

Insert @tree ([name], id, parent, [level], [order])
select Data, Id, Parent, 0, Data from T where Data=@root;
-- Заполняем поле для упорядочивания
SET @order=@root;
END -- IF
ELSE
BEGIN
SET @order=@order+'::'+@root;
select @id=Id from T where Data=@root;
END
-- Узнаём уникальный идентификатор обрабатываемого узла
select @id=Id from T where Data=@root;
-- Выбираем непосредственных потомков
-- Объявляем курсор
declare c1 cursor
keyset
for select Id, Parent, Data FROM T WHERE Parent=@Id;
-- Открыли курсор
open c1
-- Выбрали первого потомка
fetch next from c1 into @id, @parent, @data;
while (@@fetch_status <> -1)
-- Пока не закончились непосредственные потомки...
begin
Insert @tree ([name], id, parent, [level], [order])
VALUES
(@data, @id, @parent, @level+1, @order+'::'+@data);
-- Рекурсивный вызов функции
Insert @tree ([name], id, parent, [level], [order])
SELECT * FROM MyGetTree(@data, @order, @level+1);
-- Очередной потомок
fetch next from c1 into @id, @parent, @data;
end
deallocate c1;
return
end
При помощи этой функции получим поддерево, начинающееся с узла B:
select * from MyGetTree('B', '', 0) ORDER BY [order];
Результат выполнения этого запроса представлен на рис. 27.
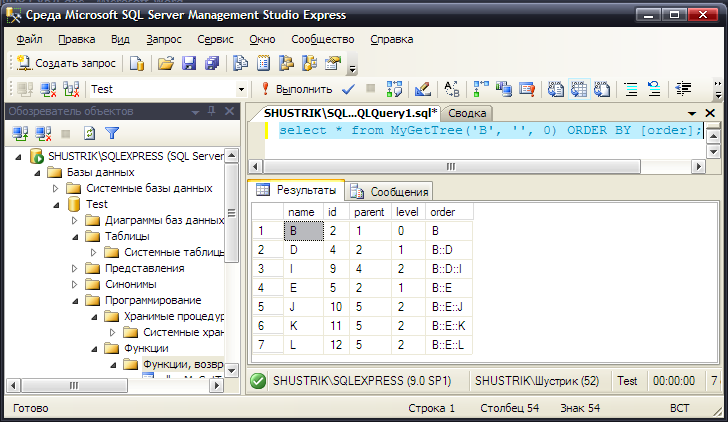
Рис. 27. Поддерево, начинающееся с узла B
Использование курсоров существенно снижает производительность. Более универсальным будет вариант, использующий цикл (любую рекурсию можно превратить в итерацию и наоборот). Приведём пример функции, основанной на использовании вместо рекурсии итерации:
CREATE FUNCTION MyGetTree(@root varchar(1))
RETURNS @tree TABLE
(
[name] varchar,
id int,
parent int,
[level] int,
[order] varchar(4096)
)
AS
BEGIN
-- ВНИМАНИЕ!
-- В реальной функции необходимо проверить законность
-- входных параметров.
-- После каждой операции необходима проверка
-- наличия ошибок, отсутствующая в данном примере!
declare @level int set @level=0;
-- Записываем в таблицу информацию о
-- корневом узле выбираемого поддерева.
