

Компьютерный практикум по статистике
.pdf
|
|
b |
|
|
|
0,04 |
|
|
0,04 |
|
|
||
b =1- P χ2n−1 |
> c2α;n−1 |
0 |
|
=1- P χ502 |
> c0,05;502 |
|
|
=1- P χ502 |
> 67,50 |
|
|
= |
|
b1 |
0,045 |
0,045 |
|||||||||||
|
|
|
|
|
|
|
|
|
|
||||
=1 – 0,16 = 0,84.
5.По данным за последние n = 12 месяцев найдена средняя доходность по некоторой акции x = 65% и соответствующее выборочное среднее квадратичное отклонение ˆs = 7%. Считая, что доходность акции распределе-
на по нормальному закону, требуется проверить на уровне значимости
α= 0,05 гипотезы о том, что в генеральной совокупности средняя доходность
равна a0 = 60%, а дисперсия равна b0 = 50(%)2, и определить вероятности не-
правильных выводов.
Решение. Проверим на 5%-ном уровне значимости гипотезу Н0: а = = а0 = 60% при альтернативной гипотезе Н1: а ¹ а0.
Поскольку модуль наблюдаемого значения статистики
|
= |
( |
|
|
- a0) |
n |
|
|
= |
|
|
( |
|
- a0) |
n -1 |
|
T − |
X |
X |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
ˆs |
||||||
n 1 |
|
|
|
|
s |
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
оказался равен |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
(65 - 60) |
11 |
|
= 2,37, |
|
|
|||||||||
|
|
|
7 |
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
а критическая точка t0,05;11 = 2,20, есть основания отвергнуть нулевую гипо-
тезу на 5%-ном уровне значимости (при этом возможно с вероятностью 0,05 допустить ошибку первого рода).
Теперь на 5%-ном уровне значимости проверим гипотезу Н0: s2 = b0 = 50 при альтернативной гипотезе Н1: s2 = b1 ¹ b0.
Наблюдаемое значение статистики
χ2n−1 = (n -1)s2 = nˆs2 , b0 b0
равное
12×49 =11,76 ,
50
попадает в интервал между нижней критической точкой c12−0,05/2;11 = 3,82 и верхней критической точкой c20,05/2;11 = 21,92, поэтому на 5%-ном уровне зна-
чимости нет оснований отвергнуть нулевую гипотезу. При этом вероят-
ность ошибки второго рода (при b = 72 |
= 49) равна |
|||||||
|
|
|
|
1 |
|
|
|
|
b = P χ2n−1 |
> c12−α/2;n−1 |
b0 |
- P χ2n−1 |
> c2α/2;n−1 |
b0 |
= 0,97 - 0,02 = 0,95. |
||
b1 |
b1 |
|||||||
|
|
|
|
|
|
|||
6. По данным за десять кварталов требуется проверить, имеется ли существенное различие между доходностями Q(1) и Q(2) двух акций:
41

q(1) |
|
−1,6 |
−0,2 |
−1,2 |
−0,1 |
3,4 |
3,7 |
0,8 |
0,0 |
2,0 |
0,7 |
||||||||||
i |
|
|
|
|
|
|
|
|
|
|
q(2) |
1,9 |
0,8 |
1,1 |
0,1 |
−0,1 |
4,4 |
5,5 |
1,6 |
4,6 |
3,4 |
i |
|
|
|
|
|
|
|
|
|
|
Решение. Рассчитаем выборочные средние и исправленные выборочные дисперсии доходностей двух акций:
q(1) = 0,75, s12 = 3,20, q(2) = 2,33, s22 = 4,01.
Будем исходить из предположения, что доходность акции распределена по нормальному закону. Прежде чем проверять гипотезу о равенстве генеральных средних доходностей акций, проверим гипотезу о равенстве генеральных дисперсий (при альтернативной гипотезе о том, что дисперсии не равны). Наблюдаемое значение статистики
= s2
Fn −1;n −1 2
2 1 s12
оказалось равно
4,0093,201 = 1,25,
что меньше критической точки fα/2; n2 −1; n1 −1 = f0,025;9;9 = 4,03, поэтому на 5%-ном
уровне значимости нет оснований отвергнуть гипотезу о равенстве генеральных дисперсий, что позволяет применить известную статистику для проверки гипотезы о равенстве генеральных средних (при альтернативной гипотезе о том, что генеральные средние не равны).
