

27. Нелинейные модели регрессии и их линеаризация. Примеры нелинейных моделей регрессии.
Нелинейные модели можно разделить на 2 класса: нелинейные модели по переменным и нелинейные по оцениваемым параметром
Методы оценки параметров нелинейных моделей:
Метод линеаризации, когда путем замены переменных нелинейное уравнение приводится к линейному виду
Если не удается подобрать линеаризующее преобразование, то исп метод нелинейной оптимизации
Что касается модели 1 вида- всегда удается их линеаризовать ( модели по переменным ), а с моделями второго класса сложнее, в ряде случаев удается, когда нет то исп оптимизация
По переменным
![]()
Что можно предложить для преобразования: замена логарифмов на х1* и х2*
Следовательно модель в линейном виде будет выглядеть:
![]()
![]()
Линеаризуем по тому же принципу- заменяем корень и дробь на х1* и х2*
По параметрам
![]()
Чтобы линеаризовать, необходимо прологорифмировать
![]()
![]()
![]()
![]()
Параметры степенно модели явл коэффициентами эластичности (средне относительное изменение результативного признака, те в %)
Экспоненциальная
у=еб0+б1х1+б2х2+б3х3+Е
![]()
Гиперболическая
![]()
![]()
y*=b0+b1x1+b2X2+E
28. Линейная и степенная модели множественной регрессии: интерпритация параметров.
Построение модели множественной регрессии (или многофакторная модель) заключается в нахождении уравнения связи нескольких показателей у и х1, х2 и т.д. , т.е. определяется как повиляет изменение показателей хi на величину y.
Для построения модели множественной регрессии используют:
Линейное уравнение множественной регрессии для i-того наблюдения, β -
параметры наблюдений, n- число наблюдений, m- число факторов
линейную
модель
![]() +Е
+Е
степенную
![]()
29. Производственная Кобба-Дугласа. Эластичность объема производства.
Y=A*Kальфа*Lбэта
к-затраты капитала
L-затраты труда
lnY=LnA+альфаLnK+бэтаLnL+LnE
Y*=A*+альфаK*+ бэтаL*+E*
Эластичные объемы производства:
коэф эластичности – объем производства по затратам капитала.
![]()
Коэф эластичности по объема производства по затратам труда
фотка
при изменении затрат капитала на 1% объем производства изменится в среденем на альфа%
30. производственная Кобба-Дугласа. Эффект от масштаба производства.
Y=A*Kальфа*Lбэта
к-затраты капитала
L-затраты труда
lnY=LnA+альфаLnK+бэтаLnL+LnE
Y*=A*+альфаK*+ бэтаL*+E*
Эффект от масштаба производства:
возрастающий
α+ β>1, при увеличении К и L в несколько раз, объем производства увеличится в большее количество раз
постоянный
α+ β=1 , при увеличении К и L в несколько раз, объем производства увеличится во столько же раз
Убывающий эффект от масштаба производства
α+ β<1, , при увеличении К и L в несколько раз, объем производства увеличится в меньшее количество раз
31. модели с распределенным лагом. Интерпритация параметров. Средний лаг. Медиатнный лаг.
Модели с распределенным лагом – регрессионные модели содержащие не только текущие, но и лаговые значения.
Лаг – характеризует запаздывание воздействия на результат.
Лаговые переменные – временные ряды факторных признаков, сдвинутых на 1 или более временной период.
Модели с распределенными лагами делятся на:
![]()
2. с бесконечной величиной лага (та же формула, только b2x(2-1)+..+Et
б0-краткосрочный мультипликатор, характеризует среднее абсолютное изменение результативного признака при изменении фактора Хт в некий фиксированный период т (на одну единицу своего измерения)
, без учета воздействия лаговых значений фактора Х.
