

Лабораторная работа №4. «Распознавание свойств в управлении качеством аис»
Постановка задачи. Основной целью решения задачи является получение студентами практических навыков в выявлении свойств функционирования АИС в ходе моделирования и экспериментального исследования, а также закрепление теоретических знаний, полученных в лекционном курсе.
Методом исследования служит кластерный анализ, реализуемый средствами программы кластер-анализа ППСА STADIA.
В экспериментальных исследованиях АИС всегда возникает задача выявления свойств моделируемого ИР, так как любое научное исследование, в том числе процесс моделирования, невозможно выполнить без распознавания свойств изучаемого объекта. Сложность распознавания свойств обусловлена необходимостью выбора эффективного индикатора в конкретных условиях. Этот индикатор должен отображать наиболее полный состав свойств функционирования АИС и иметь возможность корректно распознавать состав существенных свойств АИС так, чтобы не потребовалось привлекать значительные ресурсы в распознавании. Очевидно то, что подобная противоречивость усложняет решение задачи.
В данной задаче наиболее эффективным индикатором свойств функционирования АИС является статистическая структура дефектов функционирования АИС. Сбор и регистрация дефектов могут выполняться по различным компонентам АИС, например, по этапам технологического процесса обработки данных АИС. Подобная выборка дефектов имеет совокупность свойств, т.е. по сути, неоднородна. Устранение неоднородности предполагает выявление состава свойств, которыми обладает исследуемый технологический процесс.
Одним из методов решения подобных задач выступает классификация данных выборки и выявление и/или уточнение существенных свойств, характеризующих технологию АИС (см. ЛР №1). Разделение данных на классы производится по такому основанию, как мера близости (удаленности) каждого события (дефекта) или значение (набор значений) события, отображаемого на временной, стоимостной и других шкалах.
В нашей задаче данные выборки представляют собой набор дефектов обработки документов. Каждый дефект описывается временем и стоимостью его обнаружения и исправления. Задача заключается в том, чтобы по двум переменным — времени и стоимости — провести разделение дефектов на классы и выявить на этой основе существенные свойства статистической структуры дефектов обработки документов. В решении данной задачи классификация (группирование) данных выборки выполняется по критерию «мера близости (расстояния)» с применением средств кластерного анализа ППСА STADIA. В решении задач кластеризации имеется несколько мер близости [3]; в нашей задаче наиболее приемлемо евклидово расстояние.
Задача решается с привлечением данных выборки дефектов по двум переменным, каждая из которых состоит из 20 чисел. Перечисленные ниже переменные xl и х2 отображают соответственно время (в минутах) и стоимость (в копейках) обнаружения и исправления дефектов:
xl:3, 11, 2460, 4, 13, 2952, 5, 14, 3444, 3, 12, 2450, 4, 13, 2952, 3, 12, 3440, 2, 15;
х2: 40, 143, 31900, 52, 169, 38100, 72, 185, 44700, 40, 156, 31800, 54, 165, 38100, 39, 156, 44500, 26, 190.
Основные этапы решения задачи. Решение задачи выполняется в несколько этапов.
1. Ввод данных статистической структуры дефектов. После загрузки ППСА STADIA посредством клавиатуры вводятся данные (значения каждой переменной) в столбцы xl и х2 электронной таблицы. Необходимо обеспечить точно такую же последовательность данных, в какой они даны в ЛР №3. Нарушение последовательности повлечет за собой некорректное решение задачи кластер-анализа.
2. Выполнение кластерного анализа статистической структуры дефектов. Классификация статистической структуры дефектов проводится в следующей последовательности: 1) кликнуть меню «Статистика»; 2) в открывшемся подокне «Статистические методы» в подполе «Многомерные методы» кликнуть кнопку «Q-кла-стерный», после чего появится подокно «Исходные данные»; 3) в меню «Исходные данные» кликнуть кнопку 1=переменные объекты; 4) в появившемся меню «Метрика вычисления расстояний» кликнуть кнопку «1=Евклид», после чего появится подокно «Объединяющая».
Если необходима гибкая стратегия кластеризации, в этом же меню следует предварительно устанавливать коэффициент Beta = —0,25. Поскольку в нашей задаче заранее неизвестно число кластеров, задача заключается именно в их определении. Если в субполе «Число кластеров» имеется цифра, ее нужно заменить на нуль. Затем в меню «Объединяющая» нужно кликнуть кнопку 1=ближайшего соседа, после чего на экране появится подполе «Confirm» с вопросом «Выдать таблицу расстояний?».
