

Типы распределенных баз данных
Есть несколько типов распределенных баз данных. На рисунке 2 а изображена нераспределенная база данных, состоящая из четырех частей – W, X, Y и Z. Все эти сегмента расположены в одном и том же месте, и дублирование данных отсутствует.
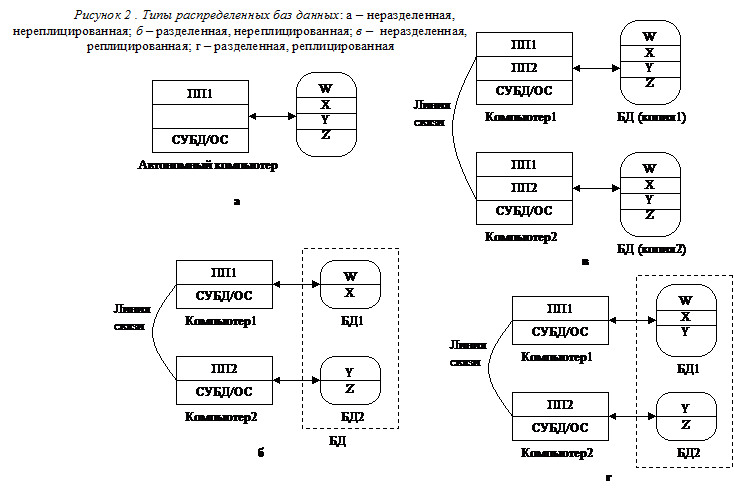
На рисунках 2 б–г изображены распределенные базы данных. На рисунке 2 б изображен первый тип распределенной базы данных, где база дан¬ных расположена на двух компьютерах – сегменты W и X хранятся на компью¬тере 1, а сегменты Y и Z – на компьютере 2. На рисунке 2 в вся база данных про¬дублирована (реплицирована) на двух компьютерах. На рисунке 2г база данных разделена, а ее сегмент Y продублирован. По отношению к разделению баз данных иногда употребляются два терми¬на. Вертикальным разделом или вертикальным фрагментом называется таблица, разделенная на две или более совокупности столбцов. Например, таблица R (С1, С2, СЗ, С4) может быть разделена на два вертикальных фрагмента: Р1 (С1, С2) и Р2 (СЗ, С4). В зависимости от приложения и от причины, по которой производится разделение, ключ отношения R, скорее всего, будет помещен в отношение Р2, которое примет вид Р2 (С1, СЗ, С4). Горизонтальный раздел или горизонтальный фрагмент – это фрагмент таблицы, представляющий собой совокупность строк. Например, если первые 1000 строк отношения R помещаются в отношение R1 (О, С2, СЗ, С4), а оставшиеся строки помещаются в отношение R2 (С1, С2, СЗ, С4), то отношения R1 и R2 образуют два горизонтальных фрагмента. Иногда база данных разбивается и на горизонтальные, и на вертикальные разделы, и результат такого разделения называется смешанным разделом. Разделы базы данных хранятся на двух или более компьютерах, а неразделенная база данных целиком дублируется на двух или более компьютерах. Наибольшим недостатком распределения является сложность управления и обусловленная этим потенциальная опасность потери целостности данных. Рассмотрим архитектуру базы данных на рисунке 2 г. Пользователь, сидящий за компьютером 1, может читать и обновлять элемент данных раздела Y, расположенный на компьютере 1, одновременно с тем, как этот же элемент раздела Y, расположенный на компьютере 2, будет читаться и обновляться пользователем, сидящим за компьютером 2.
