

3.4. Индексы
Индексы применяются для ускорения доступа к записям базы данных. Их можно сравнить с предметным указателем книги – упорядоченной последовательностью слов (словосочетаний) с перечнем номеров страниц, на которых встречается это слово (словосочетание).
Индекс базы данных представляет собой структуру, в которой содержатся рассортированные в заданном порядке значения данных в некотором поле и указатели адресов записей (страниц), где находятся эти значения. В отличие от инвертированных списков индексы занимают значительно меньшее место во внешней памяти.
Построение индекса и его обновление выполняется автоматически самой СУБД. Файл базы данных, для которого создан хотя бы один индекс, называется индексированным файлом.
Дополним табл. 3.1 сведениями о номерах страниц, на которых хранятся записи с данными (для простоты будем полагать, что каждая запись хранится на отдельной странице внешней памяти) (табл. 3.3):
Таблица 3.3
Сведения о поставках товаров в магазин
Номер накладной |
Название товара |
Артикул |
Количество |
Дата поставки |
Номер страницы |
37 |
Костюм |
500 |
50 |
10.12.05 |
1 |
54 |
Сапоги |
200 |
75 |
10.12.05 |
2 |
18 |
Туфли |
100 |
120 |
11.12.05 |
3 |
60 |
Костюм |
500 |
35 |
11.12.05 |
4 |
28 |
Костюм |
300 |
20 |
12.12.05 |
5 |
74 |
Костюм |
400 |
50 |
12.12.05 |
6 |
80 |
Туфли |
100 |
100 |
12.12.05 |
7 |
Индекс, созданный для поля Название товара, обеспечивающий быстрый поиск данных в этом поле, будет иметь вид (табл. 3.4):
Таблица 3.4
Индекс Товар
Название товара |
Номера страниц |
Костюм |
1, 4, 5, 6 |
Сапоги |
2 |
Туфли |
3, 7 |
Поиск и выборка нужных записей в базе данных осуществляются в следующей последовательности:
Выбирается индекс, соответствующий условию поиска (например Товар, если в запросе выполняется поиск товара с конкретным названием).
В индексе находится строка с заданным условием поиска (например Туфли).
Из найденной строки выбираются номера страниц, где хранятся искомые записи.
Полученные номера страниц используются для чтения необходимой информации.
Большинство СУБД реализует этот процесс автоматически, без участия пользователя.
Если для таблицы определены несколько индексов по отдельным полям, при поиске записей в данной таблице по условиям поиска, заданным в этих полях, соответствующие индексы используются совместно.
Например, для поля Дата поставки табл. 3.3 создан также индекс Дата (табл. 3.5):
Таблица 3.5
Индекс Дата
-
Дата поставки
Номера страниц
10.12.05
1, 2
11.12.05
3, 4
12.12.05
5, 6, 7
При выполнении запроса «Найти сведения о туфлях, поступивших 11 декабря 2005 г.», номера страниц в индексе Товар для значения данных Туфли будут сравниваться с номерами страниц значения 11.12.05 в индексе Дата. В результате будет выбран номер страницы, встречающийся в обоих индексах, равный 3.
Если поиск достаточно часто производится по одним и тем же полям, желательно создать составной индекс, включающий несколько полей. При использовании составного индекса сокращается время поиска, так как не приходится сравнивать значения данных из нескольких индексов.
Проиллюстрируем процесс создания индексов на примере MS Access.
Если индекс создается по одному полю, необходимо выполнить действия:
Открыть таблицу в режиме Конструктора.
Активизировать поле, для которого создается индекс.
Выбрать свойство поля Индексированное поле.
Выбрать для данного свойства одно из значений:
Да (Допускаются совпадения);
Да (Совпадения не допускаются).
Для ключевого поля индекс в MS Access создается автоматически.
Для создания составного индекса следует открыть таблицу в режиме Конструктора, нажать кнопку Индексы на панели инструментов или выполнить действия ВидИндексы, затем в появившемся диалоговом окне ввести имя индекса и указать имена полей, по которым он создается.
В MS Access имеются следующие ограничения:
в таблице не может быть более 32 индексов;
в составном индексе не может быть более 10 полей.
Индексы могут быть плотными, когда в них содержатся указатели на все записи индексированной таблицы, и неплотными – указатели создаются для блоков, включающих наборы записей. Детальная характеристика и примеры указанных понятий приводятся в работах [ 2, 4 ].
Для больших таблиц сами индексы могут занимать несколько страниц во внешней памяти. В таких ситуациях создаются многоуровневые индексы, например, в виде сбалансированных деревьев (B-дерево или Balanced-tree), имеющих иерархическую структуру [ 2, 4 ]. Целью создания B-дерева является ускорение поиска, стремление избежать просмотра всего индекса.
Рассмотрим процесс построения B-дерева на простом примере. Предположим, таблица сведений о поставках товаров в магазин включает 18 записей и индексируется по номерам накладных: 18, 28, 37, 54, 59, 60, 61, 67, 68, 70, 77, 80, 83, 91, 93, 96, 98, 99. На каждой странице в памяти содержатся только два адреса (фактически их может быть больше).
Размещаем на корневой странице дерева значения данных в поле Номер накладной, равные 60 и 82, и три указателя (рис. 5). Данные со значениями в поле Номер накладной, меньшие или равные 60, могут быть найдены с помощью левого указателя; бóльшие 60 и меньшие или равные 82 – с помощью среднего указателя; бóльшие 82 – с помощью правого указателя (см. рис. 5). Другие страницы индекса интерпретируются аналогичным образом.
На нижнем уровне B-дерева находится множество страниц с указателями на страницы, где хранятся данные (см. рис. 5).
Для нахождения с помощью B-дерева адреса размещения во внешней памяти любой страницы с данными, достаточно последовательно рассмотреть только три страницы индекса (на рис. 5 жирными стрелками указан маршрут поиска страницы с номером накладной 77), что существенно меньше общего количества страниц с данными.
60 82
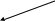
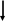
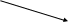
29 54
67 75
91 97






18 28
37 54
59 60
61 67
68 70
77 80
83 91
93 96
98 99
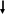
указатели на страницы, где находятся данные
Рис. 5. Индекс в виде B-дерева
Реальные данные, для которых строится многоуровневый индекс, часто не позволяют непосредственно получить сбалансированное дерево, построенное на рис. 5. В таких случаях для его создания применяются специальные алгоритмы, рассмотренные, например, в работе [ 2 ].
Недостатком индексирования является необходимость выделения во внешней памяти дополнительного места для хранения индексов. Существуют оценки, что файл, в котором созданы индексы для всех полей размещенной в нем таблицы, занимает практически вдвое больше места на внешнем носителе по сравнению с исходным файлом [ 12 ]. Кроме того, наличие индексов затрудняет обновление информации, хранящейся в базе данных, и требует дополнительных затрат времени на данный процесс.
Поэтому не рекомендуется индексировать все поля таблиц или поля, данные в которых часто изменяются. Наиболее эффективным является создание индексов для первичных и внешних ключей, для полей, по которым в основном выполняются запросы.