б- долгосрочный мультипликатор, рассчитывается как сумма этих коэффициентов (б=б0+б1+б2+бе, свободный слагаемый мы не суммируем), он показывает, среднее абсолютное изменение результативного признака, уже в долгосрочной перспективе t+l при изменении фактора Х на одну единицу своего измерения в период времени т
Рассчитываются как отдельные коэффициенты к долгосрочному мультипликатору (относительные коэффициенты модели)
![]()
Средний лаг модели:
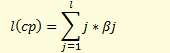
Средний лаг- характеризует средний период времени, в течение которого будет происходить изменение результата под воздействием изменения фактора. (то есть влияние фактора на результат)
![]()
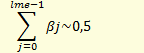
![]()
32. модели с распределенным лагом. Метод Алмона.
Модели с распределенным лагом – регрессионные модели содержащие не только текущие, но и лаговые значения.
Лаг – характеризует запаздывание воздействия на результат.
Лаговые переменные – временные ряды факторных признаков, сдвинутых на 1 или более временной период.
Модели с распределенными лагами делятся на:
2. с бесконечной величиной лага (та же формула, только b2x(2-1)+..+Et
Для модели с конечной величиной лага используется метод Алмон (полиномов)
yt= a + b0xt + b1xt-1 +b2xt-2 + ... + blxt-l + εt
Предполагается, что параметры модели полностью подчиняются
полиномиальному закону распределения
bj= c0 + c1j + c2j2
+ ... + ckj
k
(1)
yt= a + c0xt + (c0 + c1j + c2 + ... + ck)xt-1 + (c0 + 2c1j + 22c2 + 22ck)2k
ck*xt-1 + ... + (c0 + c1l
+ c2l2
+ ... + ckl2
)xt-1 + εt = a+ c0(x + xt-1 +xt-2 + ... + xt-l)[z0] + c1(xt-1 +2xt-2 + ... + lxt-l)[z1] +
c2(xt-1 +22
xt-2 + ... + l2
xt-l)[z2] + ck(xt-1 +2k
xt-2 + ... + l
k
xt-l)[z3] + εt
yt = a + c0z0 + c1z1 + c2z2 + ... + ckzk + εt (2)
где
![]() , i
= 1,…,k;
j=0,…,l. (3)
, i
= 1,…,k;
j=0,…,l. (3)
Алгоритм метода Алмона:
1) Определение величины лага (l)
2) Выбор порядка полинома (порядок полинома К≤L)
3) по соотношениям (3) рассчитываются значения переменнымх z1 (по формуле (3))
4) Определение коэффициентов ci уравнение (2) методом наим кв
5) По формулам (1) определяются коэффициенты bj
Билет 33. Модели с распределенным лагом. Метод Койка
Метод Койка: yt= a + b0xt + b1xt-1 +b2xt-2 + ... + εt В соответствии с методом ... представляет собой бесконечно убывающую геометрическую прогрессию bj =λσb0 0<λ<1
yt=a+b0xt +λb0xt-1 +λb0xt-2 +...+εt yt-1= a + b0xt-1 + λb1xt-2 + λ2b2xt-3 + ... + εt -1 | *λ [умножим 2е уровнение на λ и вычтем из 1] λyt-1= aλ + λb0xt-1 + λ2b1xt-2 + λ3b2xt-3 + ... + λεt-1 yt-λyt-1= a-aλ+ b0xt+εt-λεt-1 yt-= a(1-λ)+ yt-1+ b0xt+ut, где ut,=εt-λεt-1 Таким образом модель удалось привести к модели авторегрессии первого порядка.
