

краткая характеристика объекта:
краткая характеристика назначения подразделений объекта, для которого делается АСУ;
организационная структура;
объемные характеристики информационных и материальных потоков;
особенности функционирования объекта автоматизации.
основные положения АСУ:
цель создания АСУ;
возможная структура АСУ, т. е. состав функциональных и обеспечивающих подсистем.
требования к функциональным подсистемам (задачам):
ориентировочная очередность автоматизации
требования к информационному обеспечению (машинные информационные системы)
Информационные системы:
- документы;
- базы данных.
требования к комплексу технических средств;
требования к математическому (программному) и лингвистическому обеспечению
ПО:
- общесистемное;
- прикладное.
требования к персоналу:
Какими навыками должен обладать пользователь АСУ.
этапы разработки и внедрения АСУ:
Должен быть представлен укрупненный план-график разработки и внедрения АСУ.
расчет ожидаемых затрат:
NPV;
IRR;
Срок окупаемости.
ПРОЕКТИРОВАНИЕ
На стадии проектирования различают два типа проектов:
- технический проект - ТП
- рабочий проект - РП
Разделы этих проектов должны один в один соответствовать техническому заданию (ТЗ). В ТЗ мы пишем требования, а в ТП даются технические решения.
Рабочий проект как технический, но он снабжается инструкцией по использованию ПО, техническому обеспечению.
ТП и РП = ТРП (техно-рабочий проект)
ВНЕДРЕНИЕ АСУ
С заказчиком надо заключить акт о завершении работы.
Два этапа:
Опытная эксплуатация
Промышленная эксплуатация
Сдать АСУ в опытную эксплуатацию значит, АСУ работает параллельно с системой, которая была или с ручной работой.
Составляется акт об окончании опытной эксплуатации. В конце него пишется протокол разногласий (перечень доработок). После этого заключается акт о передаче АСУ в промышленную эксплуатацию.
Перед опытной эксплуатацией надо создать межведомственную комиссию, которая должна составить, и выполнить план-график проведения опытной эксплуатации с соответствующими записями о результатах опытной эксплуатации.
Договор на сопровождение АСУ - отдельно.
Сопровождение:
- устранение ошибок
- расширение версии (создание новой)
- тиражирование
4. Сетевое планирование и управление.
На практике приходится часто встречаться с задачей рационального планирования
сложных, комплексных работ.
Характерным для каждого такого комплекса работ является то, что он состоит из рода отдельных, элементарных работ или ((звеньев», которые зависят друг от друга так, что выполнение некоторых работ не может быть начато раньше. чем завершены некоторые другие.
Планирование любого такого комплекса работ должно производится с учетом
следующих существенных элементов:
1. времени на выполнение всего комплекса работ и его отдельных звеньев;
2. стоимости всего комплекса работ и его отдельных звеньев;
З. сырьевых, энергетических и людских ресурсов.
Основным материалом для сетевого планирования является перечень работ комплекса, в которых указаны не только работы, но и их взаимная обусловленность (окончание таких работ требуется для выполнения каждой работы). Будем называть такой список структурной таблицей.
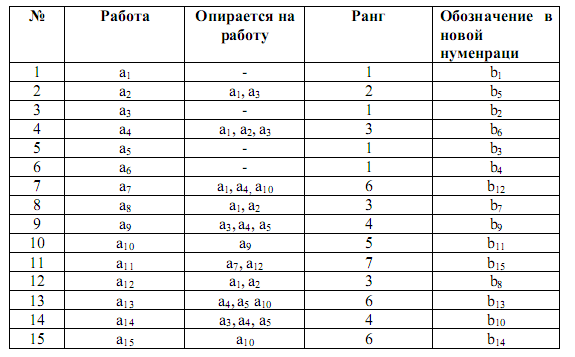
Первая операция, которую мы проведем со структурной таблицей, называется упорядочивание.
Для упорядочивания все работы подразделяются на ранги. Работа называется работой первого ранга, если для ее начала не требуется выполнение никаких других работ. Работа называется к-ого ранга, если она опирается на одну или несколько работ не выше (к-1) —го ранга, среди которых есть хотя бы одна работа (к-1) - ого ранга.
Упорядоченная структурная таблица
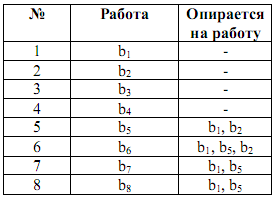
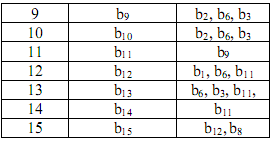
Сетевой график комплекса работ
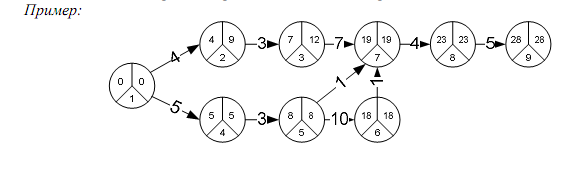
Предположим, что нам задана упорядоченная таблица комплекса работ:
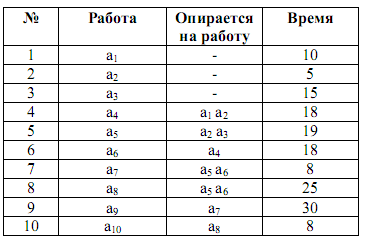
Связи между работами, входящими в этот комплекс, можно изобразить графически, в виде так называемого сетевого графика. Этот график можно строить по-разному. В одних стрелках графа обозначаются работы, а узлами — события, состоящие в выполнении одной или нескольких работ и возможности начать новые работы; в других — узлами обозначаются работы, а стрелками – логические связи между ними.

Когда сетевой график построен, встает вопрос: Каково время завершения всего комплекса работ ? Это время не может быть меньше суммы длительностей выполнения работ, взятой вдоль «самого благоприятного пути», начинающегося в одной из начальных вершин и заканчивающегося в одной из конечных.
Путь, который дает максимальную сумму длительностей выполнения работ, называется критическим путем. Работы, составляющие критический путь, называются критическими работами. Ткр = 84. Критические работы: а1, а4, а6, а7, а9. Критический путь в сетевом графике может быть не один.
Особенность критических работ состоит в следующем: для того, чтобы было соблюдено минимально – возможное время выполнения всего комплекса (длина крит. пути) каждая из критических работ должна начинаться точно в момент, когда закончена последняя из работ, на которую она опирается, и продолжаться не более того времени. которое ей отведено по плану; малейшее запаздывание в выполнении каждой из работ приводит к соответствующей задержке выполнения плана в целом.
Таким образом, критический путь на сетевом графике — это совокупность наиболее уязвимых, (слабых мест плана) которые должны укладываться во временной план с наибольшей четкостью. Что касается остальных, не критических работ, то с ними дело обстоит не так плохо: каждая из этих работ имеет известные временные резервы и может быть закончена с некоторым опозданием, без того чтобы это отразилось на сроке выполнения комплекса в целом.
Знание критического пути на сетевом графике полезно в двух отношениях: во-первых, оно позволяет выделить из всего комплекса работ совокупность наиболее «угрожаемых», непрерывно наблюдать за ними, и, в случае надобности форсировать их выполнение; во-вторых, оно дает возможность в принципе ускорить выполнение комплекса работ за счет привлечения резервов, скрытых в не критических работах, если удается за счет их «безвредного» замедления перебросить часть средств на более важные практические работы.
Резервы, соответствующие не критическим работам легко могут быть определены по сетевому графику.
Каждой не критической дуге соответствует определенный временной резерв, который может быть произвольным образом распределен между не критическими работами, лежащими на данной дуге.
2-ой способ построения графика: Работы соответствуют ребрам: вершинам соответствуют события, состоящие в окончании одних работ и возможности начать какие- то другие работы.
Событием (вершиной сетевого графика) считается момент времени, когда выполнены все предыдущие работы и могут быть начаты все непосредственно следующие работы.
Каждому событию соответствуют два момента времени — ранний момент события и поздний момент события.
Ранний момент события определяется как наиболее раннее время, когда могут быть начаты работы, исходящие из соответствующей вершины. Вычислительный процесс, используемый для определения ранних моментов событий, называется прямым проходом. При прямом проходе вычисления начинаются с первой вершины и продолжаются последовательно слева направо, пока не будут определены ранние моменты всех событий.
Для начального события ранний момент равен О. Ранний момент для последующего события определяется простым прибавлением длительности последующей работы к раннему моменту предшествующего события.
Если в вершину водят несколько работ, то её ранним моментом считается наибольшее из всех ранних времен окончания этих работ.
Поздний момент события для данной вершины определяется как наибольшее из всех поздних времен окончания работ, входящих в эту вершину.
Вычислительный процесс для определения поздних моментов событий называется обратным проходом. При обратном проходе вычисления начинаются с последней вершины и продолжаются последовательно справа налево вплоть до начального события.
Поздний момент последнего события полагается равным раннему моменту события, найденному при прямом проходе(очевидно. что нет никакого резона в затягивании проекта на время большее, чем фактически требуется для его выполнения). Поздний момент предыдущего события находится простым вычитанием из позднего момента последующего события длительности предшествующей ему работы.
Если из вершины выходит несколько работ, то ее поздним моментом считается наименьший из всех поздних моментов начала работ, выходящих из этой вершины.
Длина критического пути в этом сетевом графике равна позднему(раннему) моменту последнего события.
Критическая работа (i,j) должна удовлетворять следующим трем критериям:
1) ранний и поздний моменты события для вершины i должны быть равны.
2) ранний и поздний моменты события для вершины j должны быть равны.
3) Время выполнения работы должно равняться разности между поздним моментом события j и ранним моментом события i.
Резервы

Алгоритм задачи сетевого планирования
Определить по сетевому графику, например, длину критического пути, перечень ключевых работ т.д., можно только в том случае, когда планируемый комплекс не слишком сложен (по количеству работ и связей). На практике встречаются комплексы работ. состоящие из огромного числа звеньев (порядка тысяч и более). для анализа и усовершенствования плана работ в таких случаях используются формальные машинные алгоритмы.
Рассмотрим один из возможных алгоритмов.
Предположим, что комплекс работ описан упорядоченной структурно-временной таблицей.

5. Архитектура и функционирование систем типа scada
Системы типа SCADA - супервизорное управление и сбор данных.
В настоящее время в передовых странах управление ТП основано на применении систем типа SCADA. Они имеют многоуровневую распределенную структуру, где нижние уровни реализуют функции контроля, регистрации, регулирования и т.д., а верхние уровни функции управления и моделирования. Во всех этих системах в большей или меньшей степени реализованы следующие основные принципы:
Работа в режиме реального времени (Real Time);
Высокая частота обновления информации;
Сетевая архитектура;
Принципы открытых систем и модульного исполнения;
Наличие запасного оборудования работающего в горячем режиме.
Структура системы SCADA:
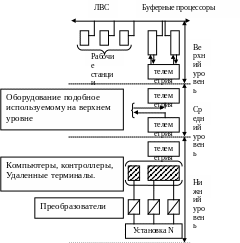
В зависимости от уровня система выполняет разные функции и оснащена различными техническими средствами.
Функции верхнего уровня.
Прогнозы и планирование производства.
Общий контроль функционирования системы.
Распределение задач между отдельными предприятиями и т.д.
Супервизорный контроль и мониторинг всей системы.
Обработка данных для АСУПХД.
Функции среднего уровня.
Планирование производства и оптимизация с учетом ряда требований верхнего уровня.
Определение функций и наборов узлов отдельных контроллеров.
Супервизорный контроль и мониторинг процессов.
Функции нижнего уровня (уровень агрегатов).
Непосредственное цифровое управление.
Контроль экстремальных значений параметров.
Простейшие расчеты.
Функционирование системы scada.
Функционирование систем SCADA можно условно представить в виде нескольких этапов:
Получение данных.
Дистанционное управление.
Диалог оператора с системой.
Получение данных. Аналоговые или цифровые сигналы, поступающие от измерительных датчиков (давление, температура и т.д.) и цифровые данные обозначающие статус различного оборудования (вкл./выкл. и т.д.) вводятся в локальную сеть через удаленный терминал или контроллеры, установленные во всех точках газовой сети. В зависимости от вида и значения они поступают в контроллеры, удаленные терминалы или в центральную ЭВМ.
Обработка данных. Здесь происходить первичная обработка данных. ПО мере поступления данные проверяются на достоверность, аварийные сигналы оцениваются, производится анализ полученных данных и оформление документации. Полученные данные сохраняются для последующих расчетов.
Дистанционное управление. Одной из основных характеристик SCADA является число параметров, по которым возможно осуществить дистанционное управление и реализовать дистанционный контроль. Дистанционное управление включает с одной стороны выдачу указаний поступающих на объект через комплекс автоматических программируемых контроллеров. С другой стороны, удаленные передатчики посылают сигналы локальному контроллеру о значениях технологических параметров.
Прогнозирование. Система SCADA предусматривает динамическое моделирование и прогнозирование работы системы. Поведение системы можно предсказать на интервале от нескольких часов до нескольких дней. Эта функция выполняется вне режима реального времени с помощью оборудования, которое может иметь или не иметь интерфейс главной системы.
6. Структурный и объектно-ориентированный подходы в проектировании информационно-управляющих систем.
Структурный подход – это метод исследования системы, который начинается с ее общего обзора, а затем детализируется, приобретая иерархическую структуру с большим количеством уровней. Система разбивается на функциональные подсистемы, подфункции, задачи и так далее вплоть до конкретных процедур.
Основные принципы структурного подхода:
"разделяй и властвуй" - принцип решения сложных проблем путем их разбиения на множество меньших независимых задач, легких для понимания и решения;
иерархическое упорядочивание - принцип организации составных частей проблемы в иерархические древовидные структуры с добавлением новых деталей на каждом уровне.
абстрагирование - выделение существенных аспектов системы и отвлечения от несущественных;
формализация - необходимость строгого методического подхода к решению проблемы;
непротиворечивость - обоснованность и согласованность элементов;
структурирование данных - данные должны быть структурированы и иерархически организованы.
Структурный анализ включает в себя инструментальные средства, которые используются при анализе моделирования системы.
Инструментальные средства включают в себя графические и текстовые компоненты, позволяющие отображать основные элементы системы. Текстовые обеспечивают точное определение элементов и связей между ними.
Инструментальные средства делятся на группы и позволяют рассматривать:
SADT (Structured Analysis and Design Technique), модели и соответствующие функциональные диаграммы;
DFD (Data Flow Diagrams), диаграммы потоков данных;
ERD (Entity-Relationship Diagrams), диаграммы "сущность-связь".
Объектно-ориентированный подход
При объектно-ориентированном (ОО) подходе используется итеративно-поступательный цикл создания ПО, перенос акцента проектирования с разработки алгоритмов функционирования системы на построения системы абстракций и их взаимодействия. Разработка состоит из ряда итераций, которые в дальнейшем приводят к созданию ИС. Каждая итерация может приводить к созданию фрагмента или новой версии и включает этапы выработки требований, анализа, проектирования, реализации и тестирования. Поскольку тестирование проводится на каждой итерации, риск снижается уже на начальных этапах жизненного цикла разработки.
Проектирование рассматривается как последовательное отражение уровней абстракции создаваемой системы управления на программную модель. Каждый уровень представляет собой совокупность объектов. Эти объекты образуют иерархии при повышении уровня общности.
7. Стандарты и классификация производственных информационных систем.
Ядром каждой производственной системы являются воплощенные в ней рекомендации по управлению производством. На данный момент существует четыре свода таких рекомендаций и соответствующих стандарта производственных ИС.
1)Исходным стандартом, появившимся в 70-х годах, был стандарт MRP (Material Requirements Planning), включавший только планирование материалов для производства.
MRP-системы в настоящее время присутствуют практически во всех интегрированных информационных системах управления предприятием.
Основная идея MRP-систем состоит в том, что любая учетная единица материалов или комплектующих, необходимых для производства изделия, должна быть в наличии в нужное время и в нужном количестве.
Входные элементы MRP:
Основной производственный план-график (ОПП). Система MRP осуществляет детализацию ОПП в разрезе материальных составляющих. После проведения необходимых итераций ОПП утверждается как действующий и на его основе осуществляется запуск производственных заказов.
Ведомость материалов (ВМ) и состав изделия (СИ).
Состояние запасов.
2)Системы MRP II (Manufacturing Resources Planning) являются дальнейшим развитием систем MRP и ориентированы на эффективное планирование всех ресурсов производственного предприятия.
Стандарт APICS на системы класса MRP II содержит описание 16 групп функций системы, среди которых, кроме MRP,
планирование продаж и производства,
управление спросом,
управление складом,
планирование потребностей в мощностях,
контроль входа/выхода,
управление финансами,
моделирование,
оценка результатов деятельности и др.
3)ERP-системы (Enterprise Resources Planning), кроме вышеуказанной функциональности, включают планирование ресурсов распределения (DRP – I, DRP – II), и ресурсов для проведения технологического обслуживания и выполнения ремонтов.
Системы DRP обеспечивают оптимальное решение (планирование, учет и управление) транспортных задач по перемещению материально-технических ресурсов и готовой продукции.
4)Последний по времени стандарт CSRP (Customer Synchronized Resource Planning) охватывает также и взаимодействие с клиентами: оформление наряд-заказа, техзадание, поддержка заказчика на местах и пр.
Таким образом, если MRP, MRP-II, ERP ориентировались на внутреннюю организацию предприятия, то CSRP вышел "за ворота" отдельного предприятия и включил в себя полный цикл от проектирования будущего изделия, с учетом требований заказчика, до гарантийного и сервисного обслуживания после продажи.
Классификация
Финансово-управленческие системы
Это локальные и малые интегрированные системы (их иногда называют "Low End PC" и "Middle PC"). Такие системы
предназначены для ведения учета по одному или нескольким направлениям (бухгалтерия, сбыт, склад, учет кадров и т.д.),
универсальны, легко адаптируются к нуждам конкретного предприятия (есть специальные программы-конструкторы),
способны работать на персональных компьютерах или локально, или в сетях под управлением Novell Netware или Windows NT,
в основном опираются на технологию выделенного сервера базы данных (file server),
в основном подготовлены настольными средствами разработки Clipper, FoxPro, dBase, Paradox,
отдельные из предлагаемых в России систем такого класса разработаны для промышленных баз данных (Oracle, SYBASE, Progress, Informix, SQL Server) в технологии клиент-сервер.
Производственные системы
Это средние и крупные интегрированные системы ("High End PC", ERP-системы). Эти системы
предназначены для управления и планирования, прежде всего, производственного процесса. Учетные функции, хотя и глубоко проработаны, выполняют вспомогательную роль. Информация, например, в бухгалтерию поступает автоматически из других модулей,
значительно более сложны в установке,
часто ориентированы на одну или несколько отраслей и/или типов производства: серийное сборочное, мало-серийное и опытное, дискретное (металлургия, химия, упаковка), непрерывное (нефте- и газодобыча),
по многим параметрам значительно более жесткие, чем финансово-управленческие,
эффект от внедрения производственных систем чувствуется на верхних эшелонах управления предприятием, когда видна вся взаимосвязанная картина работы,
разработаны с помощью промышленных баз данных, в большинстве случаев используется технология клиент-сервер.
могут работать на разных платформах (NT, UNIX, AS/400, мэйнфреймы).
Современные ИС подразделяются также по масштабам применения на три основные класса:
Настольные - для работы одного человека. К ним следует отнести Автоматизированное Рабочее Место (АРМ) бухгалтера, АРМ кассира, АРМ расчетчика заработной платы и.т.д. Внедрение таких программ не вызывает особых трудностей и для хороших систем может исчисляться днями.
Основные проблемы возникают при объединении информации с разных участков учета - данные хранятся на разных компьютерах. Например, один и тот же объект (материал, товар, изделие) на разных АРМах может иметь разные коды.
Офисные - для работы отдела. Это сетевые бухгалтерские программы, программы автоматизации торгового зала, сетевые складские программы и.т.д. Сотрудники всего отдела могут одновременно работать с единой базой данных, выполняя отдельную функцию управления предприятием.
Корпоративные - для работы целого предприятия или даже нескольких предприятий.
8. Case-технологии. Современные case-средства
CASE-технология (Computer-Aided Software/System Engineering) представляет собой совокупность методологий анализа, проектирования, разработки и сопровождения сложных систем и поддерживается комплексом взаимоувязанных средств автоматизации. Это инструментарий для системных аналитиков, разработчиков и программистов, заменяющий бумагу и карандаш компьютером, автоматизируя процесс проектирования и разработки ПО.
Особенности case-технологии.
Единый графический язык.
Единая БД проекта.
Интеграция средств.
Поддержка коллективной разработки и управления проектом.
Прототипирование.
Генерация документации.
Верификация проекта.
Автоматическая генерация объектного кода.
Сопровождение и реинжиниринг.
При использовании CASE-технологий изменяются все фазы жизненного цикла ИС, причем наибольшие изменения касаются фаз анализа и проектирования.
Характеристика современных case-средств.
Компоненты полного комплекса CASE-средств:
репозиторий, являющийся основой CASE-средства.
графические средства анализа и проектирования,
средства разработки приложений,
средства конфигурационного управления;
средства документирования;
средства тестирования;
средства управления проектом;
средства реинжиниринга.
Классификация case-средств по типам
в основном совпадает с компонентным составом CASE-средств и включает следующие основные типы:
средства анализа (Upper CASE), предназначенные для построения и анализа моделей предметной области (Design/IDEF, BPwin);
средства анализа и проектирования (Middle CASE), использующиеся для создания спецификаций компонентов и интерфейсов системы, архитектуры системы, алгоритмов и структур данных (Vantage Team Builder, Designer/2000, Silverrun, PRO-IV, CASE.Аналитик);
средства проектирования БД, обеспечивающие моделирование данных и генерацию схем баз данных (как правило, на языке SQL). К ним относятся ERwin, S-Designor и DataBase Designer (ORACLE). Средства проектирования баз данных имеются также в составе CASE-средств Vantage Team Builder, Designer/2000, Silverrun и PRO-IV;
средства разработки приложений. К ним относятся средства 4GL (Uniface, JAM, PowerBuilder, Developer/2000, New Era, SQLWindows, Delphi и др.) и генераторы кодов, входящие в состав Vantage Team Builder, PRO-IV и частично - в Silverrun;
средства реинжиниринга, обеспечивающие анализ программных кодов и схем баз данных и формирование на их основе различных моделей и проектных спецификаций. Средства анализа схем БД и формирования ERD входят в состав Vantage Team Builder, PRO-IV, Silverrun, Designer/2000, ERwin и S-Designor. В области анализа программных кодов наибольшее распространение получают объектно-ориентированные CASE-средства, обеспечивающие реинжиниринг программ на языке С++ (Rational Rose, Object Team).
Помимо этого, CASE-средства можно классифицировать по следующим признакам:
применяемым методологиям и моделям систем и баз данных (БД);
степени интегрированности с системами управления базами данных (СУБД);
доступным платформам.
9. Универсальный язык моделирования uml.
Если при проектировании информационная система разбивается на объекты (компоненты), то для ее визуального моделирования может быть использован UML.
С точки зрения визуального моделирования, UML можно охарактеризовать следующим образом:
UML предоставляет выразительные средства для создания визуальных моделей, которые единообразно понимаются всеми разработчиками, вовлеченными в проект и являются средством коммуникации в рамках проекта;
UML: не зависит от объектно-ориентированных (ОО) языков программирования,
не зависит от используемой методологии разработки проекта,
может поддерживать любой ОО язык программирования;
UML является открытым и обладает средствами расширения базового ядра;
UML можно содержательно описывать классы, объекты и компоненты в различных предметных областях, часто сильно отличающихся друг от друга.
Принципы моделирования
Использование языка UML основывается на следующих общих принципах моделирования:
абстрагирование - в модель следует включать только те элементы проектируемой системы, которые имеют непосредственное отношение к выполнению ей своих функций или своего целевого предназначения. Другие элементы опускаются, чтобы не усложнять процесс анализа и исследования модели;
многомодельность - никакая единственная модель не может с достаточной степенью точности описать различные аспекты системы. Допускается описывать систему некоторым числом взаимосвязанных представлений, каждое из которых отражает определенный аспект её поведения или структуры;
иерархическое построение – при описании системы используются различные уровни абстрагирования и детализации в рамках фиксированных представлений. При этом первое представление системы описывает её в наиболее общих чертах и является представлением концептуального уровня, а последующие уровни раскрывают различные аспекты системы с возрастающей степенью детализации вплоть до физического уровня. Модель физического уровня в языке UML отражает компонентный состав проектируемой системы с точки зрения ее реализации на аппаратурной и программной платформах конкретных производителей.
Сущности в uml
В UML определены четыре типа сущностей: структурные, поведенческие, группирующие и аннотационные. Сущности являются основными объектно-ориентированными элементами языка, с помощью которых создаются модели.
Структурные сущности - это имена существительные в моделях на языке UML. Как правило, они представляют статические части модели, соответствующие концептуальным или физическим элементам системы. Примерами структурных сущностей являются «класс», «интерфейс», «кооперация», «прецедент», «компонент», «узел», «актер».
Поведенческие сущности являются динамическими составляющими модели UML. Это глаголы, которые описывают поведение модели во времени и в пространстве. Существует два основных типа поведенческих сущностей:
взаимодействие - это поведение, суть которого заключается в обмене сообщениями между объектами в рамках конкретного контекста для достижения определенной цели;
автомат - алгоритм поведения, определяющий последовательность состояний, через которые объект или взаимодействие проходят в ответ на различные события.
Группирующие сущности являются организующими частями модели UML. Это блоки, на которые можно разложить модель. Такая первичная сущность имеется в единственном экземпляре - это пакет.
Пакеты представляют собой универсальный механизм организации элементов в группы. В пакет можно поместить структурные, поведенческие и другие группирующие сущности. В отличие от компонентов, которые реально существуют во время работы программы, пакеты носят чисто концептуальный характер, то есть существуют только в процессе разработки.
Аннотационные сущности – это пояснительные части модели UML: комментарии для дополнительного описания, разъяснения или замечания к любому элементу модели. Имеется только один базовый тип аннотационных элементов - примечание. Примечание используют, чтобы снабдить диаграммы комментариями или ограничениями, выраженными в виде неформального или формального текста.
Отношения в uml
В языке UML определены следующие типы отношений: зависимость, ассоциация, обобщение и реализация. Эти отношения являются основными связующими конструкциями UML и также как сущности применяются для построения моделей.
Зависимость (dependency) - это семантическое отношение между двумя сущностями, при котором изменение одной из них, независимой, может повлиять на семантику другой, зависимой.
Ассоциация (association) - структурное отношение, описывающее совокупность смысловых или логических связей между объектами.
Обобщение (generalization) - это отношение, при котором объект специализированного элемента (потомок) может быть подставлен вместо объекта обобщенного элемента (предка). При этом, в соответствии с принципами объектно-ориентированного программирования, потомок (child) наследует структуру и поведение своего предка (parent).
Реализация (realization) является семантическим отношением между классификаторами, при котором один классификатор определяет обязательство, а другой гарантирует его выполнение. Отношение реализации встречаются в двух случаях:
между интерфейсами и реализующими их классами или компонентами;
между прецедентами и реализующими их кооперациями.
Общие механизмы uml
Для точного описания системы в UML используются, так называемые, общие механизмы:
спецификации (specifications);
дополнения (adornments);
деления (common divisions);
расширения (extensibility mechanisms).
UML является не только графическим языком. За каждым графическим элементом его нотации стоит спецификация, содержащая текстовое представление соответствующей конструкции языка. Например, пиктограмме класса соответствует спецификация, которая описывает его атрибуты, операции и поведение, хотя визуально, на диаграмме, пиктограмма часто отражает только малую часть этой информации. Более того, в модели может присутствовать другое представление этого класса, отражающее совершенно иные его аспекты, но, тем не менее, соответствующее спецификации. Таким образом, графическая нотация UML используются для визуализации системы, а с помощью спецификаций описывают ее детали.
Практически каждый элемент UML имеет уникальное графическое изображение, которое дает визуальное представление самых важных его характеристик. Нотация сущности «класс» содержит его имя, атрибуты и операции. Спецификация класса может содержать и другие детали, например, видимость атрибутов и операций, комментарии или указание на то, что класс является абстрактным. Многие из этих деталей можно визуализировать в виде графических или текстовых дополнений к стандартному прямоугольнику, который изображает класс.
При моделировании объектно-ориентированных систем существует определенное деление представляемых сущностей.
Во-первых, существует деление на классы и объекты. Класс - это абстракция, а объект - конкретное воплощение этой абстракции. В связи с этим, практически все конструкции языка характеризуются двойственностью «класс/объект». Так, имеются прецеденты и экземпляры прецедентов, компоненты и экземпляры компонентов, узлы и экземпляры узлов. В графическом представлении для объекта принято использовать тот же символ, что и для класса, а название подчеркивать.
Во-вторых, существует деление на интерфейс и его реализацию. Интерфейс декларирует обязательства, а реализация представляет конкретное воплощение этих обязательств и обеспечивает точное следование объявленной семантике. В связи с этим, почти все конструкции UML характеризуются двойственностью «интерфейс/реализация». Например, прецеденты реализуются кооперациями, а операции - методами.
UML является открытым языком, то есть допускает контролируемые расширения, чтобы отразить особенности моделей предметных областей. Механизмы расширения UML включают:
стереотипы (stereotype) - расширяют словарь UML, позволяя на основе существующих элементов языка создавать новые, ориентированные для решения конкретной проблемы;
помеченные значения (tagged value) - расширяют свойства основных конструкций UML, позволяя включать дополнительную информацию в спецификацию элемента;
ограничения (constraints) - расширяют семантику конструкций UML, позволяя создавать новые и отменять существующие правила.
Совместно эти три механизма расширения языка позволяют модифицировать его в соответствии с потребностями проекта или особенностями технологии разработки.
Виды диаграмм uml
Графические изображения моделей системы в UML называются диаграммами. В терминах языка UML определены следующие их виды:
диаграмма вариантов использования или прецедентов (use case diagram)
диаграмма классов (class diagram)
диаграмма состояний (statechart diagram)
диаграмма деятельности (activity diagram)
диаграмма последовательности (sequence diagram)
диаграмма кооперации (collaboration diagram)
диаграмма компонентов (component diagram)
диаграмма развертывания (deployment diagram)
Каждая из этих диаграмм конкретизирует различные представления о модели системы. При этом, диаграмма вариантов использования представляет концептуальную модель системы, которая является исходной для построения всех остальных диаграмм. Диаграмма классов является логической моделью, отражающей статические аспекты структурного построения системы, а диаграммы поведения, также являющиеся разновидностями логической модели, отражают динамические аспекты её функционирования. Диаграммы реализации служат для представления компонентов системы и относятся к ее физической модели.
Из перечисленных выше диаграмм некоторые служат для обозначения двух и более подвидов. В качестве же самостоятельных представлений используются следующие диаграммы: вариантов использования, классов, состояний, деятельности, последовательности, кооперации, компонентов и развертывания.
Для диаграмм языка UML существуют три типа визуальных обозначений, которые важны с точки зрения заключенной в них информации:
связи, которые представляются различными линиями на плоскости;
текст, содержащийся внутри границ отдельных геометрических фигур;
графические символы, изображаемые вблизи визуальных элементов диаграмм.
При графическом изображении диаграмм рекомендуется придерживаться следующих правил:
каждая диаграмма должна быть законченным представлением некоторого фрагмента моделируемой предметной области;
представленные на диаграмме сущности модели должны быть одного концептуального уровня;
вся информация о сущностях должна быть явно представлена на диаграмме;
диаграммы не должны содержать противоречивой информации;
диаграммы не следует перегружать текстовой информацией;
каждая диаграмма должна быть самодостаточной для правильной интерпретации всех ее элементов;
количество типов диаграмм, необходимых для описания конкретной системы, не является строго фиксированным и определяется разработчиком;
модели системы должны содержать только те элементы, которые определены.
10. Сппр, их структура и место в асу.
АСУ – человеко-машинная система управления, которая на основе экономико-математических методов и технических средств сбора, передачи, переработки, хранения, обработки информации решает проблемы управления сложных объектов.
АСУ можно представить в виде схемы
ЭВМ
Управляющая
Система
Объект управления
Этапы обработки информации.
Сбор и регулирование информации
Передача информации
Представление информации
Хранение информации.