Insert @tree ([name], id, parent, [level], [order])
select Data, Id, Parent, @level, Data from T where
Data=@root;
while 1=1
begin
Insert @tree ([name], id, parent, [level], [order])
select T.Data, T.ID, T.Parent, @level+1, R.[order]+'::'+T.Data
from T
join @tree AS R on R.id=T.Parent and R.[level]=@level
and
T.Id<>T.Parent;
if @@rowcount=0 break;
select @level=@level+1;
end -- while
return
END
С помощью этой функции можно получить другое описание иерархии, например, с помощью оператора SELECT (рис. 28):
select * from MyGetTree('A') ORDER BY [order];
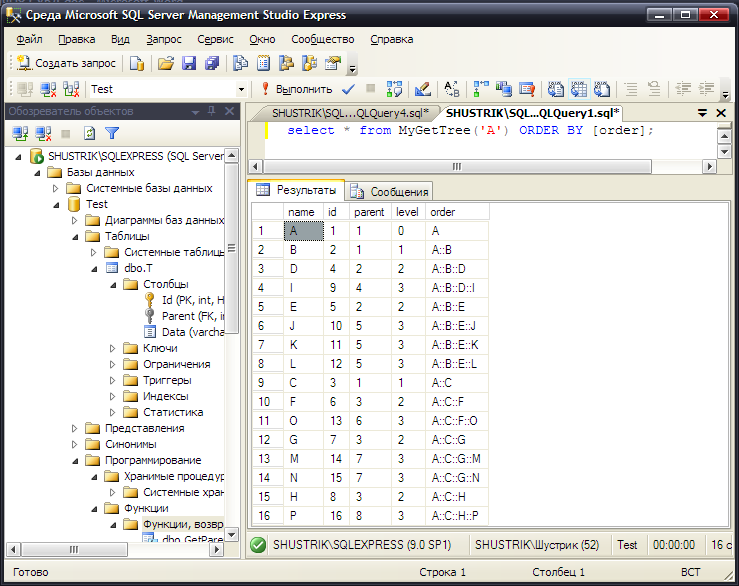
Рис. 28. Получаем полное описание иерархии
Другое, почти визуальное представление иерархии можно получить при помощи этой функции и следующего запроса (рис. 29):
SELECT REPLICATE (' |----- ', level) + [name] AS Tree
FROM MyGetTree('A') ORDER BY [order];
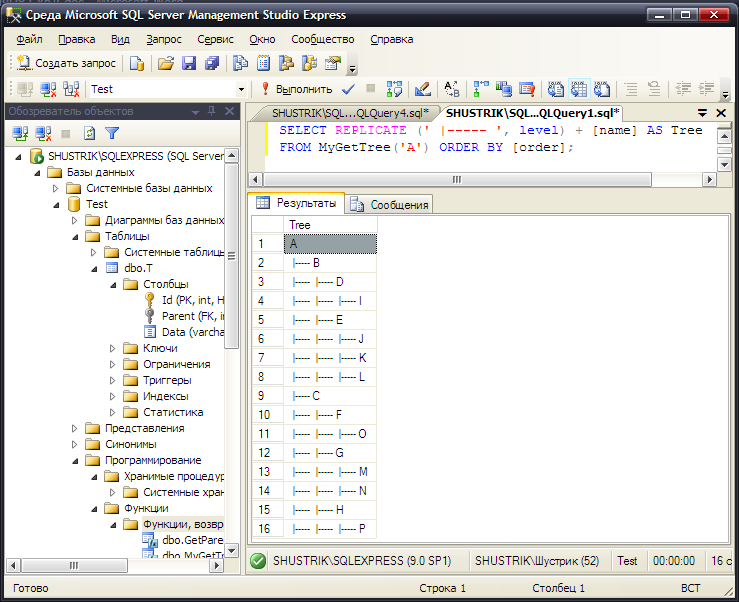

Рис. 29. Визуализация иерархии средствами SQL
Сравните полученный результат с представлением иерархии на рис. 6.
Обратите внимание. Между уровнем модели данных и уровнем визуального представления данных в приложении нет жёсткой связи. Не стремитесь к тому, чтобы структура данных каким-то образом полностью соответствовала интерфейсу программы. Обычно это тупиковый путь. Важно правильно спроектировать структуры данных, а как данные отображать – задача конкретного приложения. Одни и те же данные, хранимые в базе, могут использоваться различными приложениями с существенно различающимися интерфейсами. Структура базы и визуальный интерфейс единственно не должны друг другу противоречить.
На практике встречаются задачи, требующие упорядочения узлов одного предка и находящихся на одном уровне. Для решения таких задач расширим базовую таблицу, добавив столбец ORDER. Значения этого столбца задают порядок следования элементов с общим родителем в пределах одного уровня. Для случая нескольких вариантов сортировок можно ввести несколько аналогичных столбцов. Другим, неявным, способом задания номера потомка может быть установка ссылки, например, на «предыдущего брата».