Модуль наблюдаемого значения статистики
Tn1+n2 |
|
|
= |
|
|
|
Q(1) |
- |
Q(2) |
|
|
|
|
|
|
|
|
|
, |
|||||
−2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
(n1 -1)s12 + (n2 -1)s22 |
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
1 |
+ |
1 |
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
n1 + n2 -2 |
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
n1 |
|
n2 |
||||||||||||
равный |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,75 - 2,33 |
|
|
|
|
|
|
|
|
=1,86, |
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
9×3,20 + 9×4,01 |
1 |
+ |
1 |
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
9 + |
|
|
9 |
9 |
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
9 - 2 |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
оказался меньше критической точки tα;n1 +n2 −2 = t0,05;16 = 2,12, поэтому на 5%-
ном уровне значимости можно принять гипотезу о равенстве генеральных средних доходностей двух различных акций; делаем вывод о несущественном различии доходностей акций.
Заметим, что на 10%-ном уровне значимости гипотеза о равенстве генеральных средних должна быть отвергнута, поскольку Tn1 +n2 −2 =1,86
больше критической точки t0,1;16 = 1,7459. Иными словами, если мы готовы
довольствоваться 90%-ной надежностью выводов, то можно признать, что доходности акций различаются, если же нам нужна надежность не менее
42

95%, то оснований утверждать, что между доходностями двух акций есть различия, у нас нет. Вычисляя P = P{ Tn1 +n2 −2 > 1,86} (например, с помощью
функции СТЬЮДРАСПОБР), получим, что P = P{ Tn1 +n2 −2 > 1,86} = 0,08 — это
число называется P-значением соответствующего критерия, оно равно вероятности ошибиться, отвергнув гипотезу H0.
Теперь проверим те же гипотезы с использованием средств надстройки «Анализ данных» пакета Microsoft Excel. Введем данные в рабочий лист, как
показано на рис. 3.3.2.
A B
1Q(1) Q(2)
2 |
0,7 |
1,9 |
||
3 |
|
–1,6 |
0,8 |
|
4 |
|
–0,2 |
1,1 |
|
5 |
|
–1,2 |
0,1 |
|
6 |
|
–0,1 |
– |
|
7 |
|
3,4 |
4,4 |
|
8 |
|
3,7 |
5,5 |
|
9 |
|
0,8 |
1,6 |
|
10 |
|
0,0 |
4,6 |
|
11 |
2,0 |
3,4 |
||
Рис. 3.3.2. Числовые данные для программ «Двухвыборочный F-тест для дисперсии»
и «Двухвыборочный t-тест с одинаковыми дисперсиями»
Воспользуемся программой «Двухвыборочный F-тест для дисперсии». Для этого выберем соответствующий пункт меню надстройки «Анализ данных». В появившемся окне ввода данных (рис. 3.3.3) укажем интервал переменной 1 B1:B11 и интервал переменной 2 A1:A11 (в которых находятся ис-
ходные данные — обратим внимание, что первой переменной должна быть та, которая обладает большей выборочной дисперсией, в данном случае Q(2) ). Отметим флажок «Метки», поскольку первые строки интервалов пе-
ременных содержат названия этих переменных.
Рис. 3.3.3. Окно ввода данных программы «Двухвыборочный F-тест для дисперсии»
43

Особенно отметим, что в случае проверки гипотезы H : DX(1) |
= DX(2) о |
|
0 |
|
|
равенстве генеральных дисперсий п р и а л ь т е р н а т и в н о й |
|
г и п о - |
т е з е H : DX(1) > DX(2), в поле «Альфа» нужно вводить уровень значимости |
||
1 |
|
|
гипотезы, а в случае, к о г д а а л ь т е р н а т и в н а я г и п о т е з а |
и м е - |
|
е т в и д H0: DX(1) ¹ DX(2), в поле «Альфа» следует вводить половину уровня значимости. В данном случае в поле «Альфа» введем a/2 = 0,025.
Укажем, что результаты работы программы необходимо вывести на новый рабочий лист. Результаты работы программы представлены на рис. 3.3.4.
