

Функция и плотность распределения непрерывной случайной величины
О. Функция распределения случайной величины X называется функция действительной переменной x, определяемая равенством:
F(x)=P(X<x)
P(X<x) – вероятность того, что случайная величина примет значение, меньше x

Свойства:
Все значения отрезка принадлежат от 0 до 1 0≤F(x)≤1
Функция распределения является неубывающей
Если все возможные значения случайной величины x принадлежат бесконечному промежутку (-;+), то
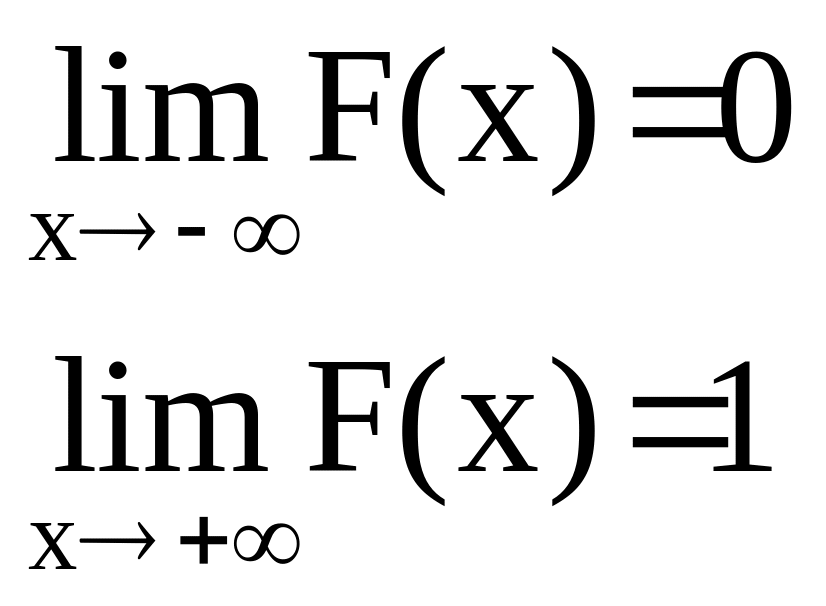
Следствие
Если X – непрерывная случайная величина, то вероятность того, что она примет одно конкретное значение равна 0.
Теорема
Вероятность того, что случайная величина примет значение в интервале (;) [a;b] равна разности значений её функции распределения на концах этого интервала: P(<X<)= F()-F()
О. Плотностью распределения вероятностей непрерывной случайной величины X называется производная её функции распределения вероятностей f(x)=F’(x).