СПР Система принятия решения
СППР Система поддержки и принятия решений
ИС Информационная система


Объект управления
Для СППР Существует 7 этапов принятия решений:
Критериальная оценка ситуаций
Генерация всевозможных альтернатив решений.
Оценка возможных альтернатив решений.
Согласование решений в СППР.
Прогнозирование последствий принимаемых решений.
Выбор решения.
Оценка соответствия принятого решения намеченным целям.
Системный подход заключается в:
ориентации на конечный результат. Должна быть сформулирована цель и далее дерево целей.
Выделение и решение ключевых проблем на ЭВМ с ориентацией на цель системы. Ключевая требует наибольшего кол-ва ресурсов и результат наибольший.
Общая схема автоматизации решения задач.
Фу СППР 1) … 7)
Задачи автоматизации 1) … 6)


Хранение
База знаний База моделей данных
Задачи автоматизации
Формирование долговременных программ, проектов производства – стратегическое планирование.
Формирование структурно-образующих соотношений производства. Соотношение трудовых ресурсов и производственных связываются в структуры управления.
Формирование логистических проектов текущего планирования (годовое).
Логистические – любое производство имеет смысл, если есть производство, сбыт, покупка сырья. Эта цепочка должна работать с мин. затратами.
Календарное планирование. Расписание.
Получение и обработка данных в производственном процессе – оперативное планирование.
Оперативное регулирование. Сравнение плановых и фактических значений.
11. Деловые игры в разработке и внедрении асу.
Деловую игру можно определить как имитацию группы лиц, хозяйственной или организационной деятельности предприятия в учебных, производственных или исследовательских целях, выполняемую на модели объекта.
Деловую игру определяют так же как «устройство», предназначенное для воспроизводства и согласования хозяйственных интересов подсистем между собой и общей целью системы.
Под деловой игрой понимают поиск оптимальных решений многокритериальных производственных задач в условиях неопределенности и недостоверности имеющейся информации, анализ, выявление недостатков и путей их устранения для комплексной производственно-хозяйственной задачи с предельно распределенными ролями участников.
Деловая игра – имитационная игра, моделирующая деятельность производственно-хозяйственной системы.
В деловой игре всегда должны реализовываться черты игровой ситуации (их две):
Обязательное наличие противодействующих сторон или факторов, которые сознательно или непроизвольно влияют на поведение играющих и характер принимаемых решений.
Динамизм ситуации, направленный на изменение под воздействием решений участников игры.
Деловые игры можно классифицировать по следующим признакам:
Назначению:
Различают 3 типа игр:
1. Исследовательские игры:
2. Производственные игры:
3. Учебные игры:
Характеру моделируемых ситуаций:
Различают 3 вида игр:
1. Игры с соперником (одним или несколькими):
2. Игры с природой:
3. Игры – тренировки:
По характеру игрового процесса:
1. Игры, в которых отношения между играющими группами носят характер борьбы (соперничества). Контакт между группами необязателен.
2. Игры, в которых отношения между играющими группами носят характер борьбы (соперничества). Контакт между группами обязателен.
3. Игры – состязания:
По характеру развития игры во времени:
1. Ограниченное число шагов (этапов);
2. Неограниченное число шагов.
По способу передачи и обработки информации, уровню средств автоматизации:
1. Ручные игры - таблицы, графики, планшеты, монограммы;
2. Человеко–машинные игры – игры, ориентированные на работу ЭВМ в интерактивном режиме.
3. Игры, на специализированном оборудовании – тренажеры, игровые автоматы.
Метод оценки результатов деловой игры:
1. Свободный метод оценки – экспертная оценка руководителем игры и его помощников.
2. Жесткий метод оценки на основе формализованной модели.
3. Комбинированный метод оценки.
Структура деловой игры
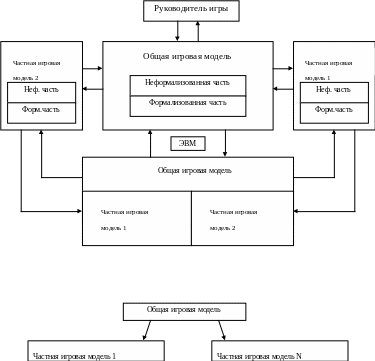
На этапе предпроектной стадии разработки АСУ деловая игра носит исследовательский характер.
Существует 3 типа проведения экспертиз:
Мозговой штурм – каждый говорит все, что хочет.
Стиль проведения:
- принимается все без возражений;
- критикуется все;
Метод анкетирования;
Метод Дельфи (Дельфы) – по какой-либо проблеме экспертом предлагается определиться (за они или против) , затем это все идет руководителю. Люди разбиваются на 3 кучки:

3 тура оказывается достаточным для принятия решения (коэффициент согласованности мнений ≈ 1)
12. Жизненный цикл комплексов программ.
Является моделью создания и ее использования. Отражает различные состояния системы, начиная с момента возникновения необходимости и заканчивая моментом полного выхода АСУ из употребления.
Традиционно и укрупнено жизненный цикл состоит из следующих этапов:
1)Анализ требований;
2)Проектирование;
3)Программирование и внедрение (реализация);
4)Тестирование и отладка;
5)Эксплуатация и сопровождение;
ISO – International Standard Organization - (основан в 1948 г.) – международные стандарты по самым различным направлениям. ISO-9000 – стандарты международного качества.
В соответствии со стандартами ISO жизненный цикл АСУ можно представить более подробно (9 пунктов):
1) Предпроектное обследование;
2) Системное и техническое проектирование;
3) Проектирование организационно-функциональной структуры;
4) Автоматизация и реинженеринг бизнес процесса;
5) Обучение пользователей и администраторов;
6) Проектирование и монтаж локальных сетей;
7) Поставка ,установка, запуск и обслуживание сетевого оборудования, сортировка;
8) Реализация и ввод в действие автоматизированной системы (внедренческие
узконаладочные работы, в том числе перенос данных из другой системы);
9) Сопровождение системы:
- устранение ошибок;
- расширение функций;
- тиражирование.
Существует 3 модели жизненного цикла АСУ:
1) Каскадная модель
Существовала до конца 80-х гг. Предполагает переход на следующий этап проектирования после полного окончания работ по предыдущему этапу.
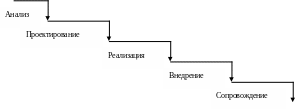
Недостатки: - ошибки накапливаются;
- ошибки сильно сказываются в процессе развития системы, т.к. назад вернуться нельзя.
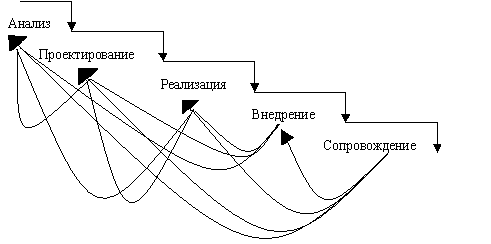
2) Поэтапная модель
Предполагает возможность обратных связей для любого предыдущего этапа
3) чаще всего используют спиральную модель жизненного цикла
Конец 80-х - начало 90-х гг.
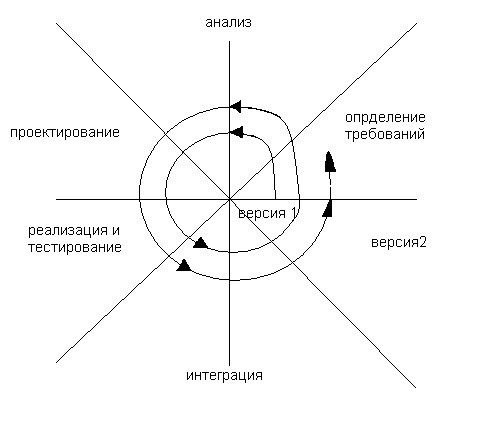
Делает упор на начальных этапах жизненного цикла, т.е. на анализе требований и проектировании, на этих этапах проверяется и обосновывается реализуемость технических решений путем создания прототипов.
Каждый виток спирали соответствует поэтапной модели создания фрагмента (версии системы), на нем уточняются цели и характеристики проекта, определяется его качество и определяется работа следующего витка спирали. Т.о. углубляются и последовательно конкретизируются детали проекта. В результате выбирается обоснованный вариант, который доводится до реализации.
Преимущества:
- накопление и повторное использование программных средств, модулей, прототипов;
- ориентация на развитие и модернизацию системы в процессе ее проектирования.
- анализ рисков и удержек в процессе проектирования.
13. Экспертные оценки и обработка результатов экспертизы.
Сущность метода экспертных оценок заключается в проведении экспертами интуитивно-логического анализа проблемы с количественной оценкой суждений и формальной обработкой результатов. Получаемое в результате обработки обобщенное мнение экспертов принимается как решение проблемы. При выполнении своей роли в процессе управления эксперты производят две основные функции: формируют объекты и производят измерение их характеристик.
Формирование объектов осуществляется экспертами на основе логического мышления и интуиции. При этом большую роль играют знания и опыт эксперта. Измерение характеристик объектов требует от экспертов знания теории измерений. В настоящее время в нашей стране и за рубежом метод экспертных оценок широко применяется для решения важных проблем различного характера. К первому классу относятся проблемы, в отношении которых имеется достаточный информационный потенциал, позволяющий успешно решать эти проблемы. Основные трудности в решении проблем первого класса при экспертной оценке заключаются в реализации существующего информационного потенциала путем подбора экспертов, построения рациональных процедур опроса и применения оптимальных методов обработки его результатов. Ко второму классу относятся проблемы, в отношении которых информационный потенциал знаний недостаточен для уверенности в справедливости указанных гипотез. При решении проблем из этого класса экспертов уже нельзя рассматривать как «хороших измерителей». Поэтому необходимо очень осторожно проводить обработку результатов экспертизы. Применение методов осреднения, справедливых для «хороших измерителей», в данном случае может привести к большим ошибкам. Например, мнение одного эксперта, сильно отличающееся от мнений остальных экспертов, может оказаться правильным. В связи с этим для проблем второго класса в основном должна применяться качественная обработка. Область применения метода экспертных оценок весьма широка. Типовые задачи, решаемые методом экспертных оценок:
1) составление перечня возможных событий в различных областях за определенный промежуток времени; 2) определение наиболее вероятных интервалов времени свершения совокупности событий; 3) определение целей и задач управления с упорядочением их по степени важности; 4) определение альтернативных (вариантов решения задачи с оценкой их предпочтения; 5) альтернативное распределение ресурсов для решения задач с оценкой их предпочтительности; 6) альтернативные варианты принятия решений в определенной ситуации с оценкой их предпочтительности. Для решения этих задач в применяются различные разновидности метода экспертных оценок. К основным видам относятся: анкетирование и интервьюирование; мозговой штурм; дискуссия; совещание; оперативная игра; сценарий. Каждый из этих видов экспертного оценивания обладает своими преимуществами и недостатками, определяющими рациональную область применения. Во многих случаях наибольший эффект дает комплексное применение нескольких видов экспертизы. Анкетирование и сценарий предполагают индивидуальную работу эксперта. Интервьюирование может осуществляться как индивидуально, так и с группой экспертов. Остальные виды экспертизы предполагают коллективное участие экспертов, в работе. Независимо от индивидуального или группового участия экспертов в работе целесообразно получать информацию от множества экспертов. Это позволяет получить на основе обработки данных более достоверные результаты, а также новую информацию о зависимости явлений, событий, фактов, суждений экспертов, не содержащуюся в явном виде в высказываниях экспертов. При использовании метода экспертных оценок возникают свои проблемы. Основными из них являются: подбор экспертов, проведение опроса экспертов, обработка результатов опроса, организация процедур экспертизы.
В зависимости от целей экспертного оценивания и выбранного метода измерения при обработке результатов опроса возникают следующие основные задачи:
1) построение обобщенной оценки объектов на основе индивидуальных оценок экспертов; 2) построение обобщенной оценки на основе парного сравнения объектов каждым экспертом; 3) определение относительных весов объектов; 4) определение согласованности мнений экспертов;
5) определение зависимостей между ранжировками; 6) оценка надежности результатов обработки.
14.Основные характеристики надежности невосстанавливаемых систем. Вероятность отказа.
Р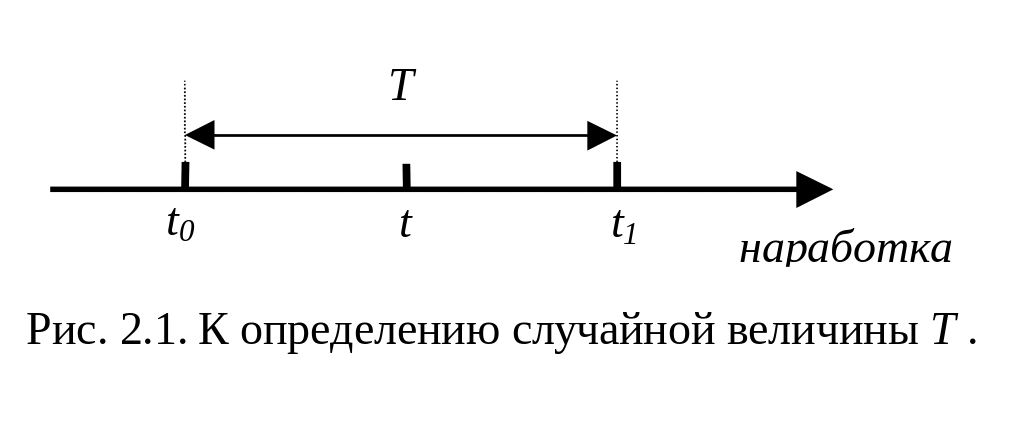 ассмотрим
некоторую техническую систему (элемент),
которая находится в работоспособном
состоянии. Пусть в момент времени t0
система начинает функционировать. Пусть
также в момент времени t1
от начала эксплуатации t0
наступает отказ системы, после которого
система отключается. Продолжительность
работы
системы для любого
ассмотрим
некоторую техническую систему (элемент),
которая находится в работоспособном
состоянии. Пусть в момент времени t0
система начинает функционировать. Пусть
также в момент времени t1
от начала эксплуатации t0
наступает отказ системы, после которого
система отключается. Продолжительность
работы
системы для любого
![]() ,
,
t > 0 называется наработкой, а случайная величина T = t1 - t0 определяет время работы системы (элемента) до наступления отказа* и называется наработкой до отказа (рис. 2.1).
Случайная наработка до отказа T, как и любая другая случайная величина, описывается некоторой теоретической функцией распределения
![]() .
.
Функция F(t) определяет вероятность P случайного события А, которое заключается в том, что наработка до отказа T не превышает некоторой заранее заданной величины t, т.е.
![]()
Для
исключения из рассмотрения систем
(элементов), которые к моменту начала
работы системы уже неисправны, потребуем,
чтобы
![]() .
При
.
При
![]() функция
F(t)
стремится к единице.
функция
F(t)
стремится к единице.
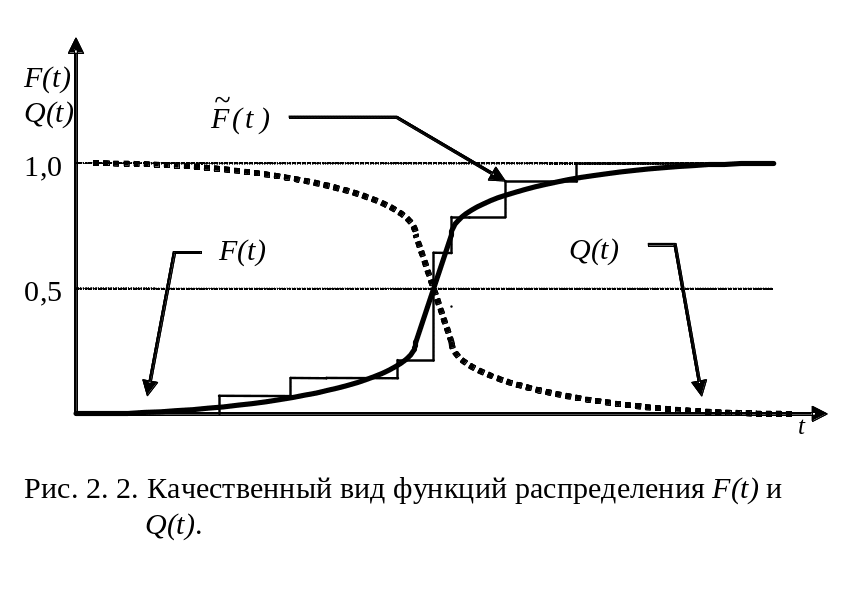
Таким образом, в общем виде, функция распределения F(t) есть неубывающая функция наработки t, которая определяет вероятность того, что отказ системы произойдет до значения длительности наработки меньшей или равной t. График функции F(t) для рассматриваемого случая представлен на рис. 2.2 жирной линией. По этой причине функцию (2.1) называют вероятностью отказа при длительности наработки t. Следовательно, вероятность отказа невосстанавливаемой системы при заданной длительности наработки t определяется как
![]() ,
(2.3)
,
(2.3)
где подстрочный индекс F в левой части равенства означает отношение определяемой величины именно к вероятности отказа.
Если
функции распределения (2.1) дифференцируема,
то её первая производная
![]() (2.4)
(2.4)
называется плотностью распределения.
Функция надежности.
Пусть теперь B есть событие, состоящее в ненаступлении отказа при длительности наработки t. Очевидно, в рамках конкретной невосстанавливаемой системы события, заключающиеся в наступлении (событие А) или ненаступлении (событие В) отказа для длительности наработки t, составляют полную группу событий, т.е. P(A) + P(B) = 1. Тогда
![]() (2.6)
(2.6)
При этом функцию Q(t) называют функцией надежности.
Таким образом, вероятность безотказной работы или функция надежности системы при длительности наработки t определяется выражением
![]() ,
(2.7)
,
(2.7)
где индекс Q в левой части (2.7) указывает на то, что в данном случае рассматривается вероятность безотказной работы. График функции надежности Q(t) показан на рис. 2.2 пунктирной линией.
Интенсивность
отказов![]()
![]()
Случайная
величина
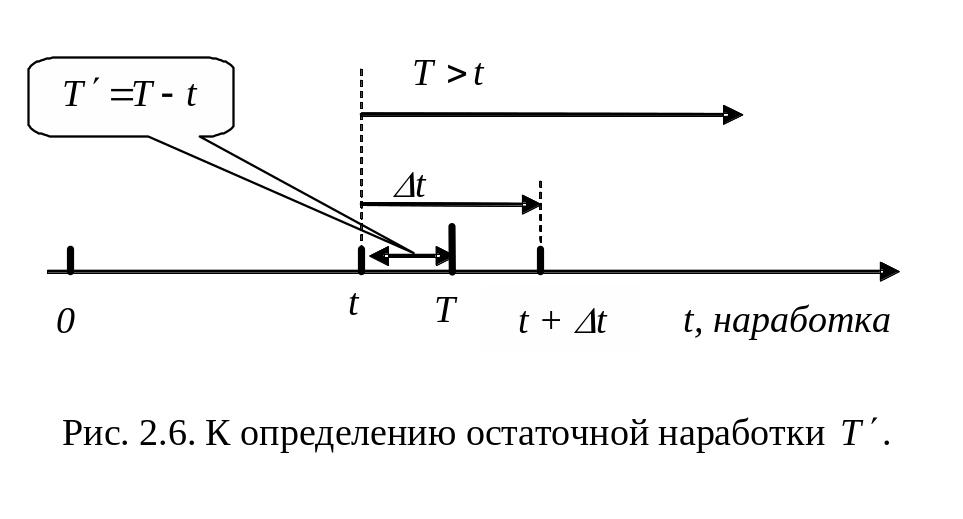
![]() называется остаточной
наработкой
(рис. 2.6). При этом случайная величина
называется остаточной
наработкой
(рис. 2.6). При этом случайная величина
![]() (остаточная
наработка до отказа) имеет функцию
распределения
(остаточная
наработка до отказа) имеет функцию
распределения
![]() ,
(2.16)
,
(2.16)
где индекс t в левой части подчеркивает, что до этого времени система работала безотказно.
Средняя наработка до отказа T0 или среднее время безотказной работы объекта (системы, элемента) определяется как математическое ожидание случайной величины Т
![]() ,
(2.17)
,
(2.17)
где символ M обозначает оператор, соответствующий правилу расчета математического ожидания.
Дисперсия и среднеквадратичное отклонение наработки до отказа:

Основные характеристики надежности восстанавливаемых систем.
В
том случае, если техническая система
(системы) является восстанавливаемой,
то, по определению, после наступления
каждого отказа должно следовать
восстановление системы либо посредством
замены отказавшего элемента системы,
либо посредством проведения определенного
комплекса ремонтных мероприятий. В
общем случае, для восстанавливаемых
систем случайной величиной является
не только наработка на отказ, но и
продолжительность (время) всех ремонтных
работ, непосредственно связанных с
восстановлением системы. Однако, как
правило, время
восстановления
![]() существенно
меньше средней
наработки на отказ
существенно
меньше средней
наработки на отказ
![]() .
В этом случае продолжительностью
(временем) восстановления пренебрегают,
полагая процедуру восстановления
мгновенной.
.
В этом случае продолжительностью
(временем) восстановления пренебрегают,
полагая процедуру восстановления
мгновенной.
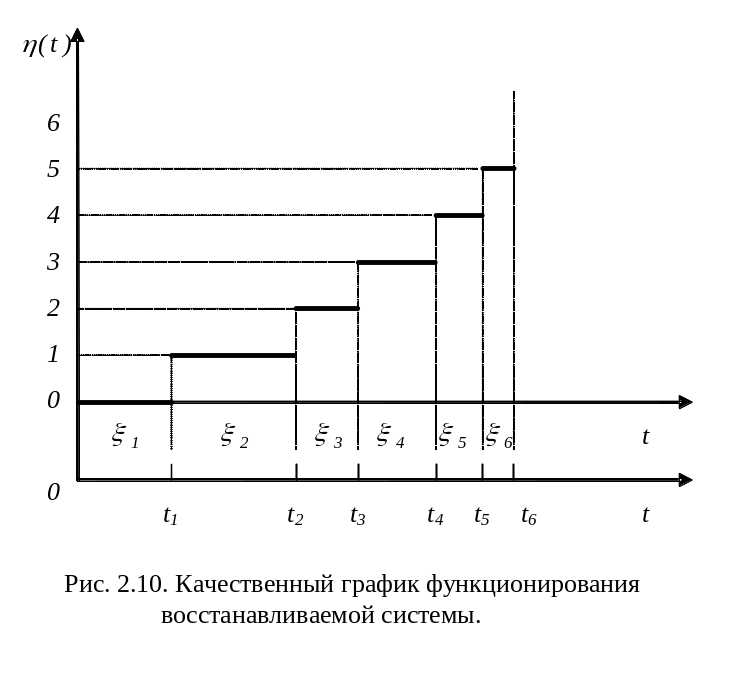
Система начинает функционировать в момент времени t0 =0. В какой-то случайный момент времени t1 происходит первый отказ. Согласно нашему допущению в этот же момент времени (мгновенно) происходит восстановление системы, после чего система продолжает функционировать. Далее в случайный момент времени t2 происходит второй отказ и связанное с этим отказом восстановление и т.д. Последовательность событий, связанных с наступлением отказов в случайное время, называется потоком отказов.
Математическое ожидание числа отказов за время t называется ведущей функцией
![]() ,
(2.55)
,
(2.55)
где W(t) - по смыслу, неотрицательная неубывающая функция.
Функция W(t) практически всегда дифференцируема. При этом величина
![]() (2.56)
(2.56)
называется параметром потока отказов.
Резервирование систем и элементов.
Повышение надежности достигается введением в структуру системы дополнительных резервных элементов. Такой вид резервирования называется структурным резервированием.
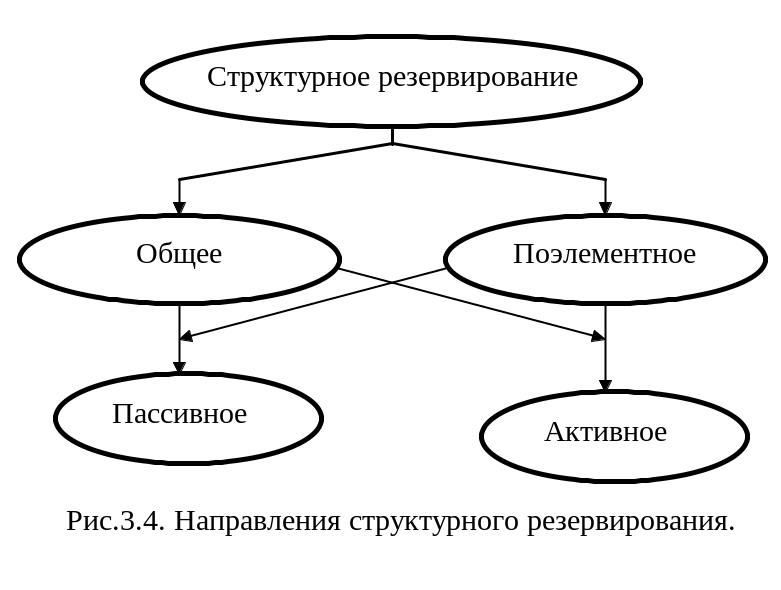
В системах структурного резервирования различают основные и резервные элементы. Общее резервирование предполагает резервирование системы в целом. В противном случае резервируются отдельные элементы или их группы. Пассивное и активное резервирование различаются способом введения резервных элементов. В первом случае, резервные элементы функционируют в системе наравне с основными элементами. Во втором случае, резерв вводится в основной состав системы посредством операции переключения только при отказе основного элемента. Другими словами происходит замещение отказавшего элемента резервным. В любом случае при отказе основного элемента его функции берет на себя резервный элемент. Следовательно, работоспособность такой системы обеспечивается до тех пор, пока для замены каждого отказавшего основного элемента имеется в наличии соответствующий резервный элемент. При этом в случае активного резервирования предполагается возможность оперативного и абсолютно надежного переключения резервного элемента в рабочее состояние.
Виды структурного резерва.
Ненагруженный резерв.
Элементы,
находящиеся в резерве не
работают.
Отсутствуют
условия, при
которых резервный элемент может перейти
в неработоспособное состояние (![]() ,
где
,
где
![]() -
интенсивность отказов в состоянии
резерва). Следовательно, для резервного
элемента показатели надежности остаются
неизменными.
-
интенсивность отказов в состоянии
резерва). Следовательно, для резервного
элемента показатели надежности остаются
неизменными.
Облегченный резерв.
Резервные
элементы находятся в нагруженном
состоянии,
но нагрузка является существенно
меньшей, чем нагрузка основных элементов.
В этом случае для заданного интервала
времени наработки вероятность отказа
основного элемента больше, чем вероятность
отказа резервного элемента (![]() ,
где
,
где
![]() -
интенсивность отказов основного
элемента).
-
интенсивность отказов основного
элемента).
3. Нагруженный резерв.
Резервные
и основные элементы одинаково нагружены
и являются стохастически эквивалентными.
В этом случае интенсивности отказов
основного и резервного элемента совпадают
(![]() ).
Для надежной работы системы при
нагруженном резерве нужно, чтобы число
работоспособных элементов не становилось
бы меньше определенного заданного
минимального значения.
).
Для надежной работы системы при
нагруженном резерве нужно, чтобы число
работоспособных элементов не становилось
бы меньше определенного заданного
минимального значения.
Параллельная структура.
Определение.
Параллельная структура (или резервное соединение) состоит из одного основного и n - 1 резервных элементов, которые находятся в нагруженном резерве (рис. 3.5).
Очевидно, параллельная структура только тогда работоспособна, когда по крайней мере один из входящих в неё элементов исправен. При этом наработка параллельной структуры до отказа запишется как
![]() .
.
Очевидно, для такой структуры вероятность отказа, в предположении о независимости отказов, входящих в эту структуру элементов, определяется как
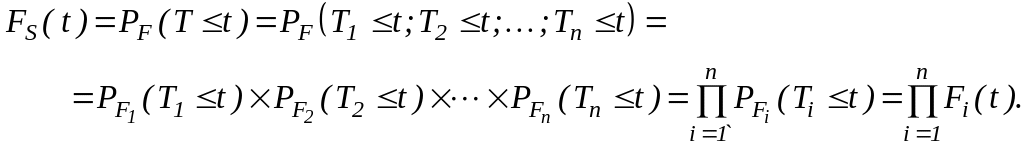
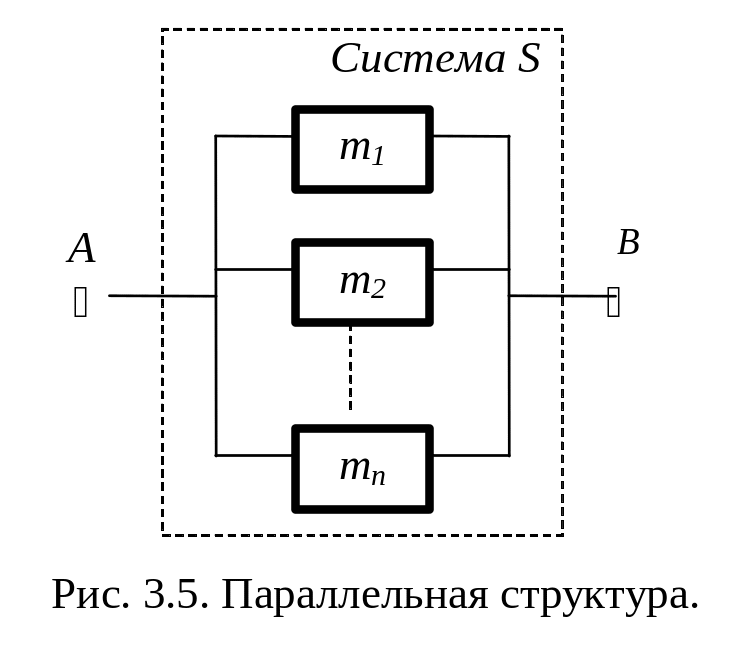
Тогда вероятность безотказной работы параллельной структуры (см. рис. 3.5) до фиксированного момента наработки t равна
![]() .
.
Структурное резервирование требует определенных затрат на резервные элементы. Тогда вложенные затраты должны окупаться снижением потерь от отказов технической системы за счет повышением её надежности. К числу основных показателей получаемого выигрыша за счет повышения надежности технической системы или сравнительных показателей эффективности использования различных способов резервирования относятся:
 -
повышение
средней наработки до отказа, где
-
повышение
средней наработки до отказа, где
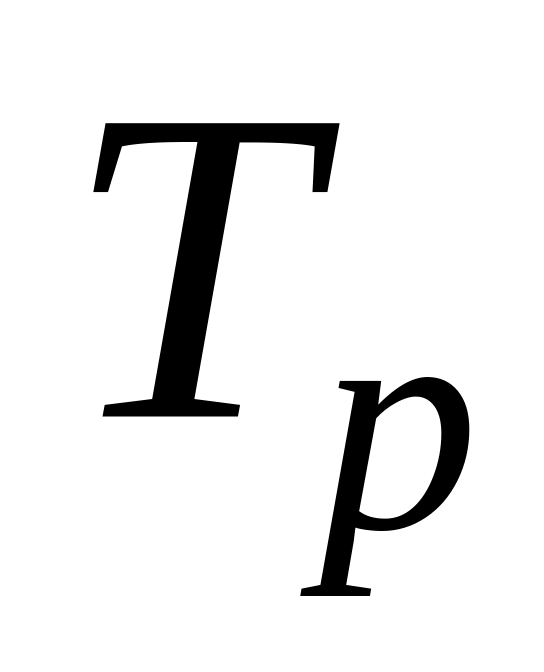 -
средняя наработка резервированной
системы;
-
средняя наработка резервированной
системы;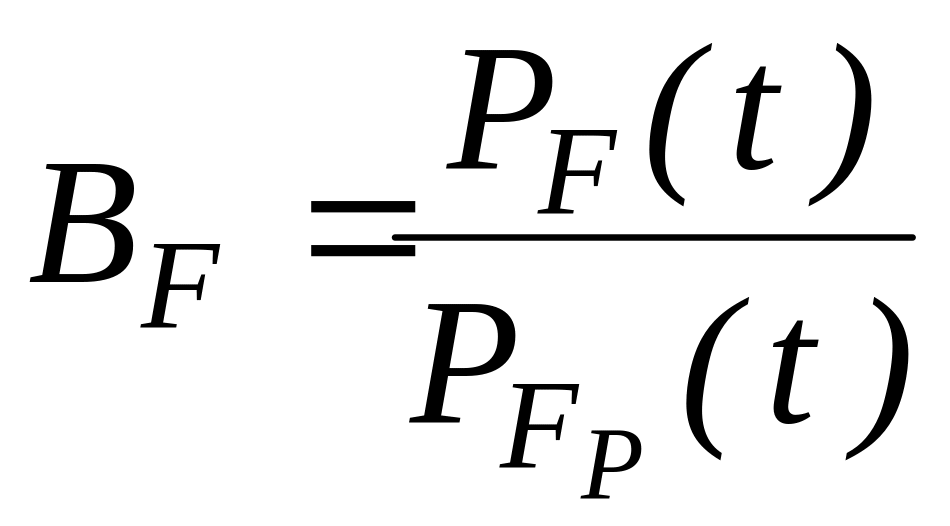 -
снижение
вероятности отказа, где
-
снижение
вероятности отказа, где
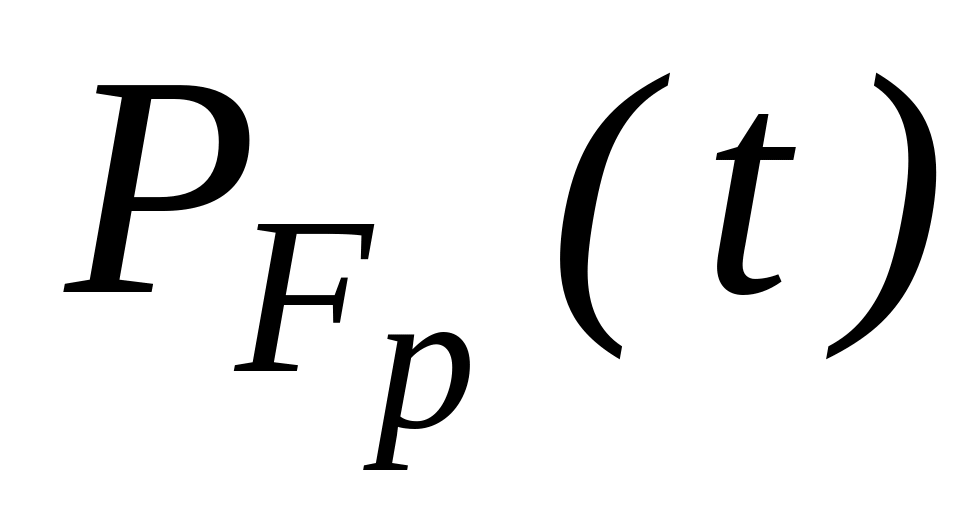 -
вероятность отказа резервированной
системы;
-
вероятность отказа резервированной
системы;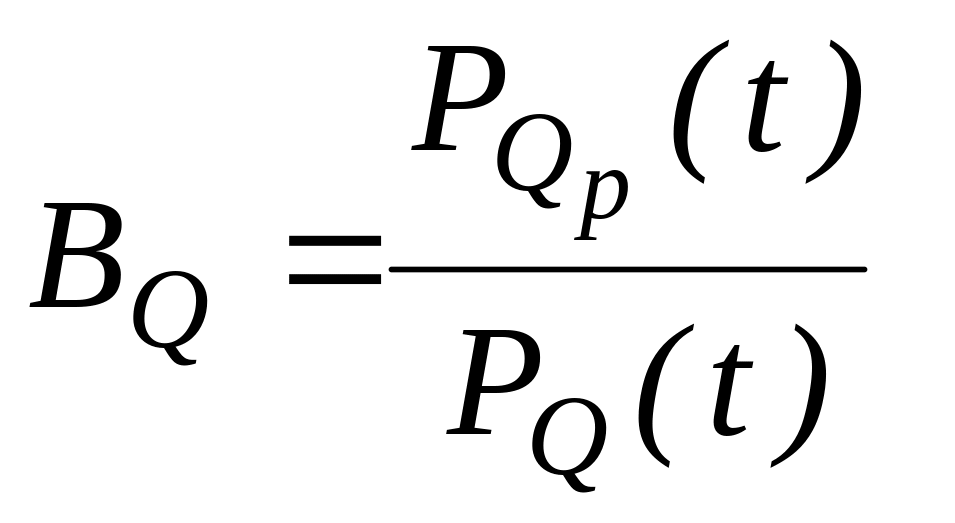 -
повышение
вероятности безотказной работы, где
-
повышение
вероятности безотказной работы, где
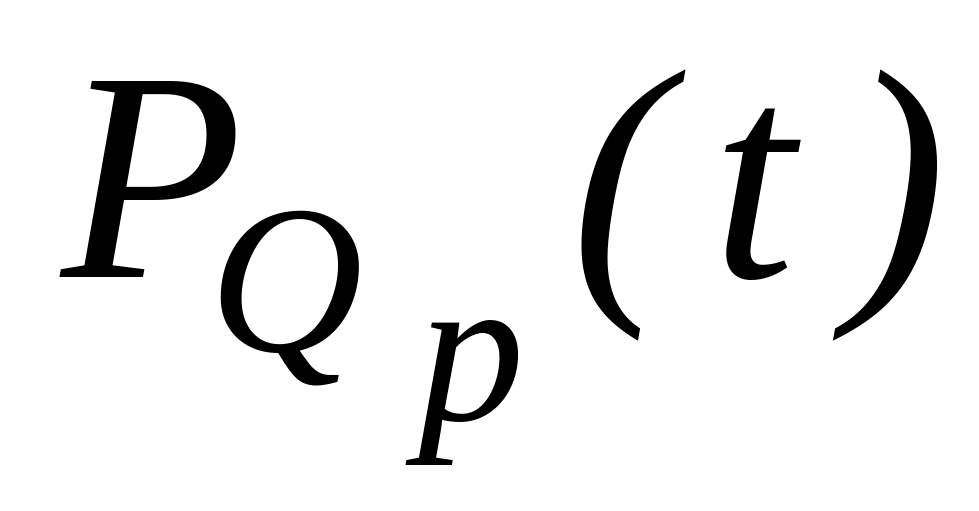 вероятность безотказной работы
резервированной системы.
вероятность безотказной работы
резервированной системы.
15.Структурные и функциональные методы тестирования программ. Методы оценки надежности программ.
Тестирование – это процесс, который заключается в проверке соответствия программного продукта или сайта заявленным характеристикам и требованиям, требованиям эксплуатации в различных окружениях, с различными нагрузками, требованиям по безопасности, требованиям по эргономике и удобству использования.
Функциональное тестирование. Этот вид тестирования проверяет соответствие реализованных функций требованиям, ТЗ, спецификациям, различным другим проектным документам и просто ожиданиям пользователя. Проверяется каждая из функций приложения и все они в комплексе. Исследуются все сценарии использования. Проверяется адекватность хранимых и выходных данных, методы их обработки, обработка вводимых данных, методы хранения данных, методы импорта и экспорта данных и т.д. в зависимости от специфики приложения.
Вы уверены, что поиск с использованием всех параметров на вашем сайте работает правильно? Вы проверяли все комбинации параметров? Подумайте, что если пользователь не найдет нужный товар, то вы потеряете часть своей прибыли!
Виды тестирования:
структурное тестирование (белый ящик),
функциональное тестирование (черный ящик)
Структурное тестирование
При данном подходе считается, что текст программы виден (белый ящик). Тестируются блоки ветвлений, циклы и т.д.
Существует несколько типов структурного тестирования:
покрытие операторов,
покрытие решений,
покрытие решений / условий,
комбинаторное покрытие условий,
тестирование циклов.
Функциональное тестирование
При данном подходе считается, что текст программы не виден, и программа рассматривается как черный ящик, т.е. известны входные и выходные условия, а также общая схема работы. Программа проверятся по ее спецификациям.
Существуют несколько видов функционального тестирования:
эквивалентные классы,
анализ граничных значений,
тестирование на предельных нагрузках,
тестирование на предельных объемах,
тестирование защиты,
эксплуатация системы самим разработчиком (если возможно),
опытная эксплуатация.
Техническое, информационное и программное обеспечение АСУ
16. Защита информации в асу. Программно – технические меры.
Методы защиты должны обеспечить:
защиту от несанкционированного доступа
целостность – защита от несанкционированного изменения
доступность – защита от несанкционированного удержания информации и ресурсов
В настоящее время разработано большое количество методов, средств и мероприятий по защите информации
законодательные меры.
организационные мероприятия
физические меры
программно – технические меры:
идентификация и аутентификация
управление доступом
протоколирование и аудит
криптография
экранирование
идентификация и аутентификация :
идентификация – присвоение какому либо объекту или субъекту уникального образа, имени или числа. Аудентификация – проверка, является ли проверяемый объект в самом деле тем за кого себя выдает.
ПАРОЛИ: Существует несколько видов паролей:
метод простого пароля – пользователь вводит строку символов
пороль типа “запрос - ответ” - используется набор ответов на вопросы
“рукопожатие” – система защиты может потребовать подлинность с помощью корректной обработки алгоритма.
ТОКЕН – разделение пароля на 2 части. 1- ая вводится пользователем, а 2-ая хранится на носителе – токен. Токен – предмет или устройство владение которым подтверждает подлинность пользователя.
Управление доступом – позволяют определять и контролировать действия которые пользователи могут выполнить над объектом. Логический контроль доступом должен обеспечить конфедициальность и целостность объектов. Для принятия решения о предоставлении доступа обычно анализируется следующая информация:
идентификатор субъекта (сетевой адрес ПК) – основа произвольного управления доступом
атрибуты субъекта ( метка безопасности, группа в которую входит пользователь) – основа принудительного доступа
время действия
внутренние ограничения сервиса: число одновременно работающих
Протоколирование и аудит - одно из эффективных средств. Ведется журнал в котором записываются все попытки доступа к программам и данным.
Криптография – наука о защите информации, делится на 2 части: криптографию и криптоанализ. Использование криптографии – один из распрастраненный методов, значительно повышающих безопасность передачи данных в сетях ЭВМ и безопасность данных хранящихся в устройствах памяти. Криптоаналитик должен взломать защиту, разработанную криптографом. Для шифрования обычно используется некоторый алгоритм или устройство. Управление процессом шифрования проводится с помощью переодически меняющегося кода ключа. Знание ключа позволяет просто и надежно расшифровать текст.
Методы закрытия информации:
шифрование
кодирование
Экранирование – в настоящее время широко применяется экраны. Некоторые межсетевые экраны позволяют организовывать виртуальные корпоративные сети.
Для повышения надежности защиты в одной сети можно использовать несколько экранов стоящих друг за другом.
17.Практические подходы к созданию и поддержанию информационной безопасности
Информационные стандарты и рекомендации, рассмотренные ранее, образуют базис, на котором строятся все работы по обеспечению информационной безопасности. Однако, стандарты статичны, они не учитывают постоянной перестройки защищаемых систем и их окружения. Во-вторых, стандарты не содержат практических рекомендаций по формированию режима безопасности. В-третьих, стандарты ориентированы на производителей и организации, занимающиеся сертификацией систем.
Проблема обеспечения безопасности носит комплексный характер, для ее решения необходимо сочетание законодательных, организационных и программно-технических мер.
Программно-технические меры включают следующие механизмы безопасности: идентификация и аутентификация; управление доступом; протоколирование и аудит; криптография; экранирование.
Создание системы безопасности организация должна начать с выработки политики безопасности. Под политикой безопасности понимается совокупность документированных управленческих решений, направленных на защиту информации и связанных с ней ресурсов.
С практической точки зрения политику безопасности делят на три уровня:
1. К верхнему уровню относят решения, затрагивающие организацию в целом. Они носят общий характер и исходят от руководства организации.
2. К среднему уровню относят вопросы, касающиеся отдельных аспектов информационной безопасности, но важные для различных систем, эксплуатируемых организацией.
3. Политика безопасности нижнего уровня относится к конкретным информационным сервисам.
После завершения формирования политики безопасности, переходят к составлению программы ее реализации. Проведение политики безопасности в жизнь требует использования трех видов регуляторов - управленческих, операционных (организационных) и программно-технических.
I. Управленческие мероприятия
Для реализации программы безопасности, ее целесообразно разделить на уровни, обычно в соответствии со структурой организации. В простом и самом распространенном случае достаточно двух уровней: верхнего и нижнего (сервисного), который относится к отдельным сервисам или группе однородных сервисов.
Программу верхнего уровня возглавляет лицо, отвечающее за информационную безопасность организации. Программа должна занимать четко определенное место в деятельности организации, она должны официально приниматься и поддерживаться руководством, у нее должны быть определенные штаты и бюджет. У программы следующие главные цели:
- управление рисками. Деятельность любой организации подвержена множеству рисков. Суть работы по управлению рисками состоит в том, чтобы оценить их размер, выработать эффективные меры по их уменьшению и убедиться, что риски заключены в приемлемые рамки;
- координация деятельности. Управление должно быть организовано так, чтобы исключить дублирование в деятельности сотрудников и в максимальной степени использовать их знания. Однако, отсутствие дублирования противоречит надежности. Если в организации есть специалист, знания которого уникальны, его временное отсутствие или увольнение могут привести к затруднительной ситуации. Поэтому целесообразно документировать накопленные знания и освоенные процедуры.
- стратегическое планирование. На верхнем уровне принимаются стратегические решения по безопасности, оцениваются технологические новинки. Информационные технологии развиваются очень быстро, и необходимо иметь четкую политику отслеживания и внедрения новых средств.
- контроль деятельности. Контроль деятельности имеет два направления:
1. Надо гарантировать, что действия организации не противоречат законам. Обязательны при этом контакты с внешними контролирующими организациями;
2. Нужно постоянно отслеживать состояние безопасности внутри организации, реагировать на случаи нарушений, дорабатывать защитные меры с учетом изменения обстановки.
Цель программы нижнего уровня - обеспечить надежную и экономичную защиту конкретного сервиса или группы однородных сервисов. На этом уровне решается, какие механизмы защиты использовать, закупаются и устанавливаются технические средства, выполняется повседневное администрирование, отслеживается состояние слабых мест. Обычно за программу нижнего уровня отвечают администраторы сервисов.
II. Организационные мероприятия
При выработке политики безопасности большое значение имеют меры безопасности, ориентированные на людей. Именно люди формируют режим информационной безопасности и они же оказываются главной угрозой для нее. К вопросам, связанными с людьми, относится:
- управление персоналом;
- организация физической защиты;
- поддержание работоспособности;
- реагирование на нарушение режима безопасности;
- планирование восстановительных работ.
18. Криптографические методы защиты. Симметричные, асимметричные алгоритмы.
I. Симметричное шифрование
В вычислительных системах широко применяется шифрование с закрытым ключом (симметричное шифрование). При этом один и тот же ключ используется как для кодирования, так и декодирования. При этом обе стороны должны знать секретный ключ, который формируется в центре ( ВЦ головной организации, штаб военной организации и т.п.). В такой системе центр не только снабжает пользователей ключами, но и несет ответственность за сохранение их в секрете при изготовлении и доставке.
Центр генерации ключей
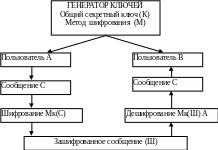
Ключ Ключ
Схема симметричного метода шифрования
Алгоритм des
Метод DES основан на комбинированном использовании перестановки, замены и
гаммированиии. Основные достоинства алгоритма:
используется только один ключ длиной 56 бит;
зашифровав сообщение с помощью одного пакета программ, для расшифровки можно использовать любой другой пакет программ, соответствующий стандарту DES;
относительная простота алгоритма обеспечивает высокую скорость обработки;
достаточно высокая стойкость алгоритма.
Другие симметричные криптоалгоритмы
В России аналогом DES является стандарт ГОСТ 28147-89.
Алгоритм IDЕA (International Data Encryption Algorithm)
Алгоритм RC2
Алгоритм RC5
Алгоритм CAST
Алгоритм Blowfish
AES.
II. Асимметричное шифрование
В 70-х годах были разработаны методы шифрования с открытым ключом: для шифрования используется один ключ, а для расшифровки - другой. Такая пара ключей называется открытый /закрытый ключ.
Открытый ключ спокойно передается партнеру, который передает сообщение, зашифрованное открытым ключом. При этом сообщение, зашифрованное с помощью открытого ключа, нельзя расшифровать этим же открытым ключом. Расшифровать подобное сообщение можно только с помощью закрытого ключа владельца.
Чтобы упростить процесс обмена шифрованными сообщениями, открытые ключи всех абонентов единой сети связи часто помещают в справочную базу данных, находящуюся в общем пользовании этих абонентов.
Алгоритм rsa
В криптографии с открытым ключом используют необратимые или односторонние функции, которые обладают следующими свойствами:
при заданном значении Х относительно просто вычислить значение f(Х), однако если У=f(Х), то нет простого пути для вычисления Х, т.е. очень трудно вычислить f -1 (У). Другими словами, невозможно вычислить один ключ из другого.
В России аналогом RSA является ГОСТ 34.10.
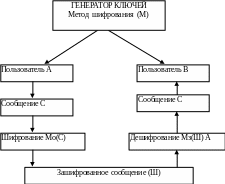
Открытый Закрытый
ключ (О) ключ (З)
Схема асимметричного метода шифрования
Чтобы использовать алгоритм RSA, сначала надо сгенерировать открытый и закрытый ключи по следующему сценарию.
1. Выбрать два больших простых числа p и q.
2. Определить n=p*q.
3. Выбрать большое случайное число d, которое должно быть взаимно простым с результатом умножения (p-1)*(q-1)
4. Определить такое число e, для которого выполняется соотношение
(e*d) mod ((p-1)*(q-1)) = 1
5. Назовем открытым ключом числа e и n, закрытым ключом - d и n.
Чтобы зашифровать данные по известному ключу {e,n} выполняют следующие шаги:
1. Разбить исходный текст на блоки, в котором каждый символ можно обозначить целым числом от 0 до (n-1).
2. Зашифровать текст, рассматриваемый как последовательность чисел М(i), над каждым из которых выполняется операция С(i)=(M(i)e) mod n.
Чтобы раскрыть данные, используя секретный ключь {d,n} необходимо выполнить вычисления M(i)=(C(i)d) mod n.
В результате будет получено исходное множество чисел M(i).
19. Средства обеспечения сетевой защиты: межсетевые экраны, системы обнаружения атак, системы анализа защищенности. (Леонов).
Многие организации принимают решение о включении своей локальной сети в Internet. Однако при этом возникает ряд проблем: как защитить локальную сеть от несанкционированного доступа, как скрыть информацию о структуре своей сети от внешнего пользователя, как разграничить права доступа внутренних пользователей, запрашивающих сервисы сети. Для решения задач защиты данных организации используют межсетевые экраны (FireWall, брандмауэры).
МЭ – это компьютер со специальным программным обеспечением, который препятствует несанкционированному доступу к информационным ресурсам предприятия, кроме того, МЭ защищает от поступления из внешней среды нежелательной информации без ведома пользователей.
Основные типы межсетевых экранов
1. Фильтрующие маршрутизаторы
ФМ представляет собой маршрутизатор или работающую на сервере программу, построенную таким образом, чтобы фильтровать входящие и выходящие пакеты. Фильтрация пакетов выполняется на основе информации в TCР и IP- заголовках пакетов.
2. Шлюзы сеансового уровня
Шлюз сеансового уровня по-другому называют системой трансляции сетевых адресов или шлюзом сетевого уровня модели OSI. Шлюз сеансового уровня принимает запрос доверенного клиента на конкретные услуги, и после проверки допустимости запрошенного сеанса устанавливает соединение с внешним хост-компьютером. После этого шлюз копирует ТСР-пакеты в обоих направлениях, не осуществляя их фильтрации. По окончании сеанса шлюз разрывает цепь, использованную в данном сеансе. Для копирования и перенаправления пакетов в шлюзах сеансового уровня применяются специальные приложения, которые называются канальными посредниками, поскольку они устанавливают между двумя сетями виртуальную цепь или канал, а затем разрешают пакетам, которые генерируются приложениями TCP/IP проходить по этому каналу.
Шлюз сеансового уровня выполняет еще одну важную функцию защиты: он используется в качестве сервера посредника. Сервер-посредник выполняет процедуру трансляции адресов, при которой происходит преобразование внутренних IP-адресов в единственный IP-адрес, т.е. IP-адрес сеансового шлюза становится единственно активным IP-адресом, который попадает во внешнюю сеть. Таким способом шлюз сеансового уровня и другие серверы-посредники защищают внутренние сети от нападения типа подмены адресов.
3. Шлюзы прикладного уровня
Для проверки содержимого пакетов, формируемых определенными сетевыми службами типа Telnet, FЕP, межсетевые экраны используют дополнительные программные средства. Такие программные средства называются полномочными серверами- посредниками, а компьютер, на котором они выполняются – шлюзами прикладного уровня. ШПУ исключает прямое взаимодействие между авторизованным клиентом и внешним хост-компьютером. ШПУ фильтруют все входящие и исходящие пакеты на прикладном уровне. Например, они могут фильтровать FTP-соединения и запрещать прохождение команды PUT, что не позволит пользователям записывать информацию на анонимный FTP-сервер.
В дополнение к фильтрации пакетов многие шлюзы прикладного уровня регистрируют все выполняемые сервером действия и предупреждают сетевого администратора о возможных нарушениях защиты.
Основные схемы сетевой защиты на базе межсетевых экранов
При подключении корпоративной или локальной сети к глобальным сетям администратор сетевой безопасности должен решить следующие задачи:
защита локальной сети от НСД со стороны внешней сети;
скрытие информации о структуре внутренней сети и ее компонентов от пользователей внешней сети;
разграничение доступа в защищаемую сеть из внешней сети и из внутренней сети во внешнюю.
Часто у организации возникает потребность иметь в составе внутренней сети несколько сегментов с разными уровнями защищенности:
свободно доступные сегменты (например, рекламный WWW-сервер);
сегмент с ограниченным доступом (например, для доступа сотрудникам организации с удаленных узлов);
закрытые сегменты (например, финансовая локальная сеть организации).
1. Межсетевой экран - Фильтрующий маршрутизатор
Это самый распространенный и наиболее простой способ организации МЭ. Фильтрующий маршрутизатор располагается между защищаемой сетью и Internet. ФМ сконфигурирован для блокирования или фильтрации входящих/исходящих пакетов на основе анализа их адресов и портов. Компьютеры, находящиеся в защищаемой сети, имеют прямой доступ с Internet, в то время как большая часть доступа к ним извне, блокируется.
Фильтрующий
маршрутизатор
Локальная сеть


2. Межсетевой экран с прикладным шлюзом и фильтрующим маршрутизатором.
Между ШПУ и ФМ образуется внутренняя экранированная подсеть. Эту подсеть можно использовать для размещения доступных извне информационных серверов.В этой схеме ШПУ полностью блокирует трафик IP между Internetи защищаемой сетью. Только полномочные сервера-посредники, размещенные на ШПУ, могут предоставлять услуги и доступ пользователям. Данный вариант межсетевого экрана реализует политику безопасности по принципу «запрещено все, что не разрешено в явном виде», при этом пользователю недоступны все службы, кроме тех, для которых определены соответствующие полномочия. Такая схема обеспечивает высокий уровень безопасности, поскольку маршруты к защищенной подсети известны только межсетевому экрану и скрыты от внешних систем.
Информационный
сервер
Локальная сеть
ФМ
Прикладной шлюз

Межсетевой экран на основе экранированного шлюза
В этой схеме первичная безопасность обеспечивается ФМ. Пакетная фильтрация в ФМ может быть реализована одним из следующих способов:
позволять внутренним компьютерам открывать соединения с внешними компьютерами в сети Internet для определенных сервисов (разрешая доступ к ним средствами пакетной реализации);
запрещать все соединения от внутренних компьютеров (заставляя их использовать полномочные серверы-посредники на прикладном шлюзе).
Эти подходы можно комбинировать для различных сервисов, разрешая некоторым сервисам соединения непосредственно через пакетную фильтрацию, а другим только непрямое соединение через полномочные серверы-посредники. Данная схема получается довольно гибкой, но менее безопасной по сравнению со схемой 2.
Информационный
сервер

ФМ
Локальная сеть


Прикладной шлюз
Межсетевой экран – экранированная подсеть
Для создания экранированной подсети используются два экранирующих маршрутизатора.
Информационный
сервер