Билет 37. В чем заключается цель адаптивных методов прогнозирования? Изложите алгоритм адаптивных методов прогнозирования АМП позоляют пепрерывно учитывать изменения в динамике изучаемого показателя (учитывтаь эволюцию тренда) Схема АМП: 1 этап: определяется прогнозное значение (ПЗ) для первого временного периода 2 этап: полученное ПЗ сравнивается с соответствующим фактическим значением для первого временного периода и определяется ошибка прогноза
3 этап: с учётом полученной ошибки прогноза пересчитываются коэффициенты модели 4 этап: определяется прогнозное значение для 2 временного периолда 5 этап: полученное ПЗ сравнивается с соответствующим фактическим значением 2 временного периода и определяется ошибка прогноза
6 этап: с учётом полученной ошибки прогноза пересчитыватся коэффициенты модели
| | | |H | | | | | | Быстроту реакции модели на изменение динамики изучаемого показателя характеризует параметр адаптации (обозначение:α, 0<α<1)
график
Билет 38. Адаптивные методы прогнозирования. Метод экспоненциального сглаживания
Адаптивные методы прогнозирования (АМП)
АМП позоляют пепрерывно учитывать изменения в динамике изучаемого показателя (учитывтаь эволюцию тренда) Схема АМП: 1 этап: определяется прогнозное значение (ПЗ) для первого временного периода 2 этап: полученное ПЗ сравнивается с соответствующим фактическим значением для первого временного периода и определяется ошибка прогноза
3 этап: с учётом полученной ошибки прогноза пересчитываются коэффициенты модели 4 этап: определяется прогнозное значение для 2 временного периолда 5 этап: полученное ПЗ сравнивается с соответствующим фактическим значением 2 временного периода и определяется ошибка прогноза
6 этап: с учётом полученной ошибки прогноза пересчитыватся коэффициенты модели
| | | |H | | | | | | Быстроту реакции модели на изменение динамики изучаемого показателя характеризует параметр адаптации (обозначение:α, 0<α<1)
график
1. Модель экспоненциального сглаживания (модел Брауна) Применяется для временных рядов без тенденций или с не ярко выраженной тенденцией Xt=a+εt! ! рисунок
эксоненциально-взвешенная скользящая средняя (эвсс) St=α*Xt+(1-α)St-1 - рекурентное соотношение. S0-? В качестве начального значения S0 берётся, как правило, или среднее значение всего ряда или среднее значене первой части ряда
Формула для прогноза: Xt*(τ)* - прогноз τ -‐‑ тау; ПЗ, определяемое в период времени t с периодом упреждения тау.
Период упреждения - тот период, на который прогнозируют (с декабря прогнозировать на январь, период упреждения = 1)
Xt*(τ) = St ПЗ не зависит от тау Схема расчёта ПЗ
Xt | ____|H α1S0
x1 |H S1=αx1+(1-α)*S0
x2 |H S2=αx2+(1-α)*S1
x3 |H Sn=αxn+(1-α)*Sn-1
.| . | S*n+1=x*n(1)=Sn
xn | S*n+3=x*n(3)=Sn
____|
*|
Xn+1 |
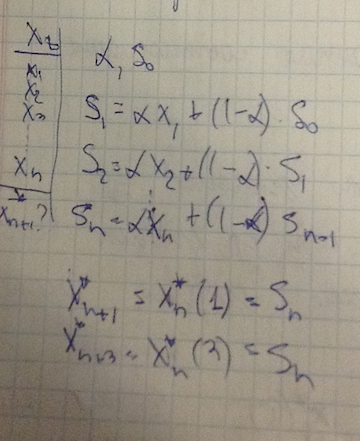
Покажем, что величина St зависит от ошибки прогноза St=α*Xt+(1-α)St-1=α*Xt+St-1-αSt-1=St-1+α(Xt-St-1) = St-1+α*et
HHHHHH⇓ H H H x*t-1(1) ПЗ на период времени t
Покажем, почему
St
называется эвсс |

1. Наличие St выражается через все уровни ряда
2. Чем больше степень β, тем меньше будет значение [по мере удаления в прошлое, информативность теряется/сокращается 3. Последовательность даёт экспоненту
Последовательность даёт экспоненту. Следовательно величина St является суммой всех уровней ряда, причём веса, с которых с эти уровни входят в сумму экспоненциально убывают по мере удаления в прошлое, следовательно St называется эвсс
Метод дисконтирования инф-ции. Инф-ция теряется по мере удаления в прошлое.
