

30. Устройства накапливающего типа: счетчики
Устройство последовательностного типа – устройство, выходные сигналы которого зависят от входных сигналов на текущем такте и от выходных сигналов на предыдущем (счетчики, регистры, генераторы кодов)
Общая структурная схема устройства последовательностного типа:

Счетчик – конечный автомат, фиксирующий под действием входных импульсов число этих импульсов
Классификация счетчиков по принадлежности к классам автоматов: синхронные/асинхронные
Синхронные счетчики – счетчики, переключение которых происходит в строго заданные моменты времени под действием синхроимпульсов
Асинхронные счетчики – счетчики, переключение которых происходит в произвольные моменты времени при подаче входных сигналов
Классификация счетчиков по организации связи между разрядными схемами: с последовательным или параллельным переносом
Режимы работы счетчика:
- регистрация числа поступивших сигналов; результат на выходе – содержимое счетчика
- деление частоты; результат на выходе – импульсы переполнения счетчика
Работа асинхронного суммирующего счетчика с модулем счета 8
Для синтеза необходимо m = ]log28[ = 3 триггера, соответствующих трем разрядам выходного числа (Q3Q2Q1)
Входной сигнал может быть равен только 1, так как 0 не изменяет состояния счетчика
|
Xt |
Q3t |
Q2t |
Q1t |
Q3t+1 |
Q2t+1 |
Q1t+1 |
|
1 |
0 |
0 |
0 |
0 |
0 |
1 |
|
1 |
0 |
0 |
1 |
0 |
1 |
0 |
|
1 |
0 |
1 |
0 |
0 |
1 |
1 |
|
1 |
0 |
1 |
1 |
1 |
0 |
0 |
|
1 |
1 |
0 |
0 |
1 |
0 |
1 |
|
1 |
1 |
0 |
1 |
1 |
1 |
0 |
|
1 |
1 |
1 |
0 |
1 |
1 |
1 |
|
1 |
1 |
1 |
1 |
0 |
0 |
0 |
Триггер младшего разряда переключается от каждого входного сигнала. В столбце следующего разряда нули и единицы чередуются через такт, то есть частота переключений в 2 раза меньше. Для старшего разряда частота переключения в 4 раза меньше. Следовательно, счетчик можно построить как цепочку последовательно включенных счетных триггеров, обладающих свойством деления частоты последовательности сигналов, поступивших на его вход, на 2
Выберем JK-триггеры, работающие в счетном режиме:

Для реализации вычитающего счетчика на входы C последующих триггеров необходимо подавать сигналы с инверсных выходов предыдущих триггеров
Подсчитываемые единицы поступают на вход C первого триггера. На выходных шинах формируется двоичный код Y3Y2Y1 количества единиц. Так как на входы J и K всех триггеров постоянно поданы единицы, каждый триггер переключается в противоположное состояние в момент спада импульса, поданного на его вход C. Это переключение происходит с задержкой – такие счетчики называются счетчиками с последовательным переносом (асинхронные). Для повышения быстродействия счетчики выполняются с параллельным, или сквозным, переносом (синхронные). Выходы предшествующих разрядов подаются на входы триггера последующего (старшего) разряда, поэтому длительность переходного процесса – время установки кода – определяется длительностью переходного процесса одного разряда и не зависит от количества триггеров. Синхронным счетчикам отдается предпочтение
31 Структура простейшего компьютера (компьютер фон-Неймана).
Архитектура вычислительной машины (Архитектура ЭВМ, англ. Computer architecture) — концептуальная структура вычислительной машины[1], определяющая проведение обработки информации и включающая методы преобразования информации в данные и принципы взаимодействия технических средств и программного обеспечения.[2]
В настоящее время наибольшее распространение в ЭВМ получили 2 типа архитектуры: принстонская (неймановская) и гарвардская. Обе они выделяют 2 основных узла ЭВМ: центральный процессор ипамять компьютера. Различие заключается в структуре памяти: в принстонской архитектуре программы и данные хранятся в одном массиве памяти и передаются в процессор по одному каналу, тогда как гарвардская архитектура предусматривает отдельные хранилища и потоки передачи для команд и данных.
В более подробное описание, определяющее конкретную архитектуру, также входят: структурная схема ЭВМ, средства и способы доступа к элементам этой структурной схемы, организация и разрядность интерфейсов ЭВМ, набор и доступность регистров, организация памяти и способы её адресации, набор и формат машинных команд процессора, способы представления и форматы данных, правила обработки прерываний.
По перечисленным признакам и их сочетаниям среди архитектур выделяют:
-
По разрядности интерфейсов и машинных слов: 8-, 16-, 32-, 64-, 128- разрядные (ряд ЭВМ имеет и иные разрядности);
-
По особенностям набора регистров, формата команд и данных: CISC, RISC, VLIW;
-
По количеству центральных процессоров: однопроцессорные, многопроцессорные, суперскалярные;
-
многопроцессорные по принципу взаимодействия с памятью: симметричные многопроцессорные (SMP), масcивно-параллельные (MPP), распределенные.
-
Архитектурные принципы Фон Неймана.
-
Программное управление. Выполнение вычислений, описанных программой, сводится к последовательному выполнению её команд.
-
Программа – это определенная последовательность управляющих слов (команд), записанных в соответствие с алгоритмом. Команда определяет тип операции и слова, т.е. информации, обрабатываемой с ее помощью.
-
Двоичное представление информации. Вся информация, необходимая для работы ЭВМ представляется в двоичном виде и разделяется на единицы, называемые словами.
-
Разнотипные по смыслу слова (команда, данные) различаются лишь способом использования.
-
-
Принцип однородности памяти. Слова размещаются в ячейках памяти и идентифицируются номерами ячеек, т.е. адресами. В одной памяти хранятся и команды и данные.
32 Принцип Гарвардской и Пристанской архитектуры
Гарвардская архитектура — архитектура ЭВМ, отличительным признаком которой является раздельное хранение и обработка команд и данных. Архитектура была разработана Говардом Эйкеном в конце 1930-х годов в Гарвардском университете.
Принстонская архитектура МК (архитектура фон Неймана):

Принстонский университет разработал компьютер с общей памятью для хранения программ и данных. Блок интерфейса с памятью выполняет арбитраж запросов к памяти, обеспечивая выборку команд, чтение и запись данных, размещаемых в памяти или внутренних регистрах. Может показаться, что блок интерфейса является наиболее узким местом между процессором и памятью, так как одновременно с данными требуется выбирать из памяти очередную команду. Однако эта проблема решается предварительной выборкой. Основное преимущество принстонской архитектуры – то, что она упрощает устройство МП, так как реализует обращение только к одной общей памяти
Гарвардская архитектура МК:
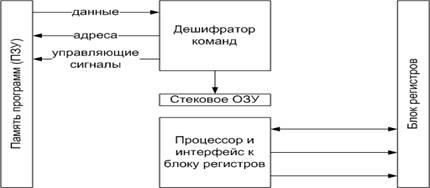
Данные двунаправленные, справа то же самое
Гарвардский университет представил разработку компьютера, в котором для хранения программ, данных и стека использовались отдельные банки памяти. В Гарвардской архитектуре, обеспечивающей более высокую степень параллелизма операций, выполнение текущей операции может совмещаться с выборкой следующей команды. Команда также выполняется за два цикла, но выборка очередной команды производится одновременно с выполнением предыдущей. Таким образом, команда выполняется всего за один цикл (во время чтения следующей команды).
33. Архитектура ЕС ЭВМ т IBM- систем
При организации ЭВМ на основе общей шины (ОШ) взаимодействие между ее устройствами осуществляется через общую шину, к которой подключены все устройства, входящие в состав ЭВМ.

Рисунок 1.4.2- Структура ЭВМ на основе ОШ
Взаимодействие между всеми устройствами ЭВМ осуществляется в режиме разделения времени общей шины (т.е. поочередно). Общая шина не обеспечивает высокой пропускной способности, что ограничивает число подключаемых устройств и общую производительность ЭВМ. Однако простота реализации обеспечили широкое использование такой структуры в ранних мини-ЭВМ и персональных компьютерах, а также в контроллерах - небольших специализированных микропроцессорных системах, предназначенных для управления производственными и бытовыми устройствами и приборами.
|
|
|
|
|
|
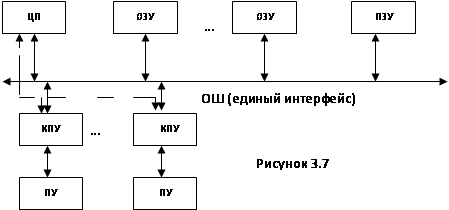
34.Архитектура ЭВМ с общей шиной
Наибольшее распространение имеют три основные (типовые) конфигурации (структуры) ВК (ЭВМ). Первая, простейшая, строится на основе единого интерфейса (ОШ) (рисунок 3.7).
