

33. Двохфакторний дисперсійний аналіз без повторень в пакеті аналізу Msexcel.
Пакет аналізу включає в себе три засоби дисперсійного аналізу. Вибірконкретного інструменту визначається числом факторів і числом вибірок вдосліджуваної сукупності даних.
однофакторний дисперсійний аналіз - однофакторний дисперсійний аналізвикористовується для перевірки гіпотези про подібність середніх значень двох абобільш вибірок, що належать одній і тій же генеральної сукупності. Цейметод поширюється також на тести для двох середніх (до якихвідноситься, наприклад, t-критерій).
Двохфакторну дисперсійний аналіз з повторенням - Являє собоюбільш складний варіант однофакторного аналізу, що включає більше ніж однувибірку для кожної групи даних.
Двохфакторну дисперсійний аналіз без повторення - Являє собоюдвохфакторну аналіз дисперсії, що не включає більше однієї вибірки нагрупу. Використовується для перевірки гіпотези про те, що середні значення двохабо декількох вибірок однакові (вибірки належать одній і тій жегенеральної сукупності). Цей метод поширюється також на тести длядвох середніх, такі як t-критерій.
Кореляційний аналіз
Використовується для кількісної оцінки взаємозв'язку двох наборів даних,представлених у безрозмірному вигляді. Коефіцієнт кореляції вибіркиявляє собою коваріації двох наборів даних, поділену на твірїх стандартних відхилень. Кореляційний аналіз дає можливість встановити, чи асоційовані набориданих по величині, тобто, великі значення з одного набору данихпов'язані з великими значеннями іншого набору (позитивна кореляція),або, навпаки, малі значення одного набору пов'язані з великими значеннямиіншого (негативна кореляція), або дані двох діапазонів ніяк непов'язані (кореляція близька до нуля).
коваріаційного аналіз
34. Кореляція і коваріація в пакеті аналізу Msexcel.
Корреляционный анализ
Используется для количественной оценки взаимосвязи двух наборов данных,
представленных в безразмерном виде. Коэффициент корреляции выборки
представляет собой ковариацию двух наборов данных, деленную на произведение
их стандартных отклонений.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы
данных по величине, то есть, большие значения из одного набора данных связаны
с большими значениями другого набора (положительная корреляция), или,
наоборот, малые значения одного набора связаны с большими значениями другого
(отрицательная корреляция), или данные двух диапазонов никак не связаны
(корреляция близка к нулю).
Ковариационный анализ
Используется для вычисления среднего произведения отклонений точек данных от
относительных средних. Ковариация является мерой связи между двумя
диапазонами данных.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы
данных по величине, то есть, большие значения из одного набора данных связаны
с большими значениями другого набора (положительная ковариация), или,
наоборот, малые значения одного набора связаны с большими значениями другого
(отрицательная ковариация), или данные двух диапазонов никак не связаны
(ковариация близка к нулю).
35. Регресія в пакеті аналізу Msexcel.
Регресійний аналіз
Лінійний регресійний аналіз заключається в підборі графіку для набору спостереженнь за допомогою методу найменших квадратів. Регресія використовується для аналізу дії на залежну змінну однієї або кількох незалежних змінних. В загальному графік можна побудувати тільки в тому випадку коли в нас є тільки одна незалежна змінна. Ситуація значно ускладнюється у випадку двох та більшої кількості незалежних змінних.
Для регресійного аналізу в MS Excel є пакет аналізу: <Сервис>, <Анализ данных>, <Регрессия>:
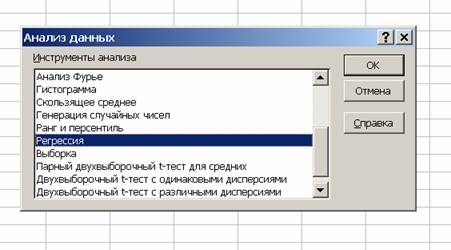
(Якщо данного пункту немає, то : <Сервис>,<Надстройки...>, поставити галочку на пункті „ Пакет Анализа”, [OK]. Почекайте з півхвилини поки MS Excel подумає, в меню повинен з’явитись пункт „Анализ данных”).