Адаптивные модели прогнозирования с учётом сезонности.
Модель Хольта-Уинтерса.
Эта модель помимо линейного тренда учитывает и сезонную составляющую. Прогноз x*(t;τ) на τ шагов по времени определяется формулой:
x*(t;τ)
=
![]() ,
,
где f(t) – коэффициент сезонности, а T – число временных тактов (фаз), содержащихся в полном сезонном цикле.
Видно, что в данной модели сезонность представлена мультипликативно. Формулы обновления коэффициентов имеют вид:
0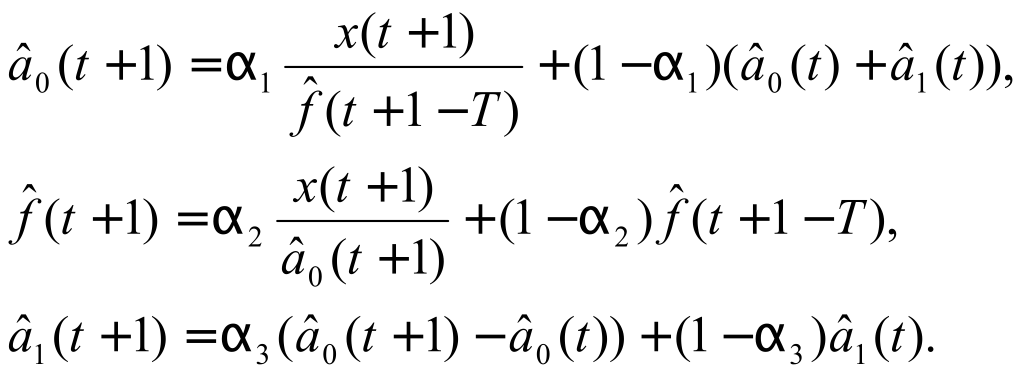 <α1,α2,α3<1
<α1,α2,α3<1
В качестве начальных значений ft берутся средние за одноимённые периоды значения частных от деления фактических данных нарасчётные, полученные по линейному ур-ю тренда
Модель Тейла-Вейджа.
Позволяет учитывать линейную тенденцию и аддитивную сезонность
x*(t;τ)
=
![]() .
.
g - аддитивный фактор сезонности
Коэффициенты вычисляются рекуррентным способом по формулам:

0<α1,α2,α3<1
Начальные значения g рассчитываются как средние за одноимённые периоды значения разностей между фактическими данными и расчётными, полученными по линейному ур-ю тренда
Билет 40. Адаптивные модели прогнозирования. Модель Брауна, модель Хольта
Адаптивные методы прогнозирования:
-позволяют непрерывно учитывать изменения динамики изучаемого показателя, т.е. учитывать эволюцию тренда
Схема адаптивных методов прогнозирования единая:
На первом шаге определяется прогнозное значение для 1-го временного периода
Полученное прогнозное значение сравнивается с соответств фактическим значением (для первого временного периода) и определяется ошибка прогноза. Из одного вычитаем др (График)-это и есть ошибка прогноза
С учетом полученной ошибки прогноза пересчитываются коэффициенты модели
Определяется прогнозное значение для второго временного периода
Сравнить эти значения, с соответсв фактическим (2 факт)
Быстроту реакции модели на изменение в динамике изучаемого показателя, характеризует параметр адаптации
Модель экспонен сглаживания
Модель Брауна- применяется только для временных рядов без тенденции или с неярко выраженной тенденцией
Xt=a+Et , на одном уровне (график)
![]()
![]()
части ряда.
