

4.4.Анализ и моделирование связи между временными рядами.
При анализе связи между явлениями по уровням временных рядов необходимо учитывать возможность искажения его результатов за счет влияния так называемой ложной корреляции, которая может возникнуть из-за простого сопутствия во времени развития двух явлений. Яркий пример ложной корреляции привел в одной из своих работ английский статистик Д.Финни.
Он сравнил динамику зарегистрированных радиоприемников и число душевнобольных в послевоенной Англии и получил высокий коэффициент корреляции, хотя прямая связь здесь, конечно, отсутствует.
Сопутствие во времени может возникнуть из-за наличия во временных рядах автокорреляции.
Определение степени тесноты связи между уровнями временных рядов осуществляется путем исчисления линейного коэффициента корреляции.
Покажем его расчет на следующем примере:
Таблица 4.10. Динамика среднегодовой численности промышленно-производственного персонала в промышленности в Ростовской области, (тыс.чел.)
|
Годы |
Среднегодовая численность промышленно-производственного персонала в промышленности, Y |
в том числе: рабочие, X |
|
1993 |
569,7 |
462,6 |
|
1994 |
516,4 |
416,7 |
|
1995 |
472,0 |
384,5 |
|
1996 |
431,0 |
344,1 |
|
1997 |
395,8 |
316,2 |
|
1998 |
365,1 |
289,8 |
Определим степень тесноты связи между среднегодовой численностью рабочих и всего ППП в промышленности Ростовской области.
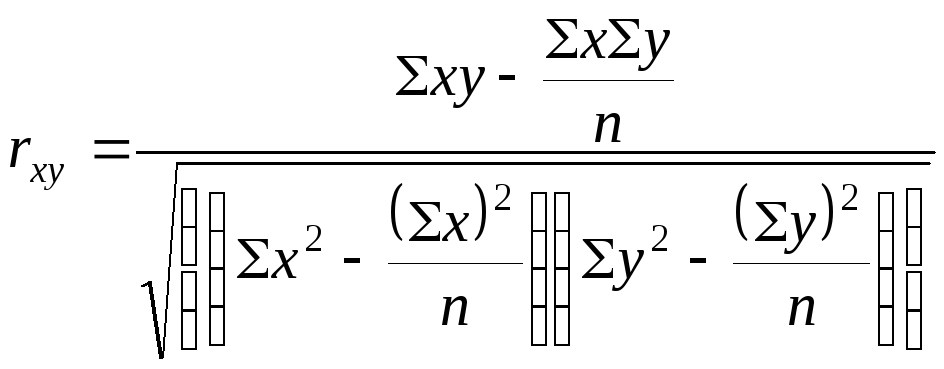
Заметим, что расчет может быть осуществлен и по другим формулам.
Промежуточные расчеты проведем в рабочей таблице.
|
Годы |
y |
x |
xy |
y2 |
x2 |
|
1993 |
569,70 |
462,60 |
263543,22 |
324558,09 |
213998,76 |
|
1994 |
516,40 |
416,70 |
215183,88 |
266668,96 |
173638,89 |
|
1995 |
472,00 |
384,50 |
181484,00 |
222784,00 |
147840,25 |
|
1996 |
431,00 |
344,10 |
148307,10 |
185761,00 |
118404,81 |
|
1997 |
395,80 |
316,20 |
125151,96 |
156657,64 |
99982,44 |
|
1998 |
365,10 |
289,80 |
105805,98 |
133298,01 |
83984,04 |
|
Суммы |
2750,00 |
2213,90 |
1039476,14 |
1289727,70 |
837849,19 |
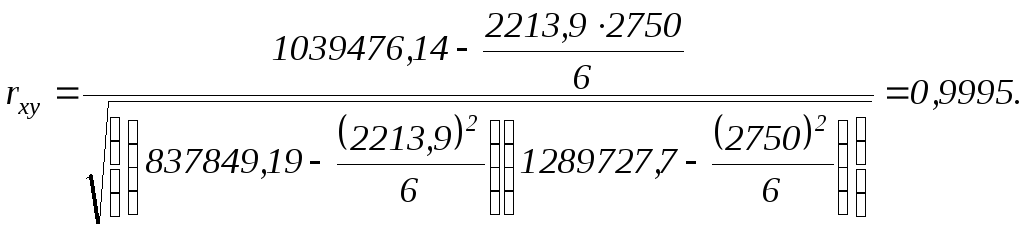
Близкое к единице значение коэффициента корреляции свидетельствует о тесной прямой (близкой к функциональной) связи между среднегодовой численностью рабочих и всего ППП в промышленности в Ростовской области.
Однако это может быть обусловлено автокорреляцией.