Нажимаємо [Enter]. З’являється діалогове вікно регресійного аналізу (Опис пунктів):

Перед тим як проводити регресійний аналіз необхідно відповідним чином підготувати наші дані. Розглянемо приклад: f(X,Y) задає поверхню в трьохвимірному прсторі. Маємо експериментальні точки:
|
Y |
||||
X |
|
1 |
2 |
3 |
4 |
1 |
0.5 |
0.8 |
1.5 |
1.7 |
|
2 |
0.7 |
1.3 |
1.6 |
1.4 |
|
3 |
1.0 |
1.1 |
1.2 |
0.8 |
|
4 |
0.7 |
0.9 |
0.6 |
0.4 |
|
Так як вхідні діапазони повинні складатись із стовпчиків, то набираємо дані відповідним чином: Вихідні дані
Тепер, як ми вияснили на попередніх заняттях (Частина IV), найкраща відповідність одержується при використанні поліному максимального ступеня. Через чотири точки (по кожній координаті) можна провести поліном третього ступеня, відповідно модель з урахуванням всіх можливих коефіцієнтів буде мати вигляд:
![]()
Підготуємо матрицю даних для регресійного аналізу: Матриця даних 1
Потім <Сервис>, <Анализ данных>, <Регрессия>, вводимо інтервали для f(X,Y) (Входной интервал Y), матриці даних (Входной интервал X), включаючи в діапазони заголовки (поставити галочку на „Метки”). „Параметры вывода” — Вказуємо „Новый рабочий лист», де для зручності вписуємо рівняння моделі — x3+x2y+xy2+y3+x2+xy+y2+x+y+b, [OK]:
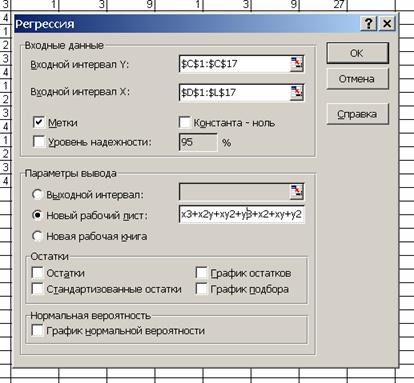
Після того як комп’ютер трошки подумає (при повідомленнях про помилки сміливо нажимайте [OK]) з’являється новий робочий лист зрезультатами регресійного аналізу (якщо написи в клітинках не поміщаються, збільшіть ширину відповідних стовпчиків): Модель 1
На
даному листі дається значення
коефіцієнтів R2,
результати дисперсійного аналізу та
регресійного аналізу (значення
коефіцієнтів, похибка для кожного
коефіцієнта, t-статистика,
ймовірність та довірчі інтервали). При
визначенні значимості коефіцієнтів є
важливою величина t-критерію
( t-статистика).
Якщо ![]() (a—
рівень недостовірності, n —
кількість ступенів свободи, знаходиться
серед результатів дисперсійного аналізу,
в графі „Остаток”):
(a—
рівень недостовірності, n —
кількість ступенів свободи, знаходиться
серед результатів дисперсійного аналізу,
в графі „Остаток”):

то
коефіцієнт значимо не відрізняється
від 0 і його можна викинути з моделі. В
нашому випадку ![]()
![]() . t-критерій для
всіх коефіцієнтів менше коефіцієнта
Стьюдента, тому з моделі відкидаємо
член з найменшим (по модулю)
значенням t-критерію
— це коефіцієнт, пов’язаний із
значенням Y.
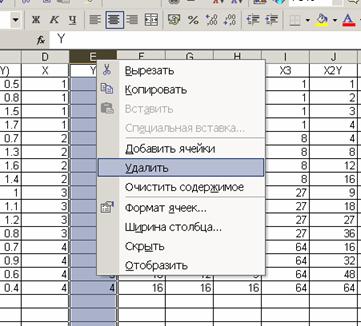
Для цього потрібно з матриці вихідних
даних видалити стовпчик Y:
(виділяємо цілий стовпчик, правою мишкою
викликаємо контекстне меню, „Удалить”)
. t-критерій для
всіх коефіцієнтів менше коефіцієнта
Стьюдента, тому з моделі відкидаємо
член з найменшим (по модулю)
значенням t-критерію
— це коефіцієнт, пов’язаний із
значенням Y.
Для цього потрібно з матриці вихідних
даних видалити стовпчик Y:
(виділяємо цілий стовпчик, правою мишкою
викликаємо контекстне меню, „Удалить”)
Тепер наступна модель у нас буде:
![]()
Переходимо на лист з вихідними даними (якщо не перейшли), Потім <Сервис>, <Анализ данных>, <Регрессия>, вводимо інтервали для f(X,Y) (Входной интервал Y), матриці даних (Входной интервал X, вона в нас вже буде менше), включаючи в діапазони заголовки (поставити галочку на „Метки”). „Параметры вывода” — Вказуємо „Новый рабочий лист», де для зручності вписуємо рівняння моделі — x3+x2y+xy2+y3+x2+xy+y2+x+b, [OK]:
36. Ковзаюче середнє і експоненціальне згладжування в пакеті аналізу Msexcel.