Прогнозное значение, определяемое в период времени t с периодом упреждения Тау (тот период на который мы прогнозируем)
![]()
То есть прогнозное значение не зависит от Тау
То есть эта модель только применима в том случае, есть нет тенденций в рядам
Xt |
|
x1 |
|
x2 |
|
x3 |
... |
... |
... |
xn |
|
X*n+1 (найти) |
Берем формулу для прогнозирования |
|
x*n+1=X*n(1)=Sn |
|
x*n+3=X*n(3)=Sn |
Покажем, что величина St зависит от ошибки прогноза.
![]()
![]()
![]()
Почему величина St так называется- экспоненциально взвешенная скользящая средняя
![]()
![]()
![]()
![]()
Теряется информационная ценность данных
….
В качестве начальных значениях берутся оценки параметров линейного уравнения тренда изучаемого показателя.
…
Показать что в модели Хольта значения а0 и а1
Модель Хольта. Позволяет учитывать тенденции линейного тренда
В модели Хольта введено два параметра сглаживания α1 и α 2 (0< α 1, α 2 <1). Прогноз x*(t;l) на l шагов по времени определяется формулой:
x*(t;
τ) =
![]() ,
,
в качестве начальных значений берутся оценки параметров линейного уравнения тренда изучаемого показателя
а пересчет коэффициентов
![]() осуществляется по формулам:
осуществляется по формулам:
![]()
Билет 41. Виды систем линейных уравнений. Структурная и преведения формы модели
Возможна система независимых уравнений, когда каждая зависимая переменная (y) рассматривается как функция одного и того же набора объясняющих факторов (x1, х2,…,хm):
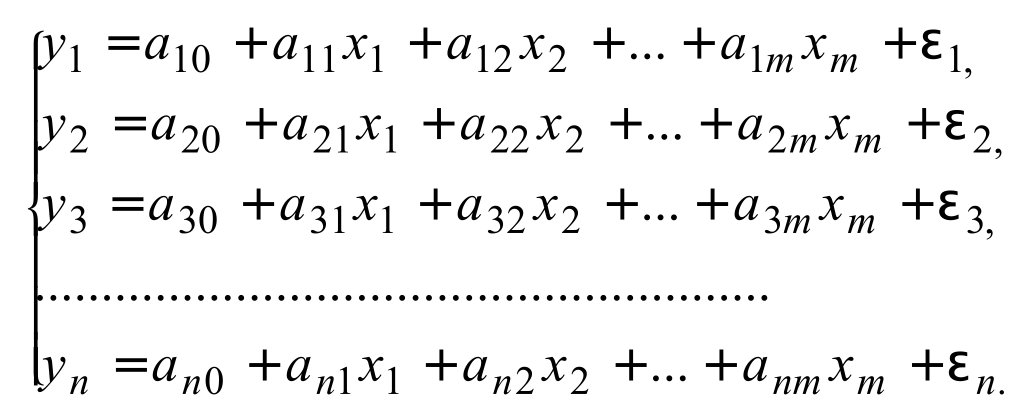
Каждое уравнение такой системы может рассматриваться самостоятельно, а для нахождения его параметров применяется метод наименьших квадратов.
Если зависимая переменная y одного уравнения выступает в виде фактора x в другом уравнении, то можно построить модель в виде системы рекурсивных уравнений:
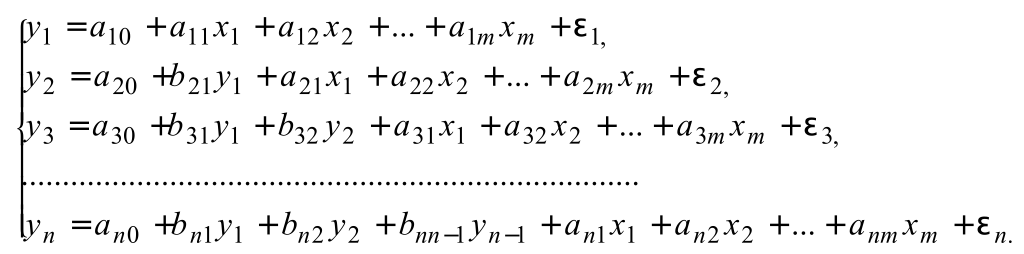
В ур-и для зависимых переменных в правую часть могут входить зависимые переменные только из предыдущих уравнений системы. такую систему можно решать по цепочке (1ое - через МНК)
Каждое уравнение такой системы также может рассматриваться самостоятельно, а его параметры оцениваются методом наименьших квадратов.