Двухвыборочный F-тест для дисперсии
|
Q(2) |
Q(1) |
Среднее |
2,33 |
0,75 |
Дисперсия |
4,01 |
3,20 |
Наблюдения |
10 |
10 |
df |
9 |
9 |
F |
1,253 |
|
P(F<=f) одностороннее |
0,371 |
|
F критическое одностороннее |
4,026 |
|
Рис. 3.3.4. Результаты работы программы «Двухвыборочный F-тест для дисперсии»
Теперь воспользуемся программой «Двухвыборочный t-тест с одинаковыми дисперсиями». Для этого выберем соответствующий пункт меню надстройки «Анализ данных». В появившемся окне ввода данных (рис. 3.3.5) укажем интервал переменной 1 A1:A12 и интервал переменной 2 B1:B12 (в кото-
рых находятся исходные данные). Укажем гипотетическую среднюю разность, равную нулю, отметим флажок «Метки», поскольку первые строки ин-
тервалов переменных содержат названия этих переменных. Зададим уровень значимости «Альфа» (по условию a = 0,05). Укажем, что результаты работы программы необходимо вывести на новый рабочий лист. Результаты работы
программы представлены на рис. 3.3.6.
Рис. 3.3.5. Окно ввода данных программы «Двухвыборочный t-тест с одинаковыми дисперсиями»
44

Двухвыборочный t-тест с одинаковыми дисперсиями
|
Q(1) |
Q(2) |
Среднее |
0,75 |
2,33 |
Дисперсия |
3,20 |
4,01 |
Наблюдения |
10 |
10 |
Объединенная дисперсия |
3,60 |
|
Гипотетическая разность средних |
0 |
|
df |
18 |
|
t-статистика |
–1,86 |
|
P(T<=t) одностороннее |
0,04 |
|
t критическое одностороннее |
1,73 |
|
P(T<=t) двухстороннее |
0,08 |
|
t критическое двухстороннее |
2,10 |
|
Рис. 3.3.6. Результаты работы программы «Двухвыборочный t-тест с одинаковыми дисперсиями»
Замечаем, что результаты компьютерных и ручных вычислений совпали (интерпретация результатов работы программ «Двухвыборочный F- тест для дисперсии» и «Двухвыборочный t-тест с одинаковыми дисперсиями»
очевидна).
В общем случае гипотезу H0: MX(1) = MX(2) (при неизвестных, но одинако-
вых дисперсиях) можно проверять, основываясь на рассчитанном уровне значимости (P-значении), т. е. на вероятности того, что статистика Tn1 +n2 −2
окажется больше модуля наблюдаемого числового значения этой статистики («P(T <= t) одностороннее»), которая используется при проверке гипотезы H0 при односторонних альтернативных гипотезах) или вероятности того, что модуль статистики Tn1 +n2 −2 окажется больше наблюдаемого числового
значения этой статистики («P(T <= t) двустороннее»), которая используется при проверке гипотезы H0 при двусторонней альтернативе).
Если соответствующее типу альтернативной гипотезы P-значение оказывается не меньше принятого уровня значимости α, то гипотезу H0 следует отвергнуть.
3.4. П а р н а я к о р р е л я ц и я и р е г р е с с и я
Исследуется связь между расходами дилеров некоторой компании на рекламу продукции (X, тыс. ден. ед.) и их объемами продаж (Y, млн. ден. ед.) и зависимость объема продаж Y от величины расходов на рекламу X. Сведения
по 60 случайно отобранным дилерам сгруппированы в корреляционную таблицу (табл. 3.4.1).
1. а) Данные об объемах продаж сгруппируем по пяти интервалам вложенных в рекламу средств и введем в рабочий лист Microsoft Excel,
отождествив каждый интервал с его серединой (рис. 3.4.1).
