

2.2. Способ правого и левого коэффициентов
Метод, предложенный Джо Селко, называемый ещё методом вложенных множеств, основан на полном обходе дерева (рис. 43). При полном обходе дерева каждому узлу назначается пара значений – левый и правый коэффициенты. Левые коэффициенты присваиваются во время движения от предка к потомку. Правые коэффициенты назначаются при движении от потомка к предку.
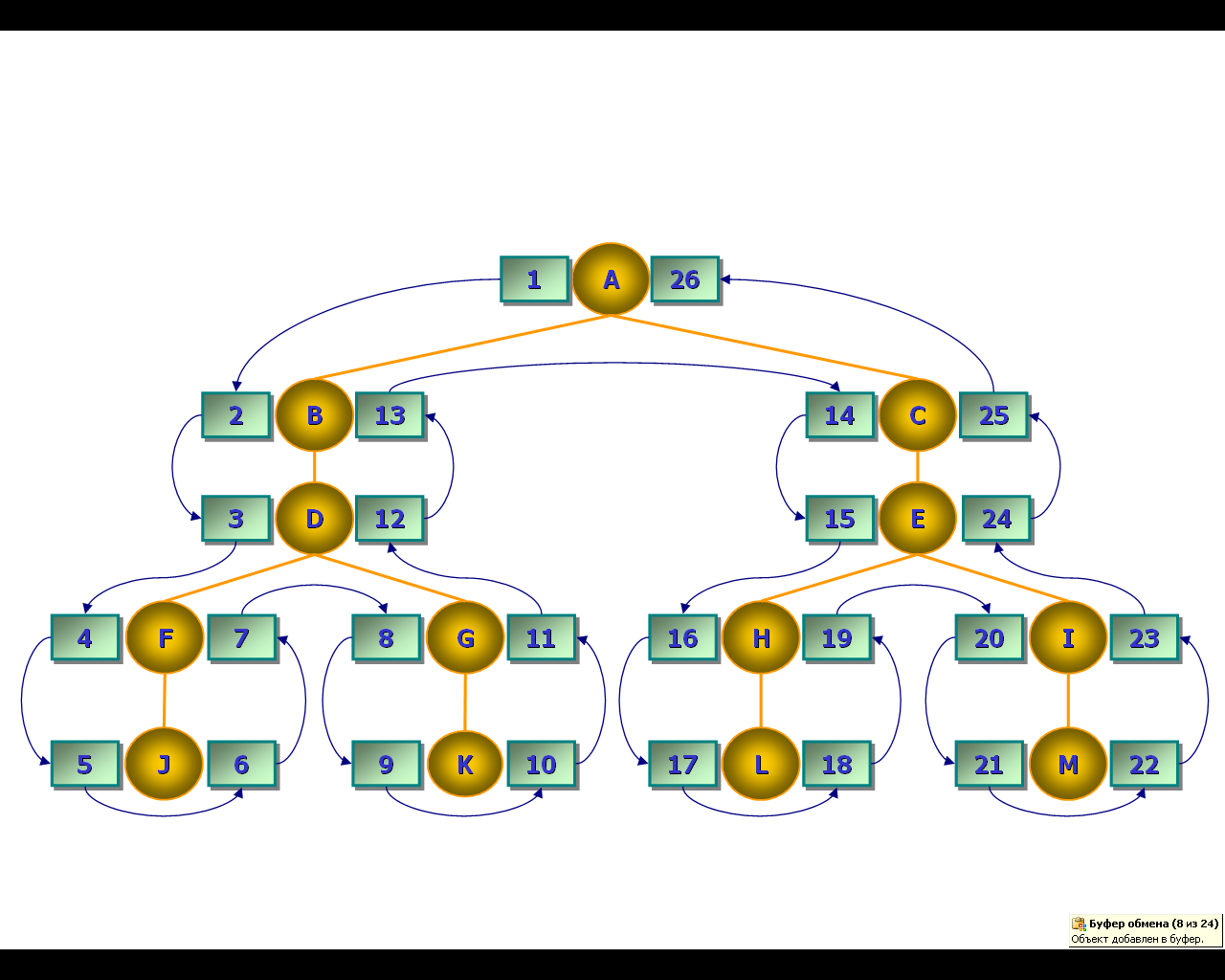
Рис. 43. Назначение коэффициентов при выполнении полного обхода дерева
Корень всегда имеет левый коэффициент, равный 1. Разность между значениями левого и правого коэффициентов для листьев всегда равна 1. Правый коэффициент для корня равен удвоенному числу узлов в иерархии (2n), так как при обходе мы должны посетить каждый узел дважды, один раз с левой стороны и один раз с правой стороны.
Отношение, соответствующее иерархии из нашего примера (см. рис. 43), выглядит следующим образом (Табл. 4).
Таблица 4
Модель иерархии на основе метода правого и левого коэффициентов
Значения левого коэффициента |
Содержательная часть данных узла |
Значения правого коэффициента |
1 |
A |
26 |
2 |
B |
13 |
3 |
D |
12 |
4 |
F |
7 |
5 |
J |
6 |
8 |
G |
11 |
9 |
K |
10 |
14 |
C |
25 |
15 |
E |
23 |
16 |
H |
19 |
17 |
L |
18 |
20 |
I |
23 |
21 |
M |
22 |
Организуемая таким образом структура данных может быть описана отношением, создаваемым следующим оператором SQL (рис. 44):
create table T (L int not null primary key,
Node varchar,
R int not null);
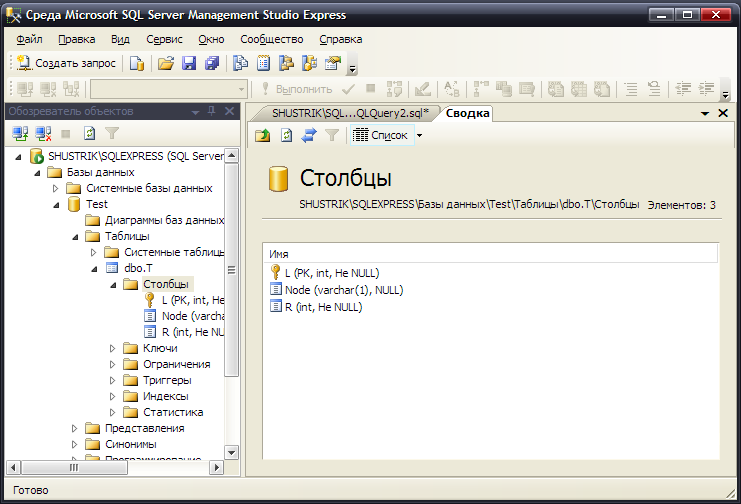
Рис. 44. Реализация модели иерархии методом правого и левого коэффициентов
Здесь L – это столбец левых коэффициентов, R – правых коэффициентов, а Node – содержательная информация об узле (здесь может располагаться несколько столбцов, хранящих содержательную часть узла). Роль уникального идентификатора узла исполняет левый коэффициент, объявленный первичным ключом. Также в качестве уникального идентификатора может быть выбран правый коэффициент или пара – левый и правый коэффициенты, взятые вместе.
Заполним созданную таблицу данными (рис. 45), соответствующими иерархии представленной на рис. 43, при помощи следующих предложений SQL:
INSERT INTO T (L, Node, R) VALUES ( 1, 'A', 26);
INSERT INTO T (L, Node, R) VALUES ( 2, 'B', 13);
INSERT INTO T (L, Node, R) VALUES ( 3, 'D', 12);
INSERT INTO T (L, Node, R) VALUES ( 4, 'F', 7);
INSERT INTO T (L, Node, R) VALUES ( 5, 'J', 6);
INSERT INTO T (L, Node, R) VALUES ( 8, 'G', 11);
INSERT INTO T (L, Node, R) VALUES ( 9, 'K', 10);
INSERT INTO T (L, Node, R) VALUES (14, 'C', 25);
INSERT INTO T (L, Node, R) VALUES (15, 'E', 23);
INSERT INTO T (L, Node, R) VALUES (16, 'H', 19);
INSERT INTO T (L, Node, R) VALUES (17, 'L', 18);
INSERT INTO T (L, Node, R) VALUES (20, 'I', 23);
INSERT INTO T (L, Node, R) VALUES (21, 'M', 22);
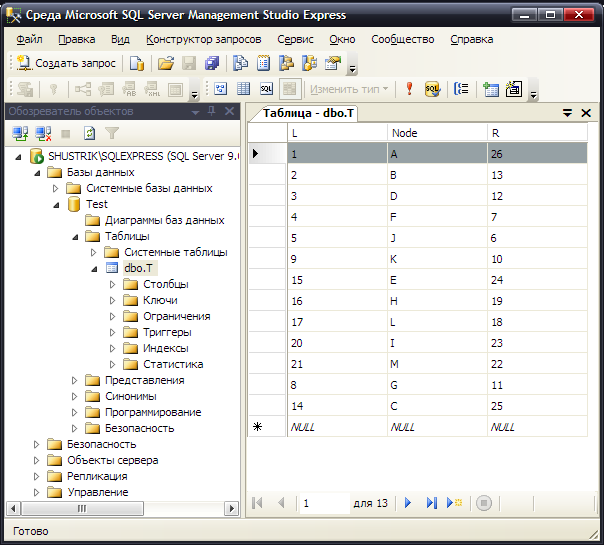
Рис. 45. Модель иерархии, представленной на рис. 8
При такой организации структуры данных для каждого элемента значения левого и правого коэффициентов его потомков заключены в интервале, определяемом значениями левого и правого коэффициентов родителя. Аналогично все родители некоторого элемента имеют значения левого коэффициента, меньшие значений левого коэффициента потомка и правого, большие правого коэффициента потомка. Отношения предок – потомок определяются из того, что значение L потомка всегда больше чем у предка, а R – меньше (рис. 46).