Если известна плотность распределения, то функцию распределения можно найти по формуле:
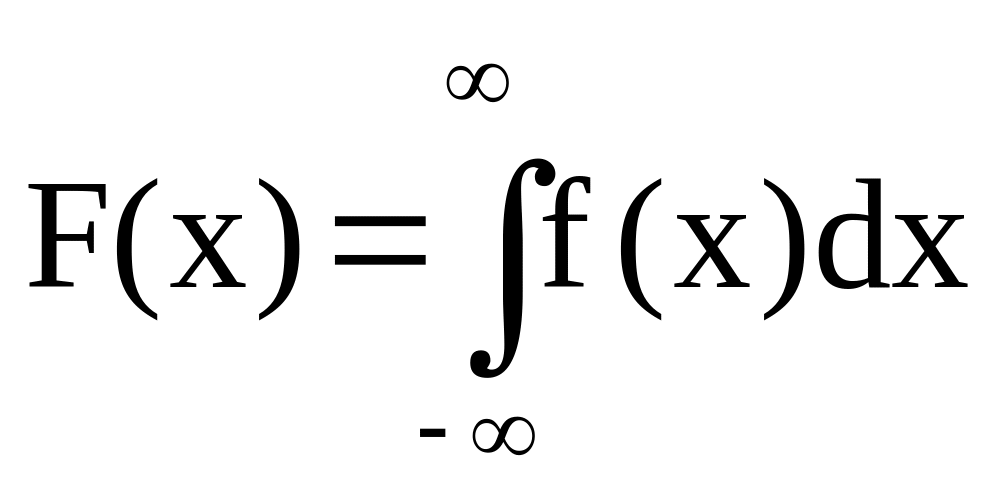
Свойства плотности распределения:
Плотность распределения – неотрицательная функция
Интеграл по бесконечному промежутку от плотности распределения вероятности равен 1

Следствие:
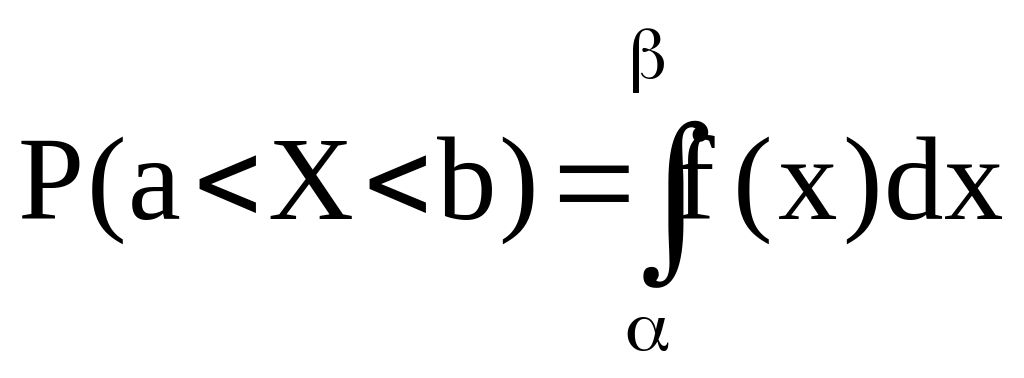
Пример: Плотность распределения вероятности имеет вид:
Рис1
Числовые характеристики непрерывных случайных величин
О. Математическим ожиданием непрерывной случайной величины X называется значение интеграла:

Если все значения непрерывной случайной величины принадлежат промежутку [a;b], то математическое ожидание находится по формуле:
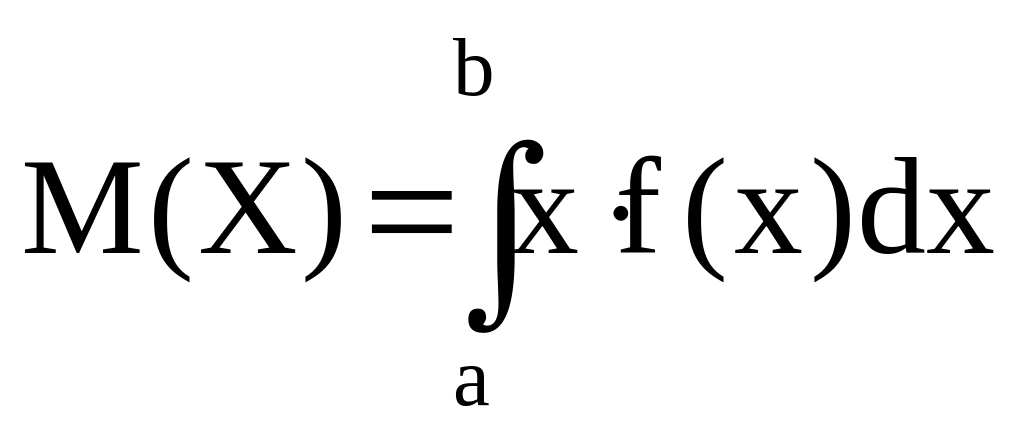
Рис2
Дисперсия непрерывной случайной величины находится по формулам:
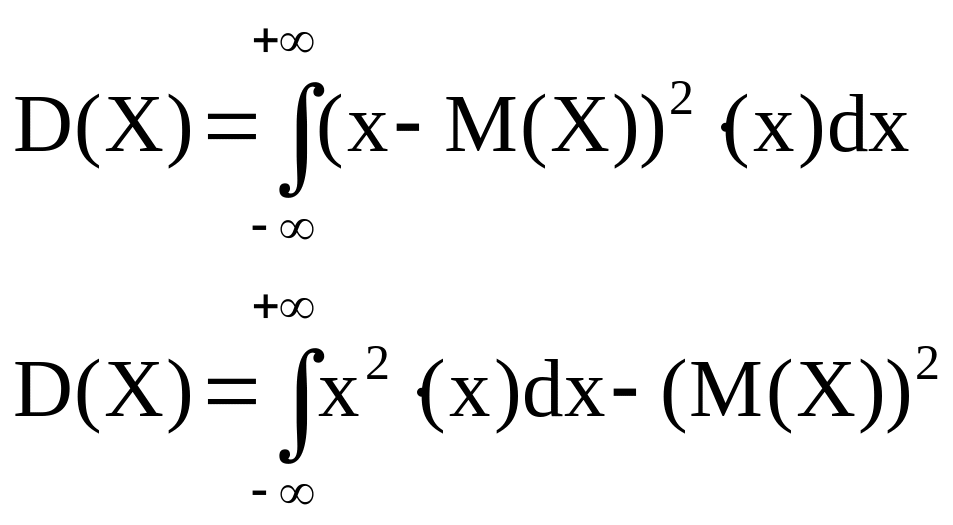
ВОПРОС № 9.
Нормальное распределение непрерывной случайной величины.
Принимается в большинстве вероятностно-статистических исследований в экономике, социологии, медицине и т. д.
