

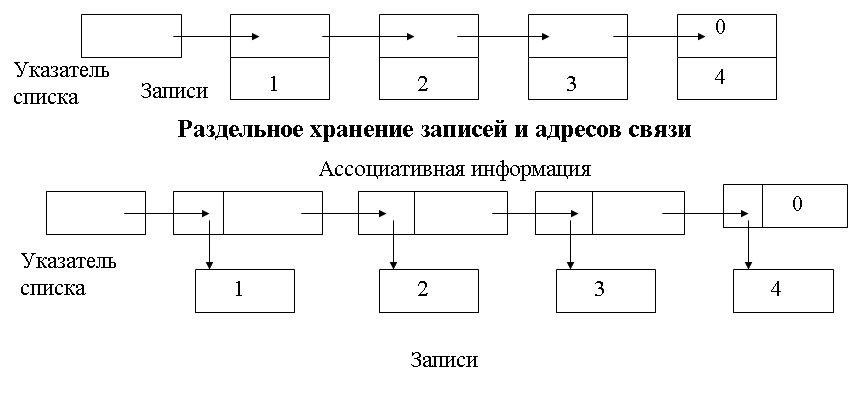
Варианты списковой организации данных Совместное хранение записей и адресов связи
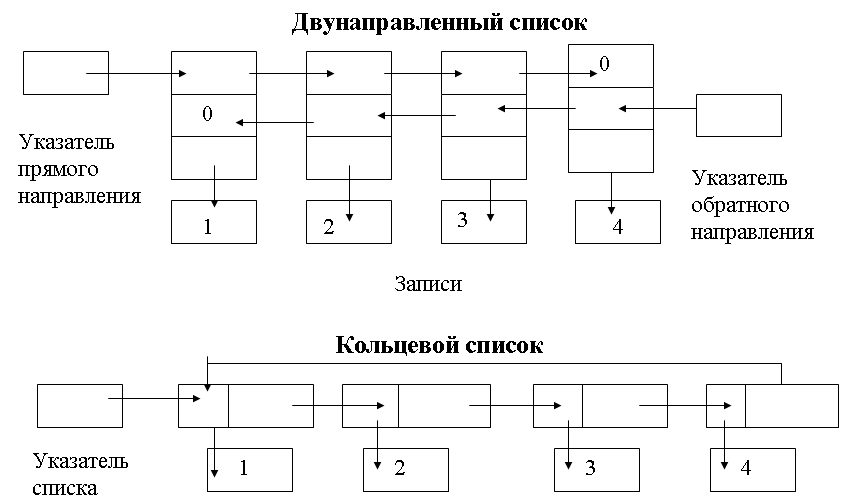
Древовидная организация данных
Древовидной организацией данных (деревом) называется множество записей, расположенных по уровнях следующим образом:
На первом уровне расположена только одна запись (корень дерева),
К любой записи i–того уровня ведет адрес связи только от одной записи уровня i-1.
Ранг – количество уровней в дереве.
Группа – совокупность записей в дереве, которые адресуются об общей записи (i-1) –го уровня,
Порядок дерева – максимальной число элементов в группе,
Звено связи – набор адресов связи, принадлежащих одной записи.
Определение. В упорядоченном бинарном дереве значение ключевого атрибута каждой записи должно быть больше, чем значение ключа у любой записи на ее левой ветви, и не меньше, чем ключ любой записи на ее правой ветви.
Это определение позволяет различать правые и левые адреса (ветви).
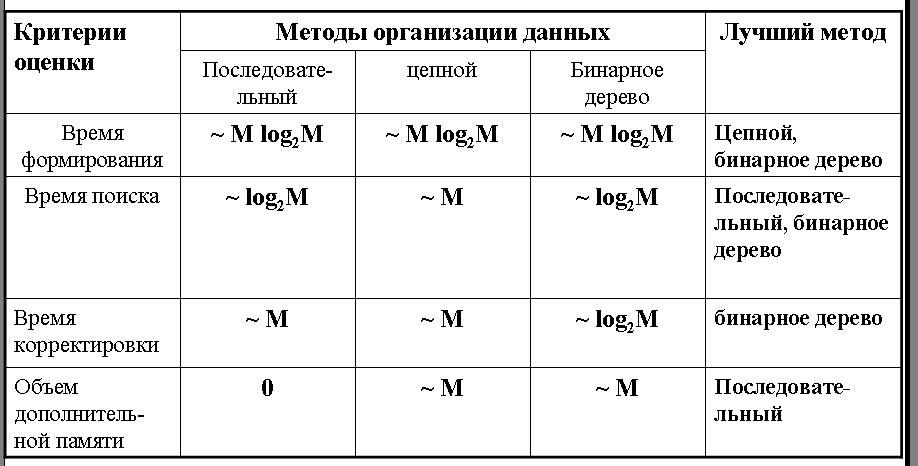
Сравнение методов организации данных
Методы ускорения доступа к данным.