Воспользуемся программой «Однофакторный дисперсионный анализ». Для этого выберем соответствующий пункт меню надстройки «Анализ данных». В появившемся окне ввода данных (рис. 3.4.2) укажем входной интервал A1:E26, в
который мы ввели исходные данные (с заголовками столбцов — серединами
45

интервалов X, поэтому отметим флажок «Метки в первой строке»). Зададим уровень значимости «Альфа» (по условию α = 0,05). Укажем, что данные сгруппированы по столбцам, а результаты работы программы необходимо вывести на новый рабочий лист. Результаты работы программы представлены на рис. 3.4.3.
|
|
|
|
|
|
Т а б л и ц а |
3.4.1 |
|
X |
|
|
[0,05;1,40) |
[1,40;2,75) |
[2,75;4,10) |
[4,10;5,45) |
[5,45;6,80) |
|
Y |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
x |
0,725 |
2,075 |
3,425 |
4,775 |
6,125 |
ny |
|
y |
|
||||||
|
|
|
|
|
|
|
|
|
[0,00; 0,26) |
0,13 |
|
6 |
1 |
1 |
|
|
8 |
[0,26; 0,52) |
0,39 |
5 |
|
|
|
5 |
|
2 |
|
|
|
12 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
[0,52; 0,78) |
0,65 |
3 |
|
|
|
13 |
|
1 |
|
|
|
17 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
[0,78; 1,04) |
0,91 |
|
|
|
|
|
6 |
|
5 |
4 |
2 |
17 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
[1,04; 1,30) |
1,17 |
|
|
|
|
|
|
|
|
|
|
|
|
3 |
3 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
nx |
14 |
|
|
|
25 |
|
9 |
7 |
5 |
60 |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A |
|
|
B |
C |
|
D |
|
E |
|
|
|
|
|
|
|
1 |
0,725 |
|
2,075 |
3,425 |
4,7756,125 |
|
|
|
||||||
|
|
|
2 |
0,13 |
|
0,13 |
0,13 |
0,91 |
|
0,91 |
|
|
|
||||
|
|
|
3 |
0,13 |
|
0,39 |
0,39 |
0,91 |
|
0,91 |
|
|
|
||||
|
|
|
4 |
0,13 |
|
0,39 |
0,39 |
0,91 |
|
1,17 |
|
|
|
||||
|
|
|
5 |
0,13 |
|
0,39 |
0,65 |
0,91 |
|
1,17 |
|
|
|
||||
|
|
|
6 |
0,13 |
|
0,39 |
0,91 |
1,17 |
|
1,17 |
|
|
|
||||
|
|
|
7 |
0,13 |
|
0,39 |
0,91 |
1,17 |
|
|
|
|
|
||||
|
|
|
8 |
0,39 |
|
0,65 |
0,91 |
1,17 |
|
|
|
|
|
||||
|
|
|
9 |
0,39 |
|
0,65 |
0,91 |
|
|
|
|
|
|
|
|||
|
|
|
10 |
0,39 |
|
0,65 |
0,91 |
|
|
|
|
|
|
|
|||
|
|
|
11 |
0,39 |
|
0,65 |
|
|
|
|
|
|
|
|
|||
|
|
|
|
0,39 |
|
0,65 |
|
|
|
|
|
|
|
|
|||
|
|
|
12 |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
0,65 |
|
0,65 |
|
|
|
|
|
|
|
|
|||
|
|
|
13 |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
14 |
0,65 |
|
0,65 |
|
|
|
|
|
|
|
|
|||
|
|
|
|
0,65 |
|
0,65 |
|
|
|
|
|
|
|
|
|||
|
|
|
15 |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
16 |
|
|
|
|
0,65 |
|
|
|
|
|
|
|
|
|
|
|
|
17 |
|
|
|
|
0,65 |
|
|
|
|
|
|
|
|
|
|
|
|
18 |
|
|
|
|
0,65 |
|
|
|
|
|
|
|
|
|
|
|
|
19 |
|
|
|
|
0,65 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,65 |
|
|
|
|
|
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
0,91 |
|
|
|
|
|
|
|
|
|
|
|
|
21 |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
22 |
|
|
|
|
0,91 |
|
|
|
|
|
|
|
|
|
|
|
|
23 |
|
|
|
|
0,91 |
|
|
|
|
|
|
|
|
|
|
|
|
24 |
|
|
|
|
0,91 |
|
|
|
|
|
|
|
|
|
|
|
|
25 |
|
|
|
|
0,91 |
|
|
|
|
|
|
|
|
|
|
|
|
26 |
|
|
|
|
0,91 |
|
|
|
|
|
|
|
|
|
|
Рис. 3.4.1. Числовые данные для программы |
|
|
||||||||||||||
|
«Однофакторный дисперсионный анализ» |
|
|
||||||||||||||
Групповые средние |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
∑ynxy |
|
|
|
|
||||
|
|
|
|
|
|
′ |
= |
y |
|
|
— |
|
|
|
|
||
|
|
|
|
y |
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
x |
|
|
|
nx |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
средние объемы продаж для каждого интервала вложенных средств (nxy — количество наблюдений (X; Y), у которых x принадлежит интервалу X, а y принадлежит интервалу Y) рассчитаны программой («Средние»). Построим на
46

рис. 3.4.4 поле корреляции — прямоугольную сетку, в каждом прямоугольнике которой проставляется nxy точек. Здесь же построим линию групповых средних, т. е. ломаную, отрезки которой соединяют точки с координатами (x′; yx′).