В подполе «Confirm» необходимо кликнуть кнопку Yes, после чего появится график, отражающий результаты кластеризации статистической структуры дефектов (рис. 4.1), в виде дендро-граммы объединения кластеров; в нашем случае — групп дефектов с однородными свойствами. По оси абсцисс указаны порядковые номера дефектов, которые они получили при вводе, т.е. номера строк электронной таблицы. По оси ординат указаны расстояния между дефектами в соответствии со шкалой расстояний, вычисленных по программе кластер-анализа.
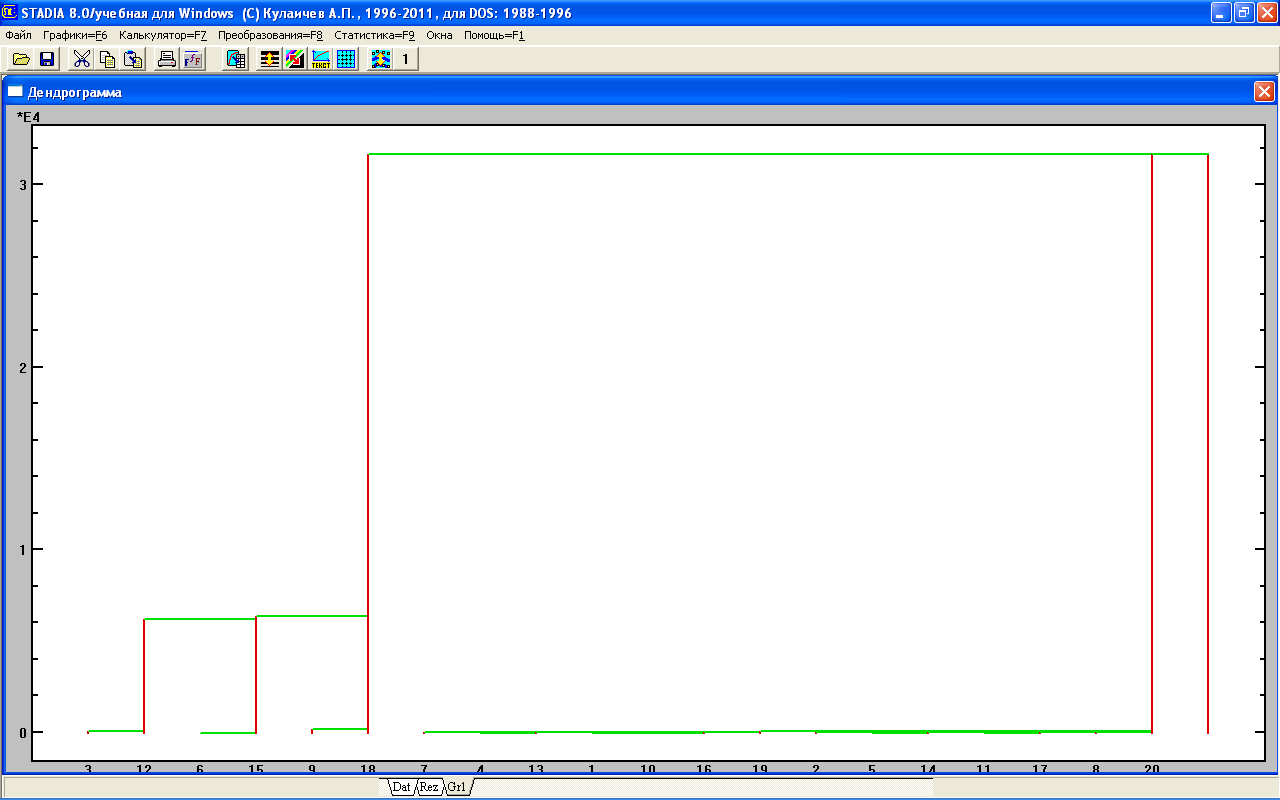
Рис. 4.1. График (дендрограмма) результатов кластеризации дефектом
В состав результатов кластер-анализа входят также «Таблица расстояний» (рис. 4.2) и (на этом же экране ниже «Таблицы расстояний» под рубрикой «Кластеры») список объектов; в нашем случае — номера дефектов. Здесь указываются значения среднего внутрикластерного расстояния, по которому можно сравнивать варианты кластеризации текущих данных, и найденные кластеры с порядковыми номерами входящих в каждый кластер объектов (дефектов).