Рис. 46. Вложенность интервалов, определяемая значениями левых и правых коэффициентов узлов иерархии
Выбираем всех потомков для узла D (рис. 47):
SELECT * FROM T WHERE
L>(SELECT L FROM T WHERE Node='D') AND
R<(SELECT R FROM T WHERE Node='D');
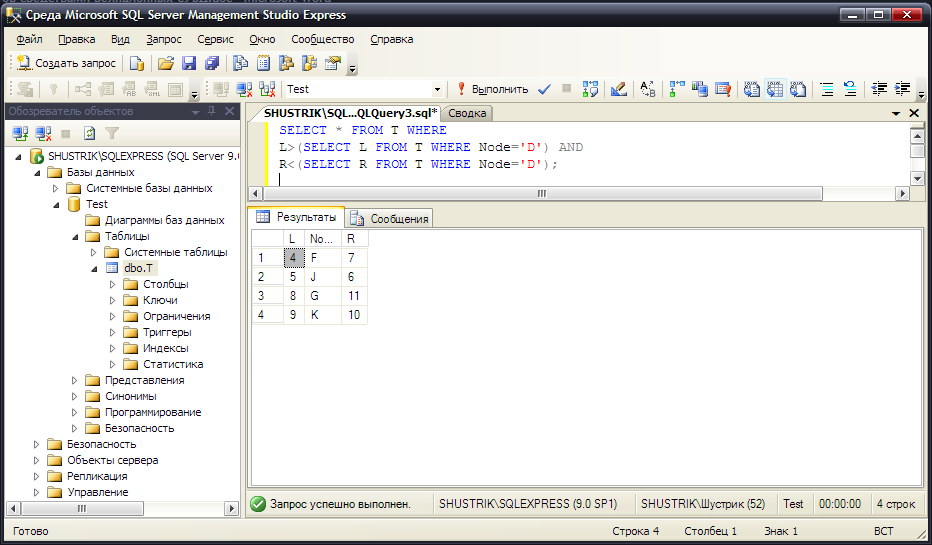
Рис. 47. Все потомки узла D
Получим всех предков узла D (рис. 48):
SELECT * FROM T WHERE
L<(SELECT L FROM T WHERE Node='D') AND
R>(SELECT R FROM T WHERE Node='D');
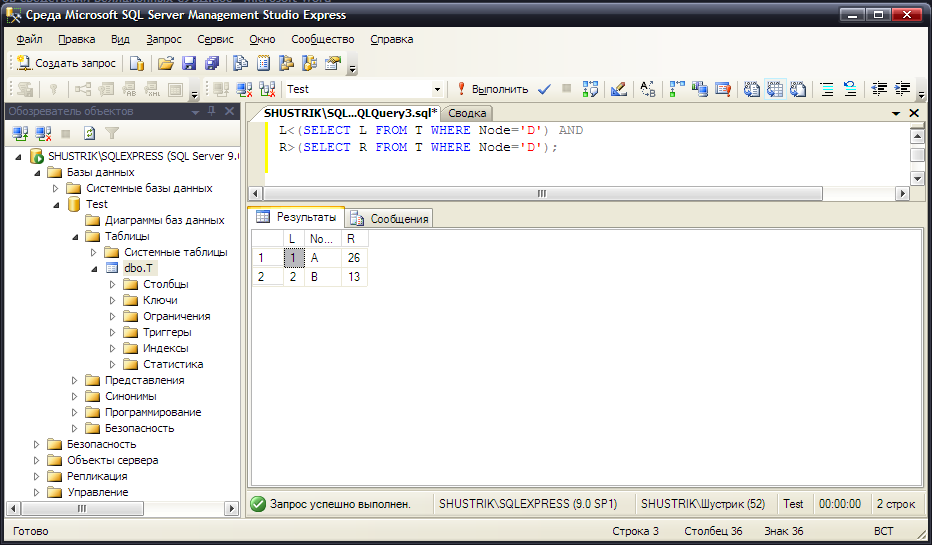
Рис. 48. Все предки узла D
Теперь воспользуемся предикатами BETWEEN, чтобы определить всех предков определенного узла. Для этого необходимо написать следующее предложение SQL (рис. 49):
SELECT 'D' AS Base,
B1.Node AS Parent,
(B1.R-B1.L) AS height
FROM T AS B1, T AS E1
WHERE E1.L BETWEEN B1.L AND B1.R AND
E1.R BETWEEN B1.L AND B1.R AND
E1.Node='D';
Чем больше значение height, тем дальше по иерархии узлы друг от друга.
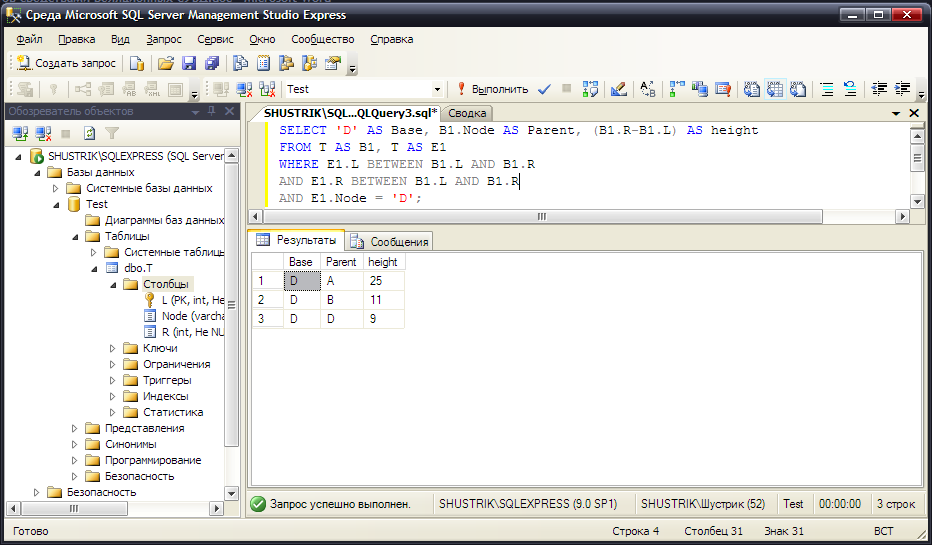
Рис. 49. Использование BETWEEN для нахождения всех предков узла D
Уровень в иерархии заданного элемента можно узнать, получив количество его предков и добавив 1.
Получим уровень в иерархии для узла D (рис. 50):
SELECT COUNT(Node)+1 AS Level FROM T WHERE
L<(SELECT L FROM T WHERE Node='D') AND
R>(SELECT R FROM T WHERE Node='D');
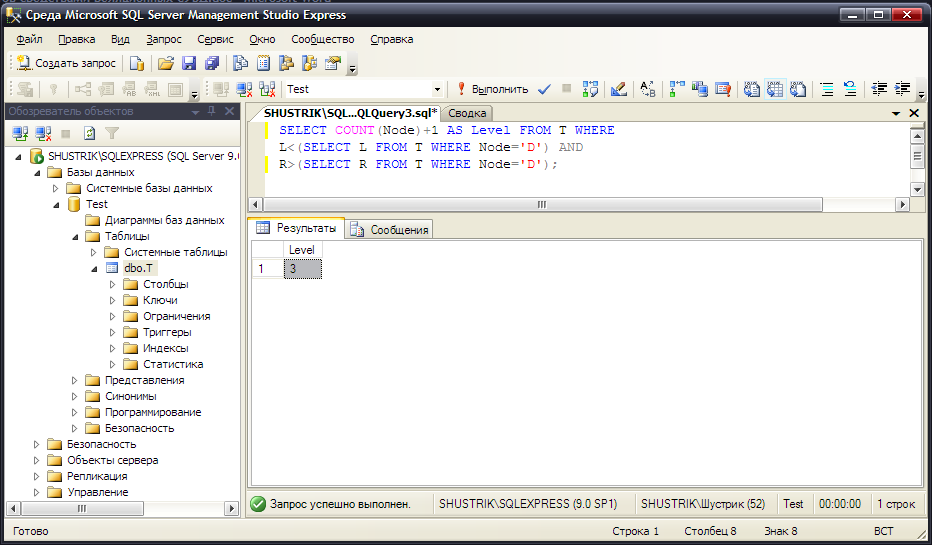
Рис. 50. Уровень узла D в иерархии
Уровень узла в иерархии, можно получить, используя предикат BETWEEN следующим образом (рис. 51):
SELECT COUNT(*) AS level FROM T AS B1, T AS E1 WHERE
E1.L BETWEEN B1.L AND B1.R AND
E1.R BETWEEN B1.L AND B1.R AND
E1.Node='D';
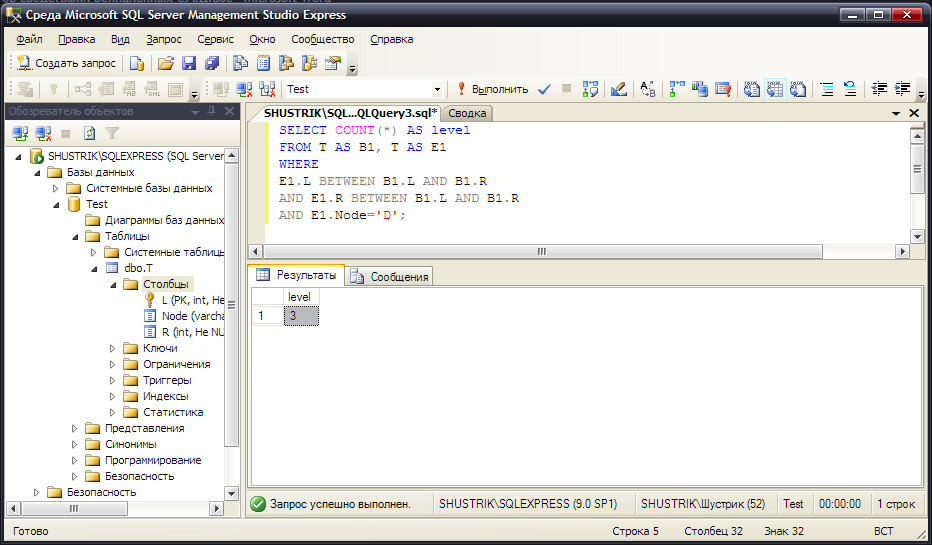
Рис. 51. Использование BETWEEN для определения уровня в иерархии
Для всех узлов в иерархии вычислим их уровни при помощи следующего запроса (рис. 52):
SELECT P2.Node, COUNT(*) AS level
FROM T AS P1, T AS P2
WHERE P2.L BETWEEN P1.L AND P1.R
GROUP BY P2.Node;
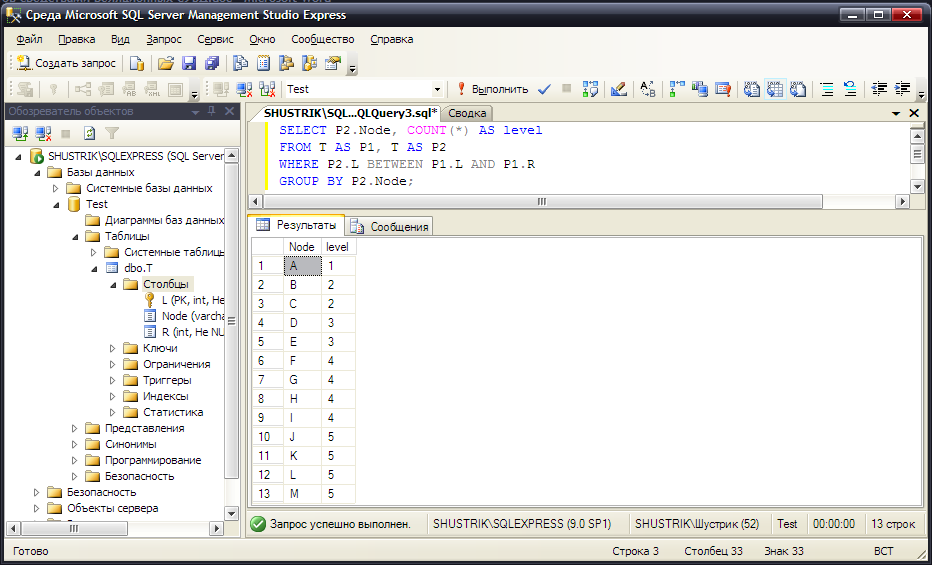
Рис. 52. Уровни всех узлов иерархии
Количество потомков можно определить как половину разности правого и левого коэффициентов (R-L)/2 (рис. 53)