Методы распределенной обработки (примеры, если он спросит)
В разных СУБД применяются различные способы распределенной обработки. В Oracle и SQL Server поддержка распределенной обработки осуществляется сходным образом, но одни и те же вещи называются по-разному, и наоборот – разные вещи имеют одинаковые названия. У других производителей также имеется своя терминология. Здесь мы сосредоточимся на основных идеях. Простейшим способом обработки распределенной базы данных является за¬грузка данных только для чтения. В этом случае обновлением всех данных в базе занимается только один компьютер, но копии данных только для чтения могут посылаться на множество (возможно, тысячи) компьютеров. В Oracle такие копии, предназначенные только для чтения, называются материализованными представлениями. В SQL Server эти копии называются моментальными снимками. При более сложном способе распределенной обработки запросы на обновление данных могут приходить со множества компьютеров, но на обработку они передаются одному специализированному компьютеру. Например, компьютер А может быть определен как единственный компьютер, который может обновлять таблицу СОТРУДНИК (и основанные на ней представления), а компьютер Б может быть определен как единственный компьютер, которому разрешено обновлять таблицу КЛИЕНТ (и ее представления). Время от времени обновления должны передаваться обратно на все компьютеры в распределенной сети, и базы данных должны синхронизироваться. Наиболее сложный способ заключается в том, чтобы разрешить множественное обновление одних и тех же данных в различных местах. В этом случае могут возникнуть три вида конфликтов распределенных обновлений). Во-первых, может быть нарушена уникальность. В базе данных галереи View Ridge два разных компьютера могут создать в таблице ROW строку с одинаковыми значениями столбцов Copy, Title и ArtistlD. Другая возможность напоминает проблему потерянного обновления: на двух компьютерах может обновляться одна и та же строка. Третий конфликт возникает в ситуации, когда на одном компьютере обновляется строка, удаленная на другом компьютере. Для разрешения конфликтов обновлений выделяется специальный компьютер. Он следит за всеми обновлениями, и возникающие конфликты разрешаются либо собственными средствами СУБД, либо приложениями, подобно тому, как это делается в триггерах. В самых крайних случаях делается запись о конфликте в журнале, и он разрешается вручную. Последний способ не рекомендуется, поскольку до устранения конфликта множество строк в работающих базах данных могут зависнуть в неопределенном положении, что приведет к неприемлемому снижению пропускной способности информационной системы предприятия. Ни один из этих способов не решает проблемы обеспечения атомарности транзакций в распределенной базе данных. Эта проблема становится особенно важной, если имеется вероятность конфликтов обновлений. В какой момент работу с базой данных можно считать выполненной? Если во время разрешения конфликта распределенных обновлений должен произойти откат обновлений, то потенциально возможно, что распределенная транзакция не будет выполнена в течение нескольких часов или даже суток. Ясно, что такая задержка неприемлема. Если оставить в стороне конфликты распределенных обновлений, остается еще один сложный вопрос — координация распределенных транзакций. Чтобы транзакция была атомарной, ни одно обновление в распределенной транзакции не должно быть сохранено, пока не будут сохранены все действия транзакции. Это означает, что каждый компьютер должен записать свои обновления условно и ожидать от диспетчера распределенных транзакций уведомления о том, что действия всех остальных компьютеров также записаны. Для этой цели используется алгоритм, называемый двухфазной фиксацией.
Билет №4
Графическое оформление выходных отчетов. Использование генераторов форм.
Создание таблиц, диаграмм, графиков, презентаций
Методы нормализации обобщенной внешней модели.
Обобщенная внешняя модель содержит данные о территориальном размещении информации. Топология РБД представляет географическое распределение локальных БД и отражает возможность обмена информацией между ними.
Структура обобщенной внешней модели, как и структура внешних моделей предметных областей пользователей, является инвариантной по отношению к структурам, реализуемым конкретным СУБД.
Характеристики обобщенной внешней модели РБД должны поддерживаться и контролироваться системой управления РБД и локальной СУБД и учитываться в процессе проектирования РБД для получения заданных характеристик функционирования корпоративных АИУС.
На основании характеристик обобщенной внешней модели определяются характеристики канонической структуры РБД.
В результате нормализации обобщенной внешней модели строится каноническая структура РБД. Каноническая структура РБД является составляющей логического уровня распределенного банка данных, которая обеспечивает универсальный интерфейс между различными локальными СУБД, между системой управления РБД и пользователем.
Этап нормализации информации обобщенной внешней модели РБД заканчивается формированием структурированной матрицы смежности А и соответствующего ей орграфа GC ( DC, Яс), который не содержит дублируемых групповых элементов и избыточных взаимосвязей между ними. Граф GC ( DC, Яс) представляет собой каноническую структуру РБД.
Построение канонической структуры обобщенной внешней модели РБД осуществляется с использованием операции наложения канонической структуры Gfc, заключающейся в совмещении идентичных групповых информационных элементов. Совмещение осуществляется независимо от уровня размещения групповых информационных элементов в канонической структуре Gk - Исключение составляют группы первого уровня иерархии ( точки входа), которые могут совмещаться только с идентичными точками входа.
Для обеспечения возможности использования информации обобщенной внешней модели на последующих уровнях представления ( логическом и физическом) и для упрощения процесса синтеза логической структуры РБД информационные элементы и их взаимосвязи в обобщенной внешней модели упорядочиваются по уровням иерархии. Упорядочение элементов d G DT осуществляется на основе рассмотренной в разделе 2.8.2 процедуры упорядочения групп данных по уровням иерархии.
БИЛЕТ №5.