

Чтобы компактно описать наборы β1, β2 ,..., βt локаторов, вводят так называемый многочлен локаторов σ(z) , корнями которого являются
элементы, обратные по умножению этим номерам,
σ(z) = (1−β1z)(1−β2 z)...(1−βt z).
Таким образом, первая задача декодера БЧХ и PC состоит в нахождении многочлена локаторов σ(z) , т.е. его коэффициентов при степенях z. Упрощенная схема декодирования кодов БЧХ включает следующие операции.
Полученная из канала последовательность Y делится на полиномы, входящие в разложение порождающего многочлена кода. Остатки от деления связаны с многочленом локаторов ключевым уравнением. Решение ключевого уравнения дает оценку многочлена σ(z) . Поиск корней этого многочлена и инвертирование принятых бит на позициях, соответствующих найденным корням, завершают алгоритм декодирования.
В словах кодов PC, заданных над полем GF(2m), каждый символ представляет собой т-разрядный двоичный вектор. Поэтому для исправления ошибки недостаточно указать номер искаженного символа. Требуется еще определить значение искажения, т.е. m- разрядный компонент вектора ошибки. Последний вычисляется по многочлену локаторов и многочлену значений, полученных при решении ключевого уравнения.
3.3. СВЕРТОЧНЫЕ КОДЫ
Сверточные коды относятся к непрерывным рекуррентным кодам. Кодовое слово является сверткой отклика линейной системы (кодера) на входную информационную последовательность. Поэтому сверточные коды являются линейными, для которых сумма любых кодовых слов также является кодовой последовательностью.
Ограничимся ниже рассмотрением лишь наиболее характерных (базовых, или материнских) для мобильной связи сверточных кодов со скоростями вида Rk =1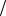 n0 , где n0 – некоторое натуральное число. Последовательность символов такого сверточного кода состоит из элементарных блоков длиной n0 , причем n0 символов текущего блока (занимающие реальное время, отвечающее одному информационному биту) являются линейной комбинацией текущего информационного бита и т предшествующих. Значение т определяет память кода, а параметр m +1 называется длиной кодового ограничения. Если один (например, первый) из n0
n0 , где n0 – некоторое натуральное число. Последовательность символов такого сверточного кода состоит из элементарных блоков длиной n0 , причем n0 символов текущего блока (занимающие реальное время, отвечающее одному информационному биту) являются линейной комбинацией текущего информационного бита и т предшествующих. Значение т определяет память кода, а параметр m +1 называется длиной кодового ограничения. Если один (например, первый) из n0
символов текущего блока повторяет текущий информационный бит, код называется систематическим.
Способы задания сверточных кодов во многом совпадают с используемыми для линейных блоковых. Одним из основных является описание сверточного кода набором n0 порождающих многочленов. Каждый многочлен устанавливает закон формирования одного из п0 символов в группе и имеет степень, не превышающую т. Ненулевые коэффициенты порождающего полинома прямо указывают, какие из информационных
42
символов (включая текущий и т предыдущих) входят в линейную комбинацию, дающую данный символ кода (см. пример 3.3). Порождающие многочлены хороших сверточных кодов найдены перебором и табулированы.
Весьма важным с точки зрения понимания алгоритмов кодирования и декодирования инструментом описания сверточных кодов является кодовая решетка, смысл которой должен быть ясен из следующего примера.
Пример 3.3. Пусть несистематический сверточный код со скоростью Rk =1/ 2 и кодовым ограничением m +1 = 3 задается порождающими
многочленами g1(x) = x2 + x +1 и g2 (x) = x2 +1.
Это означает, что первый из двух символов каждого двухсимвольного блока является линейной комбинацией (суммой по модулю 2) текущего и двух предшествующих информационных битов, тогда как второй получается сложением по модулю 2 текущего информационного бита с тем, который поступил от источника двумя тактами раньше.
Схема кодера приведена на рис. 3.3. Заметим, что при одном из многочленов, равном единице, получился бы систематический сверточный код.
ai |
|
|
|
|
|
|
|
|
М2 |
c |
, c |
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|||
D |
Т |
a |
|
D |
Т |
|
|
|
|
|||
|
|
|
ai−2 |
|
2i |
|||||||
|
|
|
|
|
|
|
|
|
|
1i |
|
|
|
|
|
i−1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
М2
Рис. 3.3. Схема кодера
Кодовая решетка этого кода показана на рис. 3.4. При ее составлении учтено, что кодер содержит память в виде двухразрядного сдвигающего регистра. Каждому из четырех возможных состояний этого регистра отвечает один из четырех узлов решетки. Поэтому левый символ в обозначении узла равен последнему информационному биту, уже записанному в регистр. При записи в регистр очередного информационного символа регистр меняет состояние на одно из двух соседних. Этот переход обозначен ребрами решетки. Порядок узлов выбран таким, что при нулевом текущем информационном символе ( ai = 0 ) переход в следующее состояние
соответствует верхнему ребру, а при ai =1 – нижнему. Маркировка ребер воспроизводит n -блок, посылаемый в канал. Каждой информационной последовательности соответствует определенный путь на кодовой решетке и кодовая последовательность, считываемая как метки, маркирующие последовательные ребра пути. К примеру, входным информационным битам отвечает кодовое слово 00 11 01 01 11, которому соответствует на рис. 3.4 путь, отмеченный жирной линией.