Нормальное распределение рассмотрено впервые Муавром в 1733 году. В 1809 – открыто Гаусом. Распределение Муавра-Лапласса-Гауса занимает ведущее место в вероятностно-статистических исследованиях.
Опр. Случайная величина Х распределена по нормальному закону если ее плотность распределения имеет вид:
f(x) = 1/сигма корень из 2П * на Е в степени –(х- (M(x))^2/ 2сигма ^2

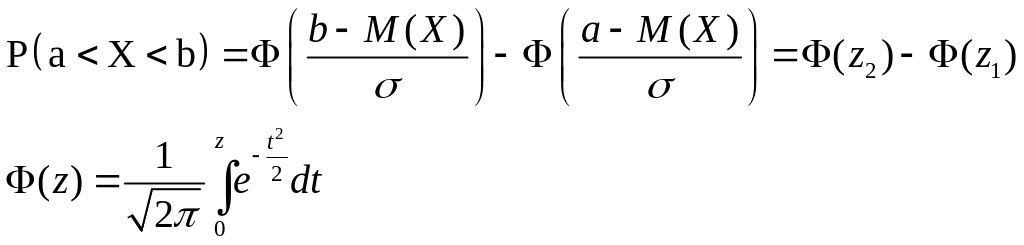
Пример (7)
Пусть M(X)=80кг
σ=5кг
p=0,98
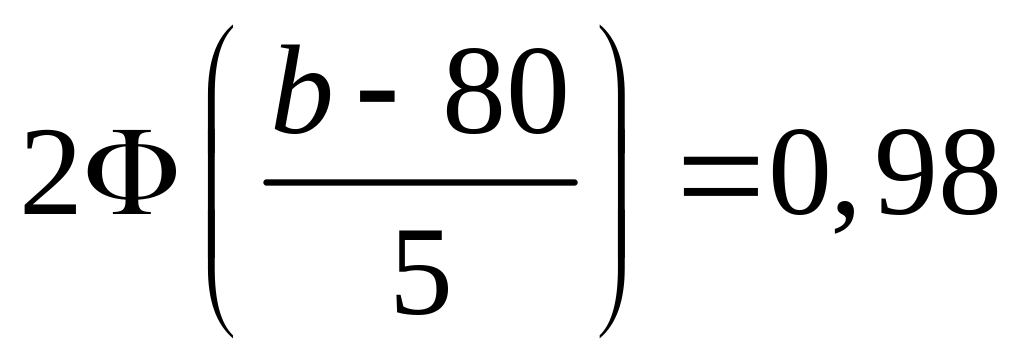
Функция Лапласса
Нормальное распределение зависит от двух параметров: Математическое ожидание и среднеквадратическое отклонение Функция Лапласса является нечетной функцией. Ф(-z)=-Ф(z)
ВОПРОС № 10
Равномерное распределение
Равномерное распределение применяется при анализе времени ожидания, при точно-периодическом через каждые t единиц времени прибытии обслуживающего устройства и при случайном поступлении заявки на обслуживание в этом интервале.