SELECT (R-L)/2 AS Child FROM T WHERE Node='D';
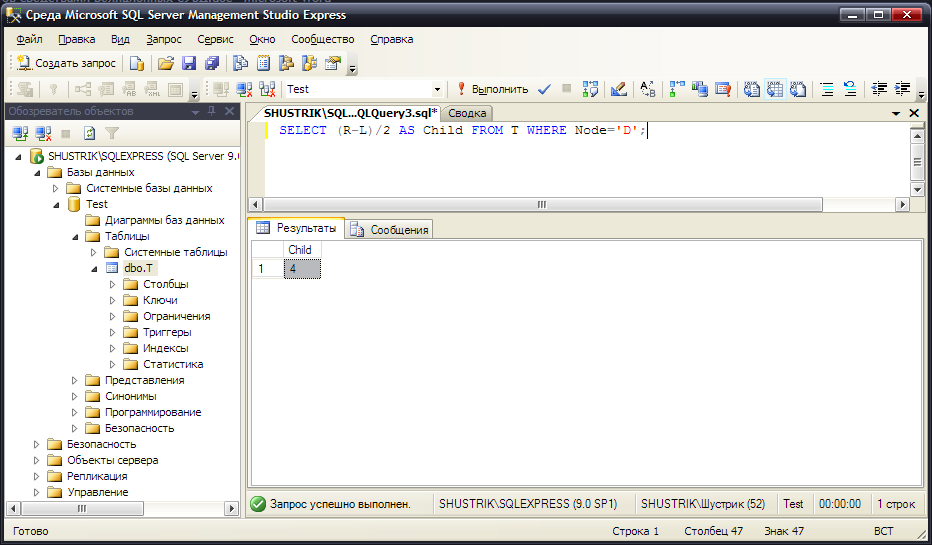
Рис. 53. Количество потомков узла D
Для элементов, не имеющих потомков, разность между значениями левого и правого коэффициентов всегда равна 1. Поэтому все листья можно найти следующим простым запросом (рис. 54):
SELECT * FROM T WHERE R-L=1;
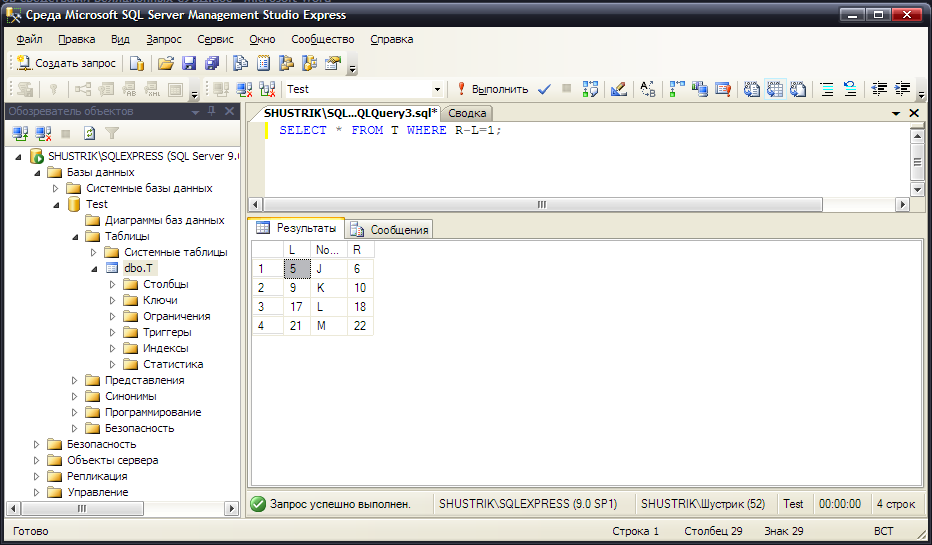
Рис. 54. Список листьев
Выполнение запроса можно ускорить за счёт использования уникального индекса по столбцу левых коэффициентов. Создадим индекс:
CREATE UNIQUE INDEX L1 ON T(L ASC);
Для того чтобы воспользоваться преимуществом индекса, запрос следует написать в виде
SELECT * FROM T WHERE L=(R-1);
Обратите внимание. MS SQL Server может применить индекс только в том случае, когда атрибуты, на которых этот индекс определён, не используются в выражениях, поэтому если записать условие в виде (R-L) = 1, то индекс использоваться не будет.
При данном способе моделирования иерархии некоторую трудность может создать задача определения всех непосредственных потомков для заданного узла. Для того чтобы выбрать всех непосредственных потомков заданного узла, нужно:
определить уровень этого заданного узла и нарастить полученное значение на единицу – это будет значение уровня в дереве для непосредственных потомков данного узла:
SELECT COUNT(*)+1 AS Level
FROM T AS B3, T AS E3
WHERE E3.L BETWEEN B3.L AND B3.R AND
E3.Node='D';
Результат выполнения этого предложения SQL в среде SQL Server Management Studio Express представлен на рис. 55.
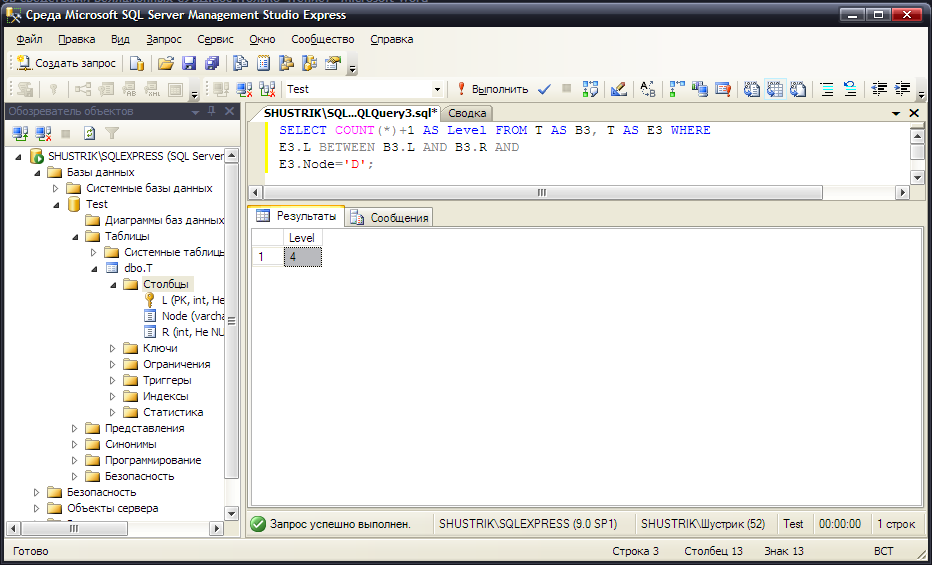
Рис. 55. значение уровня в дереве для непосредственных потомков узла D
выбрать узлы уровня, вычисленного на предыдущем шаге:
SELECT DISTINCT B1.Node FROM T AS B1, T AS E1 WHERE
(SELECT COUNT(*) FROM T AS B2, T AS E2 WHERE
E2.L BETWEEN B2.L AND B2.R AND E2.Node=B1.Node)=
(SELECT COUNT(*)+1 FROM T AS B3, T AS E3 WHERE
E3.L BETWEEN B3.L AND B3.R AND E3.Node='D');
Результат выполнения этого предложения SQL в среде SQL Server Management Studio Express представлен на рис. 56.