43

00 00 00 00 00
00
10
01 
11 |
11 |
11 |
11 |
10 |
00 |
00 |
00 |
10 |
10 |
10 |
|
01 |
01 |
01 |
01 |
11 


 10 10 10
10 10 10
3.4. Кодовая решетка
Известен ряд алгоритмов декодирования сверточных кодов. В практических системах и, в частности в мобильной связи, как правило, используется алгоритм Витерби, отличающийся простотой реализации при умеренных длинах кодового ограничения.
Алгоритм Витерби реализует оптимальное (максимально правдоподобное) декодирование как рекуррентный поиск на кодовой решетке пути, ближайшего к принимаемой последовательности. На каждой итерации алгоритма Витерби сопоставляются два пути, ведущих в данное состояние (узел решетки). Ближайший из них к принятой последовательности сохраняется для дальнейшего анализа как выживший, тогда как другой отбрасывается. Таким образом, если игнорировать случаи, когда оба конкурирующих пути равноудалены от принятой последовательности (о действиях в подобной ситуации см. ниже), число выживших путей, сохраняемых в памяти, равно числу узлов 2m . Основные операции алгоритма поясним для кода из примера 3.3.
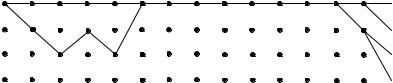
Пусть передается нулевое кодовое слово, а в канале произошла трехкратная ошибка, так что принятая последовательность имеет вид 10 10 00 00 10 00 ... 00 ... . Результаты поиска ближайшего пути после приема 14 элементарных блоков показаны на рис. 3.5.
На правой части рисунка видны четыре пути, ведущие в каждый узел решетки. Рядом проставлены метрики (хэмминговы расстояния этих путей от принятой последовательности на отрезке из 14 блоков). Метрика верхнего пути значительно меньше метрик нижних. Поэтому можно предположить, что верхний путь наиболее вероятен. Однако декодер Витерби, не зная следующих фрагментов принимаемой последовательности, вынужден запомнить все четыре пути на время приема L элементарных блоков. Число L называется шириной окна декодирования. Для уменьшения ошибки декодирования величину L следует выбирать достаточно большой многократно превышающей длину кодового ограничения, что естественно усложняет декодер. В данном случае L =15 .
44
Отметим, что тактика выбора и последующего анализа только одного пути с наименьшим расстоянием составляет сущность более экономного последовательного декодирования.
 3
3
 5
5
 6
6  6
6
Рис. 3.5. Пример работы алгоритма Витерби
На средней части рис. 3.5 видно, что все пути имеют общий резок (сливаются от 5-го до 12-го шага) и, следовательно, прием новых блоков не может повлиять на конфигурацию этого участка наиболее правдоподобного пути. Поэтому декодер уже может принимать решение о значении информационных символов соответствующих этим элементарным блокам.
Левая часть рисунка демонстрирует возможную ситуацию неисправляемой ошибки. Существует два пути с одинаковыми метриками. Декодер может разрешить эту неопределенность двумя способами: отметить этот участок как недостоверный или принять одно из двух конкурирующих решений (информационная последовательность равна 00000... или 10100...). Очевидно, что расширение окна декодирования не позволяет исправить такую ошибку. Ее исправление возможно при использовании кода с большей корректирующей способностью.
Поступление из канала нового элементарного блока вызывает сдвиг картинки в окне декодирования влево. В результате левое ребро пути исчезает, а справа появляется новый столбец решетки, к узлам которого должны быть продолжены сохраненные пути от узлов предыдущего столбца. Для этого выполняются следующие операции.
1.Для каждого узла нового столбца вычисляются расстояния между принятым блоком и маркировкой ребер, ведущих в данный узел.
2.Полученные метрики ребер суммируются с расстоянием путей, которые они продолжают.
3.Из двух возможных путей оставляется путь с меньшей метрикой, а другой отбрасывается, так как следующие поступающие блоки не могут изменить соотношения расстояний этих путей. В случае равенства расстояний или случайно выбирается один путь, или сохраняются оба.
В результате этих операций к каждому узлу нового столбца вновь ведет один путь. Например, пусть новый блок из канала равен 00. Рассмотрим продолжение пути к нижнему узлу решетки, в который можно попасть из состояния кодера 10 по ребру 01 или из состояния 11 по ребру 10 (см. рис. 7.4). В обоих случаях расстояние этих ребер от принятого блока 00 равно 1. Однако суммарное расстояние пути, продолженного из состояния 10, равно 6,
45
а пути из состояния 11 равно 7. Поэтому второй путь будет отброшен вместе с ребром 01, которое входило в нижний узел на предыдущем шаге декодирования (рис. 3.5).