О. Равномерно распределенная на отрезка [a;b] случайная величина имеет плотность распределение
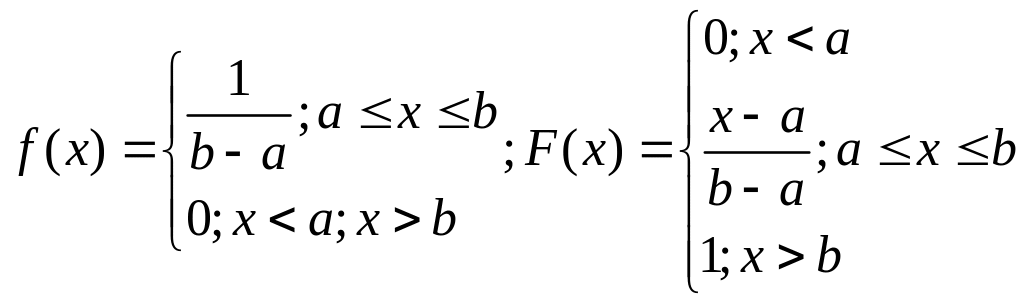
Вероятность того, что случайная величина попадет в промежуток (α<X<β), равна:
![]()
Показательное распределение. Показательное ( экспоненциальное ) распределение описывает случайные величины характеризующие длительность жизни, элементов, систем индивидуума ( задачи теории надежности, демографии и др.)
Опр. Распределение непрерывной случайной величины Х называется показательным если плотность распределения имеет вид:
f(x)= Система: 0, х<0; Л е^ -Лх, Х>=0
Вероятность попаданий случайной величины Х от а А до В равна е^-Ла – е^-Лв
Р(а<X<в) = е^-Ла – е^-Лв
F(в)- F(a)= 1– е^-Лв – (1- е^-Ла)
Математическое ожидание, дисперсия и среднеквадратическое отклонение показательного распределения соответственно равны:
М(х)= 1/Л
ВОПРОС № 11
ВОПРОС № 12. Коэффициент корреляции. Уравнение линейной регрессии
Коэффициент корреляции случайных величин называют величину «ро»
Рху = на листочке
Зависимость между случайными величинами Х и У характеризуемая коэффициентом корреляцией называется корреляцией. Случайной величиной (СВ) ХУ называются некоррелированными если «ро» ху = 0, что равносильно (сигма ху = 0)
Если «ро» ху не равно нулю, то СВ ху называют коррелируемыми.
Св-ва коэф. Корреляции: ( на листочке)
Если Х и У независимы СВ, то ХУ – некоррелированные, обратное утверждение неверно.
Уравнение линейной регрессии: У=а+вх
ВОПРОС № 13
Центральная предельная теорема. Закон больших чисел.
Под законом больших чисел в теории вероятности понимается ряд теорем в каждой из которых устанавливается факт приближения средних характеристик большого числа опытов к некоторым определенным постоянным. В основе лежит неравенство Чебышева (Пафнутий)
Теорема.