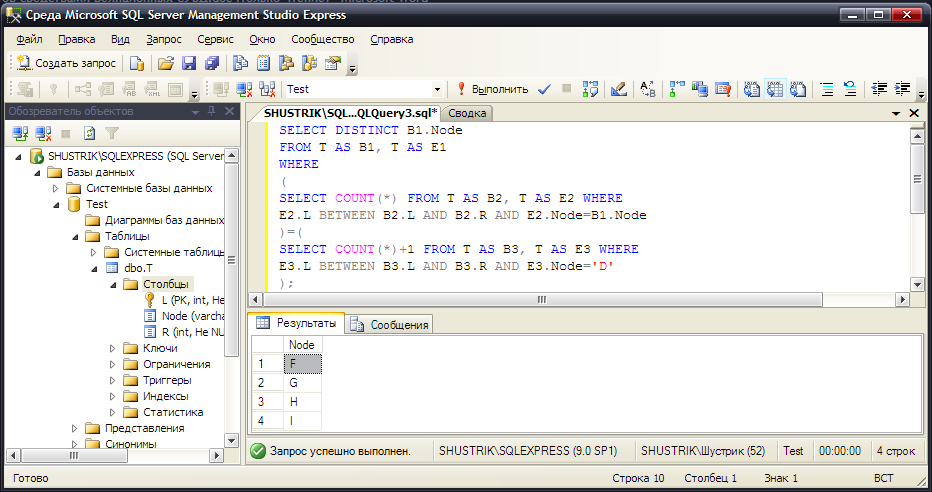
Рис. 56. Выбираем узлы 4-го уровня
Окончательно из полученного на предыдущем шаге списка узлов выбрать те узлы, которые имеют предком заданный узел:
SELECT B1.Node FROM T AS B1, T AS E1
WHERE (SELECT COUNT(*) FROM T AS B2, T AS E2 WHERE
E2.L BETWEEN B2.L AND B2.R AND E2.Node=B1.Node)=
(SELECT COUNT(*)+1 FROM T AS B3, T AS E3 WHERE
E3.L BETWEEN B3.L AND B3.R AND E3.Node='D') AND
B1.L BETWEEN E1.L AND E1.R AND E1.Node='D';
Результат выполнения этого предложения SQL в среде SQL Server Management Studio Express представлен на рис. 57.
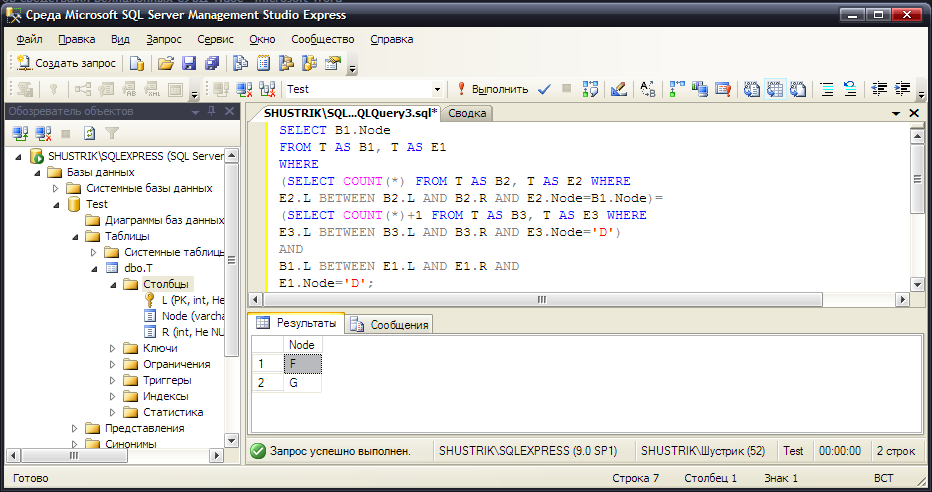
Рис. 57. Непосредственные потомки узла D
Аналогичным образом определяем непосредственного предка для заданного узла (в примере – для узла D):
FROM T AS B1, T AS E1 WHERE (SELECT COUNT(*) FROM T AS B2, T AS E2 WHERE
E2.L BETWEEN B2.L AND B2.R AND E2.Node=B1.Node)=
(SELECT COUNT(*)-1 FROM T AS B3, T AS E3 WHERE
E3.L BETWEEN B3.L AND B3.R AND E3.Node='D') AND
E1.L BETWEEN B1.L AND B1.R AND E1.Node='D';
Результат выполнения этого предложения SQL в среде SQL Server Management Studio Express представлен на рис. 58.
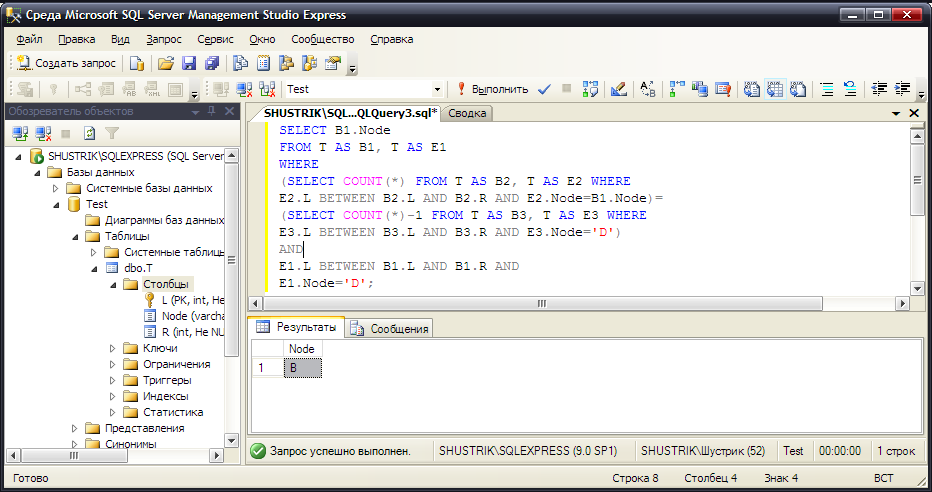
Рис. 58. Определён непосредственный предок узла D
Обратите внимание, что для первого непосредственного потомка значение левого коэффициента будет на единицу больше значения левого коэффициента родительского узла. Для второго – значение левого коэффициента будет на единицу больше значения правого коэффициента первого непосредственного потомка и т.д. Для последнего непосредственного потомка значение правого коэффициента будет на единицу меньше значения правого коэффициента родительского узла. Это свойство можно использовать для выборки непосредственных потомков узла в рекурсивной процедуре.
Для быстрого определения всех непосредственных предков и/или потомков для некоторого заданного узла таблица может быть расширена добавлением столбца, значения которого служат указателями на непосредственных предков элементов:
ALTER TABLE T ADD Parent int references T(L);
или представляют собой уровень в иерархии:
ALTER TABLE T ADD [Level] int;
Тогда задача получения значений непосредственных предков или потомков будет решаться аналогично тому, как это делается в предыдущем способе. Выполните такие выборки самостоятельно.
Теперь рассмотрим задачу поиска ближайшего общего предка для двух заданных узлов. Пусть это будут узлы J и K. Как видно на рис. 43, их ближайший общий предок – узел D.
Список всех общих для узлов J и K предков можно получить, например, следующим SQL-предложением (рис. 59):
select L, [Node], R from T where L<=(
select MIN(L) from T where Node='J' OR Node='K') AND
R>=(select MAX(R) from T where Node='K' OR Node='K');
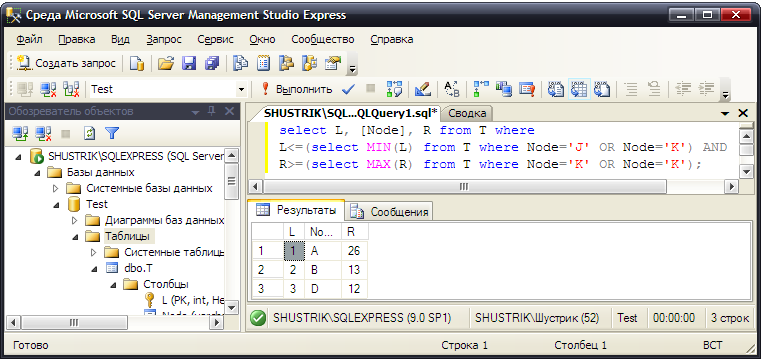
Рис. 59. Список всех общих предков узлов J и K
Нужное нам значение ближайшего общего узла можно определить как узел из данного списка, имеющий, например, максимальное значение левого коэффициента (рис. 60) (или минимальное значение правого коэффициента, или минимальное значение разности значений правого и левого коэффициентов).
select MAX(L) from T where
L<=(select MIN(L) from T where Node='J' OR Node='K') AND
R>=(select MAX(R) from T where Node='K' OR Node='K');
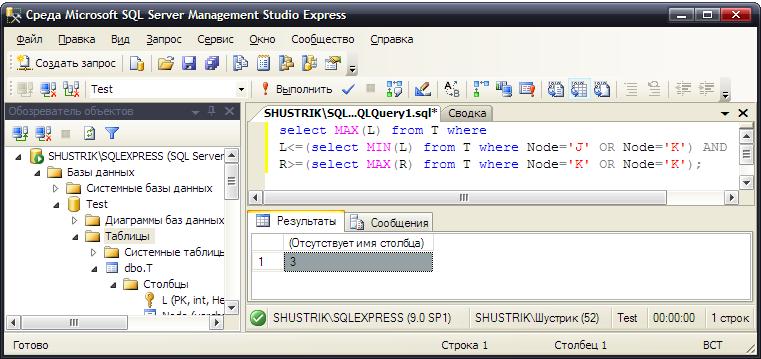
Рис. 60. Узел с максимальным значением левого коэффициента
Окончательно, находим требуемое значение (рис. 61):
select L, [Node], R from T where L=(
select MAX(L) from T where (
L<=(select MIN(L) from T where Node='J' OR Node='K')
AND R>=(select MAX(R) from T where Node='K' OR
Node='K')));

Рис. 61. Ближайший общий предок узлов J и K
Отдельно рассмотрим задачи удаления и добавления узлов в дерево. Если требуется удалить из иерархии поддерево, можно выполнить следующее предложение SQL:
DELETE FROM T WHERE L BETWEEN
(SELECT L FROM T WHERE Node='D')
AND
(SELECT R FROM T WHERE Node='D');
Результат выполнения этого предложения SQL в среде SQL Server Management Studio Express представлен на рис. 62.