Добавление и удаление листьев в дереве в рассматриваемой модели трудности не представляет. Проделайте эти операции самостоятельно.
Добавление поддерева сводится к последовательному добавлению листьев.
Удаление поддерева может быть реализовано на основе функции для получения узлов поддерева. Удалим, например, поддерево с корнем в узле H следующим образом:
DELETE FROM T WHERE Id IN (
SELECT Id FROM MyGetTree('H'));
и проверим результат выполнения запроса, выведя всё дерево, начиная с корня.
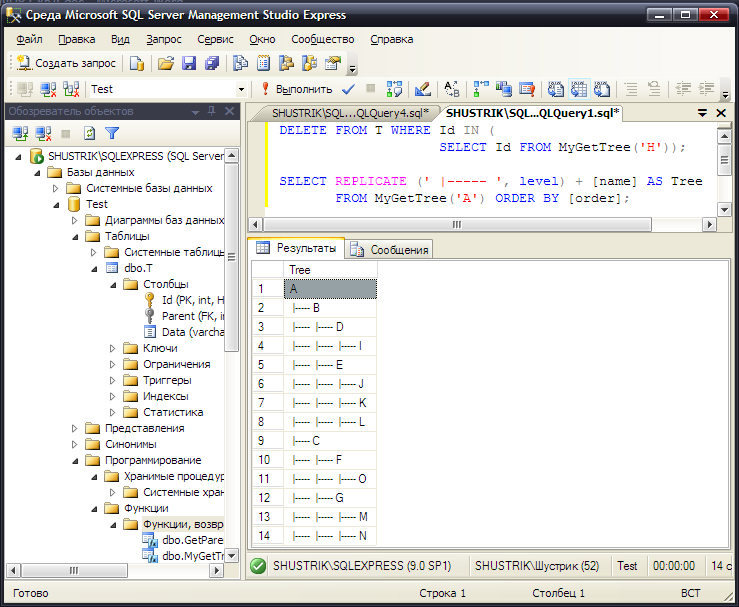
Рис. 30. Проверка выполнения операции удаления поддерева
Сравните результаты выполнения запроса, представленные на рис. 29 и рис. 30.
Более сложная задача – удаление единственного узла, имеющего потомков. При удалении такого узла требуется принять решение, какой элемент нужно назначить корневым для «отрывающегося» набора узлов (обычно решение этого вопроса определяется