ОШ здесь выполнена как двунаправленная асинхронная магистраль. Через нее обмениваются информацией все устройства. Обмен осуществляется по принципу «ведущий – ведомый».
Основная память в этой структуре всегда пассивна. Активным может быть ЦП или КПУ. Для подключения ПУ к ЭВМ (к ОШ) используется контроллер ПУ (КПУ), выполняющий роль устройства управления при обмене информацией с другими устройствами. Для каждого типа ПУ используется свой тип контроллера: контроллер клавиатуры, принтера, монитора и т. п. Ведущее устройство выставляет запрос на обмен, т. е. фактически запрос на захват ОШ. Получив ОШ в свое распоряжение, ведущее устройство выставляет адрес ведомого устройства и управляет обменом информации с ним по ОШ, посылая необходимую адресную и управляющую информацию. Например, при обмене с ОП – адрес ячейки ОП и сигнал чтения/записи. Такую структуру имеют обычно мини – и микро-ЭВМ: РДР/11, СМ ЭВМ. Достоинства: простота структуры и обмена информации по ОШ.
Недостатки: при большом количестве устройств ПУ, в частности, ОШ становится «узким» местом в системе ввиду ее ограниченной пропускной способности. Активные устройства при большой загрузке ОШ достаточно часто (все с большей вероятностью) обнаруживают ОШ занятой обменом с другими устройствами и вынуждены ждать ее освобождения. Ожидание в очереди на обмен ограничивает производительность ВК.
Как быть? Как уменьшить простои устройств и, следовательно, увеличить производительность? Первый способ – увеличить пропускную способность ОШ, если можно. Если нельзя, то применить второй способ – использовать несколько интерфейсов: два, три и т. д.
Второй недостаток: при большом количестве ПУ становятся ощутимыми затраты оборудования на их подключение к ОШ, т. е. суммарные затраты оборудования на реализацию КПУ.
В силу указанных недостатков единый интерфейс находит применение в тех случаях, когда количество ПУ невелико (до 10-15 штук), т. е. в микро-ЭВМ. В тех случаях, когда количество ПУ велико (более 10-15), использование ОШ неэффективно.
35.Принцип работы кэш-памяти, типы кэш-памяти
Кэш-память -- это высокоскоростная память произвольного доступа, используемая процессором компьютера для временного хранения информации. Она увеличивает производительность, поскольку хранит наиболее часто используемые данные и команды «ближе» к процессору, откуда их можно быстрее получить
Кэш-память напрямую влияет на скорость вычислений и помогает процессору работать с более равномерной загрузкой. Представьте себе массив информации, используемой в вашем офисе. Небольшие объемы информации, необходимой в первую очередь, скажем список телефонов подразделений, висят на стене над вашим столом. Точно так же вы храните под рукой информацию по текущим проектам. Реже используемые справочники, к примеру, городская телефонная книга, лежат на полке, рядом с рабочим столом. Литература, к которой вы обращаетесь совсем редко, занимает полки книжного шкафа.
Компьютеры хранят данные в аналогичной иерархии. Когда приложение начинает работать, данные и команды переносятся с медленного жесткого диска в оперативную память произвольного доступа (Dynamic Random Access Memory -- DRAM), откуда процессор может быстро их получить. Оперативная память выполняет роль кэша для жесткого диска.
Хотя оперативная память намного быстрее диска, тем не менее и она не успевает за потребностями процессора. Поэтому данные, которые требуются часто, переносятся на следующий уровень быстрой памяти, называемой кэш-памятью второго уровня. Она может располагаться на отдельной высокоскоростной микросхеме статической памяти (SRAM), установленной в непосредственной близости от процессора (в новых процессорах кэш-память второго уровня интегрирована непосредственно в микросхему процессора.
На более высоком уровне информация, используемая чаще всего (скажем, команды в многократно выполняемом цикле), хранится в специальной секции процессора, называемой кэш-памятью первого уровня. Это самая быстрая память.
Для процессоров старшего класса на получение информации из кэш-памяти первого уровня может уйти от одного до трех тактов, а процессор в это время ждет и ничего полезного не делает. Скорость доступа к данным из кэш-памяти второго уровня, размещаемой на процессорной плате, составляет от 6 до 12 циклов, а в случае с внешней кэш-памятью второго уровня -- десятки или даже сотни циклов.
Кэш-память третьего уровня корпорации IBM станет общесистемным кэшем, куда смогут обращаться от 4 до 16 процессоров сервера. С кэш-памятью третьего уровня Intel сможет работать только тот процессор, к которому она подключена, но представители IBM подчеркнули, что их кэш третьего уровня способен увеличить пропускную способность всей системы. Бредикич отметил, что новая кэш-память производства IBM также поможет реализовать компьютерные системы высокой готовности, необходимые для электронной коммерции, поскольку с ее помощью можно будет менять модули основной памяти и выполнять модернизацию, не прерывая работу системы.
Внутренний кэш
Внутренне кэширование обращений к памяти применяется в процессорах, начиная с 486-го. С кэшированием связаны новые функции процессоров, биты регистров и внешние сигналы.
Процессоры 486 и Pentium имеют внутренний кэш первого уровня, в Pentium Pro и Pentium II имеется и вторичный кэш. Процессоры могут иметь как единый кэш инструкций и данных, так и общий. Выделенный кэш инструкций обычно используется только для чтения. Для внутреннего кэша обычно используется наборно-ассоциативная архитектура.
Работу внутренней кэш-памяти характеризуют следующие процессы: обслуживание запросов процессора на обращение к памяти, выделение и замещение строк для кэширования областей физической памяти, обеспечение согласованности данных внутреннего кэша и оперативной памяти, управление кэшированием.
Любой внутренний запрос процессора на обращение к памяти направляется на внутренний кэш. Теги четырех строк набора, который обслуживает данный адрес, сравниваются со старшими битами запрошенного физического адреса. Если адресуемая область представлена в строке кэш-памяти (случая попадания -cache hit), запрос на чтение обслуживается только кэш-памятью, не выходя на внешнюю шину. Запрос на запись модифицирует данную строку, и в зависимости от политики записи либо сразу выходит на внешнюю шину (при сквозной записи), либо несколько позже (при использовании алгоритма обратной записи).
Смешанная и разделенная кэш-память.
Внутренняя кэш-память использовалась ранее как для инструкций(команд), так и для данных. Такая память называлась смешанной, а ее архитектура - Принстонской, в которой в единой кэш-памяти, в соответствии с классическими принципами фон Неймана, хранились и команды и данные.
Сравнительно недавно стало обычным разделять кэш-память на две - отдельно для инструкций и отдельно для данных.
Преимуществом смешанной кэш-памяти является то, что при заданном объеме, ей свойственна более высокая вероятность попаданий, по сравнению с разделенной, поскольку в ней автоматически устанавливается оптимальный баланс между инструкциями и данными. Если в выполняемом фрагменте программы обращения к памяти связаны, в основном, с выборкой инструкций, а доля обращений к данным относительно мала, кэш-память имеет тенденцию заполнения инструкциями и наоборот.
С другой стороны, при раздельной кэш-памяти, выборка инструкций и данных может производиться одновременно, при этом исключаются возможные конфликты. Последнее особенно существенно в системах, использующих конвейеризацию команд, где процессор извлекает команды с опережением и заполняет ими буфер или конвейер.