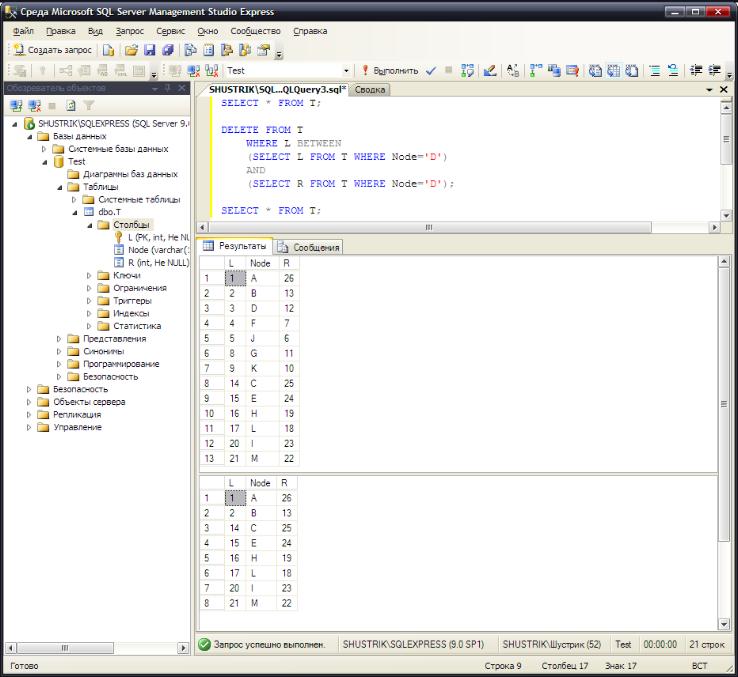
Рис. 62. Удаление узлов
После выполнения этого запроса появляются промежутки в последовательности правого и левого коэффициентов (рис. 63). Это не мешает выполнять большинство запросов к дереву, так как свойство вложенности сохраняется. Можно, например, использовать предикат BETWEEN в запросах, но другие операции, зависящие от «плотности» номеров коэффициентов, не будут работать в дереве с промежутками. Например, теперь нельзя выбрать все листья, используя свойство (R-L)=1, невозможно определить число узлов в поддереве, используя значения левого и правого коэффициентов его корня. Также, «благодаря» данному запросу, утрачена информация, которая была бы очень полезна в закрытии образовавшихся промежутков – правильные и левые номера корня поддерева. Поэтому такой запрос применять не следует!

Рис. 63. Разрыв в нумерации
Для того чтобы удаление поддерева было корректным, следует восстановить «плотность» номеров правого и левого коэффициентов (рис. 64). Для этого лучше использовать хранимую процедуру.
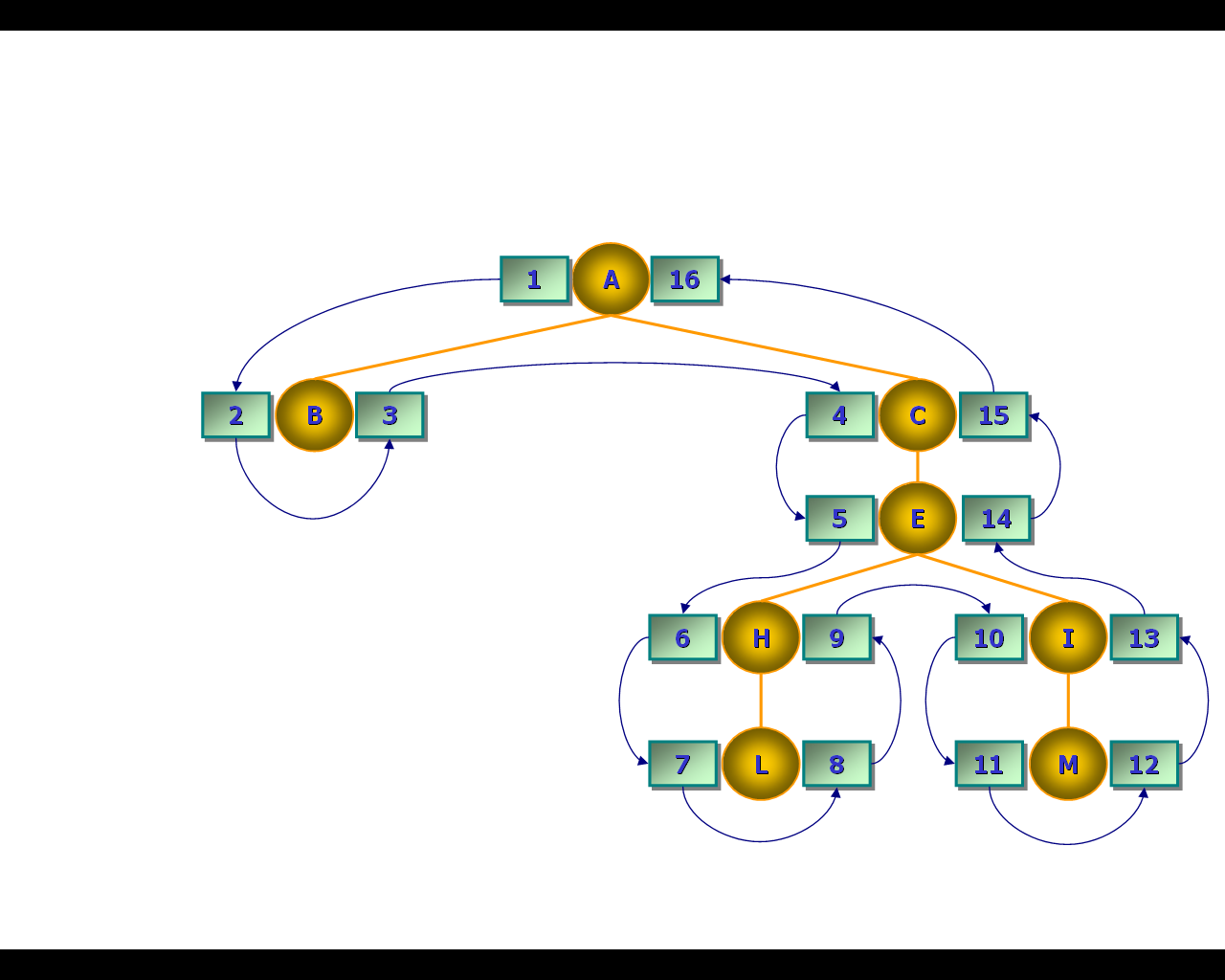
Рис. 64. Восстановленная «плотность» значений правого и левого коэффициентов
Обратите внимание. Триггер здесь неприменим, так как невозможно автоматически определить, что именно надо сделать – удалить единственный узел или всё поддерево, имеющее корнем заданный узел.
В случае отсутствия в используемой СУБД таких механизмов, следует выполнить эту операцию непосредственно в приложении.
Приведём пример хранимой процедуры для удаления поддерева:
CREATE PROCEDURE DropTree (@downsized VARCHAR) AS
-- ВНИМАНИЕ! Тут должна быть проверка входного параметра!
-- После каждой операции необходима проверка ошибок,
-- отсутствующая в данном примере!
BEGIN
DECLARE @dropNode VARCHAR;
DECLARE @dropL INT;
DECLARE @dropR INT;
-- Транзакция
BEGIN TRANSACTION DropTreeTransaction;
-- Сохраняем данные поддерева
SELECT @dropNode=Node, @dropL=L, @dropR=R
FROM T WHERE Node=@downsized;
-- Удаляем поддерево
DELETE FROM T WHERE L BETWEEN @dropL and @dropR;
-- Уплотняем промежутки
UPDATE T SET L=CASE
WHEN L>@dropL THEN L-(@dropR-@dropL+1)
ELSE L END,
R=CASE
WHEN R>@dropL
THEN R-(@dropR-@dropL+1)
ELSE R END;
-- ВНИМАНИЕ! Тут должна быть проверка результатов и,
-- если были ошибки, откат транзакции!
COMMIT TRANSACTION DropTreeTransaction;
SELECT * FROM T;
END;
Обратите внимание! Реальная процедура должна включать в себя обработку ошибок, отсутствующую в данном примере.
Результат создания хранимой процедуры в среде SQL Server Management Studio Express представлен на рис. 65.
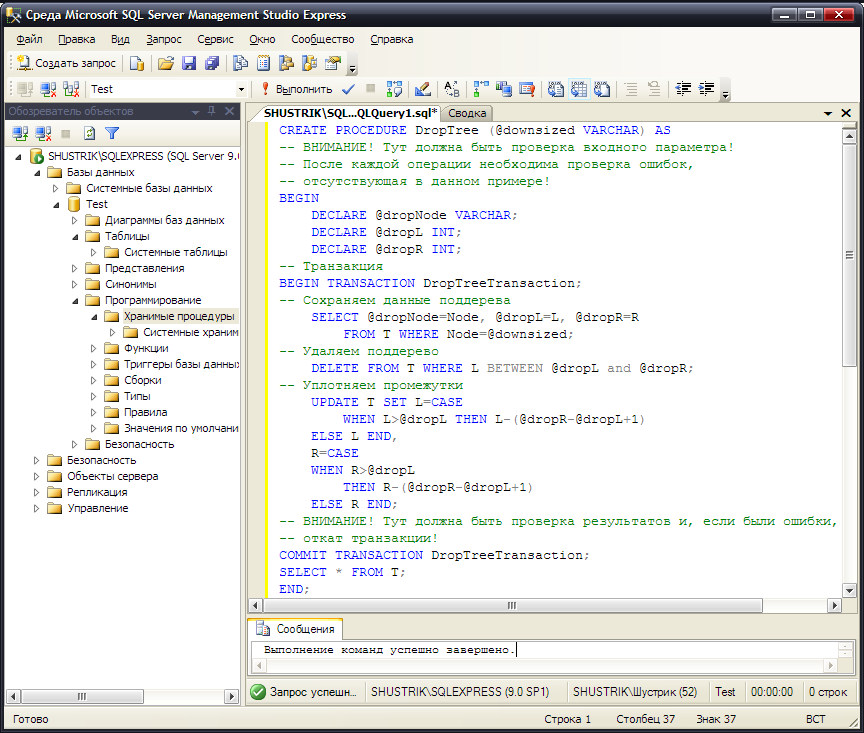
Рис. 65. Создание хранимой процедуры
Теперь используем созданную нами хранимую процедуру для того, чтобы удалить поддерево с корнем в узле D:
EXEC DropTree 'D';
На рис. 66 представлен результат выполнения этой операции.
