

Pro Visual C++-CLI And The .NET 2.0 Platform (2006) [eng]-1
.pdf808C H A P T E R 2 0 ■ U N S A F E C + + . N E T P R O G R A M M I N G
int Madd(int a, int b)
{
return a + b;
}
void main()
{
Console::WriteLine("Unmanaged |
Add |
2 |
+ |
2: |
{0}", |
UMadd(2, |
2)); |
Console::WriteLine("Managed |
Add |
3 |
+ |
3: |
{0}", |
Madd(3, |
3)); |
}
By looking at the UMadd() and Madd() methods’ code, you will not see much difference. Both are simply standard C++/CLI code. Notice you even call the methods the same way, as long as they are being called within a managed code block.
If you try to call managed code within a native code block, you get the compile time error C3821 'function': managed type or function cannot be used in an unmanaged function. This makes sense as native code does not use the CLR to run, while managed code does, so there is no way for the managed code to be executed within the native code.
Another thing you need to be careful about with these directives is thatthey are only allowed at the global scope, as shown in Listing 20-1, or at the namespace scope. This means you can’t change a method or class partway through. In other words, the whole function or class can be managed or native, but not a combination.
■Caution The following code is invalid due to invalid placement of the #pragma directives:
int ErrorFunction(int a, int b)
{
#pragma unmanaged
//Some unmanaged code #pragma managed
//Some managed code
}
■Unsafe Code Since the #pragma unmanaged directive causes unsafe code to be generated, you need to compile it with the /clr option. If you try to compile it with the /clr:safe option, you will get a whole bunch of errors.
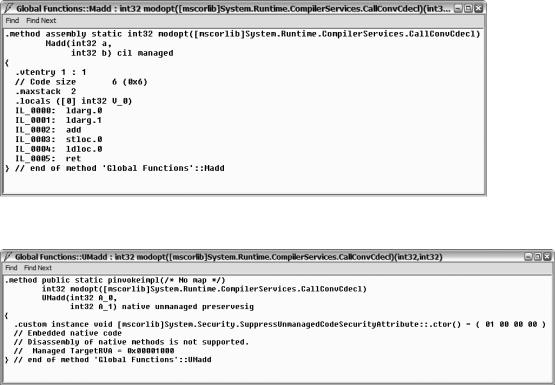
So what is the difference between Madd() and UMadd()? To see this, you need to use the ildasm tool, which disassembles an assembly. Figure 20-1 shows Madd() (what little you see of it) and Figure 20-2 shows UMadd().
C H A P T E R 2 0 ■ U N S A F E C + + . N E T P R O G R A M M I N G |
809 |
Figure 20-1. The disassembled Madd()
Figure 20-2. The disassembled UMadd()
The disassembled version of the Madd() function shows all the MSIL required to execute the function, while the UMadd() function only shows the function declaration and the attribute SuppressUnmanagedCodeSecurityAttribute. What you don’t see is the native code that will be
invoked when this function is called (if the CLR allows unmanaged code or in this case native code to be run). In a nutshell, behind the scenes the compiler generates MSIL for Madd() and native code for UMadd().
You might be thinking, as I did originally, why is this code unsafe? The CLR has the attributes needed to find out what is unsafe and can allow code access security to do its thing. But, if you think about it, it does sort of make sense. Since the whole assembly is loaded into memory, it might still be possible for someone to access the parts of the assembly that are unsafe. (Don’t ask me how, but I’m sure some hacker out there has it figured out.) Therefore, to safeguard against this possibility, the current version of the .NET runtime defines unsafe code at an assembly level, so having any unsafe code in an assembly makes the entire assembly unsafe.

810 |
C H A P T E R 2 0 ■ U N S A F E C + + . N E T P R O G R A M M I N G |
Unmanaged Arrays
One of the first things a C++ developer learns is arrays. Having coded them so long, it is easy to forget that .NET does it differently, when you want your code to be safe. (The usual culprit as to why I have unmanaged arrays in my code is that I cut and paste them in from legacy code and then forget to convert them, until I get all the errors when I try to compile with the /clr:safe option.)
The unmanaged arrays compile and work fine if you don’t use the /clr:safe option. When you examine the MSIL code generated, everything looks just fine. So why is an unmanaged array unsafe? If you have coded C++ for a while, I’m sure you know. It is very easy to overflow the stack by looping through an array too many times. (I’ve done it so many times, I’ve lost count.) There is nothing stopping a program from doing this with an unmanaged array. A managed array, on the other hand, does not allow you to go beyond the end of the array. If you try, you get a nice big exception.
■Unsafe Code Unmanaged arrays, though a legal construct in C++/CLI (so long as they contain fundamental and unmanaged data types) are unsafe. If you want both arrays and safe code, you need to use managed arrays.