Локальная сеть
ФМ
ФМ


Экранированная
подсеть
Сервер электронной
почты
Прикладной шлюз
Экранируемая подсеть содержит прикладной шлюз, а также может включать
информационные сервера и другие системы, требующие контролируемого доступа. Эта схема обеспечивает хорошую безопасность, благодаря наличию экранированной подсети.
Внешний маршрутизатор запрещает доступ из Internet к системам внутренней сети и блокирует весь трафик к Internet, идущий от систем, которые не должны являться инициаторами соединений (например, информационный сервер).
Внутренний маршрутизатор защищает внутреннюю сеть как от Internet, так и от
экранированной подсети (в случае ее компроментации), он осуществляет большую часть пакетной фильтрации.
Прикладной шлюз может включать программы усиленной аутентификации.
Данная схема подключения хорошо подходит для защиты сетей с большими объемами трафика или с высокими скоростями обмена.
Недостатки данной схемы:
- применение двух ФМ требует повышенного внимания для обеспечения необходимого уровня безопасности, т.к. из-за ошибок в их конфигурировании могут возникнуть провалы в безопасности всей сети.
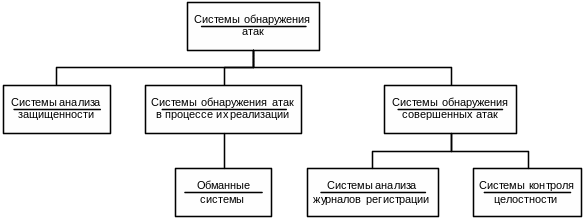
Рисунок 1. Классификация систем обнаружения атак по этапам осуществления атаки
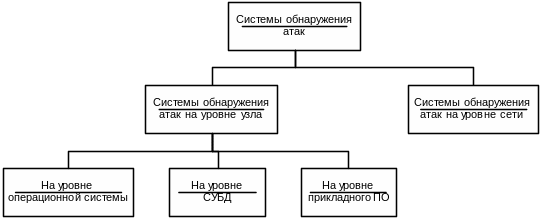
Рисунок 2. Классификация систем обнаружения атак по принципу реализации
Системы анализа защищенности
Системы анализа защищенности, также известные как сканеры безопасности или системы поиска уязвимостей, проводят всесторонние исследования систем с целью обнаружения уязвимостей, которые могут привести к нарушениям политики безопасности. Результаты, полученные от средств анализа защищенности, представляют "мгновенный снимок" состояния защиты системы в данный момент времени. Несмотря на то, что эти системы не могут обнаруживать атаку в процессе ее развития, они могут определить потенциальную возможность реализации атак.
Функционировать системы анализа защищенности могут на всех уровнях информационной инфраструктуры, т. е. на уровне сети, операционной системы, СУБД и прикладного программного обеспечения. Наибольшее распространение получили средства анализа защищенности сетевых сервисов и протоколов. Связано это, в первую очередь, с универсальностью используемых протоколов. Изученность и повсеместное использование таких стеков протоколов, как TCP/IP, SMB/NetBIOS и т. п. позволяют с высокой степенью эффективности проверять защищенность информационной системы, работающей в данном сетевом окружении, независимо от того, какое программное обеспечение функционирует на более высоких уровнях. Вторыми по распространенности являются средства анализа защищенности операционных систем. Связано это также с универсальностью и распространенностью некоторых операционных систем (например, UNIX и Windows NT). Однако, из-за того, что каждый производитель вносит в операционную систему свои изменения (ярким примером является множество разновидностей ОС UNIX), средства анализа защищенности ОС анализируют в первую очередь параметры, характерные для всего семейства одной ОС. И лишь для некоторых систем анализируются специфичные для нее параметры. Средств анализа защищенности СУБД и приложений на сегодняшний день не так много, как этого хотелось бы. Такие средства пока существуют только для широко распространенных прикладных систем, типа Web-броузеров Netscape Navigator и Microsoft Internet Explorer, СУБД Microsoft SQL Server и Oracle, Microsoft Office и BackOffice и т. п.
При проведении анализа защищенности эти системы реализуют две стратегии. Первая - пассивная, - реализуемая на уровне операционной системы, СУБД и приложений, при которой осуществляется анализ конфигурационных файлов и системного реестра на наличие неправильных параметров; файлов паролей на наличие легко угадываемых паролей, а также других системных объектов на предмет нарушения политики безопасности. Вторая стратегия, - активная, - осуществляемая в большинстве случаев на сетевом уровне, позволяющая воспроизводить наиболее распространенные сценарии атак, и анализировать реакции системы на эти сценарии.
21 Основные направления развития искусственного интеллекта.
Искусственный интеллект (ИИ) - это программная система, имитирующая на компьютере мышление человека. Для создания такой системы необходимо изучать процесс мышления человека, решающего определенные задачи или принимающего решения в конкретной области, выделить основные шаги этого процесса и разработать программные средства, воспроизводящие их на компьютере. Следовательно, методы ИИ предполагают простой структурный подход к разработке сложных программных систем принятия решений. Основные проблемы ИИ - поиск и представление знаний, разработка теоретических представлений и создание для ЭВМ соответствующих программ наиболее общего характера. Принято считать, что всякая задача, для которой неизвестен алгоритм решений, априорно относится к ИИ. Итак, сфера ИИ объединяет те области, в которых нет абсолютно точных методов решения задачи и которым присущи две характерные особенности:
- использование информации в символьной форме (буквы, слова, знаки, рисунки), что отличает от традиционного представления данных в числовой форме;
- наличие выбора, т.е. недетерминизма.
Недетерминизм отражает свободу действия, т.е. существенную составляющую интеллекта. Наличие недетерминизма носит фундаментальный характер, так как отражает реальную ситуацию выбора между многими вариантами в условиях неопределенности.
Наиболее известными направлениями развития ИИ являются: восприятие и распознавание образов; математика и автоматическое доказательство теорем; игры; решение повседневных задач (роботехника); понимание естественного языка.
В ИИ выделяют следующие направления развития: экспертные системы (ЭС), или иногда их называют системы, основанные на знаниях (СОЗ); естественно-языковые системы (ЕЯ-системы); нейронные сети (НС); нечеткие системы (fuzzy-логика).К этому можно добавить генетические алгоритмы и средства для извлечения знаний.
Экспертные системы - наиболее развитое направление ИИ. ЭС - это информационная технология, использующая опыт и знания специалистов для решения плохо формализованных задач. ЭС представляет собой программный продукт, который решает задачи в интересующей нас предметной области. Появление ЭС и их использование в различных сферах человеческой деятельности явилось результатом исследований в области искусственного интеллекта.
Типовые задачи применения ЭС: интерпретация; прогноз; диагностика планирование; мониторинг; управление; обучение; ремонт. Выделяют два класса ЭС - статические системы и динамические (системы реального времени). Основой для построения ЭС являются: оболочки (shell); инструментированные средства; языки ИИ; языки общего назначения.
В области работ по Е-Я системам выделяют следующие категории.
Е-Я-интерфейс к базам данных.
Е-Я-поиск в текстах и содержательное сканирование текстов.
Масштабируемые средства для распознавания речи
Средства голосового ввода, управления и сбора данных
Компоненты речевой обработки. Реально наибольшее распространение в этом направлении ИИ получили системы машинного перевода, программы контроля/исправления правописания и стиля, смешанные системы.
в) Нейронные сети (НС).
Технология НС нашла широкое применение в таких областях, как финансовая сфера ( управление кредитными рисками, предсказание ситуаций на фондовом рынке, оценка стоимости недвижимости), химия (конструирование химических формул) распознавание оптических символов (optical character recognition-OCR), управление процессами.
.
.22 Анализ моделей представления знаний. Представление знаний правилами и логический вывод. Представление знаний фреймами, семантическими сетями, на основе логики предикатов.
1.Представление знаний правилами и логический вывод. Одной из важных задач, которую инженер знаний должен разрешить до работ, связанных непосредственно с реализацией ЭС на ЭВМ, является выбор модели представления знаний оптимальной для конкретной задачи. Моделью в случае представления знаний правилами является система продукций. Продукционные правила, составляющие базу знаний (БЗ), есть выражения вида: Е С Л И (условие), Т О (действие). Это операция “импликация”, или как ее иначе называют “логическое следование”. Продукционная система состоит из трех компонентов: База знаний (БЗ) содержит набор правил. Рабочая память (РП) предназначена для кратковременного хранения предпосылок и результатов вывода. Механизм логического вывода (МВ) использует правила в соответствии с содержимым рабочей памяти. Продукционную БЗ можно представить в виде графа И/ИЛИ. Механизм логического вывода - это стратегия поиска решения на графе логического вывода. Обычно это сводится к механизму выбора соответствующего правила из конфликтного набора. Конфликтный набор - это множество правил, которые могут быть применены на конкретном этапе логического вывода. Управление логическим выводом имеет большое значение, так как существенен порядок выдачи запросов пользователю и оптимальность набора запрашиваемых данных. Существует два способа использования правил: прямая цепочка рассуждений; обратная цепочка рассуждений. При прямой цепочке рассуждений на каждом этапе логического вывода анализируется текущее состояние рабочей области, содержащей факты, и активизируются те продукции, условная часть которых принимает значение “истина”. Выбранное правило активизируется и факт, являющийся заключением, заносится в рабочую область. Процесс продолжается до определения целевого утверждения. Обратная цепочка рассуждений. При этом методе сначала активизируются правила, способные подтвердить целевую гипотезу. Затем факты, входящие в условную часть этих правил, устанавливаются промежуточными целями, и система старается их означить. При этом нет необходимости осуществлять полный перебор правил БЗ.
2 Представление знаний семантической сетью Базовый функциональный элемент семантической сети - это структура из двух компонент: узла и дуги. Узел - это объект, концепция, событие, понятие. Дуга - отношение между парами понятий. Каждое отношение отражает факт. Дуги имеют направленность и возможно отношение “субъект - объект”. Так как каждый из узлов может быть соединен с любым числом других узлов, то можно получить сеть фактов.
3 Представление знаний фреймами В основе теории фреймов лежит восприятие фактов посредством сопоставления, полученной извне информации, с конкретными элементами и значениями, а также с определенными в нашей памяти рамками, отражающими каждый концептуальный объект. Каждый фрейм можно рассматривать как сеть, состоящую из нескольких вершин и отношений. На самом верхнем уровне фрейма представлена фиксированная информация: факт, касающийся состояния объекта, который обычно считается истинным. На последующих уровнях расположено множество так называемых терминальных слотов, которые должны быть заполнены конкретными значениями и данными: Имя фрейма - идентификатор, являющийся уникальным для каждого фрейма в системе. Имя слота - идентификатор, присваиваемый слоту фрейма. Он должен быть уникальным для каждого фрейма. Указатель наследования, показывающий, какую информацию об атрибутах слотов фрейма верхнего уровня наследуют слоты с тем же именем производных фреймов. Атрибут слота указывает тип данных слота. Значение слота. Демон.
4 .
Понятие предиката. В
логике предикат
– понятие, определяющее предмет суждения
и раскрывающее его содержание. Для
описания предметной области в логике
предикатов используются: константы;
переменные; термы; предикаты; кванторы.
Предикатный
символ P используется для представления
отношений между объектами данной
предметной области.
.
Понятие предиката. В
логике предикат
– понятие, определяющее предмет суждения
и раскрывающее его содержание. Для
описания предметной области в логике
предикатов используются: константы;
переменные; термы; предикаты; кванторы.
Предикатный
символ P используется для представления
отношений между объектами данной
предметной области.
Предикат как логические функции принимает только два значения: истина и ложь. Предикаты служат для описания языковой системы, для которой необходимо задать следующие компоненты.
Множество знаков (т.е. алфавит).
Полное определение слов через знаковые последовательности (морфемы);
Грамматические правила образования предложений и слов.
Неотъемлемой частью языка предикатов является задание двух типов слов, первый тип описывает сущности изучаемой предметной области и называется термы; второй тип описывает атрибуты и поведение атрибутов, то есть отношения и называется предикат.
23Структура и типы экспертных систем, их роль и место в АСУ.
Экспертные системы - наиболее развитое направление ИИ. ЭС - это информационная технология, использующая опыт и знания специалистов для решения плохо формализованных задач. ЭС представляет собой программный продукт, который решает задачи в интересующей нас предметной области. Появление ЭС и их использование в различных сферах человеческой деятельности явилось результатом исследований в области искусственного интеллекта. Типовые задачи применения ЭС: интерпретация; прогноз; диагностика планирование; мониторинг; управление; обучение; ремонт. Этапы разработки: идентификация (формулирование задачи); концептуализация (определение места в системе, выбор инструментальных средств); формализация (формулировка правил); реализация; тестирование. Выделяют два класса ЭС - статические системы и динамические (системы реального времени). Основой для построения ЭС являются: оболочки (shell); инструментированные средства; языки ИИ; языки общего назначения. Предпочтение отдается инструментальным средствам. При построении ЭС наибольшую популярность получили языки Prolog, Lisp и Си ++. ЭС взаимодействует с пользователем или с экспертом через специальный диалоговый интерфейс, при разработке которого основной задачей является создание естественно-языковой среды общения. Эксперт через модуль приобретения знаний имеет возможность дополнять систему новыми знаниями. Пользователь системы получает консультацию по введенному запросу, находясь в режиме активного диалога с машиной логического вывода через интерфейс пользователя. Машина логического достигает оценки целевого утверждения, взаимодействуя с базой знаний системы, используя при этом данные, заложенные в базу данных, или запрашивая их у пользователя. Модуль объяснений позволяет аргументировать пользователю обоснованность решения задачи и промежуточных выводов.
В последние годы широкое развитие получили динамические ЭС, или экспертные системы реального времени (ЭСРВ), успех которых определен: - переходом к специализированным (проблемно/предметным) инструментальным средствам, что влечет сокращение сроков разработки приложений и позволяет повторно использовать информационное и программное обеспечение (объекты, классы, правила, процедуры); - использованием языков традиционного программирования и рабочих станций, что обеспечивает снижение требований приложений к быстродействию компьютера и объемам памяти, упрощение “интегрированности”, увеличение круга приложений; - интегрированностью; - открытостью и переносимостью; - использованием архитектуры “клиент-сервер”. ЭСРВ решают задачи, в которых: данные изменяются во времени, поступают от внешних источников и их необходимо хранить и анализировать; выполняются одновременно временные рассуждения о нескольких асинхронных задачах; обеспечивается механизм рассуждений при ограниченных ресурсах;
обеспечивается “предсказуемость“ поведения системы, т. е. запущенная задача выполняется в строгом соответствии с временными ограничениями; моделируется окружающий мир, в котором отражаются различные состояния; протоколируются действия; эффективно и удобно обеспечивается наполнение базы знаний (эту возможность предоставляет объектно-ориентированный подход); обеспечивается настройка системы на решаемые задачи; реализуется пользовательский интерфейс для различных категорий.
Перспективным следует считать применение ЭС для поддержки диспетчерских решений, а также применение ЭС как реального средства системной интеграции при управлении сложными системами. Анализ показывает, что произошли качественные изменения в системе управления технологическими процессами, что существенно трансформировало функции и условия работы диспетчерского персонала. Диспетчер, работая и современной информационной среде, при возникновении нештатных ситуаций испытывает трудности в принятии решений. Это ситуации типа “что, если...”, в которых необходима подсказка-совет, основанный на правилах, сформированных на основе жизненного опыта и/или модельных расчетах. Такой советующей системой является ЭСРВ
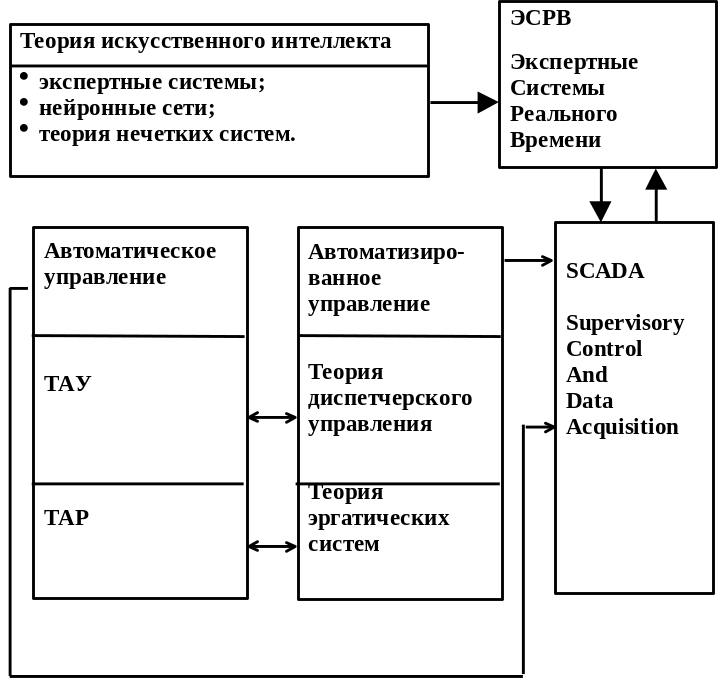
24. . Нечеткие системы и методы определения функций принадлежности.
Четкое
множество –
это такое множество, функция принадлежности
элементов которого имеет всего два
значения:![]() .
.
У нечеткого множества функция принадлежности элемента множества принимает значение от 0 до 1 (как дискретное, так и непрерывное).
Формально это описывается следующим образом:
![]()
![]() функция
принадлежности элемента Х множеству
А.
функция
принадлежности элемента Х множеству
А.
![]() некоторое
множество. 1 – это элемент, 0,8- это функция
принадлежности.
некоторое
множество. 1 – это элемент, 0,8- это функция
принадлежности.
Методы определения функции принадлежности:
Оптимизационный.
Экспертный.
Аналитический.
Оптимизационный метод.
Если решение (альтернатива) удовлетворяет условиям, оно считается оптимальным (для чётких задач программирования).
Задача нечёткого математического программирования – это задача выбора варианта проекта.
 1,
если на i-ый
объект назначен j-ый
проект
1,
если на i-ый
объект назначен j-ый
проект
xij=
0 в противном случае
cij – эффективность назначения i-го объекта на j-ый проект
аhij – количество ресурсов h-го вида, необходимое для реализации j-го проекта на i-ом объекте.
Ah – общее количество ресурсов h-го вида.
Формулируем задачу:
F
 =∑∑
xij
cij
~ max
=∑∑
xij
cij
~ max
i j
~ - выполняется приближённо. (2)
Q=∑∑ aij cij ≤ Ah
i j ~
∑ xij = 1
i (1)
∑ xij =1
j

1 0 0 0
Xl = 0 1 0 0 - Эти условия (1) обозначают, что одному объекту назначается
0 0 1 0 только один проект.
0 0 0 1
Задача нечёткого математического программирования предполагает, что искомый результат может не попасть в экстремум или не до конца удовлетворять условиям. Говорят, что нечёткое математическое программирование близко к выбору решения человеком.
Нечёткое решение – решение, которое точно выполняет ограничения (1) и присерно выполняет ограничения (2).
μF(X)=1 – точный экстремум.
μQ(X)=1 – ресурсное ограничение выполняется точно.
Если μF(X)=0 и μQ(X)=0, то решение очень плохое.
Fтек – Inf F(x)
μF(X) = ------------------------
Sup F(x) - Inf F(x)
Inf и Sup – верхняя и нижняя границы критерия.
Для задачи минимизации:
Sup F(x) – Fтек
μF(X) = ------------------------
Sup F(x) - Inf F(x)
Критерий оптимальности примерно попадает в экстремум.
1, при Q≤ Ah;
Qтек - Ah
μQ= ------------- , при A*<Q< Ah;
A* - Ah
0, при Q>A*.
μ




 Q
Q
Ah A* Xl
ΔA = A* - Ah
Таким образом, мы определяем функцию принадлежности, приводим задачу к стандартному виду и решаем по принципу Беллмана – Заде.
Принцип Беллмана – Заде
(принцип гарантированного результата)
![]()
Пусть имеется несколько альтернатив и они оцениваются по различным критериям их качества. Предположим, что чем лучше качество альтернативы, тем лучше значение критерия. Предположим также, что, если значение критерия экстремально, то и вычисленная на его основе функция принадлежности равна 1 (отличная альтернатива) или 0 (плохая альтернатива).
Пример:
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
µ1 |
0,5 |
0,3 |
0,1 |
0 |
1 |
1 |
0,4 |
0,7 |
0,9 |
µ2 |
0,4 |
0,8 |
0,4 |
0 |
1 |
0,9 |
0,5 |
0,6 |
0,6 |
µ3 |
0,7 |
0,2 |
0,3 |
1 |
0,7 |
0,6 |
0,1 |
0,2 |
0,3 |
µ4 |
0,6 |
0,6 |
0,6 |
0,3 |
0,6 |
0,6 |
0,6 |
0,7 |
0,6 |
µД |
0,4 |
0,2 |
0,1 |
0 |
0,6 |
0,6 |
0,1 |
0,2 |
0,3 |
 A
µi
A
µi5, 6 альтернативы – лучшие среди этих 9 + здесь же можно упомянуть генетический алгоритм
2. Экспертный метод.
Экспертных методов существует очень много, так как каждый эксперт придумывает свой способ определения функции принадлежности. Но существуют общие подходы к формированию этих способов.
Рассмотрим их на примере задачи, придуманной японцами: идентификация лица человека по словесному портрету. Решается она следующим методом:
Метод семантических дифференциалов (смысловых отличий).
Практически в каждой области можно получить множество шкал оценок, используя следующую процедуру:
Определить список свойств, по которым оценивается понятие «объект», или «процесс»;
Найти в этом списке полярные свойства и сформировать полярную шкалу;
Для каждой пары полюсов в этой шкале оценить понятие на то, как сильно оно обладает положительным свойством. Чаще всего для этого приходится ответить на вопрос «да/нет». Рассчитать функцию принадлежности.
Пример.
1. Формирование списка свойств:
х1 – высота лба;
х2 – форма носа;
х3 – цвет глаз;
х4 – форма подбородка, и т.д.
2. Полярные свойства:
Положительные Отрицательные
х1 высокий низкий
х2 горбатый курносый
х3 темный светлый
х4 квадратный острый
3. Функция принадлежности рассчитывается по отношению к некоторому эталону, обладающему всеми положительными свойствами. Закодируем положительные свойства как 1, отрицательные как 0. Количество единиц на объект определяется экспертом. Функция принадлежности – это отношение экспертной оценки к эталону.
Обобщение.
В общем виде процедура экспертного способа определения функции принадлежности складывается из трех этапов:
Определение условий, обеспечивающих назначение функции принадлежности;
Оценка состояния системы экспертом;
Обработка результатов экспертизы.
Для определения условий, которые обеспечивают назначение функции принадлежности, необходимо, чтобы:
система классов, на которых рассматривается конкретный объект, представляла собой противоположные события
кривая интенсивности
отказа

50%
30%
30%

система классов должна быть полной.
Из второго условия и из факта существования двух видов экспертов вытекает существование двух видов экспертиз:
Состояние системы |
Степень проявления в классе |
||
Класс 1 |
… |
Класс m |
|
х1 |
30% |
… |
20% |
… |
|
|
|
xn |
10% |
… |
44% |
Порядковый номер эксперта |
Степень проявления в классе |
||
Класс 1 |
… |
Класс m |
|
1 |
1 |
… |
0 |
… |
|
|
|
n |
0 |
… |
0 |
Во втором случае эксперт отвечает только «да» или «нет». Такая таблица составляется для каждого состояния объекта. Недостаток такой экспертизы в большой трудоемкости: определении среднего мнения, коэффициента конкордации и т.д.
При попарном сравнении объектов экспертами используется другой метод определения функции принадлежности:
Метод Саати.
Саати предложил проставлять в таблице балльную оценку bij при сравнении объектов:
i \ j |
1 |
2 |
3 |
4 |
5 |
1 |
1 |
1 |
2 |
5 |
5 |
2 |
1 |
1 |
0 |
3 |
4 |
3 |
1/2 |
0 |
1 |
0 |
0 |
4 |
1/5 |
1/3 |
0 |
1 |
0 |
5 |
1/5 |
1/4 |
0 |
0 |
1 |
bij – оценка предпочтения i-го объекта над j-м;
bji = 1/ bij.
1 – одинаковые (эквивалентные) объекты;
3 – один объект имеет некоторое преимущество перед другим;
5 – определенное преимущество;
7 – сильное преимущество;
9 – подавляющее преимущество (абсолютный приоритет);
2, 4, 6, 8 – промежуточные значения.
При такой оценке существует опасность нарушения транзитивности.
Если матрица Саати непротиворечива, то преимущества объектов можно выразить вектором приоритетов Пi. Можно доказать, что вектор приоритетов есть нормированный собственный вектор матрицы.
![]()
Оценка согласованности матрицы Саати:
![]()
где n – размерность матрицы,
λmax – максимальное значение главного собственного вектора матрицы.
Для получения λmax необходимо сложить элементы i-го столбца, умножить на i-й элемент вектора приоритетов и сложить полученные по всей матрице произведения.
Доказано, что для абсолютно согласованной матрицы Саати λmax – n = 0.
Чем меньше kc, тем более согласованна матрица. На практике матрица может быть согласованной при kc ≤ 0,2.
3. Аналитический метод.
Функция принадлежности определяется аналитически.
μ(x) = [ 1 + (a – (x – c))b ] – 1
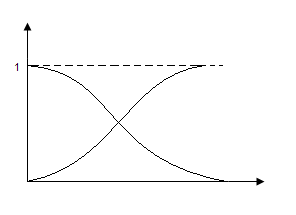
Неудобство определения функции принадлежности аналитическим методом состоит в том, что неизвестно, откуда необходимо брать экспертные оценки.
25 Дерево целей и дерево решений.
Дерево целей – это структурированная, построенная по иерархическому принципу (распределенная по уровням, ранжированная) совокупность целей экономической системы, программы, плана, в которой выделены генеральная цель («вершина дерева»); подчиненные ей подцели первого, второго и последующего уровней («ветви дерева»). Название «дерево целей» связано с тем, что схематически представленная совокупность распределенных по уровням целей напоминает по виду перевернутое дерево. Концепция «дерева целей» впервые была предложена Ч. Черчменом и Р. Акоффом в 1957 году. Она позволяет человеку привести в порядок собственные планы, увидеть свои цели в группе. Независимо от того, являются ли они личными или профессиональными. В том числе, дерево целей позволяет выявить, какие возможные комбинации обеспечат наилучшую отдачу. Термин «дерево» предполагает использование иерархической структуры (от старшей к младшей), полученной путем разделения общей цели на подцели. Метод дерева целей (рис.1) ориентирован на получение относительно устойчивой структуры целей, проблем, направлений. Для достижения этого при построении первоначального варианта структуры следует учитывать закономерности целеобразования и использовать принципы формирования иерархических структур. Этот метод широко применяется для прогнозирования возможных направлений развития науки, техники, технологий, а также для составления личных целей, профессиональных, целей любой компании. Так называемое дерево целей тесно увязывает между собой перспективные цели и конкретные задачи на каждом уровне иерархии. При этом цель высшего порядка соответствует вершине дерева, а ниже в несколько ярусов располагаются локальные цели (задачи), с помощью которых обеспечивается достижение целей верхнего уровня.
|
Дерево целей рис.1 |
Составленное дерево целей имеет систему решений на бумаге. То есть план по достижению ОСНОВНОЙ цели рис.1 - I (1). Дерево целей может быть составлено и для любой цели: глобальной, месячной, годичной. Принцип разбиения общей цели на подцели и задачи иллюстрирует схема, представленная на рисунке 2. Когда составлено дерево целей, можно просмотреть, к чему приведет та или иная цель. Например, цель (рис.2) «выпустить новый вид товара» может привести к снижению объема ранее выпускаемых товаров и, как следствие, к совершенно обратному результату – снижению прибыли. Именно дерево целей позволило это увидеть. А также, именно дерево целей позволит скорректировать данную цель и создать либо дополнительные рабочие места, либо, к примеру, проанализировать выпускаемую продукцию с целью выявления продукта с минимальной прибылью, дабы именно его заместить новым продуктом.
|
рис.2 сокращенное дерево целей |
О том, какие должны быть цели (которые записаны в графах), о правилах их составления вы можете прочесть в статье «Как правильно поставить цель?». Правила в данной статье показывают, как именно нужно вписать цель, и в какой последовательности. Чтобы закрепить результат изученного материала, рекомендую вам составить свое дерево целей. Если захотите получить анализ вашего дерева целей, пришлите его мне, будем анализировать.
Дерево решений
Своевременная разработка и принятие правильного решения — главные задачи работы управленческого персонала любой организации. Непродуманное решение может дорого стоить компании. На практике результат одного решения заставляет нас принимать следующее решение и т. д. Когда нужно принять несколько решений в условиях неопределенности, когда каждое решение зависит от исхода предыдущего решения или исходов испытаний, то применяют схему, называемую деревом решений.
Дерево решений — это графическое изображение процесса принятия решений, в котором отражены альтернативные решения, альтернативные состояния среды, соответствующие вероятности и выигрыши для любых комбинаций альтернатив и состояний среды.
Рисуют деревья слева направо. Места, где принимаются решения, обозначают квадратами □, места появления исходов — кругами ○,возможные решения — пунктирными линиями --------, возможные исходы — сплошными линиями ——.
Для каждой альтернативы мы считаем ожидаемую стоимостную оценку (EMV) — максимальную из сумм оценок выигрышей, умноженных на вероятность реализации выигрышей, для всех возможных вариантов.
Пример 1. Главному инженеру компании надо решить, монтировать или нет новую производственную линию, использующую новейшую технологию. Если новая линия будет работать безотказно, компания получит прибыль 200 млн. рублей. Если же она откажет, компания может потерять 150 млн. рублей. По оценкам главного инженера, существует 60% шансов, что новая производственная линия откажет. Можно создать экспериментальную установку, а затем уже решать, монтировать или нет производственную линию. Эксперимент обойдется в 10 млн. рублей. Главный инженер считает, что существует 50% шансов, что экспериментальная установка будет работать. Если экспериментальная установка будет работать, то 90% шансов зато, что смонтированная производственная линия также будет работать. Если же экспериментальная установка не будет работать, то только 20% шансов за то, что производственная линия заработает. Следует ли строить экспериментальную установку? Следует ли монтировать производственную линию? Какова ожидаемая стоимостная оценка наилучшего решения?
Рисунок 1 (нажмите для увеличения).
В узле F возможны исходы «линия работает» с вероятностью 0,4 (что приносит прибыль 200) и «линия не работает» с вероятностью 0,6 (что приносит убыток -150) => оценка узла F. EMV( F) = 0,4 x 200 + 0,6 х ( -150) = -10. Это число мы пишем над узлом F.
EMV(G) = 0.
В узле 4 мы выбираем между решением «монтируем линию» (оценка этого решения EMV( F) = -10) и решением «не монтируем линию» (оценка этого решения EMV(G) = 0): EMV(4) = max {EMV( F), EMV(G)} = max {-10, 0} = 0 = EMV(G). Эту оценку мы пишем над узлом 4, а решение «монтируем линию» отбрасываем и зачеркиваем.
Аналогично:
EMV( B) = 0,9 х 200 + 0,1 х (-150) = 180 - 15 = 165.
EMV(С) = 0.
EMV(2) = max {EMV(В), EMV(С} = max {165, 0} = 165 = EMV(5). Поэтому в узле 2 отбрасываем возможное решение «не монтируем линию».
EM V(D) = 0,2 х 200 + 0,8 х (-150) = 40 — 120 = -80.
EMV( E) = 0.
EMV(3) = max {EMV(D), EMV(E)} = max {-80, 0} = 0 = EMV( E). Поэтому в узле 3 отбрасываем возможное решение «монтируем линию».
ЕМ V( A) = 0,5 х 165 + 0,5 х 0 — 10 = 72,5.
EMV(l) = max {EMV(A), EMV(4)} = max {72,5; 0} = 72,5 = EMV( A). Поэтому в узле 1 отбрасываем возможное решение «не строим установку».
Ожидаемая стоимостная оценка наилучшего решения равна 72,5 млн. рублей. Строим установку. Если установка работает, то монтируем линию. Если установка не работает, то линию монтировать не надо.
26
Генетические алгоритмы - направление развития ИИ (+тетр по Юдовскому)
Генетический Алгоритм представляет собой метод, отражающий естественную эволюцию методов решения проблем, в первую очередь задач оптимизации.
Генетические Алгоритмы - процедуры поиска, основанные на механизмах естественного отбора и наследования.
Они основаны на генетических процессах биологических организмов: биологические популяции развиваются в течении нескольких поколений, подчиняясь законам естественного отбора и по принципу "выживает наиболее приспособленный".
Примеры:
проектировать структуры моста, для поиска максимального отношения прочности/веса,
интерактивного управления процессом, например на химическом заводе, или балансировании загрузки на многопроцессорном компьютере.
Вполне реальный пример: израильская компания Schema разработала программный продукт Channeling для оптимизации работы сотовой связи путем выбора оптимальной частоты, на которой будет вестись разговор.
Отличия генетических алгоритмов (от традиционных методов оптимизации):
Обрабатывают не значения параметров самой задачи, а их закодированную форму
Осуществляют поиск решения исходя не из единственной точки, а из их некоторой популяции
Используют только целевую функцию, а не ее производные и иную дополнительную информацию
Применяют вероятностные, а не детерминированные правила выбора
Терминология:
Хромосома – закодированный массив искомых параметров (вектор из нулей и единиц). Каждая позиция (бит) называется геном
Индивидуум (набор хромосом) – потенциальное решение задачи
Популяция – набор индивидумов
Эволюция – итерационный процесс оптимизации популяции с преобразованием индивидов
Поколение – номер итерации процесса эволюции
Кроссовер - операция, при которой две хромосомы обмениваются своими частями.
Мутация - случайное изменение одной или нескольких позиций в хромосоме.
Этапы алгоритма:
Инициализация – формирование исходной популяции
Оценивание приспособленности – расчет функции приспособленности. Чем больше значение этой функции, тем выше «качество» хромосомы
Проверка условия остановки – определение условий зависит от конкретного применения
Селекция – выбор хромосом для создания потомков следующей популяции
Применение генетических операторов – для формирования новой популяции потомков с помощью:Оператора скрещивания и Оператора мутации
Выбор «наилучшей» хромосомы – с наибольшим значением функции приспособленности
Селекция хромосом (метод рулетки): Каждой хромосоме сопоставим сектор колеса рулетки, величиной пропорциональной значению функции приспособленности Чем больше сектор, тем выше вероятность «победы»
Скрещивание: Выберем пары хромосом из родительской популяции случайным образом в соответствии с вероятностью скрещивания Определим точку скрещивания: если хромосома состоит из L генов, то выберем случайным образом число из интервала [1,L-1] В результате получим пару потомков
Мутация : Оператор мутации с вероятностью мутации изменяет значение гена в хромосоме на противоположное. Вероятность мутации очень мала. Она может генерироваться случайным числом из интервала [0,1] для каждого гена. Мутация происходит, если значение меньше наперед заданной величины
Особенности алгоритма:
В классическом генетическом алгоритме используется: Двоичное представление хромосом Селекция методом рулетки Точечное скрещивание (с одной точкой скрещивания)
Модификации алгоритма: Другие методы селекции Модификация генетических операторов скрещивания Преобразование функции приспособленности (масштабирование) Иные способы кодирования хромосом
27. Динамические системы. Модели представления в пространстве состояний. Модели "Выход-вход".
Представление систем в пр-ве состояний (рассм. линейный случай)