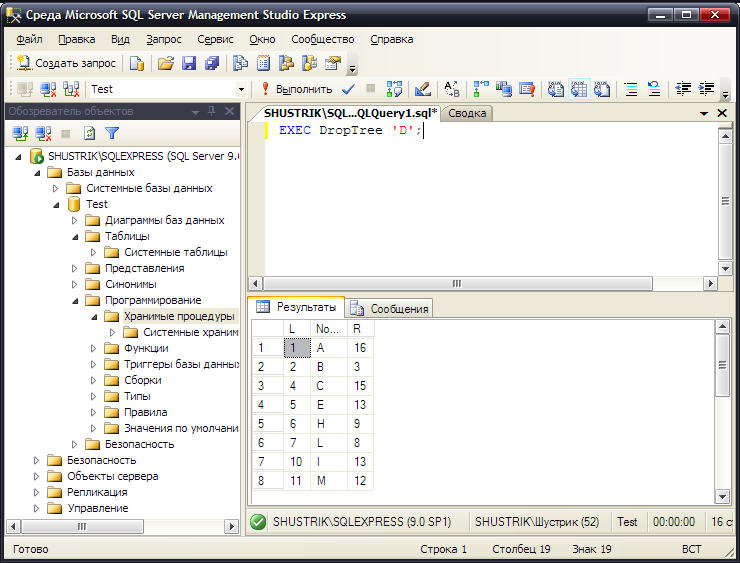
Рис. 66. Удаление поддерева
Сравните полученный результат со структурой на рис. 61.
Удаление отдельных узлов, если они не являются листьями, – более сложная задача, чем удаление полных поддеревьев (рис. 67-68) (листья рассматриваются как поддеревья, состоящие из единственного узла, и удаляются аналогично «настоящим» поддеревьям).
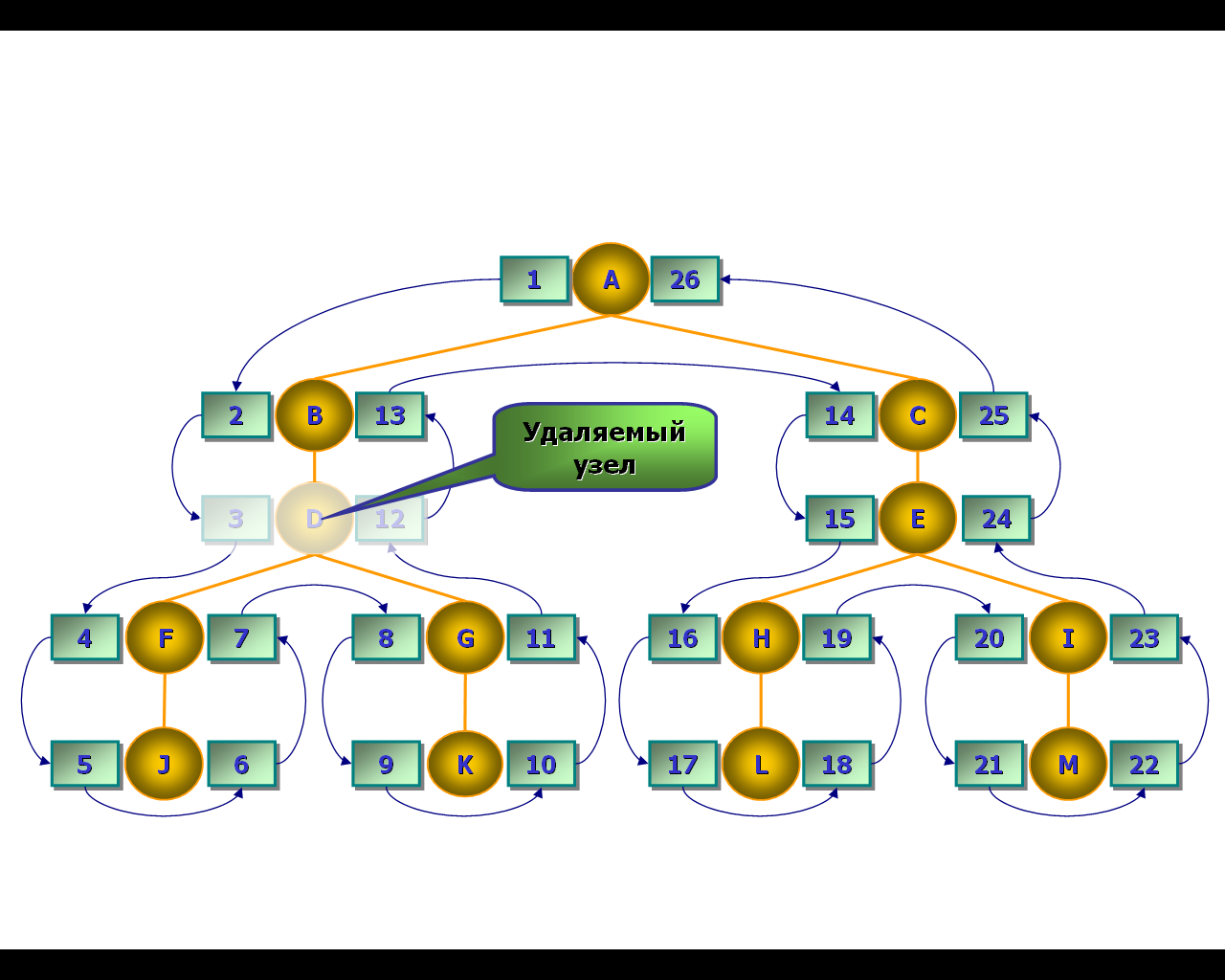
Рис. 67. Удаление единственного узла
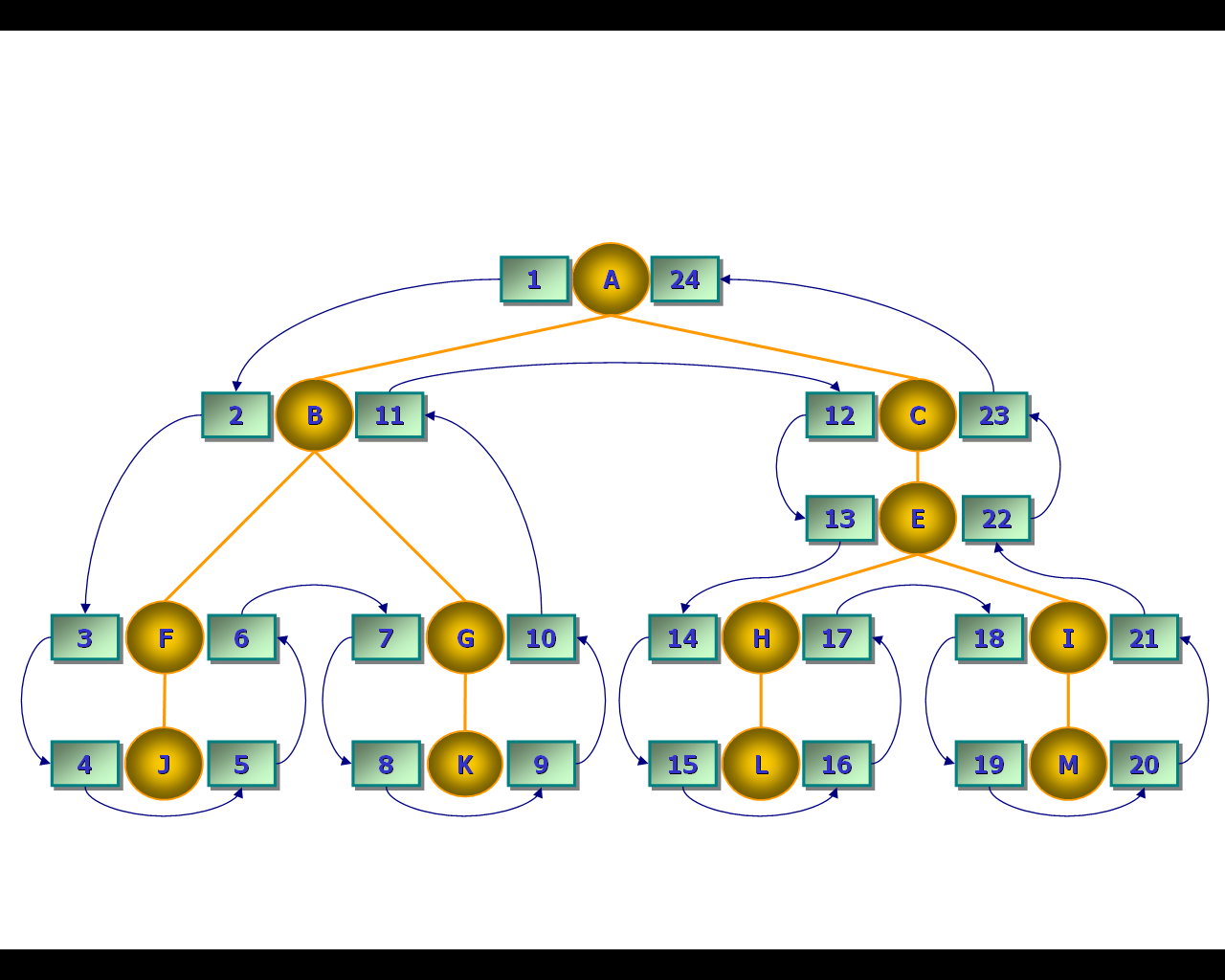
Рис. 68. Результат удаления узла D
Как и в случае рекурсивной модели, при удалении одиночного узла в середине дерева будем подключить потомков удаляемого узла к его предку. В модели вложенных множеств это выполняется автоматически. При простом удалении узла, так же как и в случае удаления поддерева, будет образовываться «разрыв» в нумерации правого и левого коэффициентов (см. рис. 67). Поэтому здесь также требуется хранимая процедура. Приведём пример процедуры, выполняющей переназначение правого и левого коэффициентов для узлов иерархии при удалении единственного узла:
CREATE PROCEDURE DropNode (@downsized VARCHAR) AS
-- ВНИМАНИЕ! Тут должна быть проверка входного параметра!
-- После каждой операции необходима проверка ошибок,
-- отсутствующая в данном примере!