Неравенство Чебышева. Пусть имеется СВ Х с математическим ожиданием m и дисперсией Д, каково бы нибыло положительное число Е вероятностью того, что величина Х отклонится от своего математического ожидания не менее чем на Е ограничено сверху числом Д/ Е^2. P(|x-m|>=E)<=Д/Е^2, еще можно записать в эквивалентной форме если перейти от события |x-m|>=E к противоположенному событию |x-m|<E , то тогда
P(|x-m|<E)> 1-Е^2
Теорема. Пусть имеется бесконечная последовательность Х1, Х2… независимых случайных величин с одним и тем же математическим ожиданиемm и дисперсией с ограниченным числом C тогда каково бы ни было положительное число Е вероятность события |((x1+x2+…xn)/n)-m|<E стремится к 1 при n -> бесконечн. Тем самым оправдывается рекомендуемый в практической деятельности метод получения более точных результатов, измерений т.е. берется среднее арифметическое большого числа измерений.
Центральная предельная теорема:
Величина Sn=(X1+X2+…Xn)/n случайная, а значит имеет некоторый закон распределения. Распределение суммы большого числа независимых случайных величин при весьма общих условий близка к нормальному распределению.
Есть еще теорема в форме Ляпунова.
ВОПРОС № 14.
Генеральная совокупность и выборка. Вариационный ряд. Гистограмма и полигон частот. Эмпирическая функция распределения.
Генеральной совокупностью называют совокупность объектов из которых производится выборкой.
Выборкой называют совокупность случайно отобранных объектов.
Если выборка правильно отражает соотношение в генеральной совокупности то ее называют репрезентативной ( представительной)
Объемом совокупности называют число ее объектов. Выборка представляет собой ряд чисел являющимися характеристиками исследуемых объектов. Вариационный ряд Х*1 Х*2 ….Х*n представляет собой ту же самую выборку но расположены в порядке неубывания элементов:
Х*1 <= Х*2 <=…<= Х*n
Значение случайной величины соответствующие отдельной группе сгруппированного ряда наблюдаемых данных называется вариантой (Хi)
Численность отдельной группы сгруппированного ряда наблюдаемых данных называется частотой вариантой (ni)
Σni =n
Отношение частоты данной варианты к объему выборки называется относительной частотой данной варианты. Р*i = ni/n
Дискретным вариационным рядом называется ранжированная ( в порядке неубывания) совокупность вариант Xi c соответствующим им частотами или относительными частотами.
Интервальным вариационным рядом называется упорядоченная последовательность интервалов варьирования случайной величины с соответствующими частотами или относительными частотами попаданий в каждой из них значений случайной величины. Для наглядности наблюдаемые данные изображают графически. Интервальный вариационный ряд графически изображается с помощью гистограммы. Для ее построения в прямоугольной системе координат на оси Х откладываются интервалы варьирования, а на оси У частоты или относительной частоты.
Вариационный ряд дискретной случайной величины графически представляет в виде полигона распределение частот или относительных частот, для этого в прямоугольной системе координат строятся точки с координатами (Хi; ni) затем последовательно соединяются ломанными линиями, которые называются полигонами.
Эмпирическая функция распределения случайной величины Х называют функцию относительной частоты числа наблюдений nх
F*(x)=nx/n, где nx/n – относительная частота события где Х<х. Эта функция служит для приближенного представления о теоретической функции распределения. График эмпирической функции называют графиком накопленных частот.
Функция дискретной случайной величины. Начальные моменты. Основные распределения дискретной случайной величины.
О. Функция распределения для дискретной случайной величины X, которая может принимать значения x1, x2 … xn с соответствующими вероятностями имеет вид:
![]()
Суммируются вероятности тех значений, которые меньше x.
