 |
13 |
Контрольные вопросы
-
Назовите различия между макетным и процедурным моделированием ИР.
-
Определите последовательность этапов вычислительного эксперимента в МИР.
-
Какие данные регистрируются в дефектной ведомости?
-
Какие инструкции разрабатываются для проведения вычислительного эксперимента?
-
Какие сведения может отражать дендрограмма кластеризации?
-
Чем отличается свободный (нулевой) коэффициент от коэффициента регрессии?
-
Чем различаются регрессионные модели по производительности технологического процесса обработки данных и себестоимость подготовки документов?
-
По каким статистическим параметрам проводится оценка адекватности модели регрессионного анализа?