BEGIN
DECLARE @dropNode VARCHAR;
DECLARE @dropL INT;
DECLARE @dropR INT;
-- Транзакция
BEGIN TRANSACTION DropNodeTransaction;
-- Сохраняем данные поддерева
SELECT @dropNode=Node, @dropL=L, @dropR=R
FROM T WHERE Node=@downsized;
-- Удаляем узел
DELETE FROM T WHERE Node=@downsized;
-- Уплотняем промежутки
UPDATE T SET L=CASE
WHEN L BETWEEN @dropL AND @dropR THEN L-1
WHEN L>@dropR THEN L-2
ELSE L END,
R=CASE
WHEN R BETWEEN @dropL AND @dropR THEN R-1
WHEN R>@dropR THEN R-2
ELSE R END;
-- ВНИМАНИЕ! Тут должна быть проверка результатов и,
-- если были ошибки, откат транзакции!
COMMIT TRANSACTION DropNodeTransaction;
END;
Результат создания этой хранимой процедуры в среде SQL Server Management Studio Express представлен на рис. 69.
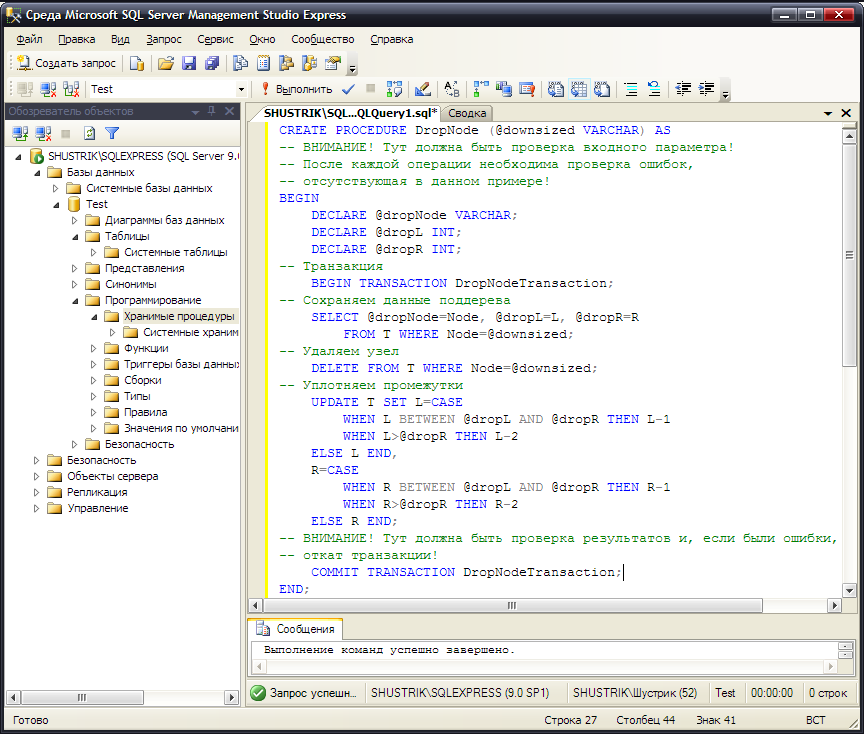
Рис. 69. Создание хранимой процедуры
Удалим узел D используя эту хранимую процедуру:
EXEC DropNode 'D';
Результат выполнения этой хранимой процедуры в среде SQL Server Management Studio Express представлен на рис. 70.
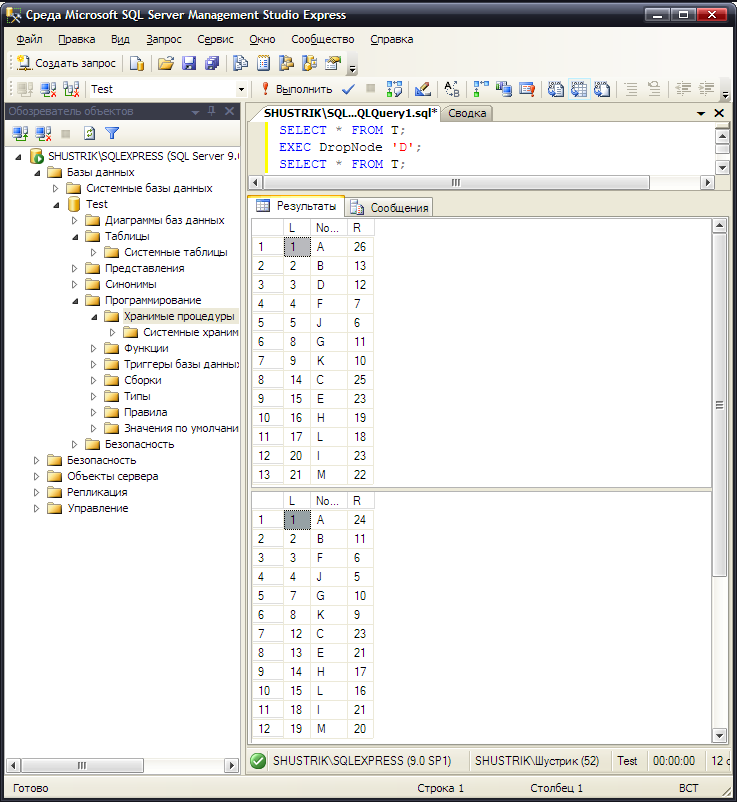
Рис. 70. Выполнение хранимой процедуры, удаление узла D
Обратите внимание! Наличие хранимых процедур не мешает удалять элементы иерархии другими способами, например при помощи ранее рассмотренного предложения SQL DELETE!
Теперь рассмотрим задачу добавления узлов в дерево. Будем помещать новые узлы справа. Для того чтобы добавить лист в иерархию, создадим следующую хранимую процедуру:
CREATE PROCEDURE AddNode (@Parent VARCHAR, @New VARCHAR) AS
-- Добавляем лист справа
-- ВНИМАНИЕ! Тут должна быть проверка входного параметра!
-- После каждой операции необходима проверка ошибок,
-- отсутствующая в данном примере!
BEGIN
DECLARE @ParentR INT;
-- Транзакция
BEGIN TRANSACTION AddNodeTransaction;
-- Получаем правый коэффициент родительского элемента
SELECT @ParentR=R
FROM T WHERE Node=@Parent;
-- Пересчитываем правый и левый коэффициенты
UPDATE T SET L=CASE WHEN L>@ParentR THEN L+2
ELSE L END,
R=CASE
WHEN R>=@ParentR THEN R+2
ELSE R END;
-- Добавляем узел
INSERT INTO T(L, Node, R) VALUES (@ParentR, @New, @ParentR+1);
-- ВНИМАНИЕ! Тут должна быть проверка результатов и,
-- если были ошибки, откат транзакции!
COMMIT TRANSACTION AddNodeTransaction;
END;
Создание этой хранимой процедуры в среде SQL Server Management Studio Express представлено на рис. 71.
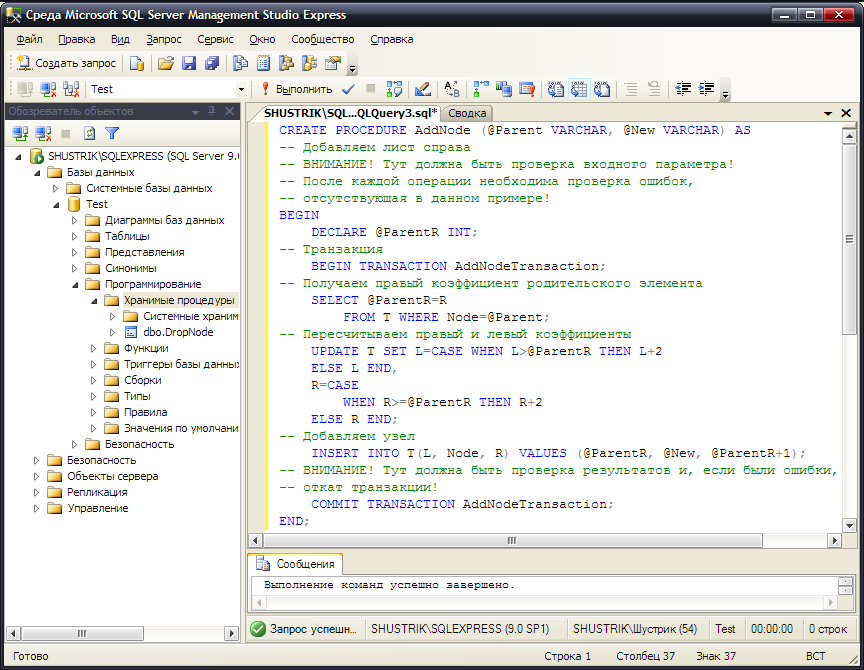
Рис. 71. Создание хранимой процедуры
Добавим к узлу B ещё одного потомка – лист D, как показано на рис. 72.
