

Міністерство освіти і науки України
Національний Університет Харчових Технологій
Кафедра інформаційних систем
Розрахункова робота
з дисципліни
Клієнт-серверні технології розроблення баз даних
на тему :
Характеристика та призначення засобів інтелектуального аналізу даних в MS SQL Server 2005
Виконав :
студент АКС 5-ІТ-М
Сачик Є. І.
Перевірив викладач:
Грибков С.В.
Київ 2010
План
Служби Microsoft SQL Server.
Служба Analysis Services, інтелектуальний аналіз даних.
Data Mining - сучасна технологія аналізу інформації.
Алгоритми інтелектуального аналізу данних.
Перевірка моделей інтелектуального аналізу даних.
Запити до моделей інтелектуального аналізу даних.
Конструктор прогнозуючих запитів; Одноелементні запити.
Редактор запитів; Шаблони.
Додатки.
Служби Microsoft SQL Server
Microsoft SQL Server 2005 являє собою платформу для роботи з базами даних, що забезпечує можливість великомасштабної оперативної обробки транзакцій, зберігання даних і роботи з додатками для електронної торгівлі, а також є платформою бізнес-аналітики для створення рішень з інтеграції даних, аналізу та складанню звітів. Детальна схема комопонентів MS SQL Server 2005 наведена на рис.1.
Рис.1 Компоненти SQL Server 2005
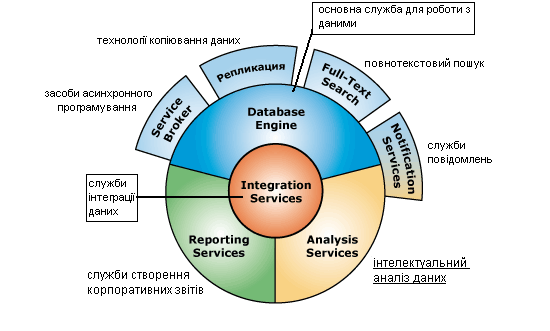
Компоненти SQL Server 2005:
Компонент Database Engine;
Служби Analysis Services;
Служби Integration Services;
Служби Reporting Services;
Служби Notification Services;
Компонент Service Broker;
Повнотекстовий пошук (Full-Text Search);
Реплікація.
Компонент Database Engine являє собою основну службу для зберігання, обробки та забезпечення безпеки даних. Цей компонент забезпечує керований доступ до ресурсів та швидку обробку транзакцій, що дозволяє використовувати його навіть в самих вимогливих корпоративних додатках обробки даних. Крім того, компонент Database Engine забезпечує різнобічну підтримку високого рівня доступності.
Служби Analysis Services пропонують інтерактивну аналітичну обробку та інтелектуальний аналіз даних для додатків бізнес-аналітики. Analysis Services підтримують інтерактивну аналітичну обробку, дозволяючи проектувати, створювати та управляти багатовимірними структурами, що містять дані, зібрані з інших джерел, таких як реляційні бази даних. Завдяки служб Analysis Services в додатках інтелектуального аналізу даних можна проектувати, створювати та візуалізувати моделі інтелектуального аналізу даних. Різноманітність стандартних алгоритмів інтелектуального аналізу даних дозволяє створювати такі моделі на основі інших джерел даних.
Служби Integration Services - це платформа для створення високопродуктивних рішень по інтеграції даних, включаючи пакети для зберігання даних, що забезпечують вилучення, перетворення і завантаження даних.
Реплікація являє собою набір технологій, за допомогою яких дані або об'єкти баз даних можна скопіювати і перенести з однієї бази даних в іншу, а потім синхронізувати ці бази даних для забезпечення узгодженості. Завдяки реплікації дані можна розміщувати в різних місцях, забезпечуючи можливість доступу до них віддалених і мобільних користувачів по локальних або глобальних мережах, за допомогою комутованих та бездротових з'єднань, а також через Інтернет.
Служби Reporting Services пропонують засоби створення корпоративних звітів з підтримкою веб-інтерфейсу, які дозволяють включати в звіти дані з різних джерел, публікувати звіти у різноманітних форматах, а також централізовано керувати безпекою і підписками.