Оценка информационного символа производится по крайнему левому ребру пути в окне декодирования. Согласно правилу построения кодовой решетки принимается, что информационный символ равен 0, если это ребро верхнее, и 1, если ребро нижнее.
Рассмотренный пример поясняет работу декодера в предположении, что выходной сигнал демодулятора квантуется на 2 уровня (так называемое жесткое декодирование). Большее число уровней квантования приводит к мягкому декодированию. Установлено, что 8 уровней квантования гарантируют практически потенциальную достоверность декодирования.
Чтобы в этом случае использовать алгоритм Витерби, требуется вместо расстояния Хэмминга ввести новое расстояние, точнее учитывающее различие между принятой последовательностью (выходным многоуровневым сигналом демодулятора) Y и ожидаемым двоичным кодовым словом С. Например, можно использовать евклидово расстояние или расстояние
n0 |
(3.5) |
d(Y ,C) = ∑log P( yi ci ), |
i=1
где P( yi ci ) – переходная вероятность канала, т.е. условная вероятность появления на выходе демодулятора отсчета yi при передаче символа ci .
n0
Для удобства вычислений (3.5) на практике заменяется на d = ∑mi , где
i=0
mi – целые положительные числа, количество которых равно числу уровней квантования, причем mi = 0 , когда между yi и ci наблюдается наибольшее
соответствие.
На рис. 3.6 приведен размеченный граф канала при 4 уровнях квантования, которым приписаны числа mi , равные 0, 1,2, 3.
0 |
0 |
|
0 |
1 |
|
||
|
|
|
|
|
|
|
1 |
c i |
3 |
2 |
y i |
|
|
|
2 |
1 |
1 |
|
3 |
0 |
|
||
|
|
|
Рис. 3.6. Граф канала при мягком декодировании
Граф позволяет определить меру расходимости между ребрами пути на кодовой решетке и принятыми символами. Если, например, на выходе демодулятора yi = 2 , а маркировка ребра проверяемого пути имеет ci = 0 , то
46
мера расходимости равна 2. При yi = 2 и наличии на ребре метки ci =1 расходимость mi =1 . Эти числа суммируются в пределах кадра n0 и добавляются к мере расходимости продолжаемого пути. Дальнейшие операции алгоритма Витерби при мягком декодировании совпадают с операциями жесткого декодирования. Выигрыш мягкого декодирования составляет около 2 дБ. Так как сложность вычислений при этом возрастает незначительно, то мягкое декодирование широко используется в современных системах мобильной связи.
Турбо-коды, предложенные сравнительно недавно, являются результатом совместного использования идей сверточного кодирования с мягким решением и перемежения символов. Блок А из k информационных бит через перемежители поступает на N элементарных систематических сверточных кодеров. Они могут быть различными и иметь разные скорости. Структурная схема кодера при N = 2 показана на рис. 3.7.
А
|
|
|
|
В1 |
|
|
|
Кодер 1 |
|
|
|
|
В2 |
|
|
|
|
|
|
|
|
|
|
|
|
Перемежитель |
|
Кодер 2 |
|
|
|
|
||
|
|
|
|
|
Рис. 3.7. Кодер турбо-кода
На выходах элементарных кодеров 1 и 2 формируются две последовательности проверочных бит Â1 , и Â2 , что дает скорость, равную 1/3. В общем случае, если кодеры одинаковы, скорость кода равна Rk =1/(N +1) .
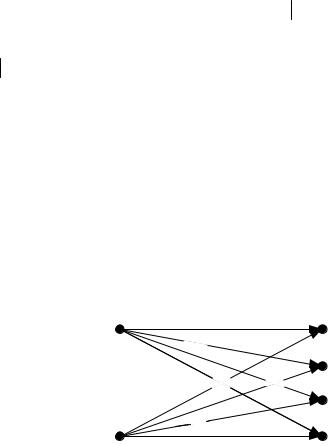
Декодирование турбо-кода выполняется элементарными декодерами с мягким решением с учетом перемежения символов, выполненного на передающей стороне. Структурная схема турбо-декодера для N = 2 показана на рис. 3.8.
Перемежители (П), идентичные перемежителю кодера, согласовывают порядок поступления бит А и оценок этих бит, вырабатываемых декодером 1. Деперемежители (ДП) восстанавливают порядок поступления оценок с выхода декодера 2 для первого, декодера. Таким образом, при оценке символа учитываются не только принятые биты, но и мягкие решения, вынесенные каждым элементарным декодером. Турбо-коды являются единственными из известных, позволяющими работать со скоростями, близкими к пропускной способности канала с ограниченной полосой. Согласно документам 3GPP (см. гл. 12) их планируется использовать в мобильных системах третьего поколения.
47