Достигается:
Применением новых методов размещения и поиска информации (специальная расстановка записей, алгоритмы сортировки, вычисление местоположения записи).
Созданием массивов вспомогательной информации о хранимых данных (метаданных).
Методы рандомизации.
Используется адресная функция (рандомизирующая функция или хэш-функция) вида:
i = f(p),
i –номер (адрес) записи,
p – значение ключевого атрибута в записи.
Требования к адресной функции:
Аналитическое задание и быстрое вычисление .
Приближенная переработка произвольно распределенных ключевых атрибутов в равномерно распределенные номера записей.
Число записей-синонимов (которые имеют одинаковое значение i для значений р разных записей ) должно составлять не более 10-20 % от общего числа записей.
Простейшая адресная функция вида:
i = p- а.
Пример. Массив с набором значений ключевых атрибутов – 13, 11, 14, 15, 18, 14,16. Организовать размещение в памяти в соответствии с адресной функцией i = p- а
Решение. Максимальное значение ключа в массиве р макс равно 18, а минимальное значение р мин – 11.
Тогда а = р мин – 1 = 10. необходимый участок памяти для размещения массива равен р макс – а = р макс -р мин + 1= 8
Поэтому первый ключ 13 помещается в (13 -10) = 3 номер , 11 – в (11-10) = 1 номер, и т. д. С помощью адресов связи извлекаются все синонимы.
Недостаток: большой объем неиспользуемой памяти, если (рмакс – рмин) >>M.
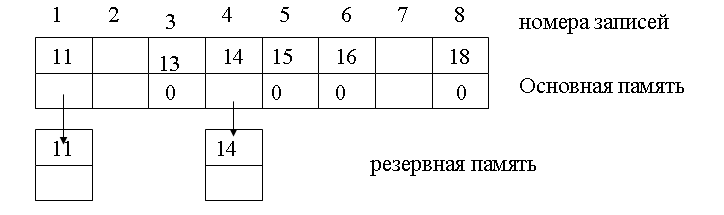
Адресная функция вида: i = ОСТ (p/m), m –целое число.
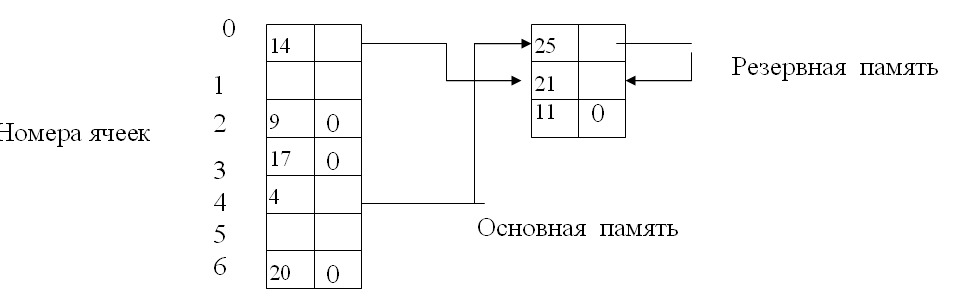
Пример. Массив с набором значений ключевых атрибутов – 17, 9, 4, 25, 21, 20,11. Организовать размещение в памяти в соответствии с адресной функцией i = ОСТ (p/m),
Решение. Так как число записей М=8, выбираем m = 7 (или 19). Выделяется два участка памяти: основная и резервная.
Последовательные номера записи, согласно адресной функции, составляют
ОСТ (17/7) = 3 номер, ОСТ (9/7) = 2 номер, ОСТ (4/7) = 4 номер и т. д. Если позиция номера занята, то значение ключа помещается в резервную память.
Дополнительная информация – массив индексов.
Разновидности индексов:
сплошная индексация (инвертированный массив ключевых атрибутов),
Последовательно-индексный массив (с арифметической прогрессией по шагу d>1),
Рандомизированный индексный массив (с приближенной арифметической прогрессией).
Организация данных во внешней памяти ЭВМ.
Организация доступа к файлу на диске:
Последовательный доступ – к концу файла.
При индексном виде доступа последовательный файл снабжается индексом. Выделяются три области памяти – первичная, индексная и переполнения.
Типичная организация индексно-произвольного доступа соответствует В-дереву.
При прямом доступе к файлу используется адресная функция i = p- а.
На выбор организации влияет количество записей, обрабатываемых в процессе реализации. Резервная память блока должна составлять 10 -15 % от общей памяти.
Доля выборки – это отношение числа требуемых при выборке записей файла к общему числу записей в файле.

Формула для расчета числа блоков (по технической документации СУБД):
S = M×L / B,
S – число блоков,
M – число записей,
L – длина записей в байтах,
B – размер блока в байтах.
Используется оптимальное вторичное индексирование.
Рассмотренные вопросы лекции:
1.Анализ алгоритмов и структур данных.
2.Методы ускорения доступа к данным.
3.Организация данных во внешней памяти ЭВМ.
Практические работы:
Построение структур размещения данных.
Построение алгоритмов поиска и доступа к данным.