37. Методы повышения производительности современных ЭВМ, понятие CISC и RISC архитектуры
CISC , RISC архитектуры ЭВМ. Архитектура – аппаратные средства и программное обеспечение данного устройства. Термин “архитектура системы” часто употребляется как в узком, так и в широком смысле этого слова. В узком смысле под архитектурой понимается архитектура системы команд. Архитектура набора команд служит границей между аппаратурой и программным обеспечением и представляет ту часть системы, которая видна программисту. Система команд – список всех командных слов языка Ассемблер для данного типа процессора. Следует отметить, что это наиболее частое употребление этого термина. В широком смысле архитектура охватывает понятие организации системы, включающее такие высокоуровневые аспекты разработки компьютера, как систему памяти, структуру системной шины, организацию ввода/вывода и т.п. Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники, являются архитектуры CISC и RISC. RISC (Reduced (Restricted) Instruction Set Computer) – уменьшенный набор команд, которыми пользуется микропроцессор компьютера, содержащий только наиболее простые команды. Эти процессоры обычно имеют набор однородных регистров универсального назначения, причем их число может быть большим. Система команд отличается относительной простотой, коды инструкций имеют четкую структуру, как правило, с фиксированной длиной. В результате аппаратная реализация такой архитектуры позволяет с небольшими затратами декодировать и выполнять эти инструкции за минимальное число тактов синхронизации. Определенные преимущества дает и унификация регистров. CISC (Complete Instruction Set Computer) – полный набор команд микропроцессора. Состав и назначение их регистров существенно неоднородны, широкий набор команд усложняет декодирование инструкций, на что расходуются аппаратные ресурсы. Возрастает число тактов, необходимое для выполнения инструкций. К процессорам с полным набором инструкций относится семейство х86. Лидером в разработке CISC-процессоров считается компания Intel со своей серией x86 и Pentium. Эта архитектура является практическим стандартом для рынка микрокомпьютеров. Для CISC-процессоров характерно: сравнительно небольшое число регистров общего назначения; большое количество машинных команд, некоторые из которых нагружены семантически аналогично операторам высокоуровневых языков программирования и выполняются за много тактов; большое количество методов адресации; большое количество форматов команд различной разрядности; преобладание двухадресного формата команд; наличие команд обработки типа регистр-память. Основой архитектуры современных рабочих станций и серверов является RISC архитектура. Понятие RISC сформировалось на базе трех исследовательских проектов: процессора 801 компании IBM, процессора RISC университета Беркли и процессора MIPS Стенфордского университета. Главными идеями этих машин было отделение медленной памяти от высокоскоростных регистров и использование регистровых окон. Эти три процессора имели много общего. Все они придерживались архитектуры, отделяющей команды обработки от команд работы с памятью, и делали упор на эффективную конвейерную обработку. Система команд разрабатывалась таким образом, чтобы выполнение любой команды занимало небольшое количество машинных тактов (предпочтительно один машинный такт). Сама логика выполнения команд с целью повышения производительности ориентировалась на аппаратную, а не на микропрограммную реализацию. Чтобы упростить логику декодирования команд, использовались команды фиксированной длины и фиксированного формата. Среди других особенностей RISC архитектур следует отметить наличие достаточно большого регистрового файла (в типовых RISC-процессорах реализуются 32 или большее число регистров по сравнению с 8–16 регистрами в CISC архитектурах), что позволяет большему объему данных храниться в регистрах на процессорном кристалле более длительное время и упрощает работу компилятора по распределению регистров под переменные. Для обработки данных процессора с RISC архитектурой, как правило, используются трехадресные команды, что помимо упрощения дешифрации дает возможность сохранять большее число переменных в регистрах без их последующей перезагрузки.
38.Суперскалярные ЭВМ
Суперскалярные архитектуры
Один конвейер - хорошо, а два - еще лучше. Одна из возможных схем процессора с двойным конвейером показана на рис. 2.4. В основе разработки лежит конвейер, изображенный на рис. 2.3. Здесь общий отдел вызова команд берет из памяти сразу по две команды и помещает каждую из них в один из конвейеров. Каждый конвейер содержит АЛУ для параллельных операций. Чтобы выполняться параллельно, две команды не должны конфликтовать при использовании ресурсов (например, регистров), и ни одна из них не должна зависеть от результата выполнения другой. Как и в случае с одним конвейером, либо компилятор должен следить, чтобы не возникало неприятных ситуаций (например, когда аппаратное обеспечение выдает некорректные результаты, если команды несовместимы), либо же конфликты выявляются и устраняются прямо во время выполнения команд благодаря использованию дополнительного аппаратного обеспечения.
Сначала конвейеры (как двойные, так и одинарные) использовались только в компьютерах RISC. У 386-го и его предшественников их не было. Конвейеры в процессорах компании Intel появились только начиная с 486-й модели.486-й процессор содержал один конвейер, a Pentium - два конвейера из пяти стадий. Похожая схема изображена на рис. 2.4, но разделение функций между второй и третьей стадиями (они назывались декодирование 1) и декодирование 2) было немного другим. Главный конвейер (u-конвейер) мог выполнять произвольные команды. Второй конвейер (v-конвейер) мог выполнять только простые команды с целыми числами, а также одну простую команду с плавающей точкой (FXCH).
Имеются сложные правила определения, является ли пара команд совместимой для того, чтобы выполняться параллельно. Если команды, входящие в пару, были сложными или несовместимыми, выполнялась только одна из них (в и-конвейере). Оставшаяся вторая команда составляла затем пару со следующей командой. Команды всегда выполнялись по порядку. Таким образом, Pentium содержал особые компиляторы, которые объединяли совместимые команды в пары и могли порождать программы, выполняющиеся быстрее, чем в предыдущих версиях. Измерения показали, что программы, производящие операции с целыми числами, на компьютере Pentium выполняются почти в два раза быстрее, чем на 486-м, хотя у него такая же тактовая частота. Вне всяких сомнений, преимущество в скорости появилось благодаря второму конвейеру.
Переход к четырем конвейерам возможен, но это потребовало бы создания громоздкого аппаратного обеспечения. Основная идея - один конвейер с большим количеством функциональных блоков, как показано па рис. 2.5. Pentium II, к примеру, имеет сходную структуру. В 1987 году для обозначения этого подхода был введен термин суперскалярная архитектура. Однако подобная идея нашла воплощение еще более 30 лет назад в компьютере CDC 6600. CDC 6600 вызывал команду из памяти каждые 100 не и помещал ее в один из 10 функциональных блоков для параллельного выполнения. Пока команды выполнялись, цен- тральный процессор вызывал следующую команду.
Отметим, что стадия 3 выпускает команды значительно быстрее, чем стадия 4 способна их выполнять. Если бы стадия 3 выпускала команду каждые 10 не, а все функциональные блоки выполняли бы свою работу также за 10 не, то на четвертой стадии всегда функционировал бы только один блок, что сделало бы саму идею конвейера бессмысленной. В действительности большинству функциональных блоков четвертой стадии для выполнения команды требуется значительно больше времени, чем занимает один цикл (это блоки доступа к памяти и блок выполнения операций с плавающей точкой). Как видно из рис. 2 5, на четвертой стадии может быть несколько АЛУ.
Параллелизм на уровне процессоров Спрос на компьютеры, работающие все с более и более высокой скоростью, не прекращается. Астрономы хотят выяснить, что произошло в первую микросекунду после большого взрыва, экономисты хотят смоделировать всю мировую экономику, подростки хотят играть в 3D интерактивные игры со своими виртуальными друзьями через Интернет. Скорость работы процессоров повышается, но у них постоянно возникают проблемы с быстротой передачи информации, поскольку скорость распространения электромагнитных волн в медных проводах и света в оптико-волоконных кабелях по-прежнему остается 20 см/нс, независимо от того, насколько умны инженеры компании Intel. Кроме того, чем быстрее работает процессор, тем сильнее он нагревается, и нужно предохранять его от перегрева.
Параллелизм на уровне команд помогает в какой-то степени, но конвейеры и суперскалярная архитектура обычно увеличивают скорость работы всего лишь в 5-10 раз. Чтобы улучшить производительность в 50, 100 и более раз, нужно разрабатывать компьютеры с несколькими процессорами. Ниже мы ознакомимся с устройством таких компьютеров.
39.Процессоры с очень длинным командным словом
Very Long Instruction Word - архитектура с очень длинным командным словом.
Выдача на одновременное выполнение фиксированного количества команд, сформатированных как:
одна «длинная» команда;
пакет команд фиксированного формата;
основополагающие принципы VLIW:
Планирование вычислений полностью реализуется программным обеспечением.
Функции «интеллектуального» компилятора: поиск в программе независимых инструкций, группирование найденных инструкций в «очень длинные» командные слова («метаинструкции» длиной 256-1024 бит).
Формат инструкции:
длина - 256 бит;
8 операционных полей, каждое из которых:
- выполняет традиционную трехоперандную RISC-подобную инструкцию;
- непосредственно управляет специфическим функциональным блоком при простом декодировании;
- имеет небольшую длину.
Т.е. за один такт возможно одновременное выполнение 8 команд.
задачи VLIW-компилятора:
Поиск в программе независимых инструкций, группирование найденных инструкций в «очень длинные» командные слова («метаинструкции» длиной 256-1024 бит).
формировка командного слова VLIW:
VLIW компилятор анализирует исходный код и находя в нем независимые операции образует из них длинную командную инструкцию, состоящую из нескольких команд.
Формат инструкции:
длина - 256 бит;
8 операционных полей, каждое из которых:
- выполняет традиционную трехоперандную RISC-подобную инструкцию;
- непосредственно управляет специфическим функциональным блоком при простом декодировании;
- имеет небольшую длину.
18. Каким образом можно повышать производительность VLIW-процессора?
Это возможно сделать двумя способами: увеличить тактовую частоту ЦП или увеличить количество одновременно выполняемых операций, тем самый увеличив длину слова инструкций и добавив в процессор дополнительные вычислительные модули.
19. Что ограничивает повышение производительности VLIW?
Ограничивает повышение производительности зависимость компилятора от микроархитектуры.
Решением является 2 стадии компиляции:
- генерация промежуточного кода
- трансляция промежуточного кода в машинно-зависимый на машине пользователя.
Также проблемой является реакция программы на непредусмотренные в процессе компиляции динамические ситуации (например неизвестно время ожидания ввода-вывода).
20. Какие преимущества имеет архитектура VLIW с точки зрения технологии?