Listing 20-2 shows the use of unmanaged arrays within managed code.
Listing 20-2. The Unmanaged Array in Managed Code
using namespace System;
void main()
{
int UMarray[5] = {2, 3, 5, 7, 11};
for (int i = 0; i < 5; i++)
{
Console::Write("{0} ", UMarray[i]);
}
Console::WriteLine(" -- End of array");
}
There is nothing terribly special about the preceding code. But there are specific criteria about what can be contained within an unmanaged array. Personally, I think it’s easier to remember what can’t be put into them—basically managed data or anything that requires the gcnew command when creating an instance.
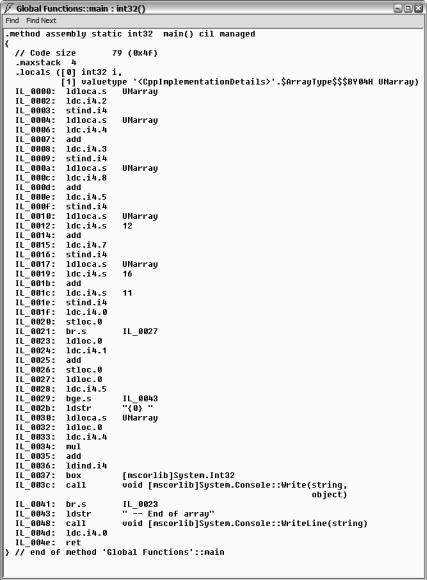
One thing of note, as shown in Figure 20-3, is that the code generated by the compiler is MSIL and not native code. Thus, showing unsafe code does not always mean that the code contains native code. (Though you might argue this, as a whole bunch of native code is added to the assembly when /clr or /clr:pure options are used.)
C H A P T E R 2 0 ■ U N S A F E C + + . N E T P R O G R A M M I N G |
811 |
Figure 20-3. MSIL generated by UMArray.exe
Unmanaged Classes/Structs
The next major constructs that a C++ developer learns after the array are the class and the struct. Though similar in many ways to C++/CLI’s ref class (which I covered way back in Chapter 3), unmanaged classes have a few major differences that cause them to be unsafe. The most obvious difference, since they are unmanaged, is that they are placed in the CRT heap and not the Managed heap when instantiated. Thus, their memory is not maintained by the .NET garbage collector.

C H A P T E R 2 0 ■ U N S A F E C + + . N E T P R O G R A M M I N G |
813 |
Listing 20-3. Mixing Managed and Unmanaged Classes
using namespace System;
class |
ClassMember {}; |
|
||
ref |
class |
RefClassMember {}; |
|
|
value class ValueClassMember {}; |
||||
class Class |
|
|
|
|
{ |
|
|
|
|
public: |
|
|
|
|
// |
RefClassMember |
rc; |
// Can't embed instance ref class |
|
// |
RefClassMember |
^hrc; |
// Can't embed handle to ref class |
|
|
ValueClassMember |
vc; |
|
|
// |
ValueClassMember ^hvc; |
// Can't embed managed value class |
||
|
ValueClassMember *pvc; |
|
||
|
ClassMember |
c; |
|
|
|
ClassMember |
*pc; |
|
|
|
int x; |
|
|
|
|
void write() { Console::WriteLine("Class x: {0}", x); } |
|||
}; |
|
|
|
|
ref |
class RefClass |
|
|
|
{ |
|
|
|
|
public: |
|
|
|
|
|
RefClassMember |
rc; |
|
|
|
RefClassMember |
^hrc; |
|
|
|
ValueClassMember |
vc; |
|
|
|
ValueClassMember ^hvc; |
|
||
|
ValueClassMember *pvc; |
|
||
// |
ClassMember |
c; |
// Can't embed instance of class |
|
|
ClassMember |
*pc; |
|
|
|
int x; |
|
|
|
|
void write() { Console::WriteLine("RefClass x: {0}", x); } |
|||
}; |
|
|
|
|
value class ValueClass |
|
|||
{ |
|
|
|
|
public: |
|
|
|
|
// |
RefClassMember |
rc; |
// Can't embed instance ref class |
|
|
RefClassMember |
^hrc; |
|
|
|
ValueClassMember |
vc; |
|
|
|
ValueClassMember ^hvc; |
|
||
|
ValueClassMember *pvc; |
|
||
// |
ClassMember |
c; |
// Can't embed instance of class |
|
|
ClassMember |
*pc; |
|
|
int x;
void write() { Console::WriteLine("ValueClass x: {0}", x); }
};
814 C H A P T E R 2 0 ■ U N S A F E C + + . N E T P R O G R A M M I N G
class ClassChildClassParent : public Class {}; |
|
// |
OK |
|||
//class ClassChildRefClassParent : public RefClass {}; |
// |
Error |
||||
//class ClassChildValueClassParent : public ValueClass {}; |
// |
Error |
||||
//ref class RefClassChildClassParent : public Class {}; |
// |
Error |
||||
ref |
class RefClassChildRefClassParent : public RefClass {}; |
// |
OK |
|||
//ref class RefClassChildValueClassParent : public ValueClass {}; |
// |
Error |
||||
//value class ValueClassChildClassParent : public Class {}; |
// |
Error |
||||
//value class ValueClassChildRefClassParent : public RefClass {}; |
// |
Error |
||||
//value class ValueClassChildValueClassParent : public ValueClass {}; |