Прежде чем оценивать связь между показателями по рядам динамики, необходимо проверить каждый ряд на наличие автокорреляции.
Проверку временного ряда среднегодовой численности ППП в промышленности в Ростовской области мы осуществили в предидущих параграфах.
Опуская промежуточные расчеты приведем некоторые итоговые показатели анализа временного ряда среднегодовой численности рабочих.
-
коэффициент автокорреляции между
уровнями между текущими и непосредственно
предшествующими уровнями временного
ряда ![]() ;
;
-
коэффициент автокорреляции по остаткам
(в данном случае – по отклонениям от
линейного тренда)![]() ;
;
- критерий Дарбина-Уотсона DW = 1,53.
Так как DW > DWU (1,53>1,36), гипотеза об отсутствии автокорреляции принимается на уровне значимости α = 0,05.
Эту
же гипотезу подтверждает низкая величина
коэффициента автокорреляции в остатках
![]() .
.
Несмотря
на то, что судя по величине критерия
Дарбина-Уотсона, рассчитанного для
временного ряда численности всего ППП,
нельзя однозначно говорить об отсутствии
автокорреляции уровней этого временного
ряда, низкий коэффициент автокорреляции
в остатках
![]() подтверждает правомерность этой
гипотезы.
подтверждает правомерность этой
гипотезы.
Следовательно,
в данном примере, можно оценивать степень
тесноты связи между временными рядами.
Полученный ранее высокий коэффициент
корреляции между уровнями временных
рядов
![]() действительно объясняется зависимостью
между численностью рабочих и ППП.
действительно объясняется зависимостью
между численностью рабочих и ППП.
Исключение автокорреляции во временных рядах. Если между уровнями ряда существует автокорреляция, она должна быть устранена.
Есть несколько способов исключения автокорреляции в рядах динамики. К ним относятся: коррелирование отклонений от тренда и коррелирование последовательных разностей.
Коррелирование отклонений от тренда заключается в том, что коррелируются не сами уровни, а отклонения фактических уровней от выравненных, отражающих тренд, т.е. коррелируются остатки.
Для
этого каждый временной
ряд необходимо выравнять по определенной
характерной для него аналитической
формуле, (т.е. найти
![]() и
и
![]() ),
затем из эмпирических уровней вычесть
выравненные (т.е. найти остатки
ey
и
ex
) и
определить тесноту связи между ними:
),
затем из эмпирических уровней вычесть
выравненные (т.е. найти остатки
ey
и
ex
) и
определить тесноту связи между ними:
![]() .
.
Несмотря на то, что мы пришли к выводу об отсутствии автокорреляции между временными рядами среднегодовой численности ППП и рабочих в промышленности в Ростовской области, используем этот пример для иллюстрации рассматриваемого приема.
Выровняем оба рядя по уравнению прямой. Не приводя расчеты параметров, запишем уравнение тренда для каждого ряда при условии отсчета времени от середины ряда:
![]()
![]()
Рассчитаем
выравненные значения
![]() и
и
![]() ,
остатки
ey
и
ex
и определим степень тесноты связи между
ними. Промежуточные расчеты приведем
в таблице:
,
остатки
ey
и
ex
и определим степень тесноты связи между
ними. Промежуточные расчеты приведем
в таблице:
|
Годы |
ey |
ex |
exey |
(ey)2 |
(ex)2 |
|
1993 |
9,52 |
7,48 |
71,25 |
90,70 |
55,96 |
|
1994 |
-3,04 |
-3,96 |
12,05 |
9,24 |
15,72 |
|
1995 |
-6,70 |
-1,71 |
11,46 |
44,92 |
2,93 |
|
1996 |
-6,96 |
-7,66 |
53,32 |
48,51 |
58,62 |
|
1997 |
-1,43 |
-1,10 |
1,57 |
2,04 |
1,21 |
|
1998 |
8,61 |
6,95 |
59,86 |
74,12 |
48,34 |
|
Суммы |
0,00 |
0,00 |
209,51 |
269,52 |
182,78 |
![]() .
.
Как мы видим, коэффициент корреляции, рассчитанный по отклонениям от тренда, хотя и оказался близким к единице, все же меньше, чем коэффициент, рассчитанный по исходным уровням двух рядов. Это объясняется тем, что некоторая незначительная автокорреляция в рассматриваемых рядах все же есть, что и выявил рассчитанный нами показатель.
Другой причиной этого может выступать недостаточно удачно подобранное уравнение тренда.
Коррелирование последовательных разностей позволяет исключить влияние тренда при коррелировании временных рядов.
При использовании уравнения прямой определяют степень тесноты связи между первыми разностями, при изменении по параболе 2-го порядка — вторые разности, при изменении по параболе п-го порядка — п-е разности.