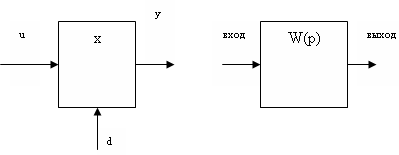
-
временная область
частотная область
Модели в пр-ве состояний получаются из моделей описания объектов с использованием классических законов сохранения энергии, массы, кол-ва движения и.т.д.
![]()
оригинал = изображение = одностороннее преобразование Лапласа
Требования к исходной ф-ии для применен преобр. Лапласа:
ф-ия д.б. непрерывной для всех значений t>=0, непрерывность может быть нарушена только в отдельных точках, число которых конечно, а эти точки – точки разрыва непрерывности 1-го рода.
ф-ия f(t) =0 for all t<0
ф-ия f(t) имеет ограниченный порядок возрастания.
Если ф-ия удовл. этим 3-м требованиям то ф-ия называется оригиналом .
Решение дифуров состояния:
Стационарные(автономные)
Нестационарные(с перемен коэф-ми)
Оба решения делятся на однородн. и неоднородн.
а). Решение скалярного дифура x(t)=etx(o)
б). Матричное диф. уравнение Ф(t)=eAt – переходная матрица системы (фундаментальная матрица)
в). Неоднородное диф. уравнение.
Переход от временной к частотной области.
Данный перход является однозначным если ф-ия удовлетворяет условиям преобразования Лапласа.
Переход от частотной области к временной.
Он не является однозначным потому что по одной и той же передаточной ф-ии можно построить целое семейство ур-ий а пр-ве состояний. Передаточная ф-ия – это рациональные дроби, и если числитель и знаменатель имеют общие корни, то после их сокращения эквивалентность модели нарушается.
Модели выход/вход в пр-ве состояний эквивалентны тогда и только тогда, когда выполняется условие управляемости и наблюдаемости.
28. Агрегативные системы. Агрегативный подход к моделированию сложных систем.
Элементы структурного анализа агрегативных систем.
Математические схемы сложных систем:
Непрерывно – детерминированные системы – это динамические системы (Д- системы)
Дискретно – детерминированные системы (F – схема, конечные автоматы)
Дискретно – стохастические системы (Р- схема, стохастический автомат)
Непрерывно – стохастические системы (Q – схемы)
Агрегатные системы (агрегативные, А- схема)
Особенность заключена в том, что в терминах агрегата можно описать 1,2,3,4 схемы.
УАИМ – универсальная автоматизированная имитационная модель.
А

 грегат
– это
обобщенная математическая модель,
которая задается рядом множеств и
операторов.
грегат
– это
обобщенная математическая модель,
которая задается рядом множеств и
операторов.
Т – множество моментов времени Х – множество входных сигналов
У – множество выходных сигналов Z - множество состояний системы
В – множество консультивных сигналов G – множество управляющих сигналов
Н (VI , VII , U) – оператор перехода из одного состояния в другое
VI – реагирует при подаче входного сигнала Х
VII – реагирует при подаче управляющего сигнала G
U – эволюционный оператор
R (R I , R II) – оператор выхода
R
 I
– отвечает
за момент выдачи сигнала, R
II
– отражает
содержание сигнала
I
– отвечает
за момент выдачи сигнала, R
II
– отражает
содержание сигнала
Агрегат
(Т, Х, У, Z, B, G) H(…), R(…)
«+» - Возможность построения однородной модели, описывающей сложную систему с разнородными математическими схемами t1,t2,t3,…. Z(t + ∆t)
(t0,t1] – интервал времени , в котором нас интересует координата
Z(t)= U(t0,t, Z(t0),g0,β) ; g0 –последний управляющий сигнал; U – оператор.
В момент времени t1 появился сигнал х1
Z(t1+0)=VI {t1, Z(t1), x1, g0, β}
Z(t1+0) – координата по аномалии переходного процесса,
Z(t1) – последнее состояние
Между интервалом t1 и t2 изменения того же характера: t2 – g1 →
Z(t2+0)=VII {t2, Z(t2), x2, g1, β}. И т.д.
Пример – одноканальная система массового обслуживания смешанного типа в виде агрегата.
В момент времени tj поступает заявка с характерным параметром αj
τj (ожид) = φ(αj, βj) – время возможного ожидания j – ой заявки - случайная величина.
φ – функция распределения (функция плотности)
Время обслуживания тоже случайная величина τj = ψ(αj, β)
β – конструктивный параметр системы (АЗС)
Запишем задачу в терминах агрегата: к – заявок, (2к+ r) координат надо, чтобы описать процесс

 .
r
k
+ r
.
r
k
+ r
очередь
обслуживаются
Z1(t) – координата, характеризующая время, оставшееся до конца обслуживания заявки, находящейся на обслуживании.
Zr(t) – число заявок в системе.
 Z
1+2к(t)=
αк-
заявка, находящаяся в очереди
Z
1+2к(t)=
αк-
заявка, находящаяся в очереди
Z 2+2к(t) – координата, характеризующая время возможного ожидания
α – характерный признак.
Для заявки , только что поступившей в систему , предусмотрены случайные координаты:
Z 1+2Z2(tj)(tj)
= αj
1+2Z2(tj)(tj)
= αj
Z 2+2Z2(tj)(tj) = φ(αj,β)
Z2(tj)>0 ,
Z1(tj+0)= Z1(tj)
Z2(tj+0)= Z(tj )+1
Z 1+2к(tj+0)= Z 1+2к(tj) для заявок в очереди
Z 2+2к(tj+0)= Z 2+2к(tj)
 Z
1+2z(tj)
(tj+0)=
αj
координаты
вновь прибывшей заявки
Z
1+2z(tj)
(tj+0)=
αj
координаты
вновь прибывшей заявки
 Z
2+2z
(tj)(tj+0)=
φ(αj,β)
Z
2+2z
(tj)(tj+0)=
φ(αj,β)
U(W* , W** ,U ) H(VI ,VII ,U)
Пусть W* служит для формирования координаты состояния, когда в момент времени t=t1* завершается обслуживание заявки.
W** - в момент времени t=t** заявка покидает систему необслуженной.
U – эволюционный параметр, т.е. просто проходит время и ничего не происходит.
W* - заявка в момент времени t1* уходит обслуженной.
Z1(t1*+0)=ψ (Z1,β)
Z2(t1*+0)= Z2(t1*)-1
Z 1+2к(t1*+0)= Z 1+2(к+1)(t2*)
Z 2+2к(t1*+0)= Z 2+2(к+1)(t2*)
1≤ l ≤ k, l – некоторый номер заявки, которая ждет некоторое время t и уходит необслуженной.
Z 1(t2**+0)=
Z1(t2**)
1(t2**+0)=
Z1(t2**)
Z2(t2**+0)= Z2(t2**)-1
Z 1+2к(t2**+0)= Z 1+2к(t2**) k<l
Z 2+2к(t2**+0)= Z 2+2к(t2**)
Z 1+2к(t2**+0)= Z 1+2(к+1)(t2**)
Z 2+2к(t2**+0)= Z 2+2(к+1)(t2**)
Момент времени t(tn, t n+1 ]
Z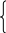
 1(t)=Z1(tn+0)-(t-tn)
1(t)=Z1(tn+0)-(t-tn)
Z2(t)=Z2(tn+0) tn t-tn Z1(tn+0)
Z 1+2к(t)= Z 1+2к(tn+0) для к=1,2,3,…К
Z 2+2к(t)= Z 2+2к(tn+0)-(t-tn)
Введен КЛА – кусочно – линейный агрегат
Оператор выхода R(R’, R”)
R’ формирует моменты выдачи выходных сигналов
Если Z(t) Z (g,β) (y) , то выдать у (выходной сигнал). y={y (1) , y (2) }
Z2(t*)=0→ Z (1)
Z 2+2k (t*)=0→ Z (2) Z (g,β) (y) =Z1Z2
y (1) - заявка ушла обслуженной (1) - Выдаем сигнал
y (2) – заявка ушла необслуженной (0)
t *
- Z1(t*)
= 0 y(t*)={1,j,
t*,}
*
- Z1(t*)
= 0 y(t*)={1,j,
t*,}
t** - Z 2+2k (t**) =0 y(t**)={0, j, t**,}
28 Методы и модели получения случайных величин с заданным законом распределения на эвм, методы генерации случайных чисел.
Имитация с. в. равномерно распределенных на [0,1]
Существует несколько методов:
а) табличный (с помощью рулетки получают набор случайных чисел и записывают в таблицу 374205…, в зависимости от количества знаков после запятой берут на интервале [0,1] числа: например, 0.37, 0.42, 0.05,… или 0.374, 0.205,…);
б) физическое генерирование (основано на использовании приборов распада радиоактивных элементов или шумов в электронных приборах);
в) метод псевдослучайных чисел (метод вычетов, Лемера).(ЭВМ позволяет легко получать так называемые псевдослучайные числа:
![]() ,
X0,
M,
a
– простые числа (задаются),
,
X0,
M,
a
– простые числа (задаются),
- с. в. равномерно распределенная на [0,1],
![]() ,
количество с. в. не может превосходить
M. )
,
количество с. в. не может превосходить
M. )
Программы ALEAT, RAND.
Имитация с. В. С заданной функцией плотности
Пусть требуется имитировать непрерывную с. в. с функцией плотности f(x), зная функцию распределения F(x).
Метод обратных функций.
- с. в. равномерно распределенная на [0,1],
![]()
Лемма: Если с. в. имеет функцию плотности f(x) , то
![]() -
есть с. в. равномерно распределенная на
[0,1].
-
есть с. в. равномерно распределенная на
[0,1].
Теорема: Пусть - функция распределения некоторой с. в., - с. в. равномерно распределенная на [0,1], тогда величина F-1() имеет функцию распределения F(x), при этом F-1(x) – функция обратная F(x).
Пример 1: f(x)=e-x, x>0,
![]()
![]() -
экспоненциально распределенная с. в.
Программа EXPON
обращается к ALEAT.
-
экспоненциально распределенная с. в.
Программа EXPON
обращается к ALEAT.
Пример
2:
![]() ,
,
![]() ,
,
![]() -
равномерно распределенная с. в. на [a,b].
-
равномерно распределенная с. в. на [a,b].
Недостаток: функцию распределения можно посчитать аналитически. Не подходит для нормального распределения.
Метод отбора или исключения применяется для имитации многомерных с. в.
Задача:
Имитировать с. в.
с функцией плотности f(x),
a
x
b,
f(x)
c
– функция ограничена.
![]() .
.
Теорема:
Пусть – 1,
2
независимые с. в., равномерно распределенные,
тогда
![]() ;
;
![]() .
С. в.
, определенная условием: =/,
если /<f(/),
имеет функцию плотности f(x).
.
С. в.
, определенная условием: =/,
если /<f(/),
имеет функцию плотности f(x).
Метод композиций (метод, основанный на использовании свойств законов распределения) Задача: Смоделировать с. в. X – нормально распределенную с мат. ожиданием x и дисперсией x2.
![]() -
нормированная н. р. с. в., y=0,
y2=1.
-
нормированная н. р. с. в., y=0,
y2=1.
Трактовка центральной предельной теоремы для генерации нормально распределенных с. в.. Пусть 1,2,…,n - с. в. равномерно распределенные с. в. с мат. ожиданием y=1/2 и дисперсией y2=1/12. Тогда в соответствии с центральной предельной теоремой:
![]() ,
- с. в. с нормальным законом распределения
с z=ny,
z2=ny2.
,
- с. в. с нормальным законом распределения
с z=ny,
z2=ny2.
При n=12 получаем Н.З.Р. на интервале .
 .
.
Программа NORMAL.
Имитация дискретных с. в.
Задача: Надо сымитировать с. в. , которая имеет закон распределения:
X: x1 x2 x3 … xn
p:
p1
p2
p3
… pn
![]() .
.
Для этого надо:
1) разбить интервал (0,1) n частичных интервалов;
0
1
p1
p1+p2
p1+p2+p3