из свойств предметной области). Например, при удалении узла E узлы J, K, L лишаются корневого элемента поддерева и «отрываются» от иерархии (рис. 31).
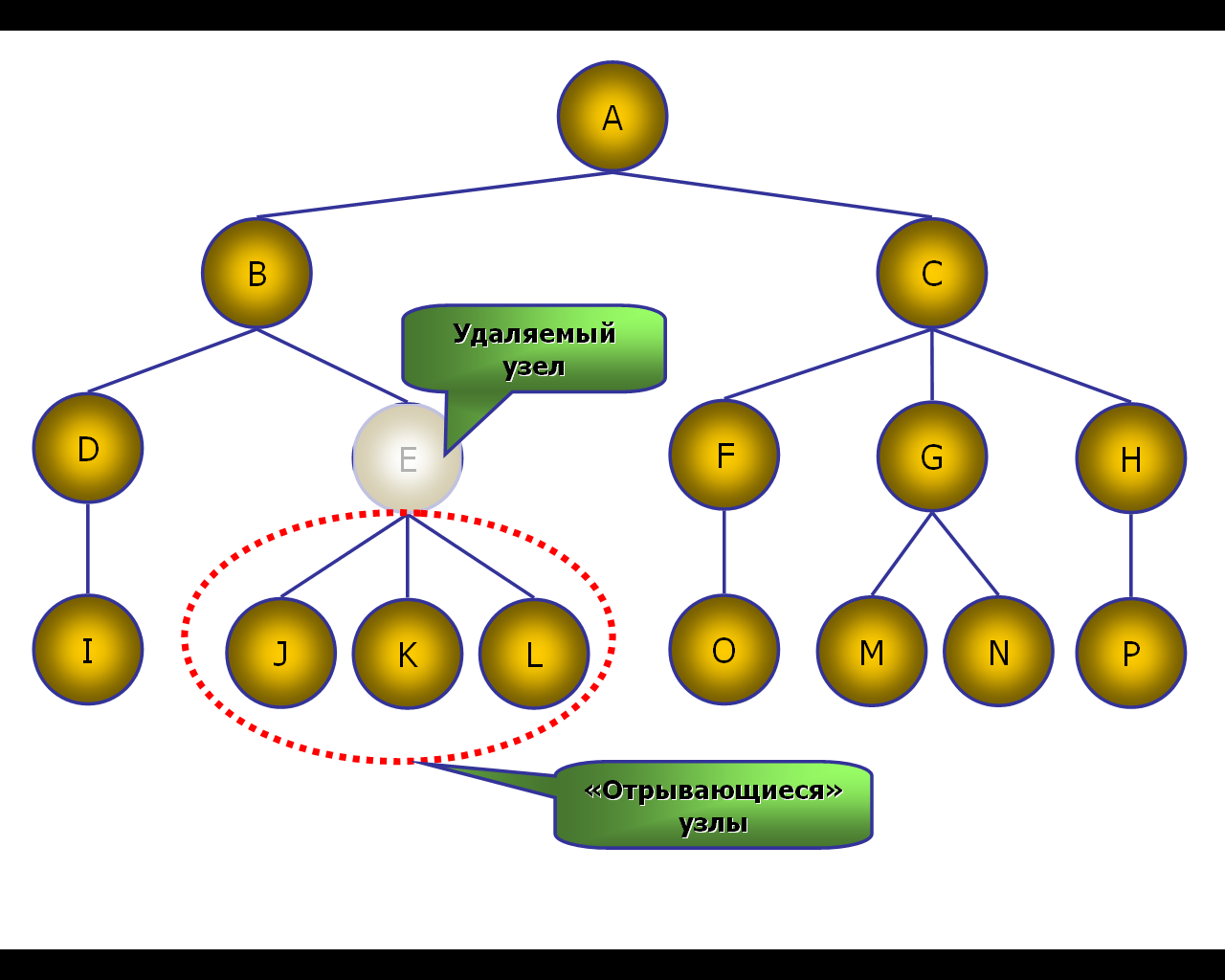
Рис. 31. Последствия удаления узла, имеющего потомков
Чаще всего для каждого непосредственного потомка удаляемого узла, остающегося в составе структуры иерархии, надо изменить значение указателя на удаляемого предка на указатель на непосредственного предка этого предка. Например, при исключении узла E, значение предка для узлов J, K, L должно быть установлено таким образом, чтобы оно указывало на узел B (рис. 32).
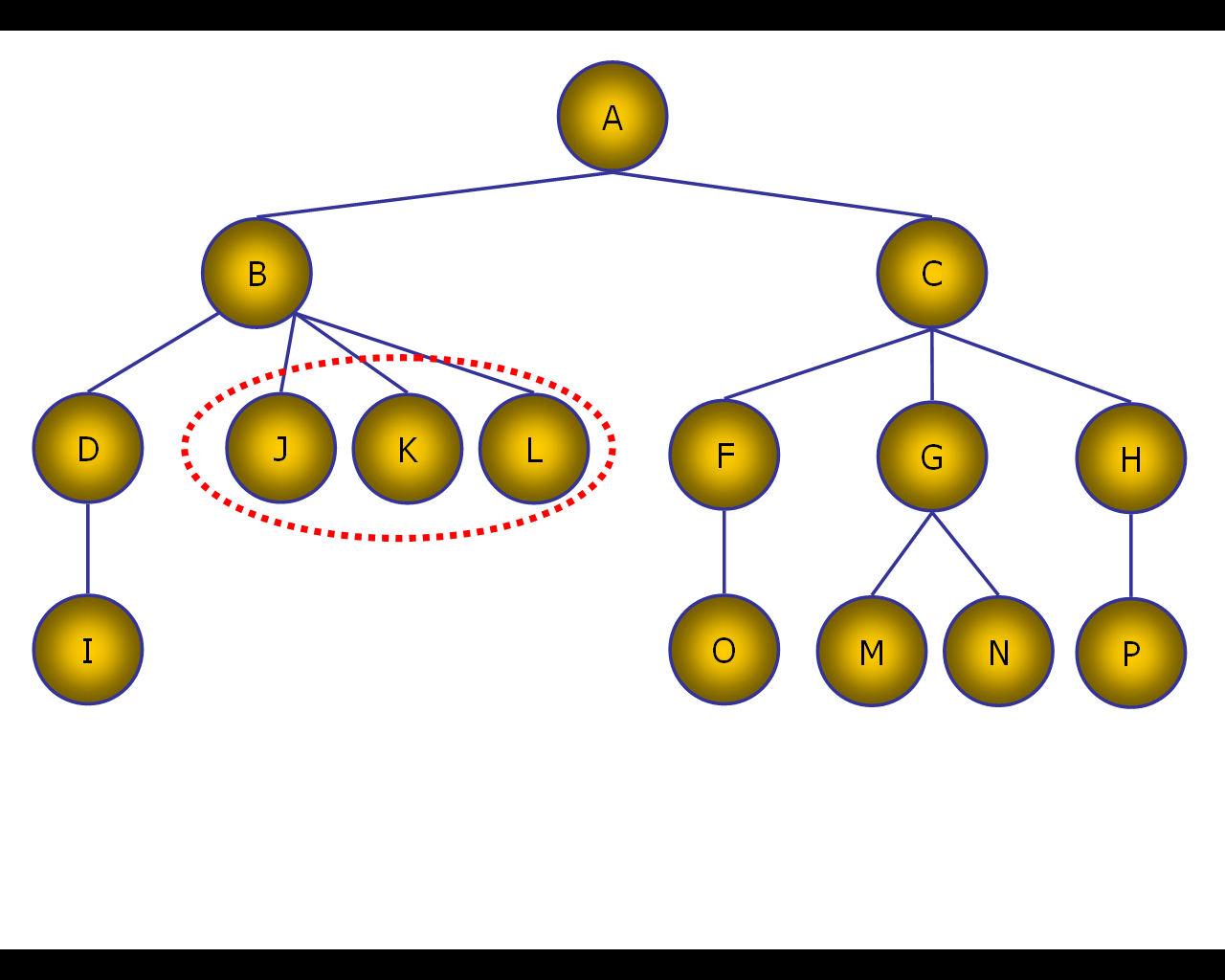
Рис. 32. Присоединение «оторвавшихся» узлов к ближайшему предку
После этого запись для узла E может быть удалена из таблицы. Реализуем эти действия при помощи хранимой процедуры:
CREATE PROCEDURE DelNode (@Node VARCHAR) AS
BEGIN
-- ВНИМАНИЕ! В реальной процедуре нужно проверить
-- корректность переданных при вызове параметров.
-- После каждой операции необходима проверка наличия
-- ошибок, отсутствующая в данном примере!
DECLARE @Parent int;
DECLARE @Id int;
-- По имени получаем уникальный идентификатор
-- удаляемого узла и
-- уникальный идентификатор его непосредственного предка.
SELECT @Id=Id, @Parent=Parent FROM T Where Data=@Node;
-- Заменяем указатель на родительский элемент
-- (переподчиняем потомков удаляемого узла
-- его родительскому узлу)
UPDATE T SET Parent=@Parent WHERE Id IN (
SELECT Id FROM T WHERE Parent=@Id);
-- Удаляем узел
DELETE FROM T WHERE Id=@Id;
END
Теперь проверим работу хранимой процедуры удалением узла E с последующим выводом структуры всего дерева.
EXEC DelNode 'E';
SELECT REPLICATE (' |----- ', level) + [name] AS Tree
FROM MyGetTree('A') ORDER BY [order];
Результат этих операций представлен на рис. 33.