Формула расчета коэффициента корреляции по разностям имеет следующий вид:

Проиллюстрируем использование этого приема на нашем примере. Так как в обоих случаях выравнивание велось при помощи уравнения прямой, рассчитаем первые разности. Эти и последующие промежуточные расчеты приведем в рабочей таблице:
|
Годы |
Δy |
Δx |
ΔxΔy |
(Δy)2 |
(Δx)2 |
|
1994 |
-53,30 |
-45,90 |
2446,47 |
2840,89 |
2106,81 |
|
1995 |
-44,40 |
-32,20 |
1429,68 |
1971,36 |
1036,84 |
|
1996 |
-41,00 |
-40,40 |
1656,40 |
1681,00 |
1632,16 |
|
1997 |
-35,20 |
-27,90 |
982,08 |
1239,04 |
778,41 |
|
1998 |
-30,70 |
-26,40 |
810,48 |
942,49 |
696,96 |
|
Суммы |
-204,60 |
-172,80 |
7325,11 |
8674,78 |
6251,18 |
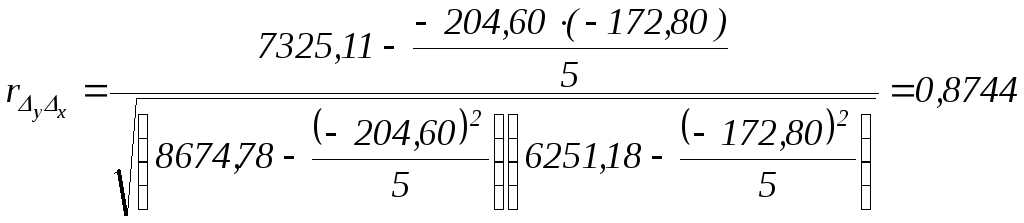 .
.
Оценивание степени тесноты связи по первым разностям привело к тем же выводам, что и расчет коэффициента корреляции по отклонениям от тренда, что подтверждает выводы, сделанные ранее. При этом меньшая величина коэффициента корреляции указывает на не вполне обоснованное использование линейной функции для выравнивания временных рядов.
Моделирование связи между явлениями по последовательным разностям и отклонениям от тренда.
Использование последовательных разностей отклонений от тренда позволяет не только оценить степень тесноты связи между рассматриваемыми признаками, но и построить уравнение зависимости между ними, исключив влияние тренда.
Параметры регрессионных уравнений рассчитываются по общим правилам, изложенным выше.
Используя уже имеющиеся промежуточные данные, рассчитаем параметры линейного уравнения регрессии по первым разностям:
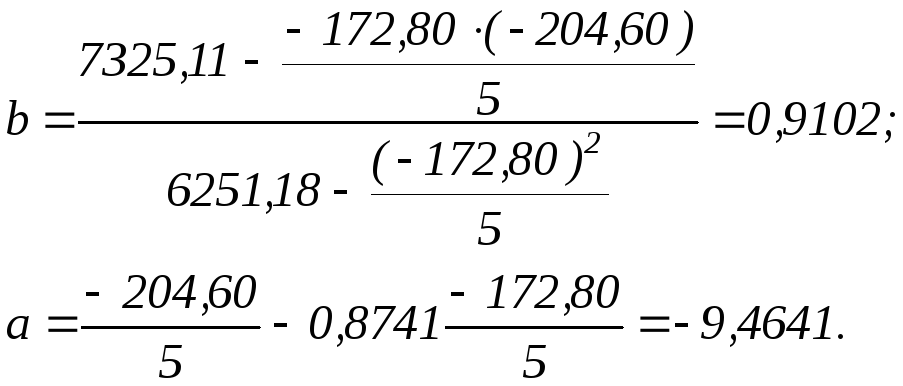
Таким образом, модель связи будет иметь вид:
![]() .
.
Коэффициент регрессии b = 0,9102 означает, что с изменением прироста среднегодовой численности рабочих на 1 процентный пункт среднегодовая численность ППП изменяется с ускорением, равным 0,9102 тыс.чел.
Аналогично произведем расчет параметров уравнения регрессии по отклонениям от тренда:

Таким образом, модель связи будет иметь вид:
![]() .
.
Методы прогнозирования стационарных временных рядов
Иногда встречаются временные ряды, у которых отсутствует тенденция к росту или падению, т.е. тренд. Такие ряды называются стационарными.
Уровни стационарного динамического ряда колеблются вокруг некоторого среднего значения. Прогнозирование сводится к поиску этого среднего значения. Чем успешнее осуществится этот поиск, тем меньше ошибки прогноза.