Архитектура VLIW ориентирована на вычисления, где особенно необходимо большое быстродействие процессора, но для объектно-ориентированных и управляемых по событиям программ она менее подходит.
21. Какие существуют трудности реализации VLIW?
При реализации архитектуры VLIW возникают и другие серьезные проблемы: VLIW-компилятор должен в деталях знать внутренние особенности архитектуры процессора, опускаясь до внутреннего устройства самих функциональных модулей. Как следствие, при выпуске новой версии VLIW-процессора с большим количеством обрабатывающих модулей (или даже с тем же количеством, но другим быстродействием) все старое программное обеспечение, скорее всего, потребует полной перекомпиляции. Надо ли было при переходе, скажем, на процессор 486 избавляться от имеющегося ПО для процессора 386? Конечно, нет, а вот при переходе от одного VLIW-процессора к другому придется, и это разработчик должен учесть при планировании своих затрат и потребуются дополнительные средства на перекомпиляцию. Сторонники VLIW-архитектуры в оправдание предлагают разделить процесс компиляции на две стадии. Все программное обеспечение должно готовиться в аппаратно-независимом формате с использованием промежуточного кода, который окончательно транслируется в машинно-зависимый код только после установки на машине пользователя. Пример такого подхода демонстрирует фонд OSF со своим стандартом ANDF (Architecture-Neutral Distribution Format). Но кроссплатформенное программное обеспечение пока еще только желаемое, а в действительности разработчики ПО для ПК зачастую весьма инертны по отношению к принятию радикально новых технологий. Другая трудность и это по своей сути статическая природа оптимизации, которую обеспечивает VLIW-компилятор. Как поведет себя программа, когда столкнется во время компиляции с непредусмотренными динамическими ситуациями, такими как, например, ожидание ввода-вывода? Архитектура VLIW возникла в ответ на требования со стороны научно-технических организаций, где при вычислениях особенно необходимо большое быстродействие процессора, но для объектно-ориентированных и управляемых по событиям программ она менее подходит, а ведь именно такие программы составляют сейчас большинство в мире ПК. Но и это еще не все: а как можно проверить, что компилятор выполняет такие сложные преобразования надежно и правильно? Пока никак. Вот почему VLIW-компиляторы называют вещью в себе. Однако решение сложной задачи обеспечения взаимодействия аппаратного и программного обеспечения в архитектуре VLIW требует серьезных предварительных исследований.
22. Какова сфера применения VLIW-компьютеров?
Что означает понятие «EPIC»?
EPIC (Explicitly Parallel Instruction Computing) - микропроцессорная архитектура с явным параллелизмом команд. Термин введён в 1997 году альянсом HP и Intel для разрабатываемой архитектуры Intel Itanium. EPIC позволяет микропроцессору выполнять инструкции параллельно, опираясь на работу компилятора, а не выявляя возможность параллельной работы инструкций при помощи специальных схем. В теории, это могло упростить масштабирование вычислительной мощности процессора без увеличения тактовой частоты.
40.Увеличение производительности путем выполнения команд «по предположению» и т.п. методов
Конвейерная организация
Простейшая организация конвейера и оценка его производительности
Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием "совмещение операций", при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода. При параллелизме совмещение операций достигается путем воспроизведения в нескольких копиях аппаратной структуры. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Для иллюстрации основных принципов построения процессоров мы будем использовать простейшую архитектуру, содержащую 32 целочисленных регистра общего назначения (R0, ... ,R31), 32 регистра плавающей точки (F0,...,F31) и счетчик команд PC. Будем считать, что набор команд нашего процессора включает типичные арифметические и логические операции, операции с плавающей точкой, операции пересылки данных, операции управления потоком команд и системные операции. В арифметических командах используется трехадресный формат, типичный для RISC-процессоров, а для обращения к памяти используются операции загрузки и записи содержимого регистров в память.
Выполнение типичной команды можно разделить на следующие этапы:
-
выборка команды - IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
-
декодирование команды / выборка операндов из регистров - ID;
-
выполнение операции / вычисление эффективного адреса памяти - EX;
-
обращение к памяти - MEM;
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности, она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
Тот факт, что время выполнения каждой команды в конвейере не уменьшается, накладывает некоторые ограничения на практическую длину конвейера. Кроме ограничений, связанных с задержкой конвейера, имеются также ограничения, возникающие в результате несбалансированности задержки на каждой его ступени и из-за накладных расходов на конвейеризацию. Частота синхронизации не может быть выше, а, следовательно, такт синхронизации не может быть меньше, чем время, необходимое для работы наиболее медленной ступени конвейера. Накладные расходы на организацию конвейера возникают из-за задержки сигналов в конвейерных регистрах (защелках) и из-за перекосов сигналов синхронизации. Конвейерные регистры к длительности такта добавляют время установки и задержку распространения сигналов. В предельном случае длительность такта можно уменьшить до суммы накладных расходов и перекоса сигналов синхронизации, однако при этом в такте не останется времени для выполнения полезной работы по преобразованию информации.
41. Обобщенная структура современного многоядерного процессора
Для большинства не секрет, что в компьютере главная составляющая аппаратной части – центральное процессорное устройство (ЦПУ). Сегодня, на полках магазинов очень много вариантов процессоров, различаемых по производительности, частоте тактовых импульсов, объему кэш-памяти, архитектуре и торговой марке. Основными его разработчиками считаются компании: Intel, AMD, IBM. Именно они делят рынок инновационных разработок в области совершенствования ПК.
Тактовая частота - количество тактов, необходимое для выполнения определенного перечня операций в секунду времени. Она характеризует производительность процессора. Чем она выше, тем лучше будет работать ПК.
По архитектуре (схеме обработки данных) различают процессоры с последовательной структурой фон Неймана, Гарвардским вариантом с хранением программного кода и данных в разных уровнях кэш-памяти и параллельной вариацией.
По поводу дополнительной «быстро» памяти для хранения блоков «свежей» информации, то нужно уточнить об ее трехуровневости. Каждый из них больше по объему предыдущего и с пропорционально увеличивающимся временем доступа.
Современные ЦПУ характеризуются еще и таким параметром, как количество ядер. Для начала, нужно понимать, что ядро – это основной функциональный блок, выполняющий определенный поток системы команд (машинного кода). Грубо говоря, оно интерпретирует список инструкций, из которых состоит программа для получения и выведения результата на экран. Ядер для работы одной копии операционной системы на кристалле процессора может быть несколько, отсюда и название – многоядерные.
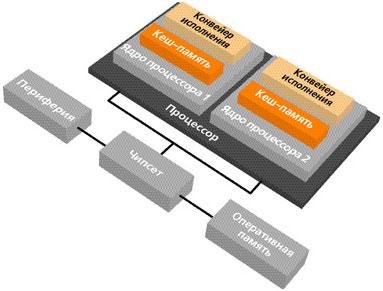
Они представляют собой революционную реализацию идеи нескольких ЦПУ и виртуальной мультипроцессорности Symmetrical MultiProcessing в едином корпусе.

Многоядерные процессоры могут быть основаны на связи ядер общим кэшем, сетью с коммутатором, разделяемой шиной. В большинстве модификаций, кэш 1-го уровень общий, а 2-й отдельный для каждого.
Мониторинг работы каждого из ядер пользователь ПК может проводить, используя Диспетчер задач, закладку Быстродействие. В окне панели будет показана хронология загрузки каждого из ядер и процессы ЦП.
Первым многоядерным микропроцессором стал POWER4 на основе архитектуры PowerPC AS от IBM, появившийся в 2001 году. Он имел два 64-битных ядра и общий промежуточный буфер памяти II уровня для быстрого доступа.
На сегодняшний день, уже известны 8-ми и 12-ти ядерные процессорные устройства. Хотя, в 2006 году Intel показала экспериментальный прототип 80-ядерного процессора будущего.
По поводу необходимости такого оснащения ядрами в домашних условиях и офисной работе, тут вопрос очень спорный. Любители 3D игр однозначно ощутят разницу. При наличии достаточного объема оперативной памяти, для рядового "неискушенного "пользователя скорость врядли будет очень заметной. Хотя, учитывая 18-20 обязательных системных программ, антивируса, работающего в фоновом режиме, все рабочие приложения будут работать в несколько "потоков" на разных ядрах. Это гарантия стабильной работы и быстрого отклика и максимального ускорения программ.