 n
интервалов.
n
интервалов.
2). выбрать (например, из таблицы случайных чисел) случайное число i. Если i попало в частичный интервал, то имитируемая дискретная с. в. приняла возможное значение xi.
0 i < p1 x = x1
p1 i < p1+p2 x = x2
p1+p2 i < p1+p2+p3 x = x3
p1+p2+p3 i < 1 x = x4
30. Основные понятия теории графов
Графом называется набор точек (эти точки называются вершинами), некоторые из которых объявляются смежными (или соседними). Считается, что смежные вершины соединены между собой ребрами (или дугами). Два ребра, у которых есть общая вершина, также называются смежными (или соседними).
Граф называется ориентированным (или орграфом), если некоторые ребра имеют направление. Это означает, что в орграфе некоторая вершина может быть соединена с другой вершиной, а обратного соединения нет.
Мультиграфы – это такие графы, в которых могут быть петли или некоторые пары вершины могут быть соединены между собой несколькими ребрами.
Маршрут в графе – это последовательность соседних (смежных) вершин. Ясно, что можно определить маршрут и как последовательность смежных ребер (в этом случае ребра приобретают направление). Заметим, что в маршруте могут повторяться вершины, но не ребра. Маршрут называется циклом, если в нем первая вершина совпадает с последней.
Путь в графе – это маршрут без повторения вершин (а значит, и ребер).
Контур – это цикл без повторения вершин, за исключением первой вершины, совпадающей с последней.
Если имеется некоторый маршрут из вершины t в вершину s, заданный в виде последовательности ребер, которые в этом случае приобрели направление, и если в этот маршрут входит ребро, соединяющее вершины (i, j), то это ребро по отношению к вершине i называют иногда прямой дугой, а по отношению к вершине j – обратной дугой (или обратным ребром).
Граф называется связным, если любые две его вершины можно соединить маршрутом (или путем).
Ребро, при удалении которого граф перестает быть связным, иногда называют мостом.
Степень вершины – это число ребер, входящих в эту вершину. Вершина называется висячей, если ее степень равна единице.
Лемма 1. Если степень всех вершин в графе больше или равна двум, то граф обязательно содержит контур.
Доказательство. Действительно, выйдя из некоторой вершины и войдя в другую, всегда можно выйти из нее по другому ребру , так как степень вершины больше или равна двум. Выйти из вершины по новому ребру невозможно только в том случае, если эта вершина уже встречалась, а это означает, что можно выделить контур из
вершин этого графа.
31
Оптимизация сложных систем. Методы оптимизации. Многокритериальные модели оптимизации, их применение в задачах проектирования АСУ.
«Интеллект» систем определяется уровнем сложности решаемых такими системами задач. Сложность задач определяется уровнем неопределенности в исходных данных и в целях, на достижение которых должно быть направлено решение задачи.
Неопределенность цели вызывает необходимость в решении задач многокритериальной оптимизации и соответствующей разработке методов многокритериальной оптимизации.
Неопределенность в исходных данных вызывает необходимость в применении методов стохастической оптимизации, методов теории игр и теории статистических решений. Одним из основных применений ИАС является задача оптимального проектирования (САПР).
Основным видом задач, которые решаются с помощью САПР являются задачи выбора вариантов, эти задачи формулируются часто как задачи линейного булева программирования с точными ограничениями. Т. к. требуется выбрать наилучший вариант, то приходится рассматривать огромное исходное множество вариантов, это означает, что приходится решать задачи большой размерности и соответственно иметь алгоритмы оптимизации не теряющие эффективность и при большой размерности решаемых задач.
Л. п. р. – лицо принимающее решение.
Даны: x1,x2,…,xn – изменяемые параметры, f(x1,x2,…,xn) – функция цели (указывает на сколько мы близки к цели). Чем больше значение этой функции, тем предпочтительнее решение, т. е.
f(x1,x2,…,xn)
![]() - критерий эффективности. (1)
- критерий эффективности. (1)
gk(x1,x2,…,xn)0, k=1,2,…,m - ограничения неравенства (2)
hj(x1,x2,…,xn) = 0 - ограничения равенства (3)
эти функции характеризуют связи между параметрами.
Задача (1)-(3) называется задачей оптимизации или математического программирования.
Задача заключается в следующем: Найти такие значения искомых переменных, которые обеспечивают экстремум функции (1) при выполнении всех ограничений (2) и (3).
Переход от min к max:
(x1,x2,…,xn)![]() ,
,
-(x1,x2,…,xn) .
Допустимым решением задачи оптимизации называется набор значений искомых переменных, которые удовлетворяют всем ограничениям задачи.
Оптимальным решением называется допустимое решение, которое обеспечивает экстремум функции цели.
Запись условий задачи:
![]() {f(x)},
x
= (x1,x2,…,xn)T
{f(x)},
x
= (x1,x2,…,xn)T
D = {X: gk(x)0, hj(x) = 0, k=1,2,…,m; j = 1,2,…,l} – область допустимых решений.
Или
{f(x)| gk(x)0, hj(x) = 0, k=1,2,…,m; j = 1,2,…,l }.
Многокритериальная оптимизация.
![]()
0). Нормировка отдельных критериев (обязательно для того, чтобы можно было считать совместно с другими критериями). Оценка верхней и нижней допустимой границы критерия.
![]()
![]()
После этого строится что-то вроде весовой функции
![]()
Далее используется один из трех методов свертки критериев.
С![]() использованием весов критериев l,
данных экспертами:
использованием весов критериев l,
данных экспертами:
С![]() выделением главного критерия. Один
критерий максимизируется, остальные
превращаются в ограничения:
выделением главного критерия. Один
критерий максимизируется, остальные
превращаются в ограничения:
Игровой, или минимаксный подход. Оптимизация с тем расчетом, чтобы получить наибольшую выгоду в наихудших условиях:
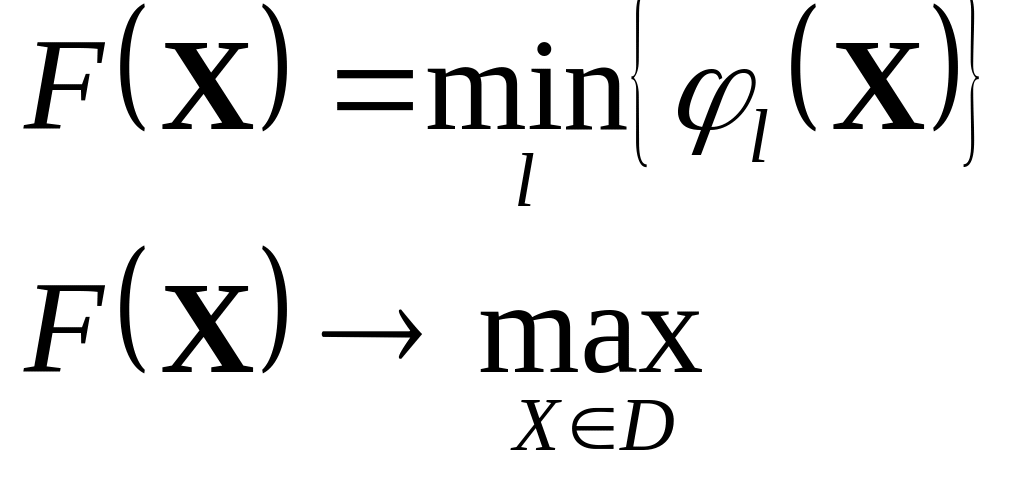
32Общая задача линейного программирования, ее каноническая форма, примеры применения. Симплекс-метод решения задач линейного программирования.
Задача:
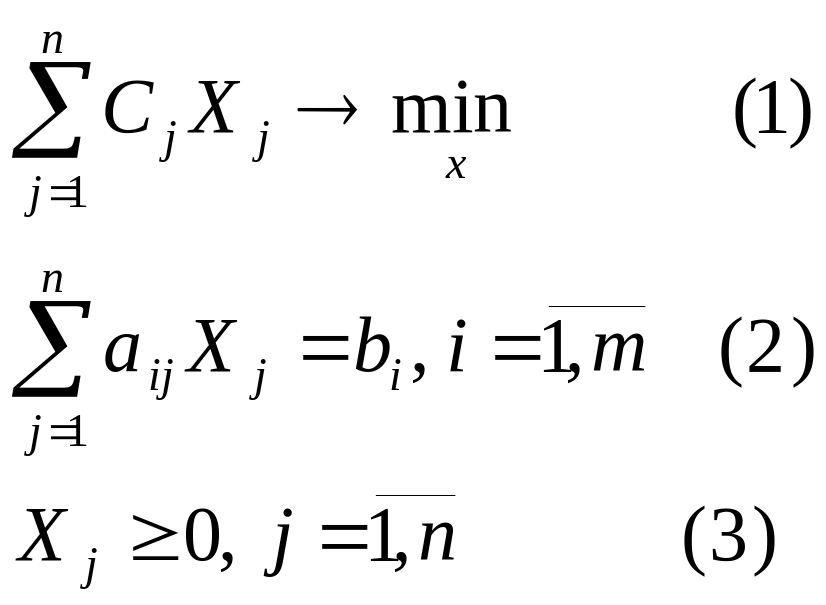
Например, Cj - прибыль от продажи продукции j–го вида, aij - затраты сырья i–го вида, bi - запасы сырья i–го вида.
1 шаг. К этому виду можно свести любую задачу линейного программирования.
В![]() задаче может быть:
задаче может быть:
приводим
к равенству, для этого вводим новые
переменные: Xn+i,
![]() .
.
П риводим
к основному виду:
риводим
к основному виду:
Предположение : Система уравнений (2) линейно независима.
Рассмотрим случаи: n<m , число уравнений больше числа неизвестных, система уравнений (2) не имеет решений. n=m решение существует и оно единственно, и если при этом выполняется условие (3), то оно допустимо, а т. к. оно единственно – оптимально. n>m система имеет бесконечное множество решений, из них следует выделить допустимые, а из допустимых – оптимальные.
Опр.1: Выпуклой комбинацией векторов X1,X2,…,Xn называется вектор
![]()
Опр.2: Точка X выпуклого множества D (xD) называется крайней (угловой), если X нельзя представить в виде выпуклой комбинации двух различных точек, принадлежащих D.
Опр.3: Основным решением системы (2) называется решение, которое получится, если k переменных (где k=n-m) положить равными 0 и найти все остальные m переменных, при условии, что определитель полученной системы из m уравнений не равен 0.
Опр.4: Те переменные, которые в основном решении полагаются равными 0 называются свободными, а все остальные – базисными.
Опр.5: Основным допустимым решением называется основное решение, удовлетворяющее условию (3).
Опр.6: Невырожденным основным допустимым решением называется основное допустимое решение, у которого имеется ровно m строго положительных элементов.
Теоремы лежащие в основе методов решения задач линейного программирования Область допустимых решений в задаче (1)-(3) является выпуклым множеством. Если существует допустимое решение, то существует и основное допустимое решение. Если целевая функция ограничена снизу, то по крайней мере одно оптимальное решение является основным допустимым решением. Целевая функция достигает своего минимума в одной из крайних точек области допустимых решений. Если она достигает своего минимума более чем в одной крайней точке, то она достигает минимума и в любой выпуклой комбинации этих точек.
Если система (2) линейно независима, а область допустимых решений формируется условиями (2) и (3), то точка, соответствующая основному допустимому решению является крайней точкой области допустимых решений. Симплекс-метод
![]()
Разбить все множество переменных на наборы свободных и базисных переменных:
{Xi}
{Xсв} {Xбаз} k=n-m (m- уравнений, n - переменных)
X1,…,Xk Xk+1,Xk+2,…,Xk+m
Проверить полученное разбиение на допустимость. Надо все базисные выразить через свободные:
![]() (4)
(4)
(система (2) и (4) абсолютно одно и тоже)
B0 (5) – условие допустимости разбиения.
нет да
1. разбиваем по другому 3. Проверить данное разбиение на оптимальность:
а) (4) подставляем в (1). Выражаем функцию цели только через свободные переменные
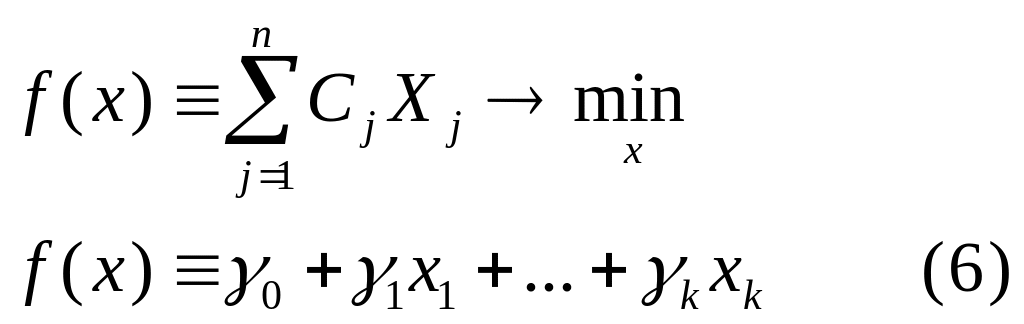 Если
выполняется, то мы нашли оптимальное
решение, если нет, то (4).
Если
выполняется, то мы нашли оптимальное
решение, если нет, то (4).
Определить
свободный x,
который нужно переместить в набор
базисных. Для этого ищется
![]() .
.
Определить базисный x, который нужно переместить в набор свободных. Для этого положим все свободные переменные кроме xt равными 0 и найдем xs, который быстрее всего уменьшается при увеличении xt. После этого меняем xs и xt местами и снова переходим к пункту 2.
Метод сходится, если функция f ограничена на D.
Доказано, что оптимальное решение будет, только если свободные переменные положить за 0.
33. Постановка и решение задач целочисленного линейного программирования. Алгоритмы «ветвей и границ» для решения задач целочисленного программирования.
Постановка задачи целочисленного линейного программирования.
![]() (1)
(1) ![]() (2)
(2)
![]() (3) xj
– целые,
(3) xj
– целые,
![]() (4)
(4)
Решение задачи (Алгоритм Гомори).
Решается задача линейного программирования (1)-(3), например, Симплекс-методом. Если ее оптимальное решение удовлетворяет условиям (4), то это – еще и оптимальное решение задачи (1)-(4). Если нет, см. п. 2.
Вводится дополнительное линейное ограничение, которое обладает двумя свойствами: а) полученное не целочисленное оптимальное решение задачи этому ограничению не удовлетворяет; б) любое допустимое целочисленное решение задачи (1)-(4) этому новому ограничению удовлетворяет.
Снова решается задача (1)-(3) с новым линейным ограничением Симплекс-методом. Проверяется выполнение условие (4), если да, то задача решена; если нет, то еще одно ограничение и т.д.
Алгоритм «ветвей и границ».
Может применяться для решения любой дискретной задачи. Позволяет получить точное решение задачи (если оно есть). Недостаток этого метода в том, что он может потребовать значительного перебора допустимых решений.
![]() ,
,
Вводится
дополнительное условие:
![]() .
.
О бласть
допустимых решений выглядит так:
бласть
допустимых решений выглядит так:
Решение. 0 итерация. Находится X*: f(X*)max. Если все xi из X* целые, то найдено оптимальное решение.
Если нет, то задаем x1=1fл и x1=0fп. Ту ветвь, на которой значение f больше, ветвим дальше, другую запоминаем.
Если на каком-то этапе получено допустимое решение, которое оказывается лучше (по ф. цели), чем все запомненные недопустимые, оно – оптимальное.
34. Задачи выпуклого программирования. Метод неопределенных множителей Лагранжа.
Задачи выпуклого программирования.
Выпуклым множеством D называется такое множество, для которого линейная комбинация любых двух принадлежащих множеству элементов тоже будет принадлежать этому множеству:
Если X1 D, X2 D, X3 = X1 + (1–)X2, 01, то X3 D.
Проще говоря, если все точки на прямой между двумя точками множества тоже принадлежат множеству, то это множество выпуклое.
Выпуклая функция f – это функция, заданная на выпуклом множестве D, такая, что X3 = X1 + (1–)X2 (см. выше) f(X3) f(X1) + (1–) f(X2). Проще говоря, это функция, прогибающаяся вниз на множестве D. Строго выпуклая функция – та, для которой неравенство превращается в строгое.
Вогнутая функция f – это функция, заданная на выпуклом множестве D, для которой (в противоположность выпуклой) f(X3) f(X1) + (1–) f(X2), т.е. она выгибается вверх.
З![]() адача
безусловной оптимизации.
адача
безусловной оптимизации.
Необходимое
условие
существования экстремума если
![]() - дифференцируемая функция. Пусть X*
– оптимальное решение задачи (1), т.е.
f(X*)
f(X),
тогда f’(X*)=0
(все частные производные функции по xi
равны 0). Это условие отсеивает неоптимальные
решения, но в случае многоэкстремальных
(нестрого выпуклых) функций может
существовать несколько точек X*,
таких, что f’(X*)=0
(так называемых локальных экстремумов).
Это одна из проблем оптимизации.
- дифференцируемая функция. Пусть X*
– оптимальное решение задачи (1), т.е.
f(X*)
f(X),
тогда f’(X*)=0
(все частные производные функции по xi
равны 0). Это условие отсеивает неоптимальные
решения, но в случае многоэкстремальных
(нестрого выпуклых) функций может
существовать несколько точек X*,
таких, что f’(X*)=0
(так называемых локальных экстремумов).
Это одна из проблем оптимизации.
Достаточное условие. Если f – выпуклая функция и f’(X*)=0, то
f(X)– f(X*)f’(X*)(X–X*) => f(X) f(X*),
т.е. X* – оптимальное решение задачи (1).
Методы поиска безусловного экстремума в основном представляют собой итерационные численные методы. В их основе лежит та же идея, что в точке экстремума градиент функции равен 0. Решение на каждом шаге равно:
![]()
Константа c определяется для каждого метода по-своему. Процесс продолжается, пока не будет достигнута заданная точность. В зависимости от того, используется ли в методе аналитическое выражение для частных производных функции f или некая его аппроксимация, методы делятся на градиентные (напр., Давидона-Флетчера-Пауэлла) и неградиентные (напр., деформируемого многогранника).
З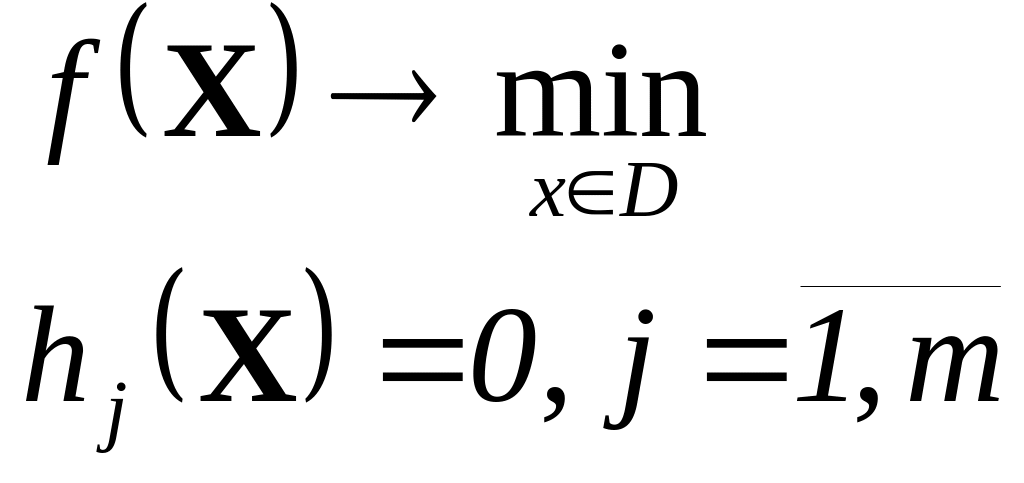 адача
условной оптимизации
формулируется следующим образом.
адача
условной оптимизации
формулируется следующим образом.
По теореме Вейерштрасса, функция достигает на ограниченном замкнутом множестве D своих наибольшего и наименьшего значений (достаточное условие).
Метод неопределенных множителей Лагранжа.
Метод относится к методам условной оптимизации и позволяет решать задачи нелинейного программирования с ограничениями-равенствами.
Основная идея метода в том, что задача с ограничениями-равенствами специальным приемом заменяется эквивалентной задачей без ограничений, которая решается одним из известных методов безусловной оптимизации.
Задача.
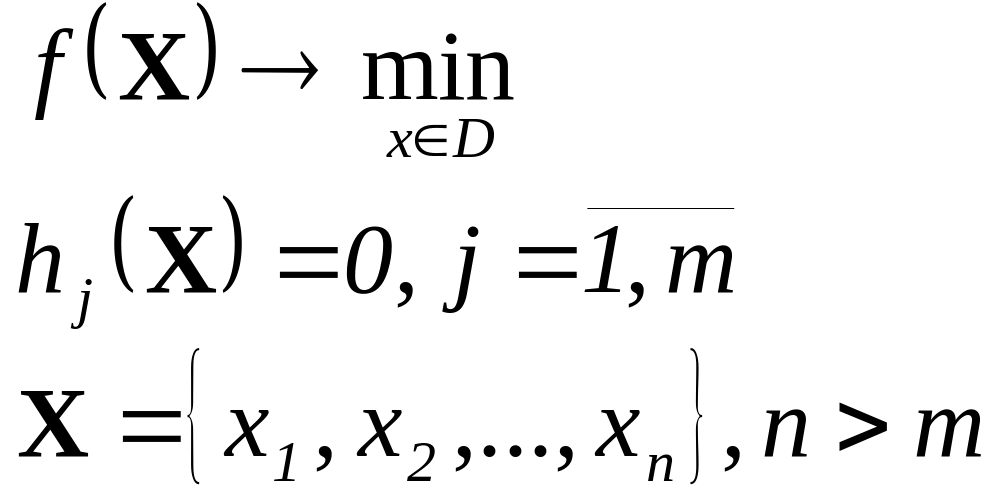
Дана f – функция n переменных (n-мерного вектора X). Заданы hj – ограничения области допустимых решений D (ОДР) в n-мерном пространстве. Требуется минимизировать f при соблюдении ограничений hj. (Можно решать задачу на min, если в целевой функции поставить противоположный знак).
Для решения задачи применяется следующий метод.
1.
Строится функция Лагранжа
![]() :
:
![]()
где
![]() – неопределенные множители Лагранжа
(по числу ограничений).
– неопределенные множители Лагранжа
(по числу ограничений).
Функция Лагранжа будет совпадать с минимизируемой функцией f везде в ОДР, поскольку в ОДР ограничения hj обратятся в 0. За пределами ОДР функция Лагранжа не будет совпадать с f.
2. Пусть f и hj – дифференцируемые функции, тогда мы можем найти все частные производные функции Лагранжа по xi и i:
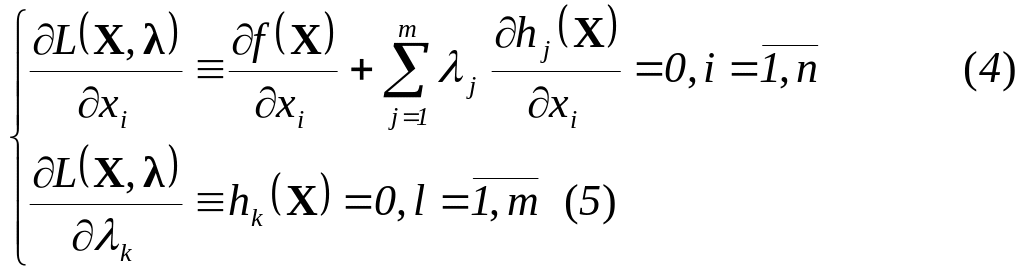
Приравнивая все частные производные к нулю, получаем систему уравнений, решение которой относительно li и xi даст нам оптимальное решение исходной задачи X*: f(X*)min.
Таким образом, мы свели задачу к известной – задаче безусловной оптимизации.
35. Транспортная задача и метод потенциалов
Общая
постановка транспортной задачи состоит
в определении оптимального плана
перевозок некоторого однородного груза
из
![]() пунктов отправления (производства)
пунктов отправления (производства)
![]() в
в
![]() пунктов назначения (потребления)
пунктов назначения (потребления)
![]() .
При этом в качестве критерия оптимальности
обычно берется либо минимальная стоимость
перевозок всего груза, либо минимальное
время его доставки. Рассмотрим транспортную
задачу, в качестве критерия оптимальности
которой взята минимальная стоимость
перевозок всего груза. Обозначим через
.
При этом в качестве критерия оптимальности
обычно берется либо минимальная стоимость
перевозок всего груза, либо минимальное
время его доставки. Рассмотрим транспортную
задачу, в качестве критерия оптимальности
которой взята минимальная стоимость
перевозок всего груза. Обозначим через
![]() тарифы перевозки единицы груза из
тарифы перевозки единицы груза из
![]() -го
пункта отправления в
-го
пункта отправления в
![]() -й
пункт назначения, через
-й
пункт назначения, через
![]() - запасы груза в
-м
пункте отправления, через
- запасы груза в
-м
пункте отправления, через
![]() - потребности в грузе в
-м
пункте назначения, а через
- потребности в грузе в
-м
пункте назначения, а через
![]() - количество единиц груза, перевозимого
из
-го пункта отправления в
-й
пункт назначения. Обычно исходные данные
транспортной задачи записывают в виде
таблицы.
- количество единиц груза, перевозимого
из
-го пункта отправления в
-й
пункт назначения. Обычно исходные данные
транспортной задачи записывают в виде
таблицы.
Пункты производства |
Пункты потребления |
Объемы производства
|
|||
|
|
|
|
||
|
|
|
|
|
|
Объемы потребителя
|
|
|
|
|
|
Составим математическую модель задачи.
![]() (1)
(1)
при ограничениях
(2)
(3)
(4).
План
![]() ,
при котором функция (1) принимает своё
минимальное значение, называется
оптимальным
планом
транспортной задачи.
,
при котором функция (1) принимает своё
минимальное значение, называется
оптимальным
планом
транспортной задачи.
Условие разрешимости транспортной задачи
Теорема: Для разрешимости транспортной задачи необходимо и достаточно, чтобы запасы груза в пунктах отправления были равны потребности в грузе в пунктах назначения, т. е чтобы выполнялось равенство
![]() .
(5)
.
(5)
Модель такой транспортной задачи называется закрытой, или замкнутой, или сбалансированной, в противном случае модель называется открытой.
В
случае
![]() вводится
фиктивный
вводится
фиктивный
![]() -й
пункт назначения с потребностью
-й
пункт назначения с потребностью
![]() и соответствующие
тарифы считаются равными нулю:
и соответствующие
тарифы считаются равными нулю:![]() ;
аналогично, при
;
аналогично, при
![]() вводится
фиктивный
вводится
фиктивный
![]() -й
пункт отправления с запасом груза
-й
пункт отправления с запасом груза
![]() и соответствующие
тарифы считаются равными нулю:
и соответствующие
тарифы считаются равными нулю:![]() .
Этим задача сводится к обычной транспортной
задаче. В дальнейшем будем рассматривать
закрытую модель транспортной задачи.
.
Этим задача сводится к обычной транспортной
задаче. В дальнейшем будем рассматривать
закрытую модель транспортной задачи.
Число
переменных
в транспортной задаче с
пунктами отправления и
пунктами назначения равно
![]() ,
а число уравнений в системе (2)-(4) -
,
а число уравнений в системе (2)-(4) -
![]() .
Так как мы предполагаем выполнение
условия (5), то число линейно независимых
уравнений равно
.
Так как мы предполагаем выполнение
условия (5), то число линейно независимых
уравнений равно
![]() .
Следовательно, опорный план может иметь
не более
отличных от нуля неизвестных. Если в
опорном плане число отличных от нуля
компонент равно в точности
,
то план называется невырожденным,
а если меньше - то вырожденным.
.
Следовательно, опорный план может иметь
не более
отличных от нуля неизвестных. Если в
опорном плане число отличных от нуля
компонент равно в точности
,
то план называется невырожденным,
а если меньше - то вырожденным.
Выбор критерия оптимальности
При решении транспортной задачи выбор критерия оптимальности имеет важное значение. Как известно, оценка экономической эффективности примерного плана может определятся по тому или иному критерию, положенного в основу расчета плана. Этот критерий является экономическим показателем, характеризующим качество плана. До настоящего времени нет общепринятого единого критерия всесторонне учитывающего экономические факторы. При решении транспортной задачи, в качестве критерия оптимальности в различных случаях используют следующие показатели:
1) Объем работы транспорта (критерий - расстояние в т/км). Минимум пробега удобен для оценки планов перевозок, поскольку расстояние перевозки определяется легко и точно для любого направления. Поэтому критерию нельзя решать транспортные задачи с участием многих видов транспорта. С успехом применяется при решении транспортных задач для автомобильного транспорта. При разработке оптимальных схем перевозки однородных грузов автомобилями.
2) Тарифная плата за перевозку груза (критерий - тарифы провозных плат). Позволяет получить схему перевозок, наилучшую с точки зрения хозрасчетных показателей предприятия. Все надбавки, а также существующие льготные тарифы затрудняют его использование.
3) Эксплутационные расходы на транспортировку грузов (критерий - себестоимость эксплутационных расходов). Более верно отражает экономичность перевозок различными видами транспорта. Позволяет делать обоснованные выводы о целесообразности переключения с одного вида транспорта на другой.
4) Сроки доставки грузов (критерий - затраты времени).
![]()
5) Приведенные затраты (с учетом эксплуатационных расходов, зависящих от размеров движения и капиталовложения в подвижной состав).
6) Приведенные затраты (с учетом полных эксплуатационных расходов капиталовложений на строительство объектов в подвижной состав).
![]() ,
,
где
![]() - эксплутационные издержки,
- эксплутационные издержки,
![]() -расчетный
коэффициент эффективности капиталовложения,
-расчетный
коэффициент эффективности капиталовложения,
![]() -
капитальные вложения, приходящие на 1
т груза на протяжении участка,
-
капитальные вложения, приходящие на 1
т груза на протяжении участка,
Т - время следования,
Ц - цена одной тоны груза.
Позволяет более полно производить оценку рационализации разных вариантов планов перевозок, с достаточно полной выраженностью количественно-одновременное влияние нескольких экономических факторов.
Построение первоначального опорного плана
Для определения опорного плана существует несколько методов: метод северо-западного угла (диагональный метод), метод наименьшей стоимости (минимального элемента), метод двойного предпочтения и метод аппроксимации Фогеля.
Кратко рассмотрим каждый из них.
1.Метод
северо-западного угла.
При нахождении опорного плана на каждом
шаге рассматривают первый из оставшихся
пунктов отправления и первый из
оставшихся пунктов назначения. Заполнение
клеток таблицы условий начинается с
левой верхней клетки для неизвестного
![]() («северо-западный угол») и заканчивается
клеткой для неизвестного
(«северо-западный угол») и заканчивается
клеткой для неизвестного![]() ,
т.е. как бы по диагонали таблицы.
,
т.е. как бы по диагонали таблицы.
2.
Метод наименьшей стоимости. Суть
метода заключается в том, что из всей
таблицы стоимостей выбирают наименьшую
и в клетку
![]() ,
которая ей соответствует, помещают
меньшее из чисел
,
которая ей соответствует, помещают
меньшее из чисел
![]() и
,
затем из рассмотрения исключают либо
строку, соответствующую поставщику,
запасы которого полностью израсходованы,
либо столбец, соответствующий потребителю,
потребности которого полностью
удовлетворены, либо и строку и столбец,
если израсходованы запасы поставщика
и удовлетворены потребности потребителя.
Из оставшейся части таблицы стоимостей
снова выбирают наименьшую стоимость,
и процесс размещения запасов продолжают,
пока все запасы не будут распределены,
а потребности удовлетворены.
и
,
затем из рассмотрения исключают либо
строку, соответствующую поставщику,
запасы которого полностью израсходованы,
либо столбец, соответствующий потребителю,
потребности которого полностью
удовлетворены, либо и строку и столбец,
если израсходованы запасы поставщика
и удовлетворены потребности потребителя.
Из оставшейся части таблицы стоимостей
снова выбирают наименьшую стоимость,
и процесс размещения запасов продолжают,
пока все запасы не будут распределены,
а потребности удовлетворены.
3. Метод двойного предпочтения. Суть метода заключается в следующем. В каждом столбце отмечают знаком «√» клетку с наименьшей стоимостью. Затем то же проделывают в каждой строке. В результате некоторые клетки имеют отметку «√√». В них находится минимальная стоимость, как по столбцу, так и по строке. В эти клетки помещают максимально возможные объемы перевозок, каждый раз исключая из рассмотрения соответствующие столбцы или строки. Затем распределяют перевозки по клеткам, отмеченным знаком «√». В оставшейся части таблицы перевозки распределяют по наименьшей стоимости.
4. Метод аппроксимации Фогеля. При определении опорного плана данным методом на каждой итерации по всем столбцам и всем строкам находят разность между двумя записанными в них минимальными тарифами. Эти разности заносят в специально отведенных для этого строке и столбце в таблице условий задачи. Среди указанных разностей выбирают максимальную. В строке (или столбце), который данная разность соответствует, определяют минимальный тариф. Клетку, в которой он записан, заполняют на данной итерации.
Определение критерия оптимальности
С помощью рассмотренных методов построения первоначального опорного плана можно получить вырожденный или невырожденный опорный план. Построенный план транспортной задачи как задачи линейного программирования можно было бы довести до оптимального с помощью симплексного метода. Однако из-за громоздкости симплексных таблиц, содержащих тп неизвестных, и большого объема вычислительных работ для получения оптимального плана используют более простые методы. Наиболее часто применяются метод потенциалов (модифицированный распределительный метод) и метод дифференциальных рент.
Метод потенциалов. Этот первый точный метод решения транспортной задачи предложен в 1949 году Кантаровичем А. В. И Гавуриным М. К. по существу он является детализацией метода последовательного улучшения плана применительно к транспортной задаче. Однако в начале он был изложен вне связи с общими методами линейного программирования. Несколько позднее аналогичный алгоритм был разработан Данциом, который исходил из общей идеи линейного программирования. В американской литературе принято называть модифицированным распределительным методом. Метод потенциалов позволяет определить отправляясь от некоторого опорного плана перевозок построить решение транспортной задачи за конечное число шагов (итераций).
Общий принцип определения оптимального плана транспортной задачи этим методом аналогичен принципу решения задачи линейного программирования симплексным методом, а именно: сначала находят опорный план транспортной задачи, а затем его последовательно улучшают до получения оптимального плана.
Составим двойственную задачу
1.
![]() ,
,
![]() - любые
- любые
2.
![]()
3.
![]()
Пусть есть план
Теорема (критерий оптимальности): Для того чтобы допустимый план перевозок в транспортной задаче был оптимальным, необходимо и достаточно, чтобы существовали такие числа , , что
![]() если
если
![]() ,
(6)
,
(6)
![]() если
если
![]() .
(7)
.
(7)
числа
![]() и
и
![]()
![]() называются потенциалами пунктов
отправления
называются потенциалами пунктов
отправления
![]() и назначения
и назначения
![]() соответственно.
соответственно.
Сформулированная
теорема позволяет построить алгоритм
нахождения решения транспортной задачи.
Он состоит в следующем. Пусть одним из
рассмотренных выше методов найден
опорный план. Для этого плана, в котором
базисных клеток, можно определить
потенциалы
и
так, чтобы
выполнялось условие (6). Поскольку система
(2)-(4) содержит
уравнений и
неизвестных, то одну из них можно задать
произвольно (например, приравнять к
нулю). После этого из
уравнений (6) определяются остальные
потенциалы и для каждой из свободных
клеток вычисляются величины
![]() .
Если оказалось, что
.
Если оказалось, что
![]() ,
то план оптимален. Если же хотя бы в
одной свободной клетке
,
то план оптимален. Если же хотя бы в
одной свободной клетке
![]() ,
то план не является оптимальным и
может быть улучшен путем переноса по
циклу, соответствующему данной
свободной клетке.
,
то план не является оптимальным и
может быть улучшен путем переноса по
циклу, соответствующему данной
свободной клетке.
Циклом в таблице условий транспортной задачи, называется ломаная линия, вершины которой расположены в занятых клетках таблицы, а звенья - вдоль строк и столбцов, причем в каждой вершине цикла встречается ровно два звена, одно из которых находится в строке, а другое - в столбце. Если ломанная линия, образующая цикл, пересекается, то точки самопересечения не являются вершинами.
Процесс улучшения плана продолжается до тех пор, пока не будут выполнены условия (7).
Пример решения транспортной задачи.
Задача. На четыре базы A1, A2, A3, A4 поступил однородный груз в следующем количестве: а1 тонн - на базу А1, а2 тонн - на базу А2, а3 тонн - на базу А3, а4 тонн - на базу А4. Полученный груз требуется перевезти в пять пунктов: b1 тонн - на базу B1, b2 тонн - на базу B2, b3 тонн - на базу B3, b4 тонн - на базу B4, b5 тонн - на базу B5. Расстояния между пунктами назначений указаны в матрице расстояний.
пункты отправления |
пункты назначения |
запасы |
||||
B1 |
B2 |
B3 |
B4 |
B5 |
||
A1 |
30 |
24 |
11 |
12 |
25 |
21 |
A2 |
26 |
4 |
29 |
20 |
24 |
19 |
A3 |
27 |
14 |
14 |
10 |
18 |
15 |
A4 |
6 |
14 |
28 |
8 |
2 |
25 |
потребности |
15 |
15 |
15 |
15 |
20 |
|
Стоимость перевозок пропорциональна количеству груза и расстоянию, на которое этот груз перевозится. Спланировать перевозки так, чтобы их общая стоимость была минимальной.
Решение. Проверим сбалансированность транспортной задачи, для этого необходимо чтобы
![]()
![]() ,
,
![]() .
.
1. Решим задачу диагональным методом или методом северо-западного угла.
Процесс получения плана можно оформить в виде таблицы:
пункты отправления |
B1 |
B2 |
B3 |
B4 |
B5 |
запасы |
|
|
|
|
|
|
|
A1 |
15 |
6 |
― |
― |
― |
21 |
6 |
0 |
0 |
0 |
0 |
0 |
0 |
A2 |
― |
9 |
10 |
― |
― |
19 |
19 |
19 |
10 |
0 |
0 |
0 |
0 |
A3 |
― |
― |
5 |
10 |
― |
15 |
15 |
15 |
15 |
15 |
10 |
10 |
10 |
A4 |
― |
― |
― |
5 |
20 |
25 |
25 |
25 |
25 |
25 |
25 |
25 |
20 |
потребности |
15 |
15 |
15 |
15 |
20 |
|
|||||||
|
0 |
15 |
15 |
15 |
20 |
|
|||||||
|
0 |
9 |
15 |
15 |
20 |
|
|||||||
|
0 |
0 |
15 |
15 |
20 |
|
|||||||
|
0 |
0 |
5 |
15 |
20 |
|
|||||||
|
0 |
0 |
0 |
15 |
20 |
|
|||||||
|
0 |
0 |
0 |
5 |
20 |
|
|||||||
|
0 |
0 |
0 |
0 |
20 |
|
|||||||
Получен следующий план:
|
15 |
6 |
0 |
0 |
0 |
X0= |
0 |
9 |
10 |
0 |
0 |
0 |
0 |
5 |
10 |
0 |
|
|
0 |
0 |
0 |
5 |
20 |
Полученный план невырожденный. F(X0)=15·30+6·24+9·4+10·29+5·14+10·10+5·8+20·2=1170.
2. Метод наименьшей стоимости.
пункты отправления |
B1 |
B2 |
B3 |
B4 |
B5 |
запасы |
|
|
|
|
|
|
|||||
A1 |
6 |
30 |
× |
24 |
15 |
11 |
× |
12 |
× |
25 |
21 |
21 |
21 |
21 |
21 |
6 |
6 |
|
|
|
|
|
|||||||||||||
A2 |
4 |
26 |
15 |
4 |
× |
29 |
× |
20 |
× |
24 |
19 |
19 |
4 |
4 |
4 |
4 |
0 |
|
|
|
|
|
|||||||||||||
A3 |
× |
27 |
× |
14 |
× |
14 |
15 |
10 |
× |
18 |
15 |
15 |
15 |
15 |
0 |
0 |
0 |
|
|
|
|
|
|||||||||||||
A4 |
5 |
6 |
× |
14 |
× |
28 |
× |
8 |
20 |
2 |
25 |
5 |
5 |
0 |
0 |
0 |
0 |
|
|
|
|
|
|||||||||||||
потребности |
15 |
15 |
15 |
15 |
20 |
|
|||||||||||
|
15 |
15 |
15 |
15 |
0 |
||||||||||||
|
15 |
0 |
15 |
15 |
0 |
||||||||||||
|
10 |
0 |
15 |
15 |
0 |
||||||||||||
|
10 |
0 |
15 |
0 |
0 |
||||||||||||
|
10 |
0 |
0 |
0 |
0 |
||||||||||||
|
6 |
0 |
0 |
0 |
0 |
||||||||||||
Получили вырожденный опорный план
|
6 |
0 |
15 |
0 |
0 |
X0= |
4 |
15 |
0 |
0 |
0 |
0 |
0 |
0 |
15 |
0 |
|
|
5 |
0 |
0 |
0 |
20 |
F(X0)=6·30+15·11+4·26+15·4+15·10+5·6+20·2=729.
3. Метод двойного предпочтения.
пункты отправления |
B1 |
B2 |
B3 |
B4 |
B5 |
запасы |
|
|
|
|
|
|
|||||
A1 |
6 |
30 |
× |
24 |
15 |
11 |
× |
12 |
× |
25 |
21 |
21 |
21 |
21 |
21 |
6 |
6 |
|
|
|
|
|
|||||||||||||
A2 |
4 |
26 |
15 |
4 |
× |
29 |
× |
20 |
× |
24 |
19 |
19 |
4 |
4 |
4 |
4 |
0 |
|
|
|
|
|
|||||||||||||
A3 |
× |
27 |
× |
14 |
× |
14 |
15 |
10 |
× |
18 |
15 |
15 |
15 |
15 |
0 |
0 |
0 |
|
|
|
|
|
|||||||||||||
A4 |
5 |
6 |
× |
14 |
× |
28 |
× |
8 |
20 |
2 |
25 |
5 |
5 |
0 |
0 |
0 |
0 |
|
|
|
|
|
|||||||||||||
потребности |
15 |
15 |
15 |
15 |
20 |
|
|||||||||||
|
15 |
15 |
15 |
15 |
0 |
||||||||||||
|
15 |
0 |
15 |
15 |
0 |
||||||||||||
|
10 |
0 |
15 |
15 |
0 |
||||||||||||
|
10 |
0 |
15 |
0 |
0 |
||||||||||||
|
10 |
0 |
0 |
0 |
0 |
||||||||||||
|
6 |
0 |
0 |
0 |
0 |
||||||||||||
Получили вырожденный опорный план
|
6 |
0 |
15 |
0 |
0 |
X0= |
4 |
15 |
0 |
0 |
0 |
0 |
0 |
0 |
15 |
0 |
|
|
5 |
0 |
0 |
0 |
20 |
F(X0)=6·30+15·11+4·26+15·4+15·10+5·6+20·2=729.
4. Метод аппроксимации Фогеля.
пункты отправления |
B1 |
B2 |
B3 |
B4 |
B5 |
запасы |
столбец-разность |
|
||||||||||
A1 |
× |
30 |
× |
24 |
15 |
11 |
6 |
12 |
× |
25 |
21 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
|
|
|
|
||||||||||||||
A2 |
× |
26 |
15 |
4 |
× |
29 |
4 |
20 |
× |
24 |
19 |
16 |
16 |
4 |
4 |
9 |
к |
к |
|
|
|
|
|
||||||||||||||
A3 |
× |
27 |
× |
14 |
× |
14 |
5 |
10 |
10 |
18 |
15 |
4 |
4 |
4 |
4 |
4 |
4 |
к |
|
|
|
|
|
||||||||||||||
A4 |
15 |
6 |
× |
14 |
× |
28 |
× |
8 |
10 |
2 |
25 |
4 |
6 |
6 |
к |
к |
к |
к |
|
|
|
|
|
||||||||||||||
потребности |
15 |
15 |
15 |
15 |
20 |
|
|
|||||||||||
строка-разность |
20 |
10 |
3 |
2 |
16 |
|
||||||||||||
к |
10 |
3 |
2 |
16 |
|
|||||||||||||
к |
к |
3 |
2 |
16 |
|
|||||||||||||
к |
к |
3 |
2 |
6 |
|
|||||||||||||
к |
к |
3 |
2 |
к |
|
|||||||||||||
к |
к |
3 |
2 |
к |
|
|||||||||||||
к |
к |
к |
к |
к |
|
|
|
|
|
|
|
|
||||||
Получили невырожденный опорный план
|
0 |
0 |
15 |
6 |
0 |
X0= |
0 |
15 |
0 |
4 |
0 |
0 |
0 |
0 |
5 |
10 |
|
|
15 |
0 |
0 |
0 |
10 |
F(X0)=15·6+15·4+15·11+5·10+4·20+6·12+10·18+10·2=717.
5. Для проверки оптимальности плана используем метод потенциалов. В качестве примера возьмем опорный план, полученный методом двойного предпочтения.
Так как взятый нами план является вырожденным, то вводим ε - некоторое число близкое к 0.
Составим систему уравнений:
u1 |
+ |
v1 |
= |
30 |
|
|
Пусть |
u1 |
= |
0 |
|
v1 |
= |
30 |
|
|
u1 |
+ |
v2 |
= |
8 |
< |
c12 |
= |
24 |
u1 |
+ |
v3 |
= |
11 |
|
|
|
u2 |
= |
-4 |
|
v2 |
= |
8 |
|
|
u1 |
+ |
v4 |
= |
24 |
> |
c14 |
= |
12 |
u2 |
+ |
v1 |
= |
26 |
|
|
|
u3 |
= |
-14 |
|
v3 |
= |
11 |
|
|
u1 |
+ |
v5 |
= |
26 |
> |
c15 |
= |
25 |
u2 |
+ |
v2 |
= |
4 |
|
|
|
u4 |
= |
-24 |
|
v4 |
= |
24 |
|
|
u2 |
+ |
v3 |
= |
7 |
< |
c23 |
= |
29 |
u2 |
+ |
v4 |
= |
20 |
|
|
|
|
|
|
|
v5 |
= |
26 |
|
|
u2 |
+ |
v5 |
= |
22 |
< |
c25 |
= |
24 |
u3 |
+ |
v4 |
= |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
u3 |
+ |
v1 |
= |
16 |
< |
c31 |
= |
27 |
u4 |
+ |
v1 |
= |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
u3 |
+ |
v2 |
= |
-6 |
< |
c32 |
= |
14 |
u4 |
+ |
v5 |
= |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
u3 |
+ |
v3 |
= |
3 |
< |
c33 |
= |
14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u3 |
+ |
v5 |
= |
12 |
< |
c35 |
= |
18 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u4 |
+ |
v2 |
= |
-16 |
< |
c42 |
= |
14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u4 |
+ |
v3 |
= |
-13 |
< |
c43 |
= |
28 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u4 |
+ |
v4 |
= |
0 |
< |
c44 |
= |
8 |
Так как существуют суммы больше cij, то план не оптимален. Введем в базис переменную (1,4) (так как разность здесь максимальна).
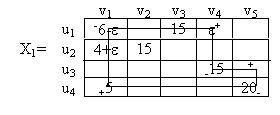
u1 |
+ |
v1 |
= |
30 |
|
|
Пусть |
u1 |
= |
0 |
|
v1 |
= |
30 |
|
|
u1 |
+ |
v5 |
= |
26 |
> |
c15 |
= |
25 |
u1 |
+ |
v3 |
= |
11 |
|
|
|
u2 |
= |
-4 |
|
v2 |
= |
8 |
|
|
u2 |
+ |
v4 |
= |
8 |
< |
c24 |
= |
20 |
u1 |
+ |
v4 |
= |
12 |
|
|
|
u3 |
= |
-2 |
|
v3 |
= |
11 |
|
|
u3 |
+ |
v1 |
= |
28 |
> |
c31 |
= |
27 |
u2 |
+ |
v1 |
= |
26 |
|
|
|
u4 |
= |
-24 |
|
v4 |
= |
12 |
|
|
u3 |
+ |
v2 |
= |
6 |
< |
c32 |
= |
14 |
u2 |
+ |
v2 |
= |
4 |
|
|
|
|
|
|
|
v5 |
= |
26 |
|
|
u3 |
+ |
v3 |
= |
9 |
< |
c33 |
= |
14 |
u3 |
+ |
v4 |
= |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
u3 |
+ |
v5 |
= |
24 |
> |
c35 |
= |
18 |
u4 |
+ |
v1 |
= |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
u4 |
+ |
v4 |
= |
-12 |
< |
c44 |
= |
8 |
u4 |
+ |
v5 |
= |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Так как существуют суммы больше cij, то план не оптимален. Введем в базис переменную (3,5) (так как разность здесь максимальна).
F(X1)=6·30-30ε+15·11+12ε+4·26-26ε+15·4+15·10+5·6+20·2=729-46ε.