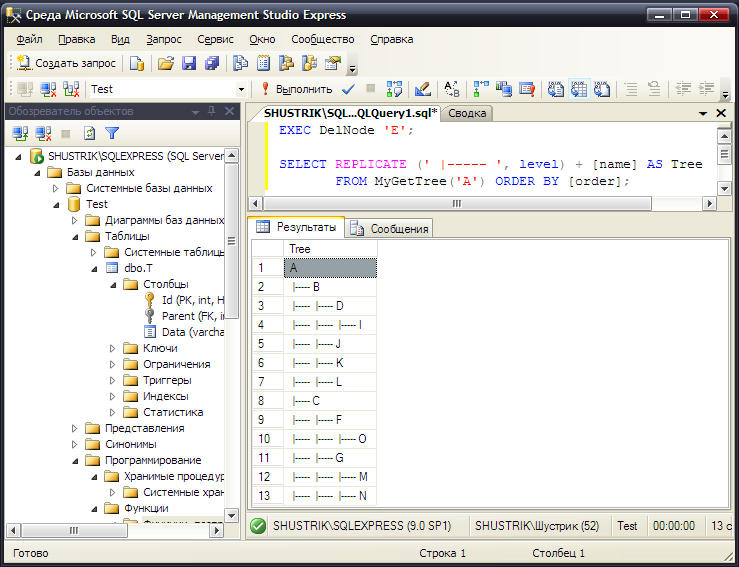
Рис. 33. Удаление единственного узла
Аналогично решается задача включения нового узла внутрь иерархии (рис. 34).
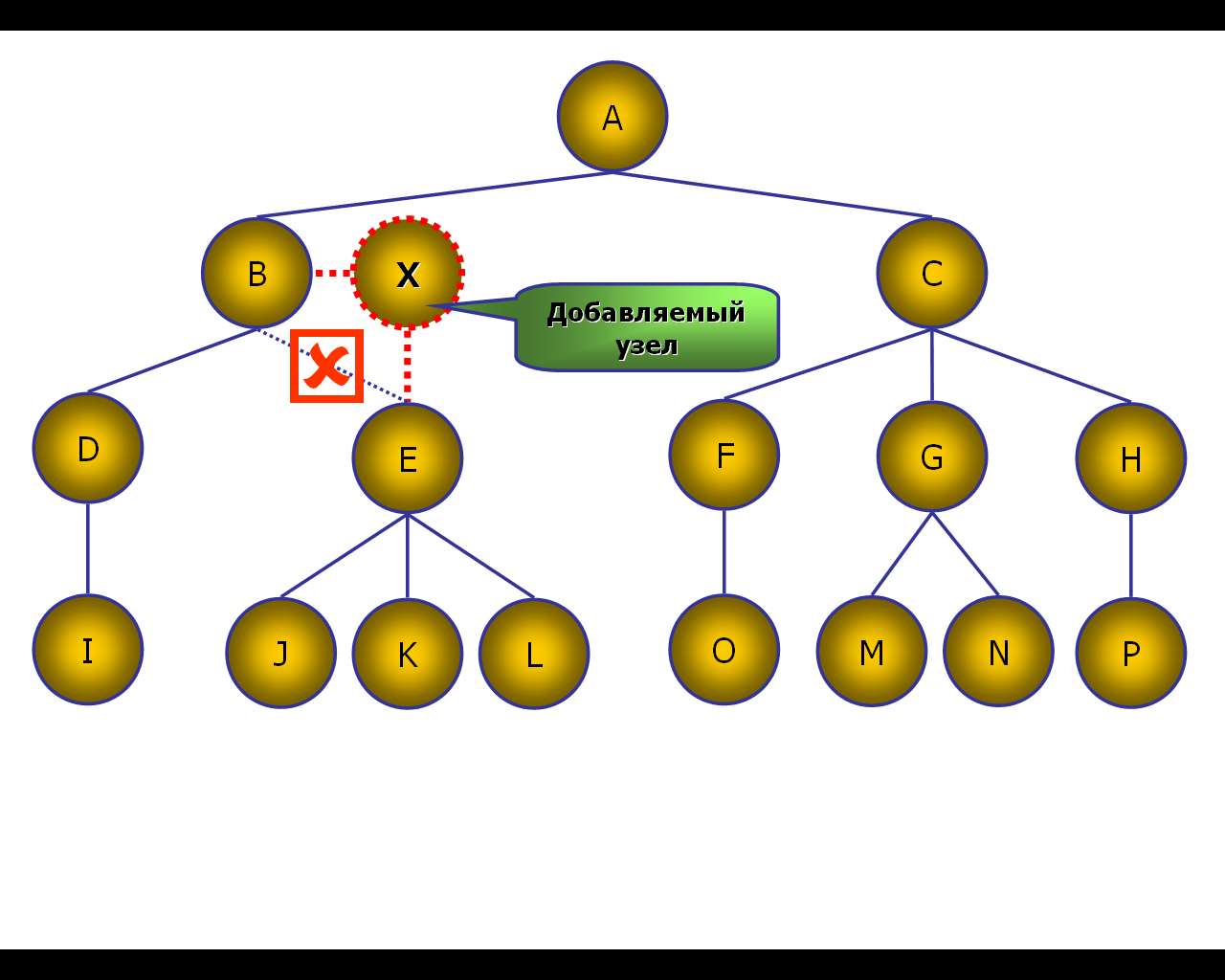
Рис. 34 Включение нового узла в иерархию
Для этого выполняем следующие действия:
добавляем новый узел как лист;
присоединяем к нему узлы – потомки, заменяя связи узлов, становящихся потомками вновь добавленного узла с их старым корнем.
В данной структуре информация о полном пути и уровне элемента в иерархии явно нигде не хранится. Из-за этого возникают сложности при формировании полного пути в дереве и вычислении уровня в иерархии, на котором находится элемент. Для решения этой проблемы можно дополнить структуру таблицы столбцом, в котором будет храниться значение уровня текущего элемента в дереве. Описание таблицы тогда будет выглядеть следующим образом:
Таблица 2
Усовершенствованная модель иерархии
Уникальный идентификатор узла |
Указатель на непосредственного предка узла |
Уровень узла в иерархии |
Содержательная часть |
A |
A или NULL |
1 |
A |
B |
A |
2 |
B |
C |
A |
2 |
C |
D |
B |
3 |
D |
E |
B |
3 |
E |
F |
C |
3 |
F |
G |
C |
3 |
G |
H |
C |
3 |
H |
I |
D |
4 |
I |
J |
E |
4 |
J |
K |
E |
4 |
K |
L |
E |
4 |
L |
O |
F |
4 |
O |
M |
G |
4 |
M |
N |
G |
4 |
N |
P |
H |
4 |
P |
Таблица создаётся следующим SQL-предложением:
create table T (Id int not null identity primary key,
Parent int not null references T(Id),