Служби Notification Services представляють собою середовище розробки і розгортання додатків, які формують і відправляють повідомлення. C допомогою цих служб можна створювати і своєчасно відправляти індивідуальні повідомлення тисячам чи навіть мільйонам передплатників. При цьому можлива доставка на різні пристрої.
Компонент Service Broker покликаний допомогти розробникам у створенні безпечних масштабованих додатків баз даних. Це нова технологія компонента Database Engine надає платформу для взаємодії на основі обміну повідомленнями, завдяки якій незалежні компоненти додатків можуть діяти як єдине ціле. У компонент Service Broker включена інфраструктура асинхронного програмування, яка може використовуватися як додатками в межах однієї бази даних чи примірника, так і розподіленими додатками.
Компонент Full-Text Search дозволяє виконувати повнотекстові запити до простих символьним даними, що зберігаються в таблицях SQL Server. Повнотекстові запити можуть включати слова і фрази або кілька форм слів і фраз.
Служба Analysis Services, інтелектуальний аналіз даних
Служби Microsoft SQL Server Analysis Services містять функції та засоби для створення складних рішень з інтелектуального аналізу даних.
Набір стандартних алгоритмів інтелектуального аналізу даних.
Конструктор інтелектуального аналізу даних, що призначений для створення і перегляду моделей інтелектуального аналізу даних, для керування моделями та для складання прогнозів за допомогою цих моделей.
Мова розширень інтелектуального аналізу даних, який можна використовувати для керування моделями інтелектуального аналізу даних і для створення складних прогнозують запитів.
Для виявлення в даних закономірностей і тенденцій можна застосовувати поєднання цих функцій і засобів, а потім використовувати знайдені закономірності і тенденції для прийняття обгрунтованих рішень щодо складних бізнес-завдань.
Архітектура служб Analysis Services
Служби Microsoft SQL Server 2005 Analysis Services (SSAS) використовують як серверні, так і клієнтські компоненти для надання додаткам бізнес-аналітики функцій оперативної аналітичної обробки (OLAP) і інтелектуального аналізу даних:
Серверний компонент служб Analysis Services реалізований у вигляді служби Microsoft Windows. Служби SQL Server 2005 Analysis Services підтримують роботу декількох екземплярів на одному комп'ютері, при цьому кожен примірник служб Analysis Services реалізований як окремий екземпляр служби Windows.
Клієнти спілкуються зі службами Analysis Services, які розглядаються як веб-служба, за допомогою загальнодоступного стандарту XML для аналітики (XMLA) - протоколу, заснованого на SOAP, для виконання команд і прийняття відповідей. Моделі клієнтських об'єктів також надаються через XMLA, і отримати доступ до них можна за допомогою керованого постачальника, наприклад ADOMD.NET, або за допомогою власних постачальників даних OLE DB.
Команди пошуку можуть виконуватися за допомогою таких мов: SQL; багатовимірних виразів - мови запитів галузевого стандарту, орієнтованого на аналіз; розширень інтелектуального аналізу даних - мови запитів галузевого стандарту, орієнтованого на інтелектуальний аналіз даних. Також мова сценаріїв служб Analysis Services (ASSL) можна використовувати для керування об'єктами бази даних служб Analysis Services.
Data Mining
Data Mining - сучасна технологія аналізу інформації з метою знаходження в накопичених даних раніше невідомих, нетривіальних і практично корисних знань, необхідних для прийняття оптимальних рішень в різних галузях людської діяльності. Це досить молода технологія (їй менше 20 років), ефективні алгоритми якої були розроблені в результаті дослідження баз даних, при використанні комбінацій давно відомих методів статистики й теорії імовірності.
Найбільш типові приклади використання технології Data Mining:
пошук прибуткових клієнтів;
розуміння потреб користувачів;
попередження зміни клієнтів;
прогноз продажів;
побудова ефективних маркетингових кампаній;
виявлення і запобігання шахрайства;
виправлення даних у процесі їх зберігання.