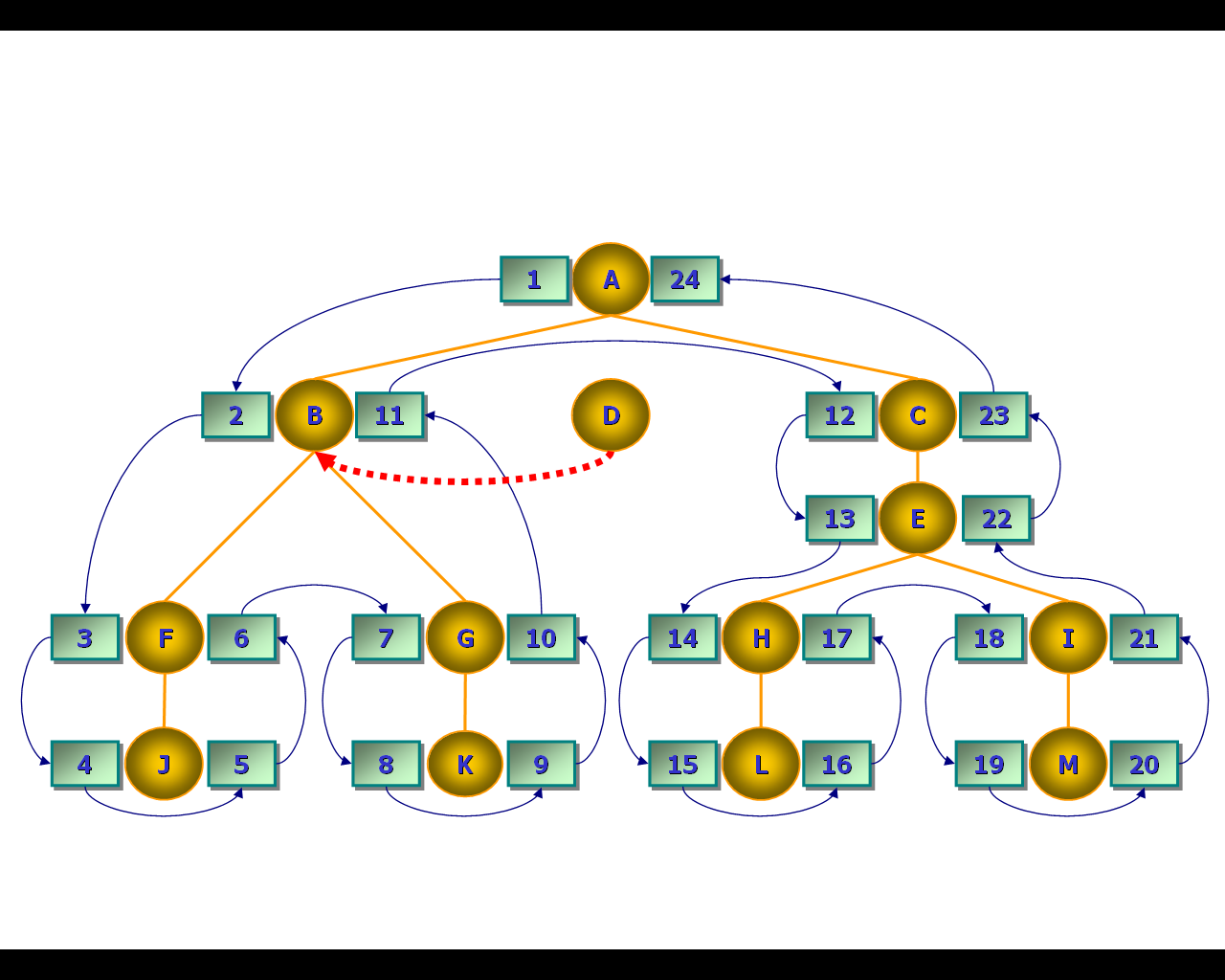
Рис. 72. Присоединение листа к иерархии
После пересчёта правого и левого коэффициентов иерархия должна иметь вид, представленный на рис. 73.
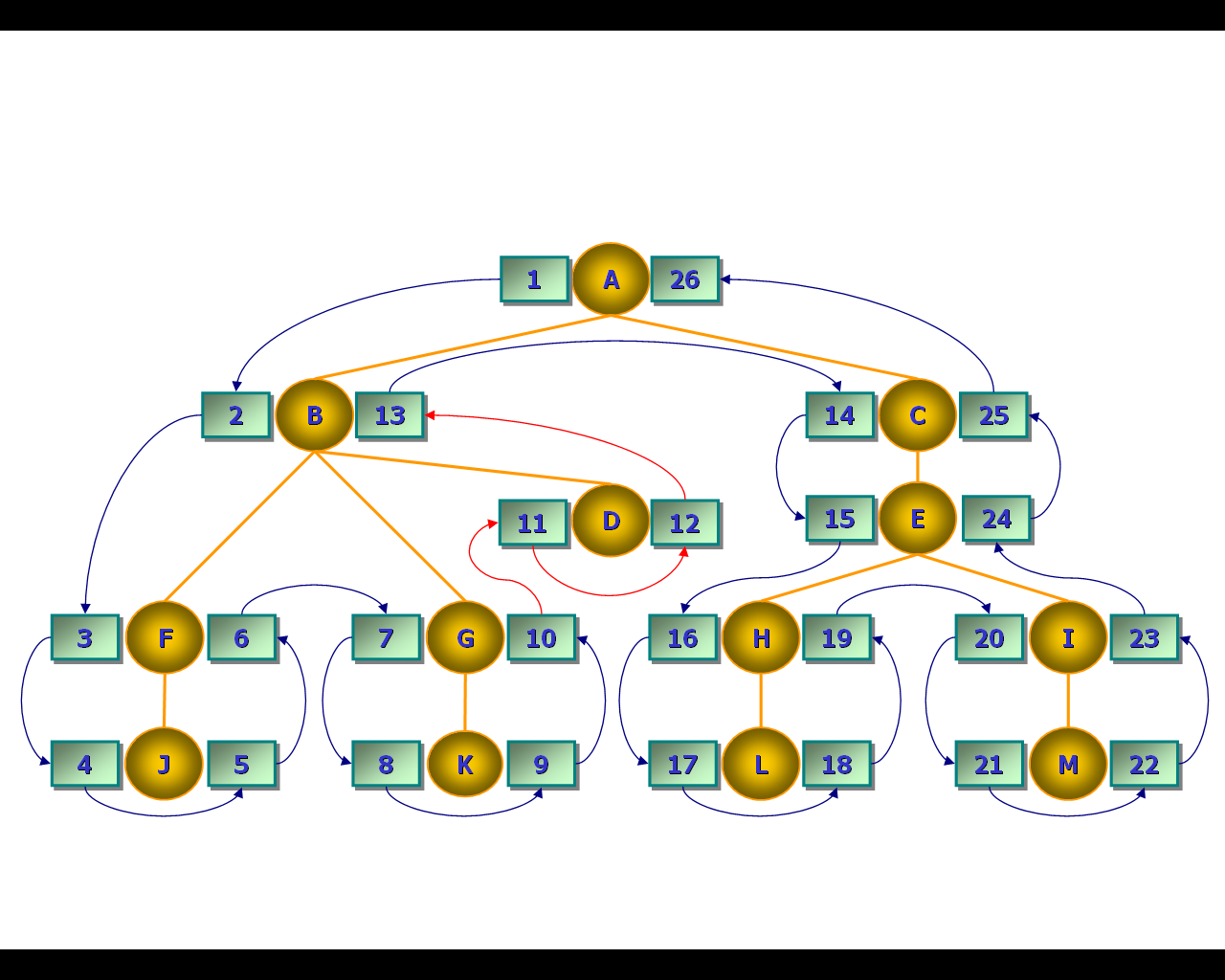
Рис. 73. Результат присоединения листа D к иерархии
Вызовем хранимую процедуру для добавления узла:
EXEC AddNode 'B', 'D';
Результат выполнения этой хранимой процедуры в среде MS SQL Server Management Studio Express представлен на рис. 74.
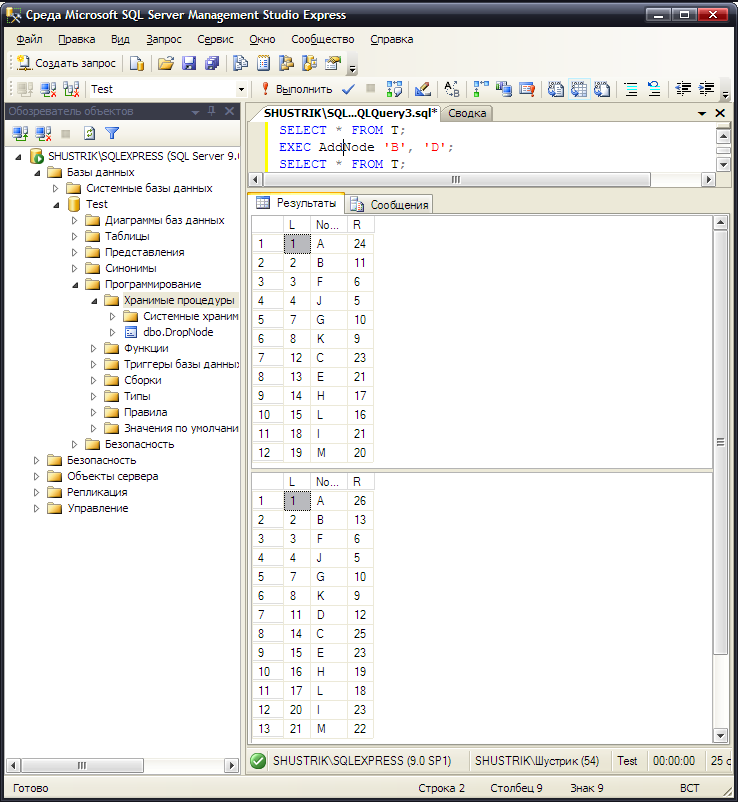
Рис. 74. Результат присоединения листа D к узлу B
Как и в случае удаления элементов иерархии, наличие хранимых процедур не препятствует добавлению записей в таблицу простым оператором INSERT. В обоих случаях остаётся опасная возможность для выполнения действий, могущих повлечь нарушения целостности данных.
Заметим, что пересчёт правого и левого коэффициентов дерева, выполненный в объемлющем языке, работает быстрее, чем реализованный в «чистом» SQL.
Таким образом, главный недостаток метода вложенных множеств состоит в том, что при изменении в структуре дерева (удалении, добавлении узлов) приходится заново пересчитывать значения правого и левого коэффициентов для всей таблицы. Это довольно трудоёмкая процедура, особенно в случае больших иерархий. Поэтому такой способ годится только для небольших и/или редко изменяемых таблиц.
Обратите внимание. Порядок узлов внутри каждого уровня уже задан значениями правого/левого коэффициентов. Если требуется поддерживать несколько различных вариантов упорядочения узлов внутри уровней, можно добавить дополнительные пары левого и правого коэффициентов для каждого варианта упорядочивания.
Задачи
Создайте таблицу, описывающую абстрактную иерархию со структурой с правым и левым коэффициентами. Заполните её данными. На основе этой таблицы сформируйте и выполните SQL-предложения, решающие следующие задачи:
Определить корневой элемент иерархии.
Определить непосредственного предка некоторого заданного элемента.
Определить, что заданный элемент не имеет потомков.
Выбрать все элементы иерархии, не имеющие потомков (листья).
Выбрать всех потомков заданного элемента (выбрать поддерево, начиная с заданного узла).
Выбрать всех предков для заданного узла.
Определить расстояние от корня до заданного узла.
Определить уровень в иерархии заданного узла относительно другого узла.