42.Современные многоядерные процессорв: ассмметричная структура AMP, симметричная структура SMP и исключительная многопроцессорность BMP.
|
Модель |
Принципы работы |
Ключевые преимущества |
|
Асимметричная многопроцессорность (AMP) |
Управление каждым ядром осуществляет отдельная операционная система или отдельная копия операционной системы, общей для нескольких ядер. Обычно каждый программный процесс привязан к одному ядру (например, процесс А выполняется только на ядре 1, процесс Б — только на ядре 2 и т. д.). Асимметричную многопроцессорность также называют архитектурой с независимыми узлами. |
Обеспечивает среду исполнения, схожую со средой исполнения однопроцессорных систем, что позволяет с легкостью переносить существующий код в AMP-системы. Асимметричная многопроцессорность также даёт разработчикам возможность независимо управлять каждым ядром. |
|
Симметричная многопроцессорность (SMP) |
Управление всеми процессорными ядрами одновременно осуществляет единственная операционная система. Процессы могут динамически перемещаться между любыми ядрами, что даёт возможность полной загрузки всех ядер. |
Обеспечивает большую масштабируемость и параллелизм, чем асимметричная многопроцессорность, а также упрощает управление ресурсами. |
|
Исключительная многопроцессорность (BMP) |
Управление всеми ядрами одновременно осуществляет единственная операционная система. Процессы могут динамически перемещаться между любыми ядрами или быть привязанными к определённому ядру. |
Обеспечивает масштабируемость и прозрачность управления ресурсами, как симметричная многопроцессорность, и даёт разработчикам возможность управления ядрами, как асимметричная многопроцессорность. Привязка процессов к конкретным ядрам позволяет с лёгкостью переносить существующий код в BMP-системы. |
43.архитектура северный мост- южный мост.
Классический чипсет состоит, как правило, из двух (реже - одной или трех) микросхем, в которых одна, поддерживающая контроллер памяти, AGP, и какую-либо вспомогательную шину (PCI либо любую другую) между микросхемами чипсета, обычно называется Northbridge. Соответственно, контроллеры ввода-вывода, а в последнее время и контроллер шины PCI, интегрируются в Southbridge. northbridge и Southbridge соединяются той или иной шиной. Примером Northbridge/Southbridge является Triton 430 ТХ.
На рисуноке приведена структура чипсета AMD 750, который имеет аналогичную архитектуру и ориентирован на процессор Athlon. Набор микросхем состоит из двух устройств: системного контроллера AMD-751 и контроллера периферийных устройств AMD 756.
Функции системного контроллера (Northbridge):
-
поддержка шинного интерфейса с процессором на частоте 200 МГц;
-
поддержка шины PCI 2.2 с подключением до шести устройств;
-
поддержка до 768 Мбайт ОП SDRAM DIMM;
-
совместимость со спецификациями AGP (1-х и 2-х графика).
Функции периферийного контроллера (Southbridge):
-
поддержка устройств Plug-n-Play и стандартов управления питанием ACPI 1.0 и АРМ 1.2;
-
поддержка контроллера клавиатуры и мыши;
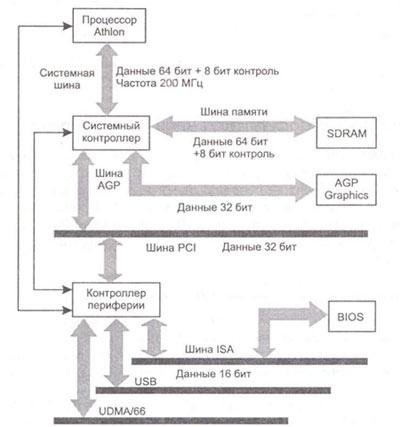
Архитектура «Северный мост-Южный мост»
-
функции IDE-контроллера с поддержкой возможностей Ultra DMA-33/66;
-
интегрированный контроллер шины ISA и мост ISA-PCI, удовлетворяющий спецификациям РС-97;
-
контроллер USB и концентратор на четыре порта
44.архитектура Hyper Transport
Технология
(архитектура) HyperTransport (НТ)
задумывалась как альтернатива
шинно-мостовой архитектуре системных
плат. Технология разработана компаниями
AMD, Apple Computers, Broadcom, Cisco Systems, NVIDIA, PMC- Sierra,
SGI, SiPackets, Sun Microsystems, Transmeta. Первый релиз
вышел в 2001 году, в 2003-м — версия 1.10.
Прежнее кодовое название — LDT (Lighting Data
Transport).
Основная
идея НТ —
замена шинного соединения компонентов
(периферийных устройств) системой
двухточечных встречно направленных
соединений. При этом достижима более
высокая тактовая частота интерфейсов,
что обеспечивает их более высокую (по
сравнению с шиной) пропускную способность.
Структурная схема компьютера архитектуры
НТ приведена на рис. 6.3. Главный мост
(host bridge) обеспечивает связь НТ с ядром
— процессором и памятью. Периферийные
контроллеры, требующие высокой пропускной
способности, реализуются в виде
НТ-туннелей. В архитектуре предусматривается
и мостовая связь с шиной PCI.
Архитектура
НТ обеспечивает все типы транзакций
процессоров и устройств PCI, PCI-X и AGP,
используемые в PC. Транзакции выполняются
в виде серий передач пакетов различных
типов. В традиционных транзакциях
целевое устройство идентифицируется
адресом: чтение и запись в пространстве
памяти, ввод-вывод в конфигурационном
пространстве, а также считывание вектора
прерывания из PIC 8259А и специальные циклы
PCI (см. 14.2). Для унификации транзакций
все пространства отображаются на единое
40-битное пространство адресов (объем 1
Тбайт), адрес передается в управляющих
пакетах. Первые 1012 Гбайт пространства
выделены для отображения обычного
пространства памяти (для ОЗУ и ввода-вывода,
отображенного на память). В оставшейся
12-гигабайтной области размещаются
конфигурационное пространство (32 Мбайт),
пространство ввода-вывода (32 Мбайт),
память SMM, пространства адресов для
выдачи векторов и подтверждения
прерываний; 54 Мбайт остались в резерве.
Транзакции НТ обеспечивают программное
взаимодействие процессора с устройствами,
прямой доступ к памяти и одноранговое
взаимодействие устройств с адресацией
в описанном комбинированном пространстве.
Существует сетевое расширение
спецификации, поддерживающее обмен
сообщениями (как в сетях), причем возможны
и широковещательные сообшения.
Транзакции
выполняются расщепленным способом:
инициатор посылает пакет-запрос и данные
для транзакции записи, целевое устройство
посылает пакет- ответ и данные для
транзакций чтения. Технология НТ
обеспечивает упорядоченность выполнения
транзакций; есть возможность регулировать
качество обслуживания (Quality of Service, QoS),
что позволяет организовывать изохронные
передачи.
Рис. 6.3. Архитектура
HyperTransport
Сигнализация прерываний в НТ
реализуется тоже пакетами: устройство
посылает сообщегше — выполняет транзакцию
записи по адресу, указанному ему при
конфигурировании (аналогично MSI на шине
PCI). Обработчик прерывания посылает
сообщение о завершении обработки
прерывания (End Of Interrupt, EOI), делая запись
по другому адресу, связанному с данным
устройством. Такой механизм сигнализации
запросов и подтверждений позволяет
преодолеть неэффективность традиционого
для PC механизма прерываний с помощью
специальных линий IRQ.
Архитектура НТ
основана на двусторонней пакетной
передаче данных между парой устройств.
Устройство НТ может выступать в роли
инициатора или/и целевого устройства
транзакций. По топологическим свойствам
различают несколько типов устройств
НТ:
¦ Туннель (tunnel) — устройство с двумя
интерфейсами НТ; такие устройства могут
собираться в цепочку (daisy chain), образующую
логическую шину. Цепочка подключается
к хосту (процессору с главным мостом),
отвечающему за конфигурирование всех
устройств и управляющему работой НТ.
 ¦
Мост (bridge) — устройство, соединяющее
одну логически первичную шину (подключенную
к хосту) с одной или несколькими логически
вторичными шинами (цепочками). Мост
имеет набор регистров, информация
которых позволяет управлять распространением
транзакций между этими шинами (аналогично
мосту PCI).
¦ Коммутатор (switch) — устройство
с несколькими интерефейсами НТ, по
структуре аналогичное нескольким мостам
PCI, подключенным к одной (внутренней)
шине.
¦ Тупик, или пещера (cave) — устройство
с одним интерфейсом НТ.
¦
Мост (bridge) — устройство, соединяющее
одну логически первичную шину (подключенную
к хосту) с одной или несколькими логически
вторичными шинами (цепочками). Мост
имеет набор регистров, информация
которых позволяет управлять распространением
транзакций между этими шинами (аналогично
мосту PCI).
¦ Коммутатор (switch) — устройство
с несколькими интерефейсами НТ, по
структуре аналогичное нескольким мостам
PCI, подключенным к одной (внутренней)
шине.
¦ Тупик, или пещера (cave) — устройство
с одним интерфейсом НТ.
45.классификация Флинна по способу взаимодействия потока команд и потока данных
По Флинну архитектуры вычислительных систем, работающих с потоками данных и потоками команд можно разделить на 4 класса:
SISD - Single Instruction Single Date - один поток команд, один поток данных.
SIMD - Single Instruction Multiple Date - один поток команд, множественный поток данных.
MISD - Multiple Instruction Single Date - Множественный поток данных, один поток команд.