// |
Error |
||||
void main() |
|
|
|
|
|
|
{ |
|
|
|
|
|
|
|
// Stack |
|
|
|
|
|
|
Class |
_class; |
|
|
|
|
|
RefClass |
refclass; |
|
// Not really on the |
stack |
|
|
ValueClass valueclass; |
|
|
|
|
|
|
// Handle |
|
|
|
|
|
// |
Class |
^hclass |
= gcnew Class(); |
// Not allowed |
|
|
|
RefClass |
^hrefclass |
= gcnew RefClass(); |
|
|
|
|
ValueClass ^hvalueclass |
= gcnew ValueClass(); |
|
|
|
|
|
// Pointer |
|
|
|
|
|
|
Class |
*pclass |
= new Class(); |
|
|
|
// |
RefClass |
*prefclass |
= new RefClass(); |
// Not allowed |
|
|
|
ValueClass *pvalueclass |
= & valueclass; |
|
|
|
|
|
// Reference |
|
|
|
|
|
|
Class |
&rfclass |
= *new Class(); |
|
|
|
//RefClass &rfrefclass = *gcnew RefClass(); // Not allowed ValueClass &rfvalueclass = valueclass;
_class.x |
= 1; |
|
refclass.x |
= 2; |
|
valueclass.x |
= 3; |
|
hrefclass->x |
= 4; |
|
hvalueclass->x = 5; |
|
|
pclass->x |
= 6; |
|
pvalueclass->x = 7; |
|
|
rfclass.x |
= 8; |
|
rfvalueclass.x = 9; |
|
|
_class.write(); |
|
// prints 1 |
refclass.write(); |
// prints 2 |
|
valueclass.write(); |
// prints 9 |
|
hrefclass->write(); |
// prints 4 |
|
hvalueclass->write(); |
// prints 5 |
|
pclass->write(); |
// prints 6 |
|
pvalueclass->write(); |
// prints 9 |
|
rfclass.write(); |
// prints 8 |
|
rfvalueclass.write(); |
// prints 9 |
|
}

C H A P T E R 2 0 ■ U N S A F E C + + . N E T P R O G R A M M I N G |
815 |
Pointers
If you have spent any time writing C++ code in the past, I’m sure you have come to realize that pointers are essential to C++ development, but also a necessary evil. Basically, it’s a “you can’t live with them, can’t live without them” relationship. Some of the greatest code has been developed using pointers, but also some of the nastiest bugs.
Unmanaged C++ data types can be placed in one of two places, the stack or the heap. When you are dealing with pointers, you are generally dealing with heap data. But pointers can point to almost anything (if the program has the rights), so a pointer can also point to an element of the runtime stack or possibly locations directly within the Windows O/S, though usually that is not allowed. Pointers can be created in a number of ways:
•Placing the address directly into the pointer
•Arithmetically calculated from another pointer
•Copied from an existing object
•Using the new command
Just looking at the preceding list should make it obvious why pointers are not safe. In fact, the first two methods of creating pointers should make you cringe. Think what a field day hackers could have with these methods and thus why they are not supported by handles.
■Unsafe Code Pointer arithmetic is probably one of the most powerful and at the same time unsafe operations available to a C++ programmer.
Copying a pointer from an existing object seems harmless enough. But even this has a problem if the object is derived from a managed type. The location of the object pointed to in the managed heap memory can move during the garbage collection process, because not only does the garbage collector delete unused objects in managed heap memory, it also compacts it. Thus, it is possible that a pointer may point to the wrong location after the compacting process. Fortunately, C++/CLI provides two ways of solving pointer movement: the interior pointer and the pinned pointer. I’ll cover both in more detail later in the chapter.
Not even using the new command is safe, as the memory allocated is on the CRT heap and is not maintained by the CLR. Using the new command requires you to maintain the allocated memory yourself and when done call the delete command. I know this sounds okay, but I’m afraid very few of us are perfect when it comes to writing code, and I’m pretty sure one day you will forget to deallocate memory, deallocate it too soon, overwrite it, or do any of the other nasty mistakes revolving around pointers.