Microsoft SQL Server 2005 надає інтегроване середовище для створення моделей Data Mining і роботи з ними. Процесу інтелектуального аналізу даних засобами Data Mining наведено на рис.2.
Рис2.
Процесу інтелектуального аналізу даних
засобами Data Mining
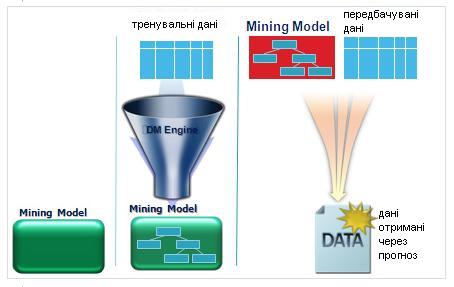
Кроки процеси інтелектуального аналізу даних засобами Data Mining:
Створюємо Data Mining модель(далі модель даних) з використанням певного алгоритму, налаштована на деяку вхідну вибірку даних.
За допомогою деяких тренувальних даних (у яких відомі як вихідні атрибути, так і ті атрибути, які ми збираємось передбачати в майбутньому) виконуємо навчання нашої моделі.
Після навчання на вхід моделі можна подавати передбачувані дані (у яких атрибути невідомі, тобто їх значення ми збираємося передбачити); в результаті роботи алгоритму будуть з певною вірогідністю передбачені невідомі атрибути.
Створення DM-моделі даних може здійснюватися з використанням інструментів: Business Intelligence Development Studio, Microsoft Excel, Microsoft Visio, SQL Server Management Studio. SQL Server підтримує побудову моделей даних як на реляційних, так і на OLAP-джерелах даних.
Рис 3. Створення моделі Data Mining
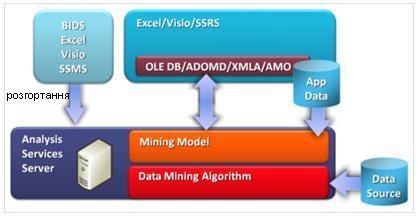
Використання (відображення) результатів роботи моделей даних може здійснюватися з використанням Microsoft Excel, Microsoft Visio, SQL Server Reporting Services тобто через засоби OLE DB, ADOMD, XMLA, AMO.
Після створення моделі можна провести її аналіз на предмет виявлення цікавих для нас шаблонів і правил. У залежності від застосовуваного алгоритму в середовищі розробки використовується різні представлення перегляду моделі.
Оскільки найчастіше проект містить кілька моделей Data Mining, попередньо створених на основі наших припущень, то виникає задача визначення найбільш адекватної з них. Для вирішення цього завдання в редакторі присутній засіб порівняння моделей Mining Accuracy Chart. З використанням цього інструменту можна передбачити точність моделі і вибрати кращу з них.
Для створення прогнозів використовується мова Data Mining Extensions (DMX), який є розширенням SQL і містить команди для створення, зміни та здійснення прогнозів на підставі різних моделей. Створення таких прогнозів може бути складним завданням, тому в редакторі присутній інструмент під назвою Prediction Query Builder, яких представляє собою візуальний засіб створення DMX-запитів.
Крім інструментарію для роботи з моделями, не менш значущими є і способи створення моделей. Ключовим моментом створення моделі є вибір алгоритму аналізу даних. SQL Server 2005 Analysis Services включає в себе наступні дев'ять алгоритмів:
Дерево рішень (Microsoft Decision Trees)
Кластеризація (Microsoft Clustering)
"Наївний" (Спрощений) Баєс (Microsoft Naive Bayes)
Кластеризація послідовностей (Microsoft Sequence Clustering)
Часові ряди (Microsoft Time Series)
Асоціативні правила (Microsoft Association)
Нейронна мережа (Microsoft Neural Network)
Лінійна регресія (Microsoft Linear Regression)
Логістична регресія (Microsoft Logistic Regression)
Використовуючи комбінацію цих алгоритмів можна створювати рішення для більшої частини завдань з виявлення прихованих закономірностей у великих обсягах даних.