MIMD - Multiple Instruction Multiple Date - множественный поток данных, множественный поток команд.
Архитектура SISD - это классическая архитектура фон Неймана. В вычислительной системе одно устройство управления и одно исполнительное устройство, например, одно универсальное арифметико - логическое устройство (АЛУ). Вычислительный процесс следует заданному в программе порядку вычислений.
Архитектура SIMD возникла в связи с развитием структур векторной или матричной обработки данных. Множество исполнительных устройств (АЛУ или процессоров) управляются одной последовательностью команд. При этом, каждый процессор обрабатывает свой поток данных. Массивы обрабатываемых данных представляются в виде матриц или векторов. Это довольно узкий круг задач. Вычислительные системы такого типа были специализированными. В таких системах решаются сложные системы линейных и нелинейных уравнений, задачи теории поля, исследования турбулентности и т.д. Векторную архитектуру имели многие первые суперЭВМ, например, первая суперЭВМ - ILLIAC-IV. Векторными были суперкомпьютеры семейства Cyber и Gray, отечественные параллельные системы - ПС-2000, ПС-3000.
Архитектура MISD - архитектура конвейерного типа. Исполнительные устройства ( АЛУ или процессоры) образуют конвейер. Выходные данные одной ступени передаются на вход следующей ступени, по такому принципу работают, например, конвейерные АЛУ.
Архитектура MIMD - архитектура, в которой каждое АЛУ или каждый процессор системы работают с собственным потоком команд. В Этой архитектуре возможно решение задач, которые разбиваются на мало связанные между собой части, которые могут решаться независимо. Архитектура может быть реализована и как многомашинная система. На приведенных ниже рисунках рассматриваются реализации нрассмотренных выше архитектур на АЛУ и устройствах управления, обрабатывающих потоки команд.

Рис.1.4. Архитектуры SISD-1, SIMD-2, MISD-3, MIMD-4.
В обычных последовательных компьютерах каждая команда может использовать только небольшое количество операндов. С усложнением структуры команд требовалось усложнять и структуру устройства управления ее выполнением. Устройство управления превратилось в процессор команд, а арифметико-логическое устройство в процессор данных. В первых моделях таких компьютеров процессор команд традиционно бездействовал во время выполнения команд в процессоре данных. Эта ситуация изменилась с введением поточной обработки в “векторных компьютерах.” Процессор команд извлекает следующую команду при обработке текущей команды, это позволяет сэкономить несколько машинных циклов при выполнении команды за счет ее предварительной подготовки к выполнению в процессоре данных и организовать поточную обработку векторных команд. Векторная команда включает наименование операции (код операции), адреса двух векторных операндов, адрес результирующего вектора и длину векторных операндов. Реализация векторной команды означает выполнение всех скалярных операций, из которых складывается векторная команда. Процесс выполнения команды разбивается на фазы.
46.Векторные и массово-параллельные процессоры
Наиболее распространённые суперкомпьютеры — массово-параллельные компьютерные системы. Они имеют десятки тысяч процессоров, взаимодействующих через сложную, иерархически организованую систему памяти.
В качестве примера рассмотрим характеристики многоцелевого массово-параллельного суперкомпьютера среднего класса Intel Pentium Pro 200. Этот компьютер содержит 9200 процессоров Pentium Pro на 200 Мгц, в сумме (теоретически) обеспечивающих производительность 1,34 Терафлоп (1 Терафлоп равен 1012 операций с плавающей точкой в секунду), имеет 537 Гбайт памяти и диски ёмкостью 2,25 Терабайт. Система весит 44 тонны (кондиционеры для неё — целых 300 тонн) и потребляет мощность 850 кВт.
Супер-компьютеры используются для решения сложных и больших научных задач (метеорология, гидродинамика и т. п.), в управлении, разведке, в качестве централизованных хранилищ информации и т.д.
Отличительной особенностью суперкомпьютеров являются векторные процессоры, оснащенные аппаратурой для параллельного выполнения операций с многомерными цифровыми объектами — векторами и матрицами. В них встроены векторные регистры и параллельный конвейерный механизм обработки. Если на обычном процессоре программист выполняет операции над каждым компонентом вектора по очереди, то на векторном — выдаёт сразу векторые команды.
Векторная аппаратура очень дорога, в частности, потому, что требуется много сверхбыстродействующей памяти под векторные регистры.
47.Подробная классификация систем много команд –много данных
MIMD (англ. Multiple Instruction stream, Multiple Data stream — Множественный поток Команд, Множественный поток Данных, сокращённо МКМД) — концепция архитектуры компьютера, используемая для достижения параллелизма вычислений. Машины имеют несколько процессоров, которые функционируют асинхронно и независимо. В любой момент, различные процессоры могут выполнять различные команды над различными частями данных. MIMD-архитектуры могут быть использованы в целом ряде областей, таких как системы автоматизированного проектирования / автоматизированное производство, моделирование, а также коммуникатор связей (communication switches). MIMD машины могут быть либо с общей памятью, либо с распределяемой памятью. Эта классификация основана на том как MIMD-процессоры получают доступ к памяти. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных.
Обработка разделена на несколько потоков, каждый с собственным аппаратным состоянием процессора, в рамках единственного определённого программным обеспечением процесса или в пределах множественных процессов. Поскольку система имеет несколько потоков, ожидающих выполнения (системные или пользовательские потоки), эта архитектура эффективно использует аппаратные ресурсы.
В MIMD могут возникнуть проблемы взаимной блокировки и состязания за обладание ресурсами, так как потоки, пытаясь получить доступ к ресурсам, могут столкнуться непредсказуемым способом. MIMD требует специального кодирования в операционной системе компьютера, но не требует изменений в прикладных программах, кроме случаев когда программы сами используют множественные потоки (MIMD прозрачен для однопоточных программ под управлением большинства операционных систем, если программы сами не отказываются от управления со стороны ОС). И системное и пользовательское программное обеспечение, возможно, должны использовать программные конструкции, такие как семафоры, чтобы препятствовать тому, чтобы один поток вмешался в другой, в случае если они содержат ссылку на одни и те же данные. Такое действие увеличивает сложность кода, снижает производительность и значительно увеличивают количество необходимого тестирования, хотя обычно не настолько чтобы свести на нет преимущества многопроцессорной обработки.
Подобные конфликты могут возникнуть на аппаратном уровне между процессорами, и должен обычно решаться аппаратными средствами, или с комбинацией программного обеспечения и оборудования.
48.Виды программного обеспечения: системное, прикладное, инструментальное
Систе́мное програ́ммное обеспе́чение — это комплекс программ, которые обеспечивают эффективное управление компонентамикомпьютерной системы, такими как процессор, оперативная память, устройства ввода-вывода, сетевое оборудование, выступая как «межслойный интерфейс», с одной стороны которого аппаратура, а с другой - приложения пользователя. В отличие от прикладного программного обеспечения, системное не решает конкретные прикладные задачи, а лишь обеспечивает работу других программ, управляет аппаратными ресурсами вычислительной системы и т.д.
-
BIOS
-
Операционная система
-
Общего назначения
-
Реального времени
-
Сетевая
-
Встраиваемая
-
К прикладному программному обеспечению (application software) относятся компьютерные программы, написанные для пользователей или самими пользователями, для задания компьютеру конкретной работы. Программы обработки заказов или создания списков рассылки — пример прикладного программного обеспечения. Программистов, которые пишут прикладное программное обеспечение, называют прикладными программистами.
-
программные средства общего назначения
-
Текстовые редакторы
-
Системы компьютерной вёрстки
-
Графические редакторы
-
СУБД
-
-
программные средства специального назначения
-
Экспертные системы
-
Мультимедиа приложения (Медиаплееры, программы для создания/редактирования видео, звука, Text-To-Speech и пр.)
-
Гипертекстовые системы (Электронные словари, энциклопедии, справочные системы)
-
Системы управления содержимым
-
-
программные средства профессионального уровня
-
САПР
-
АРМ
-
АСУ
-
АСУ ТП
-
АСНИ
-
Геоинформационные системы
-
Биллинговые системы
-
CRM
-
50. Понятие об инструментальном ПО
Инструмента́льное програ́ммное обеспе́чение — программное обеспечение, предназначенное для использования в ходе проектирования, разработки и сопровождения программ, в отличие отприкладного и системного программного обеспечения.
К этой категории относятся программы, предназначенные для разработки программного обеспечения:
-
ассемблеры — компьютерные программы, осуществляющие преобразование программы в форме исходного текста на языке ассемблера в машинные команды в виде объектного кода.
-
трансляторы - программы или технические средства, выполняющее трансляцию программы.
-
компиляторы — Программы, переводящие текст программы на языке высокого уровня, в эквивалентную программу на машинном языке.
-
интерпретаторы — Программы (иногда аппаратные средства), анализирующие команды или операторы программы и тут же выполняющие их
-
-
компоновщики (редакторы связей) — программы, которые производят компоновку — принимают на вход один или несколько объектных модулей и собирают по ним исполнимый модуль.