Прогноз для периода t+1 , т.е. на один шаг вперед, на основе среднего уровня может иметь следующий вид:
П t+1 = (Фt + Фt-1 + Фt-2):3,
где Фt - фактический уровень текущего периода,
Ф t-1 и Ф t-2 - уровни более ранних периодов.
Здесь для расчета средней использовано три прошлых уровня. В принципе их может быть больше. Погашение случайностей при этом будет более сильным. Однако, углубляясь в историю, надо всегда помнить об опасности переноса на будущее слишком старых закономерностей.
Недостатком вышеприведенной средней является то, что при ее расчете придается одинаковый вес периодам, разноудаленным от горизонта прогнозирования. Между тем, периодам, близким к горизонту прогнозирования, следовало бы придавать несколько больший вес. Это в какой-то мере ослабляло бы влияние старых закономерностей и усиливало бы значение закономерностей последних лет, близких к горизонту прогнозирования.
Неравные веса можно взять произвольно. Например, следующим образом:
-
Период
t
t-1
t-3
Вес
3
2
1
Тогда расчет средней будет выглядеть так:
![]()
Р.Браун предложил брать веса, убывающие по экспоненте:
|
Период |
t |
t-1 |
t-2 |
t-3 |
… |
t-n |
|
Вес |
|
(1-) |
(1-)2 |
(1-)3 |
… |
(1-)n |
Величина называется параметром сглаживания и исчисляется по формуле, предложенной Р.Брауном:
=
![]() ,
,
где n - число уровней динамического ряда, которые желательно принять во внимание при расчете средней.
Если необходимо ориентироваться только на четыре последних уровня ряда, то окажется равной:
=
![]() = 0,4.
= 0,4.
Веса отдельных периодов при этом будут иметь такой вид:
|
Период |
t |
t-1 |
t-2 |
t-3 |
|
Вес |
0,4 |
0,4(1-0,4) |
0,4(1-0,4)2 |
0,4(1-0,4)3 |
|
|
0.4 |
0.24 |
0.144 |
0.0864 |
Обычно рекомендуется брать на уровне 0,05-0,3, то есть предлагается ориентироваться на длительную историю, порядка 8- 40 временных периодов. Для быстро меняющихся условий параметрнужно брать на уровне 0,7-0,9. Если взять, например,=0,7, то прогноз для периода t+1 будет выглядеть так:
П t+1 = Фt 0,7 + Фt-1 0.21 + Фt-2 0.063 + Ф t-3 0,0189 + ..
“Хвост” этого выражения, т.е. Фt-1 0.21 + Фt-2 0.063 + Фt-3 0,0189 + .., можно представить как прогноз для периода t. Тогда прогноз для периода t+1 получит вид такой рекурентной формулы:
П t+1 = Фt + П t (1-). (4.4)
Расчеты каждого очередного прогноза являются при этом продолжением ранее сделанных расчетов. Исключается необходимость производить их каждый раз с начального периода.
Для начального периода можно использовать “наивный прогноз”
П1=Ф1.
Можно также вместо “наивного прогноза” использовать экспертную оценку. Тогда прогноз для второго периода на базе данных первого периода получит такой вид:
П 2 = Ф1 + ПЭ 1 (1 - ), (4.5)
где ПЭ1 - прогнозная величина первого периода, установленная экспертным путем.
При экспертной оценке величине ПЭ1стремятся придать такое значение, которое бы в последующих расчетах минимизировало бы ошибку прогноза. Минимизация ошибки достигается не только перебором возможных значений упомянутой величины, но также перебором различных значений параметра сглаживания -. Чем меньше в конечном результате получается ошибка последующих прогнозов, тем лучше будет адаптация модели к реально сложившимся условиям.
Методические указания3
Задания к домашней работе составлены в 10 вариантах. Номер варианта соответствует последней цифре шифра зачетной книжки. Если последняя цифра зачетной книжки – 0, следует выполнить 10-й вариант.
Каждый вариант контрольной работы содержит 5 задач по основным разделам курса. Порядковый номер задачи из каждой темы соответствует номеру варианта.
Результаты расчетов всех относительных величин необходимо проводить с точностью до 0,0001, а процентов - до 0,01.
Все расчеты должны быть выполнены как вручную, так и с использованием пакетов прикладных программ на персональном компьютере. В последнем случае следует обязательно указывать название и версию использованного программного обеспечения. Соответствующие распечатки необходимо привести в тексте работы или оформить в качестве приложения.
Все расчеты должны сопровождаться комментариями и интерпретацией полученных результатов.
Указания к выполнению контрольных работ содержат все необходимые формулы, а также содержат примеры расчетов типовых задач, которые по тексту указаний выделены курсивом.