В системе линейных одновременных уравнений одни и те же переменные (y) одновременно рассматриваются как зависимые в одних уравнениях и независимые в других. Такая система уравнений называется структурной формой модели. Каждое уравнение в системе одновременных уравнений не может рассматриваться самостоятельно, поэтому метод наименьших квадратов для оценки параметров неприменим.
В общем случае структурная форма модели имеет вид:

нельзя рассматривать независимо.
Зависимые переменные, число которых равно числу уравнений в системе, называются эндогенными переменными и обозначаются y.
Предопределенные переменные, влияющие на эндогенные переменные, но не зависящие от них, называются экзогенными переменными и обозначаются x.
Примером системы одновременных уравнений является модель спроса и предложения, когда объем спроса на товар (Qd) определяется его ценой (P) и доходом потребителя (I), объем предложения (Qs) – его ценой (P) и достигается равновесие между спросом и предложением:
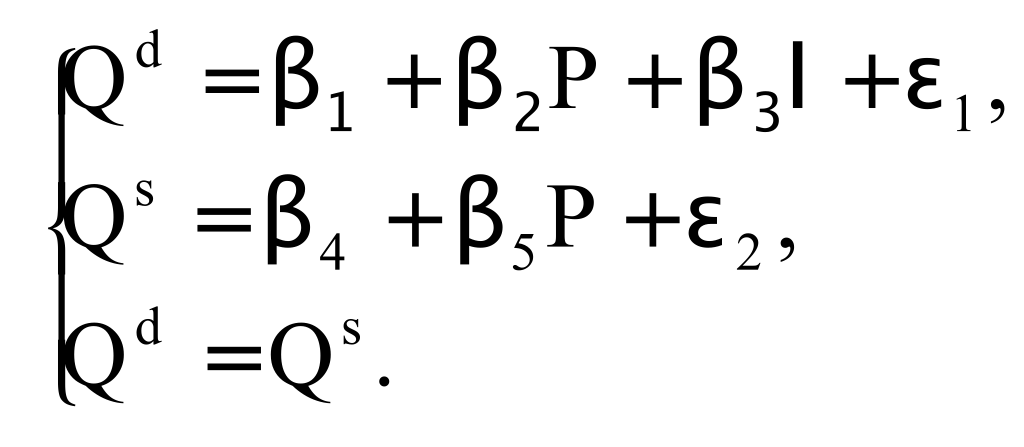
Переменные Qd, Qs, и P формируют свои значения внутри модели, согласно уравнениям системы, и таким образом, являются эндогенными переменными. Переменная I полагается заданной, ее значения формируются вне модели, и она является экзогенной.
Использование МНК для оценивания структурных коэффициентов модели дает смещенные и несостоятельные оценки. Поэтому для определения структурных коэффициентов модель преобразуется в приведенную форму модели.
Приведенная форма модели представляет систему линейных функций эндогенных переменных от экзогенных:
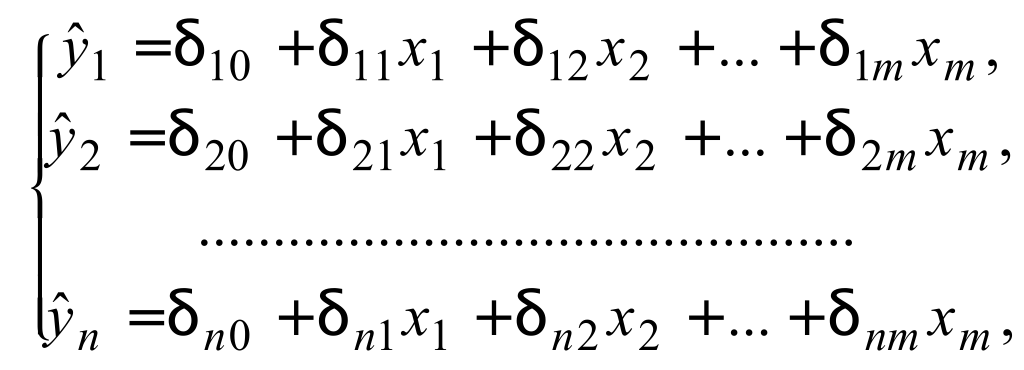
где δij – коэффициенты приведенной формы модели.