-
препроцессоры исходных текстов — это компьютерные программы, принимающие данные на входе и выдающие данные, предназначенные для входа другой программы, например, такой, как компилятор
-
Отла́дчик (debugger)- является модулем среды разработки или отдельным приложением, предназначенным для поиска ошибок в программе.
-
текстовые редакторы — компьютерные программы, предназначенные для создания и изменения текстовых файлов, а также их просмотра на экране, вывода на печать, поиска фрагментов текста и т. п.
-
специализированные редакторы исходных текстов — текстовые редакторы для создания и редактирования исходного кода программ. Специализированный редактор исходных текстов может быть отдельным приложением, или быть встроен в интегрированную среду разработки (IDE).
-
-
библиотеки подпрограмм — сборники подпрограмм или объектов, используемых для разработки программного обеспечения.
-
Редакторы графического интерфейса
51. Виды прикладного ПО: КИС , ERP. MRP, MRPII
Корпоративная информационная система (КИС) — управленческая идеология, объединяющая бизнес-стратегию и информационные технологии. Следует помнить, что КИС, в первую очередь, это система, и только в частном случае - информационная технология. (Википедия). Рано или поздно руководство любой компании сталкивается с проблемой систематизации информации и автоматизации процессов, работающих с информацией. Если на начальном этапе развития небольшой фирмы возможна ситуация, когда сотрудники компании используют стандартные офисные приложения, такие как, например, MS Office, для ведения складского, бухгалтерского, управленческого и других учетов, а руководству компании для принятия решения, подкрепленного достоверными данными Когда нужны Корпоративные Информационные Системы (КИС), ERP Systems?
, достаточно позвонить нужному сотруднику и попросить подготовить отчет в произвольной форме. То со временем рост объемов данных (по данным исследования объем информации, аккумулируемой компаниями, удваивается каждые 18 месяцев) ставит перед компанией задачу создания современной Корпоративной информационной системы, охватывающий все аспекты хозяйственной деятельности предприятия. То есть приобретение Корпоративной информационной системы не является самоцелью. Корпоративная информационная система, это лишь инструмент, который позволяет эффективно функционировать организации. Это касается работы, как рядовых исполнителей, так и менеджеров любого звена. Напрашивается аналогия с лопатой и комбайном. Имея пять соток земли, фермер в состоянии обрабатывать его, использую в качестве инструментов лопату и грабли. Увеличив свое хозяйство до пяти гектаров, ему уже не обойтись без комбайна. Комбайн в этом случае по-прежнему инструмент (не с точки зрения бухгалтерского учета), более совершенный, требующий знаний и навыков обращения с ним, но все же инструмент.
Зачем нужна Корпоративная Информационная Система (КИС), ERP System? Задачи, решаемые Корпоративной Информационной Системой (КИС), ERP System
Таким образом, приобретение Корпоративной Информационной Системы (КИС), ERP System, это лишь приобретение инструмента, позволяющего сохранить управление над компанией либо повысить эффективность этого управления. "Автоматического управления", к сожалению, не бывает. Поэтому если после внедрения Корпоративной Информационной Системы (КИС), ERP System не ускоряется процесс сбора и обработки информации, не повышается достоверность и полнота данных, а руководство организации не получает новых данных, или не может правильно их использовать, то информация остается невостребованной, а это не приводит к повышению эффективности решений. Корпоративная Информационная Система (КИС), ERP System сама по себе не повышает прибыльность предприятия. Она может повысить эффективность и ускорить процесс обработки данных, может предоставить информацию для принятия решений. Увеличивают прибыльность эффективные решения на основе этой информации. Поэтому необходимо не только правильно выбрать и внедритьКорпоративную Информационную Систему (КИС), ERP System, но и научиться ее использовать с максимальной отдачей. Причем понимание возможностей и способов использования Корпоративной Информационной Системы (КИС), ERP System должно предшествовать, а точнее определять выбор, поставщика и процесс внедрения Корпоративной Информационной Системы (КИС), ERP System. Главное, что позволяет сделать Корпоративную Информационную Систему (КИС), ERP System - объединить информацию о деятельности предприятия. Для промышленного предприятия это - данные о производстве, финансах, закупках, сбыте. На основе полученной информации руководитель может оперативно корректировать и планировать деятельность предприятия. Он получает возможность увидеть все предприятие изнутри, посмотреть, как функционируют основные системы, где и за счет чего можно минимизировать издержки, что мешает увеличить прибыль. Также возрастает потребность и в аналитических свойствах Корпоративной Информационной Системы (КИС), ERP System. Руководство холдингов заинтересовано в консолидации информации, поступающей из филиалов и центральных офисов их предприятий, а также в возможности проведения дистанционного мониторинга состояния всех подразделений.
Типовые цели внедрения Корпоративной Информационной Системы (КИС), ERP System
1. Оперативный доступ к достоверной, исчерпывающей информации, представленной в удобном виде, руководителей всех уровней управления предприятием; 2. Создание единого информационного пространства для всех уровней управления; 3. Упрощение регистрации данных и их обработку; 4. Избавление от двойной регистрации одних и тех же данных; 5. Регистрация информации там, где она действительно появляется, а не там где она стала необходимой, т.е. регистрация информации в режиме реального времени; 6. Снижение трудозатрат и распределение их равномерно на всех участников системы учета, планирования и управления; 7. Автоматизация консолидации данных для распределенной организационной структуры (холдингов).
Внедрение Корпоративной Информационной Системы (КИС), ERP System
Нередко Заказчик ожидает, что Корпоративная Информационная Система (КИС), ERP System сама внедрится и заработает на предприятии, но основной "особенностью" проектов является то, что ими нужно управлять.
Выбор поставщика Корпоративной Информационной Системы (КИС), ERP System
Выбор поставщика Корпоративной Информационной Системы (КИС), ERP System целесообразно производить в режиме коммерческого тендера, что позволяет максимально объективно анализировать предложения и вести предметный диалог с потенциальными поставщиками.
Выбор Корпоративной Информационной Системы (КИС), ERP System
При выборе Корпоративной Информационной Системы (КИС), ERP System нужно всегда руководствоваться исходной постановкой задачи. Не стоит пытаться отвечать на возникающие вопросы самому, исходя из прочитанных маркетинговых брошюр. На конкретные вопросы, касающиеся применимости Корпоративной Информационной Системы (КИС), ERP System в каждом случае, должны отвечать специалисты поставщика, подтверждая каждый свой ответ соответствующей демонстрацией (показом действующей системы у других клиентов, настройкой контрольного примера и т. д.).
Сопровождение Корпоративной Информационной Системы (КИС), ERP System
Условия сопровождения Корпоративной Информационной Системы (КИС), ERP System необходимо оговаривать и фиксировать в договоре на покупку и внедрение Корпоративной Информационной Системы (КИС), либо одновременно подписывать отдельный договор на сопровождение, для того, чтобы заложить в смету затраты на сопровождение и зафиксировать стоимость этих услуг.
Оценка эффективности Корпоративной Информационной Системы (КИС), ERP System
В настоящий момент существуют 3 использующихся подхода к оценке эффективности инвестиций в реализацию Корпоративной Информационной Системы (КИС), ERP System: бенчмаркинг (постфактум анализ результатов похожих проектов), экспертная оценка и применение метода сбалансированной оценочной ведомости (The Balanced Scorecard). Последний был разработан в 1990 году Дэвидом Нортоном и Питером Капланом и представляет собой современную методику анализа состояния компании, базирующуюся на нефинансовых показателях. Эта методика позволяет рассматривать Корпоративную Информационную Систему (КИС), ERP System как элемент компании, представляющий собой одно из главных стратегических преимуществ с точки зрения технологичности бизнеса, и оценивать итоговые экономические показатели в результате экспертного анализа качественных улучшений бизнес-процессов на всех уровнях управленческой иерархии. Однако очевидно, что точного преобразования из качества в количество добиться невозможно, поэтому и этот подход страдает определенным субъективизмом. Тем не менее, его применение, особенно с привлечением нескольких экспертов, является целесообразным. Дополнительно необходимо осознавать тот факт, что любая Корпоративная Информационная Система (КИС), ERP System может оцениваться только применительно к конкретной задаче и никоим образом не сам по себе.
52.Виды прикладного ПО: финансовые системы
В первое десятилетие XXI в. в России, в силу усложнения структуры финансовых взаимоотношений личности и личных финансовых операций (из-за появления института кредитования, дифференциации доходов по слоям населения и во времени, увеличении статей расходов, появлении возможности частных инвестиций и пр.), набирает популярность управление личными финансами. Чаще всего для этих целей используют персональные системы бухгалтерского учёта.
К отличительным чертам таких систем можно отнести (не все признаки могут встречаться в системе одновременно):
-
Простая система использования и управления.