Алгоритми інтелектуального аналізу данних
Дерево рішень - Microsoft Decision Trees
Алгоритм "Дерево рішень" призначений для вирішення задач класифікації і регресії і добре підходить для прогнозування. В алгоритмі Microsoft Decision Trees використовуються як дискретні, так і безперервні атрибути.
У процесі побудови моделі алгоритм ітеративно обчислює ступінь впливу кожного вхідного атрибуту моделі на значення вихідного атрибуту і використовує атрибут, що впливає на вихідну змінну найбільшою мірою для розбиття вузла дерева рішень. Вузол верхнього рівня описує розподіл значень вихідного атрибуту за всієї сукупності даних. Кожен наступний вузол описується розподілом вихідного атрибута при дотриманні умов на вхідні атрибути, відповідні цього вузла. Модель продовжує рости до тих пір, поки розбиття вузла на наступні вузли збільшує ймовірність того, що вихідний атрибут буде приймати якесь певне значення в порівнянні з усіма іншими значеннями, тобто розбиття збільшує якість прогнозу. Алгоритм здійснює пошук атрибутів і їх значень, розбиття по яких дозволяє з більшою ймовірністю правильно передбачити значення вихідної атрибуту.
Кластеризація - Microsoft Clustering
Алгоритм кластеризації використовує ітеративний метод угрупування записів набору даних у кластери, що володіють подібними характеристиками. Використовуючи розбивка на кластери можна виявити в досліджуваному масиві даних такі зв'язки, які неможливо виявити простим переглядом цих даних. Крім того, за допомогою алгоритмів кластеризації можна здійснювати прогнозування. Наприклад, об'єднати в групу людей, які живуть в одному районі, водять одну марку машин, мають схожі переваги в їжі і купують один тип продукції. Таке об'єднання і є кластер. Другий кластер може включати в себе людей, які відвідують один ресторан, що мають один рівень доходу і їздять двічі на рік у відпустку в інші країни. Оцінюючи розподіл даних у цих кластерах, можна краще зрозуміти взаємозв'язки різних характеристик досліджуваних об'єктів, а також як ці взаємозв'язки впливають на значення прогнозованого атрибуту.
У Microsoft Analysis Services 2005 для кластеризації використовується модифікації алгоритмів максимізації очікування (Expectation Maximization) і K-найближчих сусідів (K-Means).
У першому випадку кожен кластер характеризується своєю функцією розподілу атрибутів вхідних даних, які обчислюються в ході ітеративного процесу. У процесі виконання алгоритму ітеративно максимізується функція правдоподібності на просторі параметрів функцій розподілу для кожного кластеру. При цьому передбачається, що безперервні атрибути мають спільне багатовимірне нормальний розподіл, а дискретні - спільне дискретне розподіл.
У другому випадку ітеративно мінімізується сума квадратів відстаней (у різних метриках) від кожного елемента даних до центру відповідного кластеру.
Наївний алгоритм Байеса - Microsoft Naive Bayes
Цей алгоритм призначений для вирішення задач класифікації та прогнозування. У процесі його реалізації обчислюються ймовірності станів вхідних атрибутів для кожного стану вихідного атрибуту. Ці значення використовуються для обчислення ймовірності того, що вихідний атрибут приймає той чи інший стан при заданих значеннях вхідних атрибутів. Алгоритм приймає тільки дискретні або дискретизовані атрибути моделі, а також виходить з припущення про стохастичною незалежності вхідних атрибутів ( "наївність" алгоритму якраз обумовлена цими припущеннями). Алгоритм Microsoft Naive Bayes являє собою просту модель для аналізу даних, яку можна розглядати як засіб початкового розвідувального аналізу. Внаслідок того, що більшість необхідної для побудови моделі інформації обчислюється в процесі обробки відповідного куба, результати алгоритму Байеса повертаються дуже швидко. Це є ще однією перевагою використання алгоритму в якості оптимального розвідувального механізму для класифікації та прогнозування.