Рис. 3.4.2. Окно ввода данных программы «Однофакторный дисперсионный анализ»
|
|
Однофакторный дисперсионный анализ |
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ИТОГИ |
|
|
|
|
|
|
|
|
|
|
|
|
|
Группы |
|
Счет |
Сумма |
|
Среднее |
Дисперсия |
|
|
|
|
|
|
|
0,725 |
|
14 |
4,68 |
|
0,334 |
0,0435 |
|
|
|
|
|
|
|
2,075 |
|
25 |
15,99 |
|
0,640 |
0,0421 |
|
|
|
|
|
|
|
3,425 |
|
9 |
6,11 |
|
0,679 |
0,0920 |
|
|
|
|
|
|
|
4,775 |
|
7 |
7,15 |
|
1,021 |
0,0193 |
|
|
|
|
|
|
|
6,125 |
|
5 |
5,33 |
|
1,066 |
0,0203 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Дисперсионный анализ |
|
|
|
|
|
|
|
|
|
||
|
|
Источник вариации |
|
SS |
df |
|
MS |
F |
|
P-значение |
F критическое |
|
|
|
|
|
|
|
|
|
|
|
|
2E– |
|
|
|
|
|
Между группами |
|
3,24 |
4 |
|
0,81 |
17,73 |
|
09 |
|
2,54 |
|
|
|
Внутри групп |
|
2,51 |
55 |
|
0,05 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Итого |
|
5,74 |
59 |
|
|
|
|
|
|
|
|
|
|
Рис. 3.4.3. Результаты работы программы |
|
|
|||||||||
|
|
«Однофакторный дисперсионный анализ» |
|
|
|||||||||
б) |
Используя |
|
с л у ч а й н у ю |
м о д е л ь о д н о ф а к т о р н о г о |
|||||||||
д и с п е р с и о н н о г о а н а л и з а: |
|
|
|
|
|
|
|||||||
|
|
Y(i) = θ(0) + θ(i) + ε(i); |
i = 1, 2, 3, 4, 5; |
k = 1, 2,…, n |
, |
|
|||||||
|
|
k |
|
|
k |
|
|
|
|
i |
|
|
|
где θ(i) |
= N(0; σθ ), εk(i) |
= N(0; σост ), проверим гипотезу H0: σθ = 0 об отсутствии |
|||||||||||
влияния интервала вложенных в рекламу средств на объем продаж. Расшифровка дисперсионной таблицы, полученной с помощью про-
граммы «Однофакторный дисперсионный анализ», представлена в табл. 3.4.2.