Пример
X |
0 |
1 |
2 |
3 |
P |
0,2 |
0,4 |
0,3 |
0,1 |
Дискретная случайная величина x делит бесконечную прямую на промежутки:
X |
(-∞;0] |
(0;1] |
(1;2] |
(2;3] |
(3;+∞] |
P |
0 |
0,2 |
0,6 |
0,9 |
1 |
Начальные и центральные моменты
Начальные и центральным момента k случайной величины X считается математическое ожидание величины X в степени k:

Начальный момент равен математическому ожиданию случайной величины X V1=M(X)
Центральным моментом порядка k случайной величины X называется математическое ожидание величины (X-M(X))k и обозначается: μk=(X-M(X))k
Следствия:
Центральный момент первого порядка равен нулю:
μ1=(X-M(X))1=M(X)-M(M(X))=M(X)-M(X)=0
Центральный момент второго порядка равен дисперсии:
μ2=(X-M(X))2=D(X)
D(X)=M(X2)-(M(X))2=ν2-ν12
Характеристики формы распределения:
Одно из характеристик служит коэфициет ассиметрии β1:

Основные распределения непрерывной случайной величины
Математическое ожидание непрерывной случайной величины:
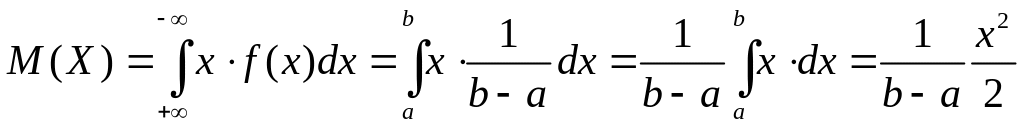 +РИС5
+РИС5
Дисперсия равномерно-распределенной случайной величины
![]()
Пример:
X: время ожидание автобуса
M(X)=?; σ=?
b-a=5; b=5; a=0
M(X)=(5+0)/2=2,5
![]()
Рис 6
Локальная теорема Лапласа
При больших n вероятность того, что из n независимых испытаний событие A произойдет ровно k раз приближенно равна:
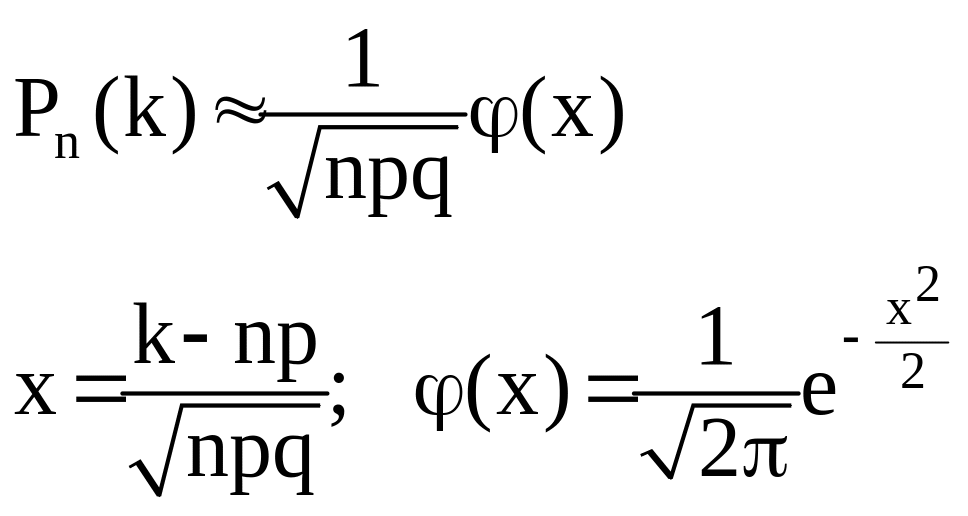
Пример:
Монету бросают 100 раз. Какова вероятность того, что при этом герб выпадет ровно 50 раз?
Hbc1
Интегральная теорема Лапласа
При больших n вероятность того, что из n независимых испытаний событие A произойдет от k1 до k2 раз приближенно равна:
![]()
![]()