-
Предварительная настройка счетов для бытовых применений.
-
Малая стоимость, либо полная бесплатность (возможно, за просмотр рекламы или с потенциальным переходом к более функциональной платной версии).
-
Упрощённая система безопасности (аутентификация, как правило, производится с помощью комбинации «имя пользователя — пароль» и / или комбинации «имя базы данных — пароль»).
-
Закрытый формат базы данных (БД), что не позволяет импортировать данные в другие системы и привязывает пользователя к используемой.
-
Упрощённые средства анализа и генерации отчётов.
-
Возможность хранения данных на сервере, доступном из глобальной сети Интернет, что позволяет связываться и работать со своей бухгалтерской БД с любого компьютера и/или выполнять синхронизацию БД на нескольких компьютерах.
Примерами таких систем могут служить отечественные разработки Family, «Домашняя бухгалтерия»[1], DomEconom, jMoney[2]. В США наиболее популярной системой такого рода является Quicken, раньше популярностью пользовалась также система Microsoft Money[3]. Среди открытого программного обеспечения можно упомянуть GnuCash и KMyMoney.
Альтернативой персональным системам бухгалтерского учета являются программы для ведения электронных таблиц, такие как Microsoft Excel либо OpenOffice.org Calc. Для электронных таблиц разработано множество уже готовых файлов для учета домашних финансов, например, My Finance[4]. Обычно отмеченные разработки бесплатны и более просты в освоении, однако обладают более скудным функционалом по сравнению с персональными программными системами бухгалтерского учёта, правда появились уже серьезные профессиональные системы , использующие именно электронные таблицы в качестве баз данных и серьезно конкурирующие с традиционными системами СУБД.
В последнее время, с ростом аудитории Интернета, стали пользоваться популярностью онлайн-системы для ведения домашней бухгалтерии, такие как Mint.com[5], Home.Finance.Ua[6]. Предоставляя тот же набор возможностей по анализу и планированию бюджетов они имеют ряд преимуществ: доступ к финансовой информации через интернет-браузер (в том числе через мобильные устройства) независимость от Операционных систем, мониторинг состояния банковских счетов.
Финансовые функции используются для вычисления ежегодного дохода, процентных начислений, амортизационных начислений и других финансовых показателей за будущий, текущий и прошедший периоды. Excel предлагает более пятидесяти финансовых функций, которые могут быть использованы как в отдельности, так и в комбинации с другими функциями для выполнения более сложных вычислений. Каждая функция сопровождается синтаксическим описанием, что помогает понять суть проводимых ею вычислений. Кроме того, каждая функция содержит несколько аргументов, которые требуют постановки соответствующих значений. Значения должны быть строго определенного формата. В табл.4 дано краткое описание финансовых функций.
53.CRM – системы (на примере)
-
Высокая гибкость системы В стандартной версии клиентского досье имеется широкий спектр атрибутов, В систему заложено много полезных алгоритмов. Однако реализация клиент-ориентрованных стратегий является одной из наименее стандартизованных составных частей управления предприятием, т.к. включает наработанные ноу-хау по общению с клиентом. Кроме того, это еще и наиболее "подвижная" часть бизнес-процессов, ибо, чтобы побеждать в конкурентной борьбе, постоянно приходится придумывать новые методы. Встроенный в CRM-систему визуальный инструмент "Мастера КОМПАСа" позволяет легко и быстро собственными силами, не прибегая к услугам сторонних консультантов, создать индивидуальную версию CRM-системы и внести в нее все имеющиеся ноу-хау.
-
Отпуск товаров с учетом складских остатков В отличие от "независимых" CRM-систем CRM-система "КОМПАС: Маркетинг и менеджмент", внедренная вместе с программой складского учета, позволяет менеджеру контролировать наличие тех или иных товаров при оформлении документов на их отпуск.
-
Развитая система прайс-листов, наценок, скидок Для ускорения подготовки накладных и счетов покупателям (оптовики знают, что недостаточная скорость выпуска этих документов может порой привести даже к потере клиента) предназначена система автоматических наценок/скидок. Программа позволяет поддерживать любое количество прайс-листов. Цена может выбираться из нужного прайс-листа (указывается его номер) или рассчитываться автоматически по формуле с самыми разнообразными аргументами. Например, цена может зависеть от объема закупаемой партии или от категории покупателя.
-
Наличие функционала контроля взаиморасчетов с предельными сроками платежей
-
Процедура автоматического ранжирования клиентов Функционал автоматического ранжирования клиентов на основе анализа уровня их доходности (ABC-анализ) позволяет не только печатать соответствующие отчеты, но автоматически переносить клиентов в группы соответствующей приоритетности.
-
Встроенный функционал управления материальной мотивацией CRM-система позволяет настроить автоматический расчет бонусов за выполнение и перевыполнение плана по любом суммовым и/или количественным показателям (объем личных продаж, количество контактов, количество подготовленных документов и т.п.). Бонусы могут рассчитываться как процент от величины показателя, так и непосредственно в рублях. Расчет может быть ступенчатым, причем количество ступеней произвольное. Например, за перевыполнение плана до 30% добавляется 2% от реализации, а от 31% до 100% - уже 3%. Аналогичным образом можно настроить расчет штрафов за невыполнение плана.
-
Поддержка оптимальных стратегий общения с клиентом Встроенный в CRM-систему аппарат WorkFlow позволяет стандартизовать бизнес-процессы общения с клиентами, вовремя напоминать менеджерам о необходимости совершения следующего контакта, а также ускорить обучение новых сотрудников. Процедура автоматического ранжирования клиентов по уровню доходности (ABC-анализ) помогает выявить VIP-клиентов, на которые менеджерам следует направлять основные усилия.
-
Планирование затрат и контроль бюджета на маркетинговые кампании Система позволяет учесть фактические и плановые затраты на различные варианты маркетинговых кампаний и сравнить их между собой, а также произвести сравнение "факт / план". В сочетании со встроенными в CRM-систему функциями оценки эффективности проведенных маркетинговых кампаний это позволяет в дальнейшем выбирать оптимальный вариант воздействия на рынок.
-
Планирование маркетинговых кампаний по образцу Этот функционал CRM-системы ускоряет подготовку маркетинговых кампаний, т.к. позволяет не вводить всю информацию заново, а только откорректировать уже имеющийся вариант.
-
Автоматизация внутреннего управления предприятием Помимо стандартных функций управления взаимоотношениями с клиентами и обслуживания маркетинговых кампаний, в CRM-систему "КОМПАС: Маркетинг и менеджмент" включены процедуры, автоматизирующие внутреннее управление предприятием (Time Management): планирование и контроль работы сотрудников, управление совещаниями и др.
-
Сегментация клиентов по произвольным наборам признаков
-
Наличие резидентной программы напоминания в режиме online
-
Функции электронной рассылки Система позволяет поддерживать разнообразные списки рассылки по потенциальным и действующим клиентам.
системы управления цепочками поставок
Системы управления цепями поставок (англ. Supply Chain Management, SCM) предназначены для автоматизации и управления всеми этапами снабжения предприятия и для контроля всего товародвижения на предприятии. Система SCM позволяет значительно лучше удовлетворить спрос на продукцию компании и значительно снизить затраты на логистику и закупки. SCM охватывает весь цикл закупки сырья, производства и распространения товара. Исследователи, как правило, выделяют шесть основных областей, на которых сосредоточено управление цепями поставок: производство, поставки, месторасположение, запасы, транспортировка и информация.
В составе SCM-системы можно условно выделить две подсистемы:
-
SCP — (англ. Supply Chain Planning) — планирование цепочек поставок. Основу SCP составляют системы для расширенного планирования и формирования календарных графиков. В SCP также входят системы для совместной разработки прогнозов. Помимо решения задач оперативного управления, SCP-системы позволяют осуществлять стратегическое планирование структуры цепочки поставок: разрабатывать планы сети поставок, моделировать различные ситуации, оценивать уровень выполнения операций, сравнивать плановые и текущие показатели.
-
SCE — (англ. Supply Chain Execution) — исполнение цепей поставок в режиме реального времени.
Управление цепями поставок (SCM)
-
Управление цепями поставок (Supply Chain Management - SCM) представляет собой процесс планирования, исполнения и контроля с точки зрения снижения затрат потока сырья, материалов, незавершенного производства, готовой продукции, сервиса и связанной информации от точки зарождения заявки до точки потребления (включая импорт, экспорт, внутренние и внешние перемещения), т.е. до полного удовлетворения требований клиентов. Сущностью понятия "управления цепочками поставок" является рассмотрение логистических операций на протяжении всего жизненного цикла изделий, т.е. процесс разработки, производства, продажи готовых изделий и их послепродажное обслуживание.
-
Управление цепями поставок представляет собой стратегию бизнеса, обеспечивающую эффективное управление материальными, финансовыми и информационными потоками для обеспечения их синхронизации в распределенных организационных структурах.