47
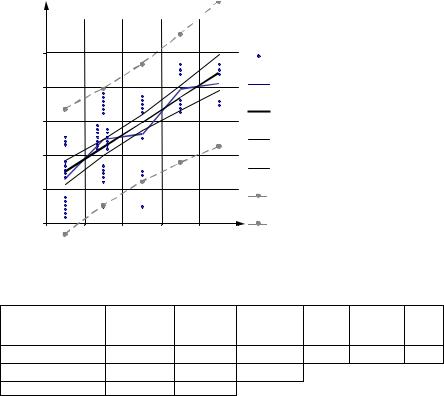
Y |
|
|
|
|
|
|
|
|
|
|
|
1,3 |
|
|
|
|
|
|
Поле корреляции |
|
|
||
|
|
|
|
|
|
|
|
|
|||
1,04 |
|
|
|
|
|
|
Линия групповых средних |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Линия регрессии |
|
|
||
0,78 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Верхняя граница |
|
|
||
0,52 |
|
|
|
|
|
|
интервального прогноза M(Y|x) |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Нижняя граница |
|
|
||
|
|
|
|
|
|
|
интервального прогноза M(Y|x) |
|
|||
0,26 |
|
|
|
|
|
|
Верхняя граница |
|
|
||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
x |
интервального прогноза Y|x |
|
|||
|
|
|
|
|
|
Нижняя граница |
|
|
|||
0 |
|
|
|
|
|
|
|
|
|||
0,05 |
1,40 |
2,75 |
4,10 |
5,45 |
6,80 |
интервального прогноза Y|x |
|
||||
Рис. 3.4.4. Поле корреляции, линии групповых средних, регрессии, |
|
||||||||||
|
интервальный прогноз групповых средних |
|
|
||||||||
|
|
|
|
|
|
|
|
|
Т а б л и ц а |
3.4.2 |
|
Источник вариации |
Показатель |
Число степе- |
Оценка дис- |
Fν−1; n−ν = |
|
|
|||||
|
|
|
|
|
2 |
|
|
||||
результативного |
вариации (SS) |
ней свободы |
персии σост |
2 |
2 |
P-значение fα; ν −1; n−ν |
|||||
признака Y |
|
|
|
(df) |
|
|
(MS) |
= sX |
/sост |
|
|
Расходы на рекламу X |
SSX =3,24 |
ν – 1= 4 |
|
|
sX2 =0,81 |
17,73 |
0,000000002 |
2,54 |
|||
Остаточные факторы |
SSост= 2,51 |
n – ν = 55 |
|
|
sост2 =0,05 |
|
|
|
|
||
Общая вариация |
|
SS = 5,74 |
n – 1 = 59 |
|
|
|
|
|
|
|
|
Проверка гипотезы H0 производится на основе анализа статистики Fν−1; n−ν = s2X /sост2 , имеющей (в предположении справедливости H0) распреде-
ление Фишера — Снедекора с ν – 1 = 4 и n – ν = 55 степенями свободы (здесь ν = 5 — число интервалов x). В данном случае наблюдаемое значение
этой статистики оказалось равным 17,73 [в результатах работы программы (рис. 3.4.3, табл. 3.4.2) оно приводится в таблице «Дисперсионный анализ» в
столбце «F»], а критическая точка f0,05; 4; 55 = 2,54 (F критическое), откуда следует, что гипотеза H0 об отсутствии влияния вложений в рекламу на объем
продаж отвергается на 5%-ном уровне значимости.
Гипотезу H0 можно проверить и так: если P-значение оказывается не меньше принятого уровня значимости α (в данном случае α = 0,05), гипотезу H0 принимают, а если P-значение оказывается меньше α, гипотезу H0 отвергают. В данном случае P-значение равно P = P{F4; 55 > 2,54} = 0,000000002 [оно
приводится в результатах работы программы (рис. 3.4.3, табл. 3.4.2)], значит, гипотезу H0 следует отвергнуть на 5%-ном уровне значимости.
в) Оценим влияние величины расходов на рекламу на объем продаж
2 |
SSX |
|
3,24 |
|
с помощью коэффициента детерминации ˆρ (Y | X) = |
|
= |
|
= 0,56 — |
SS |
5,74 |
|||
|
итог |
|
|
|
48 |
|
|
|
|

такова (56%) доля общей вариации (дисперсии, разброса, различий) объема продаж Y, обусловленная влиянием на него расходов на рекламу X. Корре-
ляционное отношение ˆr(Y | X) = ˆr2(Y | X) = 0,75.
Нетрудно убедиться в том, что
ˆˆ |
|
|
|
|
|
ˆ |
( |
ˆ |
) |
|
||||||
2 |
2 |
(Y |
| |
X), |
|
|
|
2 |
|
2 |
|
, |
||||
SSX = nsYr |
SSост = nsY |
1- r (Y | X) |
||||||||||||||
а статистика |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
sX |
|
|
|
|
ˆ |
|
|
|
|
|
|
|
|
|
|
|
|
= |
|
|
r |
(Y | X) (n -1) |
|
. |
|
|
|||||
|
|
2 |
|
( |
|
2 |
|
) |
|
|
|
|
|
|||
|
sост |
ˆ |
(n |
- n) |
|
|
||||||||||
|
|
1- r |
(Y | X) |
|
|
|
||||||||||
2. а) Наблюдения, сгруппированные в табл. 3.4.1, представим в обычной форме: пару (0,725; 0,13) выпишем 6 раз, пару (0,725; 0,39) — 5 раз и т. д. Введем эти данные в рабочий лист Microsoft Excel (рис. 3.4.5).