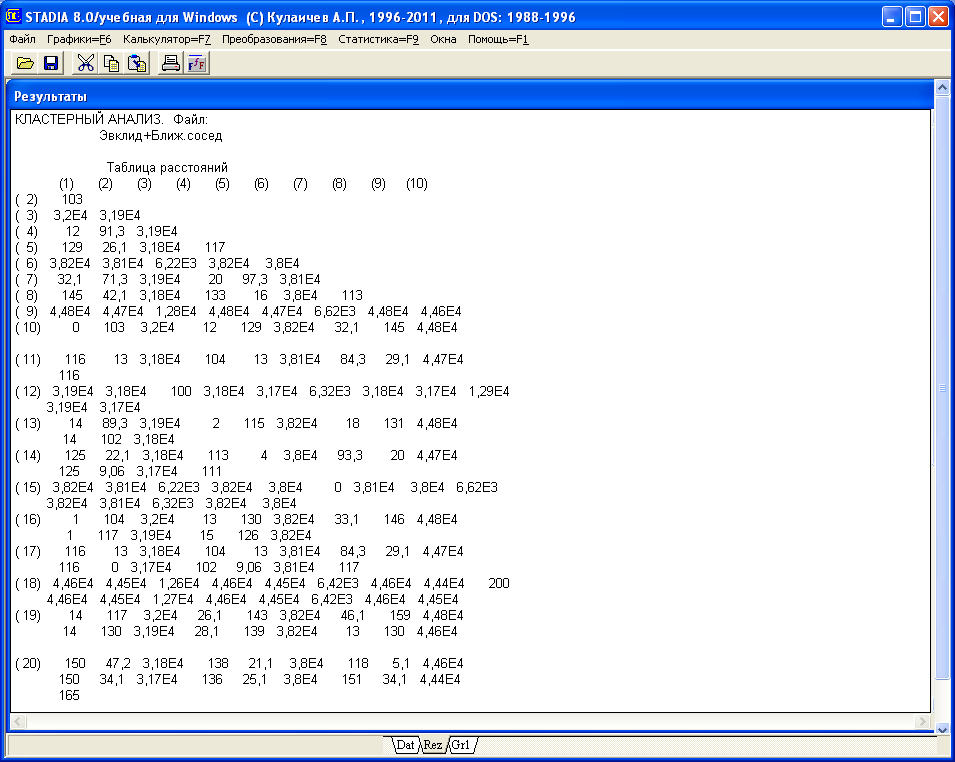
Рис. 4.2. «Таблица-расстояний» кластер-анализа дефектов
3. Анализ результатов кластеризации. Стратегия «ближайшего соседа» отчетливо выделяет три группы (класса) дефектов обработки документов. На минимальном расстоянии (примерно 15,03) произошло объединение дефектов 19, 7, 13,4, 10, 1, 16; на расстоянии примерно 30,02 произошло объединение дефектов 20, 14, 8, 5, 17, 11, 2; на расстоянии примерно 4030 произошло объединение дефектов 18, 15,6,9. В последнюю третью группу дефектов отнесены дефекты 3 и 12. Их объединение произошло при расстоянии 11,18.
В нашей задаче первый кластер составили дефекты с минимальными значениями времени и стоимости, сформированные прежде всего. При идентификации этих дефектов установлено, что они характеризуются наличием искажений символов (цифр, букв) в реквизитах документов, допущенных при выполнении технологических операций с документами. Во второй кластер дефектов вошли пропуски, или отсутствие элементов документов (реквизитов-оснований), являющихся регламентом структуры того или иного документа. В третьем кластере объединены дефекты, характеризующиеся опозданием, несвоевременным представлением документов от этапа к этапу технологического процесса обработки данных, т.е. нарушением регламентных сроков представления документов. Эти три кластера дефектов можно обозначить соответственно как дефекты по достоверности, полноте и своевременности. Таким образом, выделяются три наиболее существенных признака (свойства) функционирования данной АИС в технологии обработки документов. При использовании кластер-анализа в других АИС кластеры могут иметь и другие свойства.
Целесообразно провести более полный анализ влияния меры близости (удаленности) кластеров по шкале расстояний оси ординат графика дендрограммы. Например, дефекты достоверности отличаются наименьшим разбросом, на втором месте дефекты по полноте и далее дефекты по своевременности. Класс дефектов по полноте имеют меньшую удаленность от класса дефектов по достоверности, чем от класса дефектов по своевременности. Поэтому если дефекты по достоверности и полноте в организационно-техническом отношении могут быть сравнительно просто локализованы и устранены, то дефекты по своевременности исправить намного труднее в силу того, что для этого необходим более широкий спектр организационно-технических мероприятий.
4. Формулирование выводов по результатам решения задачи. В выводах необходимо сформулировать место и значение анализа статистической структуры данных выборки на неоднородность; показать, какие пути и инструментальные средства могут быть использованы для решения этой задачи; отметить, какие критерии классификации данных выборки могут быть применимы, и перечислить основные этапы кластеризации.
5. Составление и оформление отчета о решении задачи производятся после выполнения работ в полном объеме.
Варианты
Контрольные вопросы
-
Назовите отличительные признаки дескриптивного и формализованного моделирования ИР
-
Приведите классификацию математических моделей МИР
-
Назовите системные требования к математическим моделям МИР
-
Какие компоненты составляют кибернетическую модель ИР?
Лабораторная работа №5.