При переходе от приведенной формы модели к структурной приходится сталкиваться с проблемой идентифицируемости модели. Идентифицируемость – это единственность соответствия между приведенной и структурной формами модели.
Билет 42. Проблема идентифицируемости модели. Необходимое и достаточное условия условие идентифицируемости
Проблема идентифицируемости - это возможность получения однозначно определенных структурных коэф по известным приведенным коэф.
С позиции индефицируемости системы одновременных уравнений делятся на три вида:
Индентифицируемый - когда удается однозначным образом определить структурные коэф по известным приведенным. (как правило число структурных коэф= числу приведенных)
Сверх идентифицируемая система, когда для какого-то структурного параметра сущ несколько способов расчета. В этом случае число структурных коэф меньше числа приведенных
Неидентифицируемая система- когда невозможно определить 1 или несколько параметров структурной модели (как правило число струк коэф больше числа приведенных)
Для проверки модели на идентифицируемость необходимо каждое уравнение системы проверить по необходимому и достаточному условиям идентиф-мости
Тождества на идентиф-ость не применяются!!! (они изначально счит иден-емыми)
Необходимые условия иденфиц-мости:
Для проверки рассчитываются 2 вспомогательные величины:
-Д- это число экзогенных переменных, входящих в систему, но отсут в проверяемом уравнении
-Н-это число эндогенных переменных, присутствующих в проверяемом уравнении
После этого проверяем уравнения: Д+1=Н то уравнение иден-емое
Д+1 меньше Н то уравнение неид
Д+1 больше Н то уравнение - свериден
Достаточное ур-ние иден-ости - уравнение иденф, если по отсутствующим в нем переменным как эндогенным так и экзогенным можно из коэф при них в др уравнениях системы составить матрицу, определитель которой отличен от нуля, а ранг не меньше числа эндогенных переменных минус 1.
После чего можно сделать вывод по эндогенности системы в целом.
Он делается с учетом следующих правил: 1. система в целом иденф, если индеф все входящие в нее уравнения
Если хотя бы одно из уравнений системы неиденф то и вся система в целом- неиденфицируема
Билет 43. Проблема идентифицируемости модели. Суть косвенного метода МНК
Косвенный метод наименьших квадратов (КМНК)- используется только для иденфиц систем.
Суть, схема:
Записывается приведенная форма модели
Обычным МНК оцениваются приведенные коэф
Приведенные коэф преобразуются в структурные параметры
Билет 44.проблема идентифицируемости модели. Пошаговый МНК
Пошаговый метод наименьших квадратов (ДМНК)- применяется для сверидентиф систем. Для иденф систем ДМНК дает тот же эффект что и косвенный метод.
Схема:
Записывается приведенная форма модели
Обычным МНК оцениваются приведенные коэф
Выявляет энтогенные переменные, стоящ в правой части сверхидентиф уравнения
По соотв приведенным уравнениям, определяются расчетные значения эндогенных переменных, стоящ в правой части сверидентиф уравнения.
Обычным методом наименьших квадратов оцениваются параметры сверидентиф уравнения, используя в качестве исходных данных фактич значения экзогенных переменных и расчетные значения эндогенных переменных, стоящих в правой части сверхидентиф уравнения