|
A |
B |
1 |
X |
Y |
2 |
0,725 |
0,1 |
3 |
0,725 |
0,1 |
4 |
0,725 |
0,1 |
5 |
0,725 |
0,1 |
6 |
0,725 |
0,1 |
7 |
0,725 |
0,1 |
8 |
0,725 |
0,3 |
9 |
0,725 |
0,3 |
10 |
0,725 |
0,3 |
11 |
0,725 |
0,3 |
12 |
0,725 |
0,3 |
13 |
0,725 |
0,6 |
14 |
0,725 |
0,6 |
15 |
0,725 |
0,6 |
16 |
2,075 |
0,1 |
17 |
2,075 |
0,3 |
18 |
2,075 |
0,3 |
19 |
2,075 |
0,3 |
20 |
2,075 |
0,3 |
21 |
2,075 |
0,3 |
22 |
2,075 |
0,6 |
23 |
|
|
Рис. 3.4.5. Числовые данные для программ «Корреляция» и «Регрессия»
Воспользуемся программой «Корреляция». Для этого выберем соответствующий пункт меню надстройки «Анализ данных». В появившемся окне ввода данных (рис. 3.4.6) укажем входной интервал A1:B61, в который мы ввели
исходные данные (с заголовками столбцов — названиями признаков, поэтому отметим флажок «Метки в первой строке»). Укажем, что данные сгруппированы по столбцам, а результаты работы программы необходимо вывести на новый рабочий лист. Результаты работы программы представлены на рис. 3.4.7.
В результате работы этой программы рассчитана оценка ˆr(X; Y) = 0,72 коэффициента корреляции r(X, Y). Проверим на 5%-ном уровне значимости гипотезу H0: r(X, Y) = 0 при альтернативной гипотезе H1: r(X, Y) ¹ 0.
Наблюдаемое числовое значение статистики
49

Tn−2 = |
|
|
ˆr |
|
||
|
|
|
|
|||
2 |
|
|||||
|
|
|
|
|
(1−ˆr )/(n − 2) |
|
равно |
|
|
|
|
||
|
|
|
0,72 |
= 7,9 . |
||
|
|
|
|
|
|
|
|
|
(1− |
0,722)/58 |
|||
|
|
|
||||
Рис. 3.4.6. Окно ввода данных программы «Корреляция»
|
X |
|
Y |
X |
|
1 |
|
Y |
|
0,72 |
1 |
Рис. 3.4.7. Результаты работы программы «Корреляция»
При α = 0,05 значение критической точки tα; n−2 = t0,05;58 = 2,00. Поскольку |7,9| > t0,05; 99 , есть основания отвергнуть проверяемую гипотезу H0. При
2 |
2 |
= |
этом оценка коэффициента л и н е й н о й детерминации ˆr (X, Y) = 0,72 |
||
= 0,52 означает, что 52% общей вариации объема продаж Y обусловлены л и н е й н ы м влиянием на него расходов на рекламу X (сравним это значение с коэффициентом детерминации ˆρ2(Y | X) = 0,56 — долей вариации
объема продаж, связанной с влиянием расходов на рекламу). П о л о ж и - т е л ь н о е и б л и з к о е к е д и н и ц е значение оценки коэффициента корреляции означает, что наблюдается п о л о ж и т е л ь н а я и д о с т а - т о ч н о т е с н а я корреляционная связь между X и Y.
б) Предположив, что корреляционная зависимость Y от x линейна (функция регрессии Y на x линейна), оценим степень близости связи между Y и x к линейной функциональной.
М о д е л ь п а р н о г о л и н е й н о г о р е г р е с с и о н н о г о а н а - л и з а признака Y записывается следующим образом:
Yi = a0 + a1xi + εi ; i = 1, 2,…, n (n = 60) ,
где все случайные величины εi (случайные эффекты влияния на результатив-
ный признак неконтролируемых факторов) независимы и имеют одинаковое нормальное распределение εi = N(0;σELR ) или, иначе, все наблюдения Yi неза-
висимы и имеют нормальное распределение
50