Метод згладжування - це спосіб, що забезпечує швидке реагу-вання розроблювального прогнозу на всі події, що відбуваються про-тягом періоду довжини базової лінії. Методи, що ґрунтуються нарегресії, такі як функції ТЕНДЕНЦІЯ й РІСТ, застосовують до всіхточок прогнозу ту саму формулу. Із цих дій досягнення швидкоїреакції на зрушення в рівні базової лінії значно утруднюються.Зглад-жування являє собою простий спосіб обійти дану проблему. Основ-на ідея методу згладжування полягає в тому, що кожен новий про-гноз виходить за допомогою переміщення попереднього прогнозу в Джерело:Лінійно-зважене ковзне середнє
У зваженому ковзному середньому останніми даними присвоюється більшу вагу, а більш раннім - менший. Виважена ковзне середнє розраховується шляхом множення кожної з цін закриття в розглянутому ряду на певний ваговий коефіцієнт. LWMA = SUM (CLOSE (i) * i, N) / SUM (i, N) (4) де SUM - сума; CLOSE (i) - поточна ціна закриття; SUM (i, N) - сума вагових коефіцієнтів; N - період згладжування. Як SMA може бути вибрано будь-яке з ковзних середніх. Ціни, відчуваючи коливання навколо свого закономірного руху, утворюють так званий канал зміни цін. Ширина каналу цін визначається їх мінливістю. Простий (і найстарший) з таких індикаторів, що визначають мінливість цін - Канал цін (Price Channel Upper - PCU). Для побудови каналу цін у даному індикаторі розраховується просте ковзне середнє SMA і будується смуга навколо нього. Верхню межу смуги отримують, відступаючи від SMA вгору на величину, що розраховується як певний відсоток і від SMA, і нижню - відступаючи вниз на відсоток d від SMA. U = {1 + u / 100} * SMA (Р, n) і L = {1 - d / 100} * SMA (P, n), (5) де - U - верхня смуга каналу цін; - L - нижня смуга каналу цін; - U - встановлений трейдером відсоток відхилення верхньої смуги від ковзної середньої; - D - те саме для нижньої смуги; SMA (P, n) - змінна середня. Передбачається, що при вдалому виборі параметрів індикатора, побудований канал буде відповідати рівноважного стану ринку, і, отже, всі виходи ціни за його межі, повинні супроводжуватися її поверненням назад. Тому сигналом до купівлі або продажу є підйом або зниження поточної ціни за смугу. Параметрами, що підбираються користувачем, є період усереднення і ширина смуги зверху і знизу u v [4].
37. Аналіз Фур'є в пакеті аналізу Msexcel.
Аналіз Фур'є
Призначається для вирішення завдань у лінійних системах та аналізуперіодичних даних, використовуючи метод швидкого перетворення Фур'є (ШПФ). Ця процедура підтримує також зворотні перетворення, при цьому,інвертірованіе перетворених даних повертає вихідні дані.
Двухвиборочний F-тест для дисперсій
Двухвиборочний F-тест застосовується для порівняння дисперсій двох генеральнихсукупностей. Наприклад, F-тест можна використовувати для виявлення відмінності вдисперсія тимчасових характеристик, обчислених за двома вибірках.
Гістограма Використовується для обчислення вибіркових та інтегральних частот попаданняданих у вказані інтервали значень, при цьому, генеруються числавлучень для заданого діапазону клітинок. Наприклад, необхідно виявити типрозподілу успішності в групі з 20 студентів. Таблиця гістограмискладається з меж шкали оцінок та кількості студентів, рівень успішностіяких знаходиться між самою нижньою межею та поточної кордоном. Найбільшчасто повторюваний рівень є модою інтервалу даних.
Ковзаюче середня
Використовується для розрахунку значень у прогнозованому періоді на основісереднього значення змінної для вказаного числа попередніх періодів. Кожне прогнозоване значення засноване на формулі:
де
. N число попередніх періодів, що входять до ковзне середня
. Aj фактичне значення в момент часу j
. Fj прогнозоване значення в момент часу j
38. Статистична функція ZtЕСТ.
Повертає однобічне р-значення z-критерію.
Для заданого гіпотетичного середнього значення генеральної сукупності, x, функція Z.TEST повертає ймовірність того, що середнє значення вибірки буде більшим за середнє значення спостережень у наборі даних (масиві), тобто середнє значення досліджуваної вибірки.
Щоб переглянути способи використання функції Z.TEST у формулі для обчислення значення двобічної ймовірності, див. підрозділ «Примітки» нижче.