Interior Pointer
As I harped previously, pointers are extremely powerful, and it would be a great loss to the C++ to lose this aspect of the language. C++/CLI realizes this and has added what it calls interior pointers. Interior pointers are fundamentally pointers to managed objects.
I hope your alarms went off with the last sentence. Remember, managed objects can move. So let’s be a little more accurate. An interior pointer is a superset of the native pointer and can do anything that can be done by the native pointer. But not only does it point to a managed object, when the garbage collector moves the object, the interior pointer changes its address to continue to point to it.
816 |
C H A P T E R 2 0 ■ U N S A F E C + + . N E T P R O G R A M M I N G |
By the way, interior pointers are safe! Well, I better qualify that. You can use the pointers as you see fit, and they are safe. Just don’t change the value of the pointers or manipulate them using pointer arithmetic. Listing 20-4 is a somewhat complicated example showing a safe program using interior pointers.
Listing 20-4. Safe Interior Pointers using namespace System;
ref class Point
{
public: int X;
}; |
|
void main() |
|
{ |
|
Point ^p = gcnew Point(); |
|
interior_ptr<Point^> ip1 = &p; |
// Interior pointer to Point |
(*ip1)->X = 1; |
// Assign 1 to the member variable X |
Console::WriteLine("(&ip1)={0:X}\tp->X={1}\t(*ip1)->X={2}", |
|
(int)&ip1, p->X, (*ip1)->X); |
|
interior_ptr<int> ip2 = &p->X; |
// Pointer to Member variable X |
*ip2 += (*ip1)->X; |
// Add X to an interior pointer of itself |
Console::WriteLine("(&ip2)={0:X}\t*ip2={1}", (int)&ip2, *ip2);
}
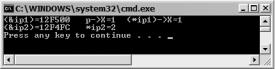
Notice I can assign numbers to the value of the interior pointer. I just can’t change the address that the pointer is pointing to. Well, actually, I can, but then the code is no longer safe.
Figure 20-4 shows the results of this little program.
Figure 20-4. Results of IntPtr.exe
I’ve been writing about pointer arithmetic long enough. Let’s look at Listing 20-5 and see an example. This example adds the first eight prime numbers together. It does this by adding the value of the same pointer eight times, but each time the value is added the address of the pointer has advanced the size of an int. This example really doesn’t need an interior pointer and can be written many other (safe) ways.
C H A P T E R 2 0 ■ U N S A F E C + + . N E T P R O G R A M M I N G |
817 |
Listing 20-5. Interior Pointer and Pointer Arithmetic and Comparision
using namespace System;
void main()
{
array<int>^ primes = gcnew array<int> {1,2,3,5,7,11,13,17};
interior_ptr<int> ip = &primes[0]; |
// Create the interior pointer |
int total = 0; |
|
while(ip != &primes[0] + primes->Length) |
// Comparing pointers |
{ |
|
total += *ip; |
|
ip++; |
// Add size of int to ip not 1 |
} |
|
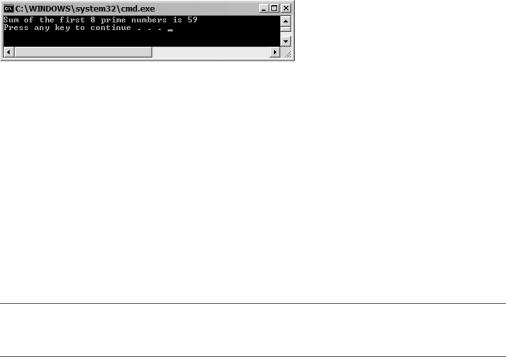
Console::WriteLine("Sum of the first 8 prime numbers is {0}", total);
}
Figure 20-5 shows the results of this little program.
Figure 20-5. Results of IntPtrArth.exe
Pinning Pointers
If you are a seasoned traditional C++ programmer, you probably saw immediately a problem with the handle’s ability to change addresses. There is no fixed pointer address to access the object in memory. In prior versions of C++/CLI (Managed Extensions for C++), the same syntax was used for addressing managed and unmanaged data. Not only did this lead to confusion, but it also did not make it apparent that the pointer was managed and thus could change. With the new handle syntax, it is far less confusing and readily apparent that the object is managed.
Unfortunately, the volatility of the handle address also leads to the problem that passing a handle to a managed object, as a parameter to an unmanaged function call, will fail. To solve this problem, C++/CLI has added the pin_ptr<> keyword, which stops the CLR from changing its location during the compacting phase of garbage collection. The pointer remains pinned so long as the pinned pointer stays in scope or until the pointer is assigned the value of nullptr.
■Unsafe Code The pin_ptr<>, since it deals with providing specific address locations into memory, is an unsafe operation.
The pin_ptr<> uses template syntax where you place the type of object you want to pin within the angle [<>] brackets. For example:
pin_ptr<int>
I covered templates in Chapter 4.