[Level] int default 1 not null,
Data varchar);
В столбце Level хранятся числовые значения уровней узлов в дереве. По умолчанию значение уровня устанавливается равным 1. Поддержка корректности значений, вводимых в этот столбец, возлагается на триггер, назначаемый операции добавления записей в таблицу (INSERT) или, если триггер создать невозможно, на приложение. Для заполнения этого поля по идентификатору родительского элемента нужно определить его уровень и, нарастив на единицу, установить полученное значение для добавляемого узла.
CREATE TRIGGER AddNode
ON T
FOR INSERT
AS
BEGIN
-- ВНИМАНИЕ! В реальной процедуре нужно проверить
-- корректность переданных при вызове параметров.
-- После каждой операции необходима проверка наличия
-- ошибок, отсутствующая в данном примере!
DECLARE @Parent int;
DECLARE @Id int;
DECLARE @Level int;
-- Получаем вновь вставленную запись.
-- ВНИМАНИЕ! В реальном триггере нужно учесть,
-- что может быть добавлено несколько записей.
SELECT @Id=Id, @Parent=Parent, @Level=[Level] FROM inserted;
-- ВНИМАНИЕ! Идентификатор родительского узла
-- может быть не указан.
-- В реальном триггере следует предусмотреть
-- обработку этой ситуации.
-- Узнаём значение уровня родительского узла
SELECT @Level=[Level] FROM T WHERE Id=@Parent;
-- Устанавливаем правильное значение для уровня узла
UPDATE T SET [Level]=@Level+1 WHERE Id=@Id;
END
Проверим работу триггера добавлением записи в таблицу