u1 |
+ |
v3 |
= |
11 |
|
|
Пусть |
u1 |
= |
0 |
|
v1 |
= |
24 |
|
|
u1 |
+ |
v1 |
= |
24 |
< |
c11 |
= |
30 |
u1 |
+ |
v4 |
= |
12 |
|
|
|
u2 |
= |
2 |
|
v2 |
= |
2 |
|
|
u1 |
+ |
v2 |
= |
12 |
< |
c12 |
= |
24 |
u2 |
+ |
v1 |
= |
26 |
|
|
|
u3 |
= |
-2 |
|
v3 |
= |
11 |
|
|
u1 |
+ |
v5 |
= |
20 |
< |
c15 |
= |
25 |
u2 |
+ |
v2 |
= |
4 |
|
|
|
u4 |
= |
-18 |
|
v4 |
= |
12 |
|
|
u2 |
+ |
v3 |
= |
13 |
< |
c23 |
= |
29 |
u3 |
+ |
v4 |
= |
10 |
|
|
|
|
|
|
|
v5 |
= |
20 |
|
|
u2 |
+ |
v4 |
= |
14 |
< |
c24 |
= |
20 |
u3 |
+ |
v5 |
= |
18 |
|
|
|
|
|
|
|
|
|
|
|
|
u2 |
+ |
v5 |
= |
22 |
< |
c25 |
= |
24 |
u4 |
+ |
v1 |
= |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
u3 |
+ |
v1 |
= |
22 |
< |
c31 |
= |
27 |
u4 |
+ |
v5 |
= |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
u3 |
+ |
v2 |
= |
0 |
< |
c32 |
= |
14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u4 |
+ |
v2 |
= |
-16 |
< |
c42 |
= |
14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u4 |
+ |
v3 |
= |
-7 |
< |
c43 |
= |
28 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u4 |
+ |
v4 |
= |
-6 |
< |
c44 |
= |
8 |
Так как все суммы больше cij, то план оптимален. Число ε близко к 0, следовательно план примет вид
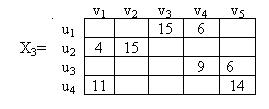 =
X*
- оптимальный план.
=
X*
- оптимальный план.
F(X*)=15·11+6·12+4·26+4·15+9·10+6·18+11·6+2·14=165+72+104+60+90+108+28+66=693.
36. Метод динамического программирования и его применение в задачах распределения ресурсов.
Этот метод успешно применяется в задачах, которые нужно разложить на более мелкие задачи.
Xi - объем ресурсов , выделяемых i – ой работе, i=1,…m
Пусть К 1 – суммарный запас ресурсов.
Даны функции f i (Xi) – выполнение i – ой работы в зависимости от величины выделяемых ресурсов.
Найти такое распределение ресурсов между работами , которое обеспечит максимальную эффективность выполнения всех работ.
Задача: fi(Xi)max
i Xi0
Xi K1
i
‘’i – ый шаг'' – поиск оптимального значения i- ой искомой переменной.
К i – остаток от К1 для i-ого, (i+1)-ого и далее шагов до n – ого шага.
К i+1 = К i - Х i
n) Xn*=? Пусть для данного шага осталось К n (неизвестное число), тогда fn(Xn)max 0XnKn
Xn* = (Kn) и пусть fn(Xn*) = n(Kn). Зная эти функции, переходим к предыдущему шагу.
n-1) Xn-1* =? Kn-1
Xn-1*: fn-1(Xn-1)+ n(Kn) max ;
0 Xn-1Kn-1; Kn=Kn-1 – Xn-1
И тогда мы находим: Xn-1* n-1(Kn-1)
fn-1(Xn-1*)+ n(Kn-1 – Xn-1*)n-1(Kn-1) и т.д.
X1=? K1
X1*: f1(X1) )+ 2(K2) max
0 X1K1; K2=K1 – X1
и находим Х1*= 1(K1) (нашли Х1)
Х1* К2=К1 – Х1* Х2*=2(K2) К3=…Х3*=……Хn*
37.Численные методы безусловной оптимизации нулевого порядка
Основные определения
Решение многих теоретических и практических задач сводится к отысканию экстремума (наибольшего или наименьшего значения) скалярной функции f(х) n-мерного векторного аргументах. В дальнейшем под x будем понимать вектор-столбец (точку в n-мерном пространстве):
![]()
Вектор-строка получается путем применения операции транспонирования:
![]() .
.
Оптимизируемую функцию f(x) называют целевой функцией или критерием оптимальности.
В дальнейшем без ограничения общности будем говорить о поиске минимального значения функции f(x) записывать эту задачу следующим образом:
f(x ) --> min.
Вектор х*, определяющий минимум целевой функции, называют оптимальным.
Отметим, что задачу максимизации f(x) можно заменить эквивалентной ей задачей минимизации или наоборот. Рассмотрим это на примере функции одной переменной (Рис. 2.1). Если х* - точка минимума функции y = f(x), то для функции y =- f(x) она является точкой максимума, так как графики функций f(x) и - f(x), симметричны относительно оси абсцисс. Итак, минимум функции f(x) и максимум функции - f(x) достигаются при одном и том же значении переменной. Минимальное же значение функции f(x), равно максимальному значению функции - f(x), взятому с противоположным знаком, т.е. min f(x) =-max(f(x)).
Рассуждая аналогично, этот вывод нетрудно распространить на случай функции многих переменных. Если требуется заменить задачу минимизации функции f(x1, …, xn) задачей максимизации, то достаточно вместо отыскания минимума этой функции найти максимум функции f(x1, …, xn). Экстремальные значения этих функций достигаются при одних и тех же значениях переменных. Минимальное значение функции f(x1, …, xn) равно максимальному значению функции - f(x1, …, xn), взятому с обратным знаком, т.е. min f(x1, …, xn) =max f(x1, …, xn). Отмеченный факт позволяет в дальнейшем говорить только о задаче минимизации.
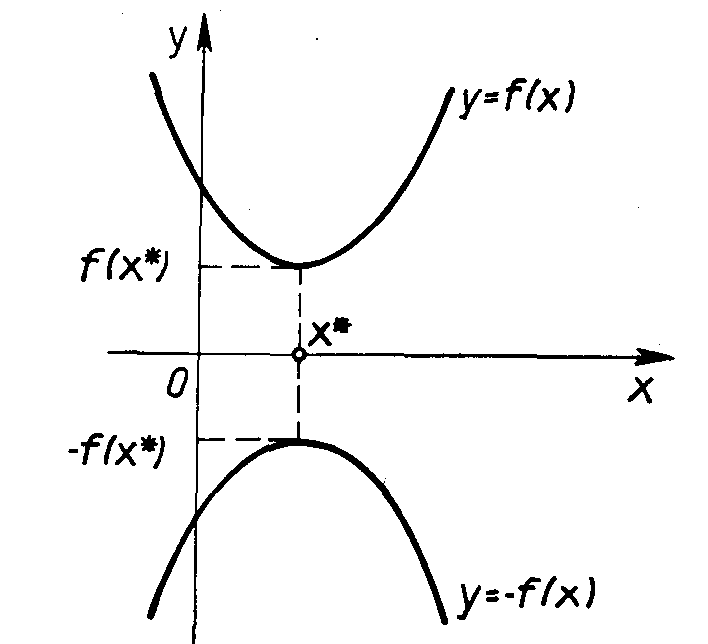
Рис. 2.1. Экстремум
В реальных условиях на переменные xj, i=1, …. n, и некоторые функции gi (х), hi(х), характеризующие качественные свойства объекта, системы, процесса, могут быть наложены ограничения (условия) вида:
gi (х) = 0, i=1, …. n,
hi (х) <= 0, i=1, …. n,
a <= x <= b,
где
![]() ;
;
![]()
Такую задачу называют задачей условной оптимизации. При отсутствии ограничений имеет место задача безусловной оптимизации.
Каждая точка х в n-мерном пространстве переменных х1, …, хn, в которой выполняются ограничения, называется допустимой точкой задачи. Множество всех допустимых точек называют допустимой областью G. Решением задачи (оптимальной точкой) называют допустимую точку х*, в которой целевая функция f(х) достигает своего минимального значения.
Точка
х*
определяет глобальный
минимум
функции одной переменной f(x),
заданной на числовой прямой Х
, если x
*![]() X и f(x*)
< f(x)
для всех x*
X
(Рис. 2.2, а). Точка х*
называется точкой
строгого глобального минимума,
если это неравенство выполняется как
строгое. Если же в выражении f(х*)
<= f(x)
равенство возможно при х,
не равных х*,
то реализуется нестрогий
минимум, а
под решением в этом случае понимают
множество х*
= [x*
X:
f(x) = f(x*)]
(Рис. 2.2, б).
X и f(x*)
< f(x)
для всех x*
X
(Рис. 2.2, а). Точка х*
называется точкой
строгого глобального минимума,
если это неравенство выполняется как
строгое. Если же в выражении f(х*)
<= f(x)
равенство возможно при х,
не равных х*,
то реализуется нестрогий
минимум, а
под решением в этом случае понимают
множество х*
= [x*
X:
f(x) = f(x*)]
(Рис. 2.2, б).
Рис. 2.2. Глобальный минимум. а - строгий, б - нестрогий
Точка х* Х определяет локальный минимум функции f(x) на множестве Х , если при некотором достаточно малом e > 0 для всех х, не равных х*, x X, удовлетворяющих условию ¦х - х*¦<= e, выполняется неравенство f(х*) < f(х). Если неравенство строгое, то х* является точкой строгого локального минимума. Все определения для максимума функции получаются заменой знаков предыдущих неравенств на обратные. На Рис. 2.3 показаны экстремумы функции одной переменной f(х) на отрезке [a, b] . Здесь х1, х3, х6 - точки локального максимума, а х2, х4 - локального минимума. В точке х6 реализуется глобальный максимум, а в точке х2 - глобальный минимум.
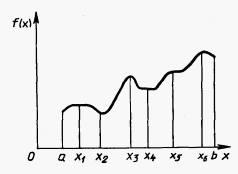
Рис. 2.3. Экстремумы функции
Классификация методов
Возможны два подхода к решению задачи отыскания минимума функции многих переменных f(x) = f(x1, ..., хn) при отсутствии ограничений на диапазон изменения неизвестных. Первый подход лежит в основе косвенных методов оптимизации и сводит решение задачи оптимизации к решению системы нелинейных уравнений, являющихся следствием условий экстремума функции многих переменных. Как известно, эти условия определяют, что в точке экстремума х* все первые производные функции по независимым переменным равны нулю:
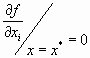 ,
i=1, …, n.
,
i=1, …, n.
Эти условия образуют систему п нелинейных уравнений, среди решений которой находятся точки минимума. Вектор f’(х), составленный из первых производных функции по каждой переменной, т.е.
![]() ,
,
называют градиентом скалярной функции f(x). Как видно, в точке минимума градиент равен нулю.
Решение систем нелинейных уравнений - задача весьма сложная и трудоемкая. Вследствие этого на практике используют второй подход к минимизации функций, составляющий основу прямых методов. Суть их состоит в построении последовательности векторов х [0], х [1], …, х [n], таких, что f(х[0])> f(х [1])> f(х [n])>… В качестве начальной точки x[0] может быть выбрана произвольная точка, однако стремятся использовать всю имеющуюся информацию о поведении функции f(x), чтобы точка x[0] располагалась как можно ближе к точке минимума. Переход (итерация) от точки х [k] к точке х [k+1], k = 0, 1, 2, ..., состоит из двух этапов:
выбор направления движения из точки х [k];
определение шага вдоль этого направления.
Методы построения таких последовательностей часто называют методами спуска, так как осуществляется переход от больших значений функций к меньшим.
Математически методы спуска описываются соотношением
x[k+1] = x[k] + akp[k], k = 0, 1, 2, ...,
где p[k] - вектор, определяющий направление спуска; ak - длина шага. В координатной форме:
Различные методы спуска отличаются друг от друга способами выбора двух параметров - направления спуска и длины шага вдоль этого направления. На практике применяются только методы, обладающие сходимостью. Они позволяют за конечное число шагов получить точку минимума или подойти к точке, достаточно близкой к точке минимума. Качество сходящихся итерационных методов оценивают по скорости сходимости.
В методах спуска решение задачи теоретически получается за бесконечное число итераций. На практике вычисления прекращаются при выполнении некоторых критериев (условий) останова итерационного процесса. Например, это может быть условие малости приращения аргумента
![]()
или функции
![]() .
.
Здесь k - номер итерации; e, g - заданные величины точности решения задачи.
Методы поиска точки минимума называются детерминированными, если оба элемента перехода от х[k] к x[k+l] (направление движения и величина шага) выбираются однозначно по доступной в точке х [k] информации. Если же при переходе используется какой-либо случайный механизм, то алгоритм поиска называется случайным поиском минимума.
Детерминированные алгоритмы безусловной минимизации делят на классы в зависимости от вида используемой информации. Если на каждой итерации используются лишь значения минимизируемых функций, то метод называется методом нулевого порядка. Если, кроме того, требуется вычисление первых производных минимизируемой функции, то имеют место методы первого порядка, при необходимости дополнительного вычисления вторых производных - методы второго порядка.
В настоящее время разработано множество численных методов для задач как безусловной, так и условной оптимизации. Естественным является стремление выбрать для решения конкретной задачи наилучший метод, позволяющий за наименьшее время использования ЭВМ получить решение с заданной точностью.
Качество численного метода характеризуется многими факторами: скоростью сходимости, временем выполнения одной итерации, объемом памяти ЭВМ, необходимым для реализации метода, классом решаемых задач и т. д. Решаемые задачи также весьма разнообразны: они могут иметь высокую и малую размерность, быть унимодальными (обладающими одним экстремумом) и многоэкстремальными и т. д. Один и тот же метод, эффективный для решения задач одного типа, может оказаться совершенно неприемлемым для задач другого типа. Очевидно, что разумное сочетание разнообразных методов, учет их свойств позволят с наибольшей эффективностью решать поставленные задачи. Многометодный способ решения весьма удобен в диалоговом режиме работы с ЭВМ. Для успешной работы в таком режиме очень полезно знать основные свойства, специфику методов оптимизации. Это обеспечивает способность правильно ориентироваться в различных ситуациях, возникающих в процессе расчетов, и наилучшим образом решить задачу.
Общая характеристика методов нулевого порядка
В этих методах для определения направления спуска не требуется вычислять производные целевой функции. Направление минимизации в данном случае полностью определяется последовательными вычислениями значений функции. Следует отметить, что при решении задач безусловной минимизации методы первого и второго порядков обладают, как правило, более высокой скоростью сходимости, чем методы нулевого порядка. Однако на практике вычисление первых и вторых производных функции большого количества переменных весьма трудоемко. В ряде случаев они не могут быть получены в виде аналитических функций. Определение производных с помощью различных численных методов осуществляется с ошибками, которые могут ограничить применение таких методов. Кроме того, на практике встречаются задачи, решение которых возможно лишь с помощью методов нулевого порядка, например задачи минимизации функций с разрывными первыми производными. Критерий оптимальности может быть задан не в явном виде, а системой уравнений. В этом случае аналитическое или численное определение производных становится очень сложным, а иногда невозможным. Для решения таких практических задач оптимизации могут быть успешно применены методы нулевого порядка. Рассмотрим некоторые из них.
38.Прямые методы условной оптимизации
Основные определения
Задача условной оптимизации заключается в поиске минимального или максимального значения скалярной функции f(x) n-мерного векторного аргументах (в дальнейшем без ограничения общности будут рассматриваться задачи поиска минимального значения функции):
f(x) -> min
при ограничениях:
gi(x)
![]() 0,
i
1,
..., k;
0,
i
1,
..., k;
hj(x)
![]() 0,
j
1,
.., m;
0,
j
1,
.., m;
a x b.
Здесь x, a, b — векторы-столбцы:
![]() ,
,
![]() ,
,
![]()
Оптимизируемую функцию f(x) называют целевой функцией. Каждая точка x в n-мерном пространстве переменных x1, ..., х, в которой выполняются ограничения задачи, называется допустимой точкой задачи. Множество всех допустимых точек называется допустимой областью G . Будем считать, что это множество не пусто. Решением задачи считается допустимая точка х*, в которой целевая функция f(х) достигает своего минимального значения. Вектор х* называют оптимальным. Если целевая функция f(x) и ограничения задачи представляют собой линейные функции независимых переменных х1, ..., хn, то соответствующая задача является задачей линейного программировании, в противном случае - задачей нелинейного программирования. В дальнейшем будем полагать, что функции f(x), g(x), i 1, ..., k , hj(x), j 1, …, m, - непрерывные и дифференцируемые.
В
общем случае численные методы решения
задач нелинейного программирования
можно разделить на прямые и непрямые.
Прямые методы
оперируют непосредственно с исходными
задачами оптимизации и генерируют
последовательности точек {x[k]},
таких, что f(х[k+1])
![]() f(x[k]).
В силу этого такие методы часто называют
методами
спуска.
Математически переход на некотором k-м
шаге (k.
0,
1, 2, ...) от точки х[k]
к точке
x[k+1]
можно записать в следующем виде:
f(x[k]).
В силу этого такие методы часто называют
методами
спуска.
Математически переход на некотором k-м
шаге (k.
0,
1, 2, ...) от точки х[k]
к точке
x[k+1]
можно записать в следующем виде:
x[k+l] x[k] + akp[k],
где р[k] — вектор, определяющий направление спуска; аk — длина шага вдоль данного направления. При этом в одних алгоритмах прямых методов точки х[k] выбираются так, чтобы для них выполнялись все ограничения задачи, в других эти ограничения могут нарушаться на некоторых или всех итерациях. Таким образом, в прямых методах при выборе направления спуска ограничения, определяющие допустимую область G, учитываются в явном виде.
Непрямые методы сводят исходную задачу нелинейного программирования к последовательности задач безусловной оптимизации некоторых вспомогательных функций. При этих методах ограничения исходной задачи учитываются в неявном виде.
Рассмотрим некоторые алгоритмы прямых методов.
Метод проекции градиента
Рассмотрим данный метод применительно к задаче оптимизации с ограничениями-неравенствами. В качестве начальной выбирается некоторая точка допустимой области G. Если х[0] - внутренняя точка множества G (Рис. 3.1), то рассматриваемый метод является обычным градиентным методом:
x[k+l] x[k] –akf’(x[k]), k 0, 1, 2, ...,
где
градиент целевой функции f(х) в точке x[k].
После выхода на границу области G в некоторой граничной точке х[k] , k 0, 1, 2,..., движение в направлении антиградиента -f’(х[k]) может вывести за пределы допустимого множества (см. Рис. 3.1). Поэтому антиградиент проецируется на линейное многообразие М, аппроксимирующее участок границы в окрестности точки х[k]. Двигаясь в направлении проекции вектора -f'(x[k]) на многообразие М, отыскивают новую точку х[k+1], в которой f(х[k+1]) f(x[k]), принимают х[k+1] за исходное приближение и продолжают процесс. Проведем более подробный анализ данной процедуры.
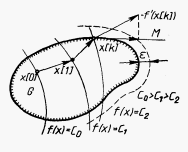
Рис. 3.1. Геометрическая интерпретация метода проекции градиента
В точке х[k] часть ограничений-неравенств удовлетворяется как равенство:
hi(x) 0, j 1, ..., l; l m.
Такие ограничения называют активными.
Обозначим через J набор индексов j(1 j l) этих ограничений. Их уравнения соответствуют гиперповерхностям, образующим границу области G в окрестности точки х[k] . В общем случае эта граница является нелинейной (см. рис. 3.1). Ограничения hj(x), j J, аппроксимируются гиперплоскостями, касательными к ним в точке х[k]:
![]()
Полученные гиперплоскости ограничивают некоторый многогранник М, аппроксимирующий допустимую область G в окрестности точки х[k] (см. Рис. 3.1).
Проекция р[k] антиградиента -f'(x[k]) на многогранник вычисляется по формуле
p[k] P[-f’(x[k])].
Здесь Р - оператор ортогонального проектирования, определяемый выражением
Р E – AT(AAT)-1A,
где Е - единичная матрица размеров п; А - матрица размеров lхn . Она образуется транспонированными векторами-градиентами аj, j 1, ..., l, активных ограничений. Далее осуществляется спуск в выбранном направлении:
x[k+1] x[k] + akp[k].
Можно показать, что точка х[k+1] является решением задачи минимизации функции f(х) в области G тогда и только тогда, когда Р[-f’(x[k])] 0,
т.
е![]() ,
и
u
(u1,
..., ul)
(ATA)-1AT(-f’(х[k]))
,
и
u
(u1,
..., ul)
(ATA)-1AT(-f’(х[k]))
![]() 0.
0.
Эти условия означают, что антиградиент (-f’(х[k])) целевой функции является линейной комбинацией с неотрицательными коэффициентами градиентов ограничений hj(x) 0.
В соответствии с изложенным алгоритм метода проекции градиента состоит из следующих операций.
1. В точке х[k] определяется направление спуска р[k].
2. Находится величина шага аk.
3. Определяется новое приближение х[k+1].
Рассмотрим детально каждую из этих операций.
1. Определение направления спуска состоит в следующем. Пусть найдена некоторая точка х[k] G и известен набор активных ограничений hi(х[k]) 0, j J. На основании данной информации вычисляют (-f’(х[k])) и определяют проекцию Р[-f’(х[k])]. При этом возможны два случая:
а) Р[-f’(х[k])] не равна 0. В качестве направления спуска р[k] принимают полученную проекцию;
б) Р[-f’(х[k])] 0, т. е. .
Данное
выражение представляет собой систему
из п
уравнений для определения коэффициентов
иj.
Если все иj
![]() 0,
j
J,
то в
соответствии с вышеизложенным точка
х[k]
является решением задачи. Если же
некоторый компонент иq
0,
то соответствующий ему градиент выводится
из матрицы А
и порождается новая проецирующая матрица
Р.
Она определит новое направление спуска.
0,
j
J,
то в
соответствии с вышеизложенным точка
х[k]
является решением задачи. Если же
некоторый компонент иq
0,
то соответствующий ему градиент выводится
из матрицы А
и порождается новая проецирующая матрица
Р.
Она определит новое направление спуска.
2. Для определения величины шага аk целевая функция минимизируется по направлению р[k] при условии соблюдения ограничений задачи с установленной точностью. Последняя задается введением некоторого положительного числа e. Считают, что точка х удовлетворяет условиям задачи с заданной точностью, если hi(х) e, j 1, ..., m. Величина шага аk определяется решением задачи вида:
f(x[k] + ар[k]) > min;
hj(x[k] + ар[k]) e, j 1, ..., m.
3. Определение нового приближения состоит в следующем. Очередная точка вычисляется по формуле
x[k+1] x[k] + аkр[k].
Признаком сходимости является стремление к нулю векторов р[k]. Рассмотренный метод является в некотором смысле аналогом градиентных методов для решения задач на безусловный экстремум, и ему свойствен их недостаток - медленная сходимость.
39. Задачи нечеткого математического программирования Классификация и общая характеристика.
Во многих случаях задачу принятия решений в общем виде можно описать множеством допустимых выборов (альтернатив) и заданным на этом множестве отношением предпочтения, которое отображает интересы лица, принимающего решение.
Как правило, это отношение является бинарным, то есть позволяет сравнивать попарно лишь две альтернативы.
В этом случае задача принятия решений заключается в выборе допустимой альтернативы, которая является лучшей среди всех альтернатив для заданного отношения предпочтения.
Отношение предпочтения на множестве альтернатив можно описать двумя способами: 1) с помощью функции полезности (utility function); 2) в виде бинарного отношения предпочтения.
Функция полезности обычно имеет вид отображения множества альтернатив на числовую ось.
Не всякое отношение предпочтения и не на всяком множестве альтернатив можно описать функцией полезности.
В некоторых случаях это отношение удается описать с помощью конечного набора функций полезности, и тогда соответствующие задачи принятия решений являются многокритериальными.
Задачи принятия решений, в которых используются функции полезности, являются задачами математического программирования. Оптимальным решением в таких задачах является выбор допустимой альтернативы, на которой функция полезности принимает максимальное значения.
Нечеткость в постановке задачи математического программирования может содержаться как при описании множества альтернатив, так и при описании функций полезности.
Задачи, в которых нечетко описано множество альтернатив и (или) функции полезности, называют задачами нечеткого математического программирования [20, 26, 37].
Анализируя задачи НМП, можно выделить два разных подхода к их решению. При первом подходе, впервые предложенном Р.Беллманом и А.Заде [65], задача НМП формулируется как задача выполнения нечеткой цели при нечетких ограничениях, причем решение задается пересечением нечетких множеств цели и ограничений.
При втором подходе предполагается, что решения должны выбираться подобно тому, как это делается в задачах многокритериальной оптимизации. Рассматриваются лишь такие решения (альтернативы), которые не доминируются строго никакими иными альтернативами, то есть выбираются эффективные альтернативы в понимании Парето.
Такие решения используют аппарат нечетких отношений преимущества.
Задача достижения нечетко определенной цели (подход Беллмана—Заде).
Задача достижения нечетко определенной цели, сформулированная Р.Белманом—Л.Заде, базируется на предположении, что цель принятия решений и множество альтернатив рассматриваются как равноправные нечеткие подмножества некоторого универсального множества альтернатив. Это допущение позволяет найти решение задачи относительно просто [65].
Пусть
![]() —
универсальное множество альтернатив,
то есть универсальная совокупность
возможных выборов ЛПР.
—
универсальное множество альтернатив,
то есть универсальная совокупность
возможных выборов ЛПР.
Нечеткой
целью в
является
нечеткое подмножество
,
которое обозначим
![]() .
.
Нечеткая
цель описывается функцией принадлежности
![]() .
.
Пример
9.5. Пусть
—
числовая ось. Тогда нечеткой целью ЛПР
может быть, например, нечеткое множество
вида:
![]() -
значительно больше 10.
-
значительно больше 10.
Предполагается,
что такие нечеткие множества вполне
точно описываются функциями полезности.
Чем больше степень принадлежности
альтернативы x нечеткому множеству
,
то есть чем больше значение
![]() ,
тем больше степень достижения этой цели
при выборе альтернативы
,
тем больше степень достижения этой цели
при выборе альтернативы
![]() в
качестве решения. Нечеткие ограничения
также описываются нечеткими подмножествами.
в
качестве решения. Нечеткие ограничения
также описываются нечеткими подмножествами.
Так, в вышеприведенном примере нечеткое ограничение может быть, например, таким: должно быть приблизительно равно 31, или должно быть намного больше 25.
Определим теперь, что понимается под решением задачи достижения нечеткой цели. Решить данную задачу означает достигнуть цели и удовлетворить ограничению, причем в данной постановке необходимо говорить не просто о достижении цели ,а об ее достижении с той или иной степенью, с учетом степени выполнения ограничений.
В подходе Беллмана – Заде эти факторы учитываются так.
Пусть
некоторая альтернатива
обеспечивает
достижение цели со степенью
и
удовлетворяет ограничение
![]() со
степенью
со
степенью
![]() .Тогда
принимают, что степень принадлежности
этой альтернативы решению задачи равна
минимуму из этих величин. Таким образом,
нечетким решением задачи достижения
нечеткой цели называется пересечение
нечетких множеств цели и ограничений,
то есть функция принадлежности решений
.Тогда
принимают, что степень принадлежности
этой альтернативы решению задачи равна
минимуму из этих величин. Таким образом,
нечетким решением задачи достижения
нечеткой цели называется пересечение
нечетких множеств цели и ограничений,
то есть функция принадлежности решений
![]() равна
равна
![]() (9.3.1)
(9.3.1)
При наличии нескольких целей и ограничений нечеткое решение описывается функцией принадлежности
![]() .
.
Если
различные цели и ограничения различаются
по степени важности и заданы соответствующие
коэффициенты относительной важности
целей![]() и ограничений
и ограничений
![]() ,
то
задается
выражением
,
то
задается
выражением
![]() (9.3.2)
(9.3.2)
Пример
9.6. Пусть
имеется универсальное множество
![]() ,
на котором заданы нечеткая цель
,
на котором заданы нечеткая цель
![]() (
близкое 5), нечеткое ограничение
(
близкое 5), нечеткое ограничение
![]() (
близкое
4) и
(
близкое
4) и
![]() (
близкое
6). Пусть их функции принадлежности
заданы в табл. 9.2.
(
близкое
6). Пусть их функции принадлежности
заданы в табл. 9.2.
Таблица 9.2.
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
0 |
0.1 |
0.4 |
0.8 |
1.0 |
0.7 |
0.4 |
0.2 |
0.1 |
0 |
|
0.3 |
0.6 |
0.7 |
1 |
0.9 |
0.8 |
0.5 |
0.3 |
0.2 |
0 |
|
0.2 |
0.4 |
0.6 |
0.7 |
0.9 |
1 |
0.8 |
0.6 |
0.4 |
0.2 |
Тогда
для решения
![]() получаем
функцию принадлежности
получаем
функцию принадлежности
![]() ,
а решение
интерпретируется
так:
должен
быть близким 5 (табл. 9.3).
,
а решение
интерпретируется
так:
должен
быть близким 5 (табл. 9.3).
Таблица 9.3
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
0 |
0.1 |
0.4 |
0.7 |
0.9 |
0.7 |
0.4 |
0.2 |
0.1 |
0 |
Это решение можно интерпретировать как нечетко сформулированную инструкцию. При таком представлении остается неопределенность, какую же альтернативу следует выбрать, то есть надо разрешить эту неопределенность. Существуют различные способы разрешения этой неопределенности. Наиболее распространенный из них, предложенный Л.Заде, состоит в выборе альтернативы, имеющей максимальную степень принадлежности нечеткому решению, то есть альтернатива определяется из условия:
![]() .
.
Такие альтернативы называются максимизирующими.
Классификация задач нечеткого математического программирования.
Задача математического программирования в общем виде формулируется так:
![]()
при
ограничениях
![]() ,
,
где
![]() –
целевая функция,
–
целевая функция,
![]() –
ограничение.
–
ограничение.
При
моделировании реальных задач в такой
форме нечеткость может проявиться в
форме нечеткого описания функций
![]() ,
и
параметров, от которых они зависят, и
самого множества
,
и
параметров, от которых они зависят, и
самого множества
![]() .
Подобное описание ситуации может
отражать, например, недостаточность
информации об этой ситуации или служить
формой приближенного описания ситуации,
достаточной для решения поставленной
задачи.
.
Подобное описание ситуации может
отражать, например, недостаточность
информации об этой ситуации или служить
формой приближенного описания ситуации,
достаточной для решения поставленной
задачи.
Формы нечеткого описания бывают различными. Соответственно существуют разные классы задач нечеткого математического программирования. Приведем некоторые типичные классы задач НМП [20].
Задача
1. Максимизация
заданной обычной функции
на
заданном нечетком множестве допустимых
альтернатив
![]() .
.
Для решения этой задачи предлагается провести нормировку функции следующим образом:
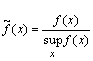 ,
,
причем
![]() рассматривается
как функция принадлежности нечеткого
множества цели ЛПР. Значение этой функции
интерпретируется как степень достижения
цели при выборе альтернативы
рассматривается
как функция принадлежности нечеткого
множества цели ЛПР. Значение этой функции
интерпретируется как степень достижения
цели при выборе альтернативы
![]() .
Это позволяет применить к решению
указанной задачи подход Беллмана –
Заде. Требуется найти такую альтернативу
.
Это позволяет применить к решению
указанной задачи подход Беллмана –
Заде. Требуется найти такую альтернативу
![]() ,
для которой достигается
,
для которой достигается
![]() ,
(9.3.3).
,
(9.3.3).
Можно проверить, что задачу отыскания этой альтернативы можно сформулировать следующим образом:
![]()
при
ограничениях:
![]() .
(9.3.4)
.
(9.3.4)
Задача 2. Нечеткий вариант стандартной задачи математического программирования.
Пусть задана следующая задача НМП:
![]() .
(9.3.5)
.
(9.3.5)
Нечеткий вариант этой задачи получается если:
1) смягчить ограничения, то есть допустить возможность их нарушения с той или иной степенью;
2)
вместо максимизации функции
можно
стремиться достичь некоторого заданного
значения
![]() этой
функции, причем различным отклонениям
от
следует
приписывать различные степени
допустимости. Эту задачу можно записать
так:
этой
функции, причем различным отклонениям
от
следует
приписывать различные степени
допустимости. Эту задачу можно записать
так:
![]() ,
(9.3.6)
,
(9.3.6)
где
знак![]() означает нечеткое выполнение
соответствующих неравенств.
означает нечеткое выполнение
соответствующих неравенств.
Один
из возможных подходов к формализации
подобных нечетко сформулированных
задач состоит в следующем. Пусть
-заданная
величина целевой функции
,
достижение которой считается достаточным
для выполнения цели
принятия решений, и пусть ЛПР задает
два порога
![]() и
и![]() такие, что неравенства
такие, что неравенства
![]() означают
сильное нарушение соответствующих
неравенств
означают
сильное нарушение соответствующих
неравенств
![]() .
Тогда можно ввести следующие нечеткие
множества цели и ограничений:
.
Тогда можно ввести следующие нечеткие
множества цели и ограничений:
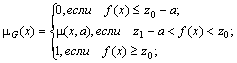 (9.3.7)
(9.3.7)
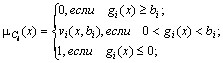 (9.3.8)
(9.3.8)
где
![]() –
некоторые функции
–
некоторые функции
![]() ,
описывающие степень выполнения
соответствующих неравенств с точки
зрения ЛПР. В результате исходная задача
оказывается сформулированной в форме
задачи достижения нечеткой цели и к ней
можно применить подход Беллмана–Заде.
,
описывающие степень выполнения
соответствующих неравенств с точки
зрения ЛПР. В результате исходная задача
оказывается сформулированной в форме
задачи достижения нечеткой цели и к ней
можно применить подход Беллмана–Заде.
Задача
3. Нечетко
описанная целевая функция, то есть
задано отображение
![]() ,
где
—
универсальное множество альтернатив,
,
где
—
универсальное множество альтернатив,
![]() —
числовая ось.
—
числовая ось.
Здесь
функция
![]() при
каждом фиксированном
—
это нечеткое описание оценки результата
выбора альтернативы, то есть нечеткая
оценка альтернативы
.
Кроме того, задано нечеткое множество
допустимых альтернатив с функцией
принадлежности
при
каждом фиксированном
—
это нечеткое описание оценки результата
выбора альтернативы, то есть нечеткая
оценка альтернативы
.
Кроме того, задано нечеткое множество
допустимых альтернатив с функцией
принадлежности
![]() .
К такой постановке сводится весьма
широкий класс задач НМП. Это наиболее
известная постановка задачи НМП.
.
К такой постановке сводится весьма
широкий класс задач НМП. Это наиболее
известная постановка задачи НМП.
Задача
4. Задана
обычная целевая функция
и
система ограничений
![]() ,
причем параметры в описаниях функций
заданы
в форме нечетких множеств. Например,
для линейной функции
имеют
вид
,
причем параметры в описаниях функций
заданы
в форме нечетких множеств. Например,
для линейной функции
имеют
вид
![]() ,
,
где
параметры
![]() являются
элементами нечетких множеств с функциями
принадлежности
являются
элементами нечетких множеств с функциями
принадлежности
![]() .
Указанный класс задач можно свести к
задачам типа 1 или 3.
.
Указанный класс задач можно свести к
задачам типа 1 или 3.
Задача
5. Функции
,
заданы
с точностью до нечетко определенных
параметров
![]() ,
которые являются элементами нечетких
множеств с заданными функциями
принадлежности
,
которые являются элементами нечетких
множеств с заданными функциями
принадлежности
![]() .
Этот класс задач можно свести к задачам
типа 3.
.
Этот класс задач можно свести к задачам
типа 3.
40. Игровые модели принятия решений в асу. Методы решения задач теории игр.
Основные понятия, определения и теоремы.
Теория игр – это способы математического описания конфликтных ситуаций и методы поиска оптимального поведения в этих ситуациях.
Конфликтная ситуация – это столкновение интересов нескольких лиц, имеющих противоположные цели.
Игра – это набор правил и соглашений, которым подчиняется данная конфликтная ситуация.
Каждый игрок преследует в игре свою цель. Степень достижения цели количественно характеризуется функцией цели, которая в теории игр называется функцией выигрыша. Так как в игре существуют правила и соглашения, то решения можно выбирать из некоторой допустимой области.
Рассмотрим f(X,Y) – функцию выигрыша.
X - мы выбираем. Y – выбирает противник.
1)
![]()
![]()
Определение: Точка с координатой (X0, Y0) , где X0 A , Y0 B, называется седловой точкой для f(X,Y), если выполняется следующее неравенство:
f(X,Y0) f(X0,Y0) f(X0,Y).
Понятие максимин (минимакс)
![]() – максимин
– максимин
![]() -
минимакс
-
минимакс
Как искать максимин:
XA
Y0
B: f(X,Y0)
![]()
2)
F(X)f(X,Y0(X))
X0A:
F(X)![]()
Как искать минимакс:
YB X0A: f(X,Y)
G(X)f(X0(Y),Y) Y0B: G(Y)
Теорема 1. a b (максимин не больше минимакса)
Теорема 2. Пусть существуют a и b, тогда для того, чтобы a = b необходимо и достаточно, чтобы функция выигрыша имела седловую точку (X0,Y0), причем f(X0,Y0)=a=b
Матричные игры
X: A={1,2,…,n}
Y: B={1,2,…,m}
aij – выигрыш игрока X при применении i-ой стратегии (j- стратегия Y)
i = 1,2,…,n , j = 1,2,…,m
Пусть aij > 0. j min
Пример: Дана матрица: I 3 5 2 4 2 max 2 = a
2 6 1 1 1
max
3 6 2 4
min
2 = b
a = max min; b = min max.
Если a = b выбираем стратегии: либо 1 игрок – 3-я стратегия, либо 2 игрок – 1-я стратегия.
Если a b, то приходится применять стратегии с вероятностями.
Поиск оптимальных вероятностей применения стратегий:
X: Y:
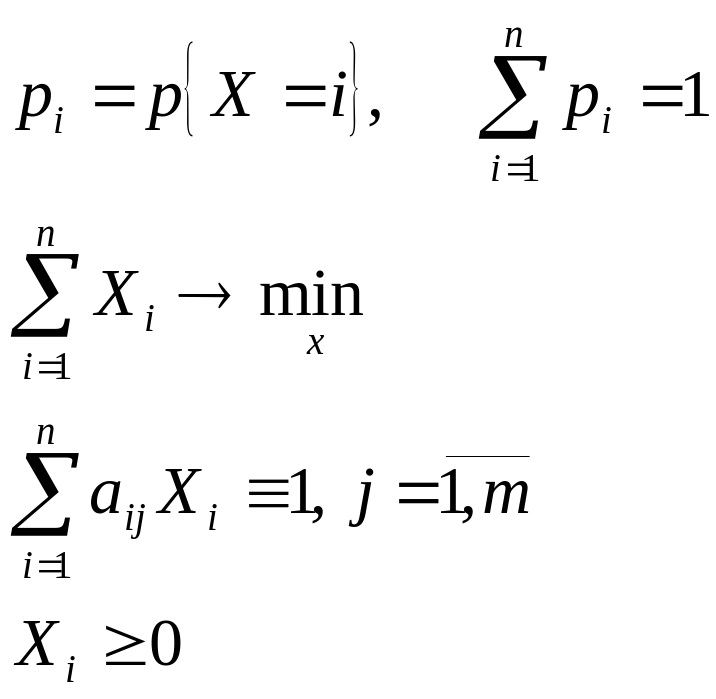
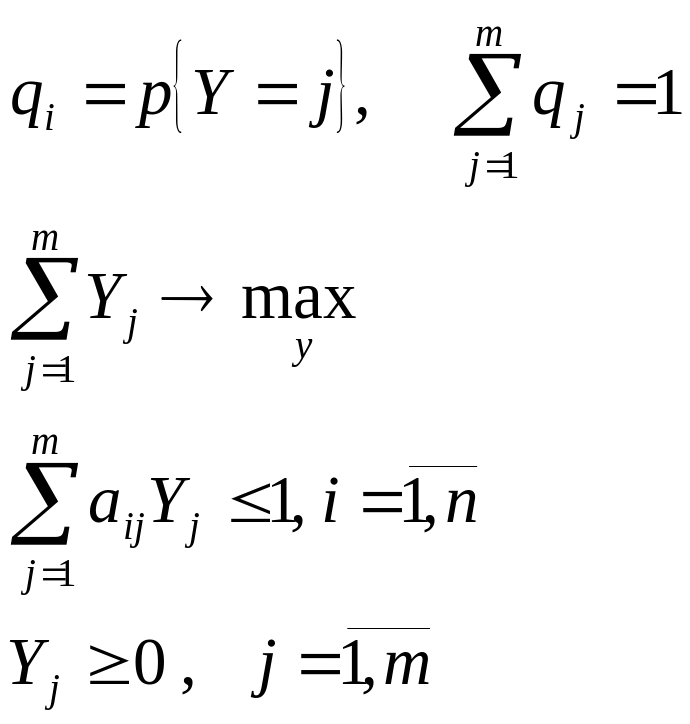
Пусть {Xi*} – оптимальное решение Пусть {Yj*} - опт. решение
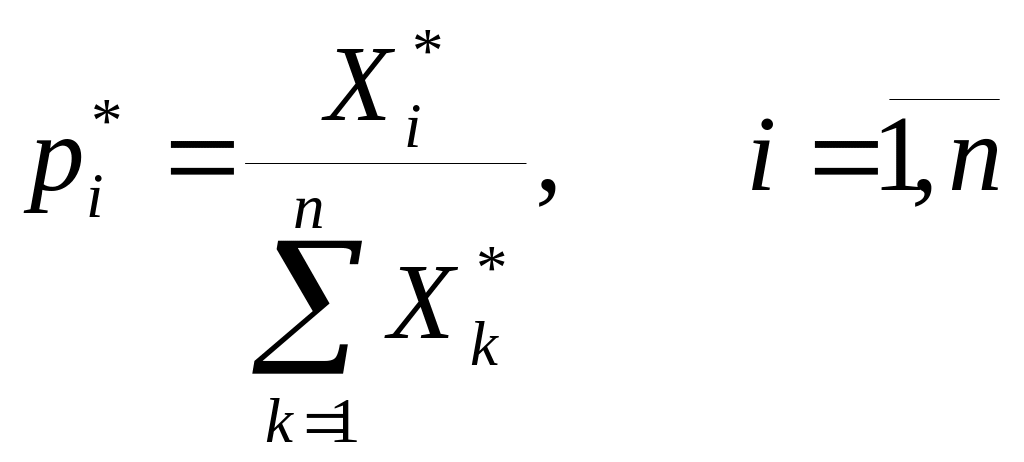
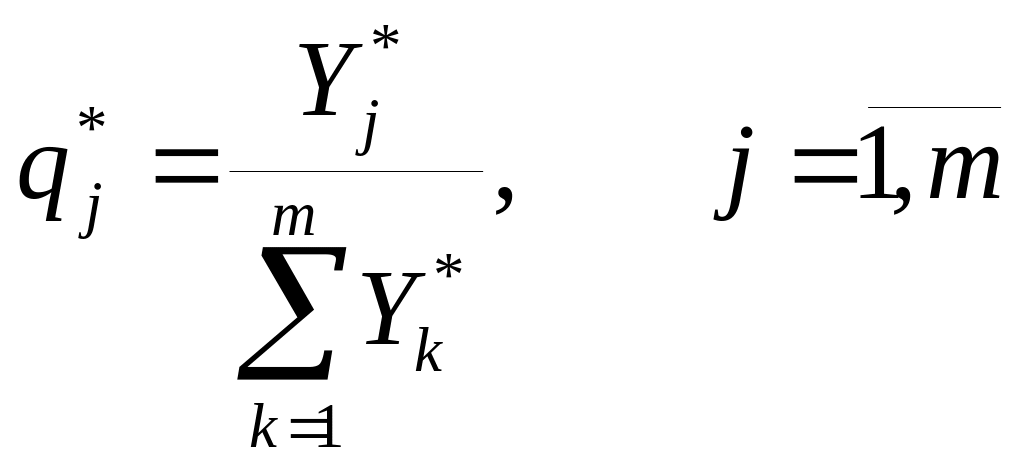
41. Марковские процессы принятия решений. Основные понятия теории случайных процессов.
Понятие случайного процесса тесно связано с понятием случайной величины.
Случайная величина Х есть некоторая функция от случайного события φ(ω):
Х= φ(ω).
В результате случайного события ωi получается случайная величина Хi:
Хi= φ(ωi).
Функция Х(t) называется случайным процессом, если её значение при любом значении аргумента t является случайной величиной. Из этого следует, что понятие случайного процесса является обобщением случайной величины. Т.е. функция Х(t) есть функция двух аргументов:
Х(t)=φ(ω,t),
ω – множество элементов парных событий, ω Ω;
t – время (Но может так же использоваться для обозначения длины дороги/трубопровода). t T.
В момент времени t` будем иметь значение Х. Фиксация случайного события в какой-то момент времени называется его сечением. В зависимости от того, что происходит в сети, будем иметь различные случайные события в момент времени t`.
Одна кривая называется реализацией.
 φ(ω,t)
φ(ω,t)
 реализация
реализация
В зависимости от того, какое значение имеет t и функция φ, будет иметь место следующая классификация случайных процессов:
1) Непрерывное t (время) и непрерывное φ (состояние). (См. рисунок выше.)
2) Непрерывное t и дискретное φ.
φ(ω,t)
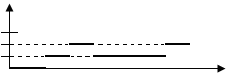 t
t
3) Дискретное t и дискретное φ.
φ(ω,t)
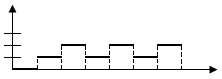 t
t
4) Дискретное t и непрерывное φ.
Дискретные случайные процессы.
Пример: техническое устройство может находиться в следующих состояниях:
S0 – работает исправно;
S1 – вышло из строя и ждет ремонта;
S2 – ремонтируется;
S3 – возвращается в работу;
S4 – списывается.
Случайные процессы, не число, описываются как угодно и дискретным, и непрерывным временем.
Система «блуждает» случайным образом по своим состояниям и числовая характеристика нас не интересует.
Математическое ожидание для дискретного случайного процесса с любым временем:
![]() .
.
Используют понятие центрирования случайного процесса:
![]() ,
где
,
где
mx(t) – математическое ожидание неизвестной величины Х.
Дисперсия (математическое ожидание от центрированной случайной величины):
![]() .
.
Корреляционный момент (математическое ожидание от двух центрированных случайных процессов):
![]() .
.
Если переходить от двух процессов к одному:
![]() .
.
Марковские случайные процессы.
Марковские случайные процессы названы по фамилии русского математика Маркова. Теория Марковских случайных процессов имеет наглядный и простой математический аппарат, находящий отражение в области знаний.
Дискретные состояния (качественные состояния).
Дискретная цепь Маркова задается ориентированным графом, в котором вершина есть состояние системы, а дуги графа для дискретного времени есть вероятности перехода из состояния в состояние. Для непрерывного времени интенсивности перехода, которое обычно задано, искомыми являются вероятности пребывания системы в некотором состоянии.
Стрелками обозначается переход системы из одного состояние в другое.
P01 – вероятность перехода системы из нулевого состояния в первое.
Этот ориентированный граф задается матрицей вероятностей переходов:
P00 |
P01 |
0 |
P03 |
P04 |
0 |
0 |
P12 |
0 |
0 |
0 |
0 |
0 |
P23 |
0 |
P30 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
P00 – вероятность задержки.
Р44 – поглощающая вершина. Сколько бы система не «блуждала» по своим состояниям, она вернется в ту же вершину.
Одномоментно система может находиться только в одном состоянии. Сумма вероятностей по строке равна единице, так как все вероятности составляют полную группу событий.
Определение Марковского процесса (для дискретного времени):
![]() .
.
Вероятность перехода из состояния i в состояние j на k-ом шаге, где k – состояние времени, определяется тем, что система на (k-1)-ом шаге находится в состоянии i, а на k-ом шаге в состоянии j.
Условия Марковости:
Случайный процесс «блуждания» в системе по своим состояниям является процессом с пуассоновским законом распределения.
Свойства:
Стационарный;
Ординарный (одновременно система может находиться в двух состояниях);
Без последствий (отсутствие функциональной связи между состояниями).
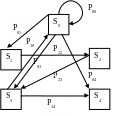
Для вычисления Pj – на k-том шаге существует соотношение Колмогорова – Чепмена:
![]()
Переход из состояния в состояние зависит от того, в каком состоянии находилась система на предыдущем шаге.
Pij(k) – матрица вероятности переходов на k-ом шаге, и эти вероятности могут меняться.
Для того, чтобы пользоваться этой формулой, необходимо знать начальные условия.
![]()
Вероятности i,j от шага к шагу могут меняться. Если матрица вероятности переходов не зависит от номера шага, то цепь Маркова называется однородной.
Условие однородности цепи Маркова – пуассоновский поток событий, который переводит систему из состояния в состояние.
Марковская цепь обладает еще одним свойством. Она может иметь стационарный режим. Стационарность режима работы цепи Маркова состоит в том, что вероятности пребывания системы в каком-либо состоянии перестают зависеть от номера шага, на котором рассматривается эта цепь, то есть Pj=const.
Если время дискретно.
Математический поток вероятностей входящей информации равен потоку вероятностей выходящей информации, то есть
![]()
- это система минимального алгоритма уравнений расчета пребывания системы в каком-либо состоянии.
Правило определения знака.
Если стрелка выходит из k-ого состояния, то поток вероятности берется с минусом, если стрелка входит в k-тое состояние системы, то поток вероятностей берется с плюсом.
Для нулевого состояния
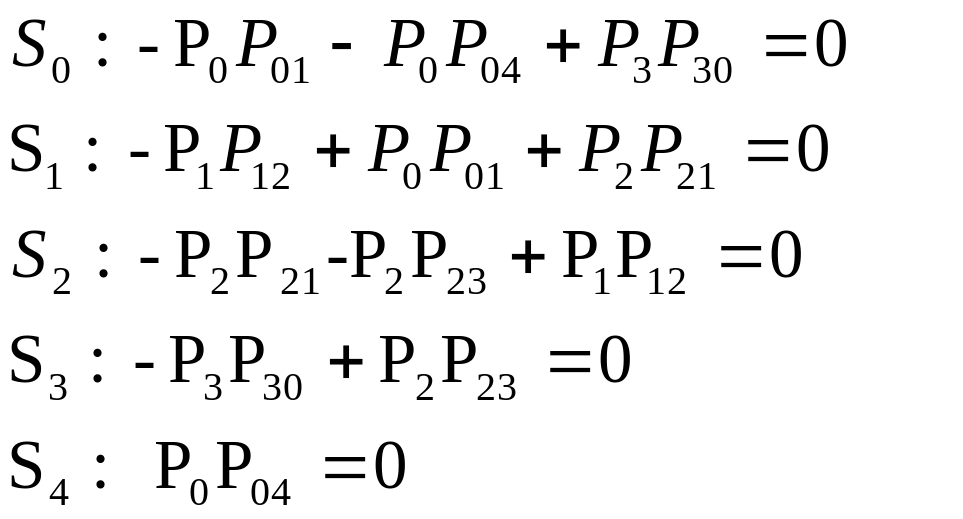 (вероятности
задержки в этой системе не учитываются)
(вероятности
задержки в этой системе не учитываются)
Начальные
условия:
![]()
Решается всегда одинаково. Самое большое уравнение отбрасывается, все остальные выражаются через самое маленькое.
Если имеются циклы, то стационарного режима не будет (то есть все будет зацикливаться). А в нашем случае условием выхода является S4.
Если время непрерывно.
Переход на непрерывное время выполняется при предположении, что квант становится очень мал:
![]() ,
где λij
–
интенсивность
перехода.
,
где λij
–
интенсивность
перехода.
Уравнение Колмогорова-Чепмена преобразуется в систему дифференциальных уравнений:
![]()
Для стационарного и пуассоновского потока событий λij=const
![]() ,
где
,
где
![]() -
среднее время перехода из i-ого
состояния в j-ое.
Тогда система (*) имеет вид:
-
среднее время перехода из i-ого
состояния в j-ое.
Тогда система (*) имеет вид:
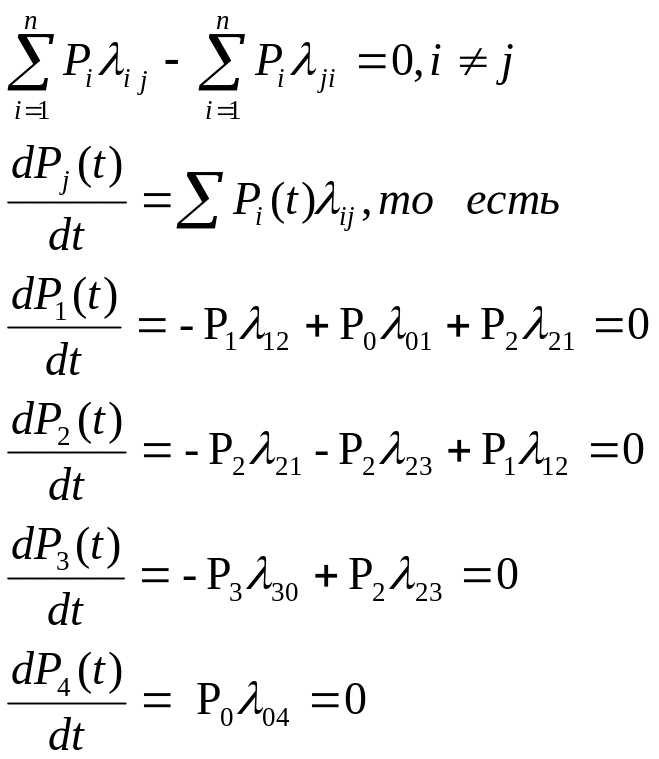
42. Системы массового обслуживания. Основные понятия теории массового обслуживания.
Условно систему массового обслуживания можно представить следующим образом:

очередь на обслуженные
обслуживание заявки
заявки
Объект обслуживания – это канал обслуживания (один или больше).
Для того чтобы система состоялась, на входе должны быть «заявки» (как информационные объекты, так и физические), а на выходе «обслуженные заявки».
Каналом обслуживания называется техническое или какое-либо другое устройство, обеспечивающее выполнение какой-либо заявки.
В теории массового обслуживания работа канала характеризуется тем временем, которое затрачивается на обслуживание одной заявки. В общем случае оно считается случайным и, как правило, время обслуживания в теории массового обслуживания подчиняется пуассоновскому закону распределения.
Из сказанного следует, что на выходе канала обслуживания будет появляться обслуженные заявки с интервалом времени, подчиняющимся пуассоновскому закону распределения. Из сказанного также следует, что если на входе системы существует очередь и каждая заявка обслуживается независимо от других и не покидает систему во время обслуживания, а только после его завершения, то интервалы времени между обслуженными заявками будут также независимы и подчинены пуассоновскому закону распределения.
Процесс
обслуживания обычно определяется
параметром обслуживания
![]() - среднее время обслуживания (пуассоновский
параметр).
- среднее время обслуживания (пуассоновский
параметр).
Интенсивность
потока заявок определяется как
![]()
В классических СМО потоки заявок на входе и выходе пуассоновские.
Дисциплина обслуживания – это порядок распределения заявок между свободными каналами, кроме того это закон образования очереди, закон поведения заявок в очереди и порядок обслуживания заявок.
Системы массового обслуживания бывают разомкнутые и замкнутые.
Разомкнутые системы: на вход поступает извне некоторый поток заявок, причем источник заявок в систему не входит и анализу не подвергается. Разомкнутые системы массового обслуживания бывают с отказами и без отказов: если система свободная, она обслуживается, если нет, то получает отказ на обслуживание.
В замкнутой системе число источников заявок ограничено и интенсивность поступления заявок зависит от состояния источников, обусловленных работой самой системы. При поступлении заявки на обслуживание заявка либо обслуживается, либо, если система занята, уходит из очереди. Очередь может быть ограниченная и не ограниченная. В замкнутой СМО заявка рано или поздно обслуживается, то есть никогда не получает отказа.
Разомкнутые системы массового обслуживания.
Условно разомкнутые системы массового обслуживания можно представить следующим образом:

![]()
![]()
поток заявок
На вход поступает поток заявок на обслуживание с интенсивностью λ.
На выходе:
- интенсивность потока обслуженных заявок;
- интенсивность потока необслуженных заявок.
Уравнение
расхода:
![]()
Обслуженные и не обслуженные заявки образуют полную группу событий, следовательно:
![]()
Кроме того, что является интенсивностью обслуженных заявок, это еще и абсолютная
пропускная способность системы массового обслуживания.
![]() -
относительная пропускная способность
СМО.
-
относительная пропускная способность
СМО.
Одноканальная система массового обслуживания.
Рассмотрим простейшую систему массового обслуживания, имеющую один канал.
Граф состояний простейшей системы может быть представлен следующим образом:
![]() Здесь:
Здесь:
![]() - канал свободен;
- канал свободен;
![]() - канал занят;
- канал занят;
![]() -
интенсивность поступления заявок;
-
интенсивность поступления заявок;
μ - интенсивность обслуживания заявок.
Система уравнений Колмогорова:

![]()
![]()
В начальный момент времени системы канал свободен:
(0)=1;
![]() (0)=0;
(0)=0;
![]()
Решая систему двух уравнений, можно получить две траектории:
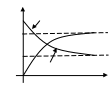
1
![]()
![]()
![]()
![]()
При
t
→ ∞
![]() - вероятность обслуживания.
- вероятность обслуживания.
Отсюда,
![]() .
.
Многоканальные системы массового обслуживания с отказами – система Эрланга.
Поток Эрланга получается из пуассоновского потока при равномерном прореживании.
Система массового обслуживания Эрланга имеет n каналов. На вход поступает n заявок с интенсивностью λ. Каждый канал работает с интенсивностью μ. Работа такой системы массового обслуживания описывается Марковским случайным процессом типа гибели-размножения следующего вида:
![]()
μ 2μ kμ (k+1)μ (n-1)μ nμ
На входе поток заявок имеет одну и ту же интенсивность λ вне зависимости от состояния.
В
состоянии
![]() все каналы свободны и ни одной заявки
не обслуживается.
все каналы свободны и ни одной заявки
не обслуживается.
В
состоянии
![]() занят один канал (какой, не важно), ведется
обслуживание одной заявки.
занят один канал (какой, не важно), ведется
обслуживание одной заявки.
В
состоянии
![]() занято
k
каналов и обслуживается k
заявок.
занято
k
каналов и обслуживается k
заявок.
В
состоянии
![]() заняты
все каналы и обслуживается n
заявок.
заняты
все каналы и обслуживается n
заявок.
Для
вычисления
![]() и
и
![]() Эрланг вывел следующие формулы:
Эрланг вывел следующие формулы:
формулы Эрланга

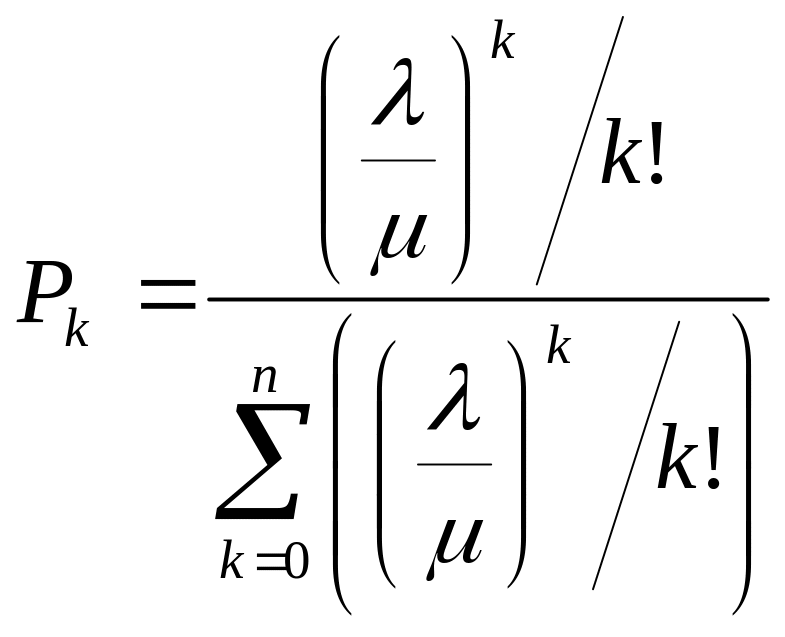

Если
![]() ,
тогда числитель можно обозначить как
,
тогда числитель можно обозначить как
![]() ,
а знаменатель
,
а знаменатель
![]() .
.
и - табличные функции. Таким образом:
![]() .
.
Из этого следует, что вероятность обслуживания равна:
![]() .
.
Замкнутые системы массового обслуживания.
Одноканальные СМО.
Есть некоторое количество станков N, которые обслуживает один наладчик. Каждый станок в любой момент времени может выйти из строя и потребовать обслуживания.
λ – интенсивность потока заявок на обслуживание каждого станка.
![]() ,
где t
– среднее время выхода станка из строя.
,
где t
– среднее время выхода станка из строя.
Если
в этот момент наладчик свободен, он
берется за наладку и тратит на это
определенное время tобсл.
Тогда интенсивность
обслуживания:![]() .
.
Если в момент выхода станка из строя наладчик занят, станок становится в очередь на обслуживание.
Граф состояний системы:
Состояния:
S0 – все станки работают, рабочий свободен;
S1 – один станок (неважно, какой) вышел из строя, рабочий занят его наладкой;
S2 – два станка неисправны, один из них (неважно какой) налаживается, один стоит в очереди и ждет наладки;
Sk – k станков вышло из строя, один налаживается, (k-1) стоит в очереди и т. д.
Поскольку рабочий один, μ одинакова во всех состояниях.
Запишем уравнения Колмогорова:
Вычислим характеристики эффективности работы этой системы:
Среднее количество неисправностей, которое устраняет наладчик в единицу времени. Вероятность занятости наладчика
 Если наладчик занят, он обслуживает
μ
станков в единицу времени, следовательно,
его абсолютная пропускная способность:
Если наладчик занят, он обслуживает
μ
станков в единицу времени, следовательно,
его абсолютная пропускная способность:
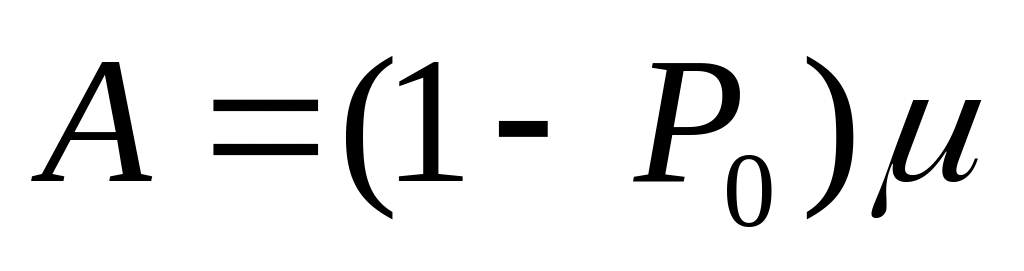 .
Вероятность того, что рабочий будет
свободен:
.
Вероятность того, что рабочий будет
свободен:
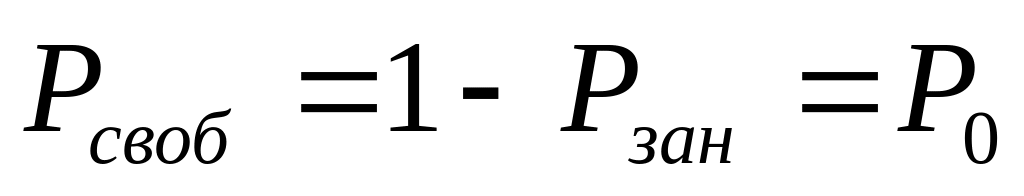 .
Среднее число неисправных станков
или, другими словами, среднее число
станков связано с обслуживанием:
.
Среднее число неисправных станков
или, другими словами, среднее число
станков связано с обслуживанием:
 - это математическое ожидание дискретных
случайных величин. Каждый работающий
станок порождает поток неисправностей
с интенсивностью λ.
В нашей системе среднее число работающих
станков:
- это математическое ожидание дискретных
случайных величин. Каждый работающий
станок порождает поток неисправностей
с интенсивностью λ.
В нашей системе среднее число работающих
станков:
 .
Поток неисправностей, которые они
порождают, равен
.
Поток неисправностей, которые они
порождают, равен
 .
Все эти неисправности устраняются
одним рабочим:
.
Все эти неисправности устраняются
одним рабочим:
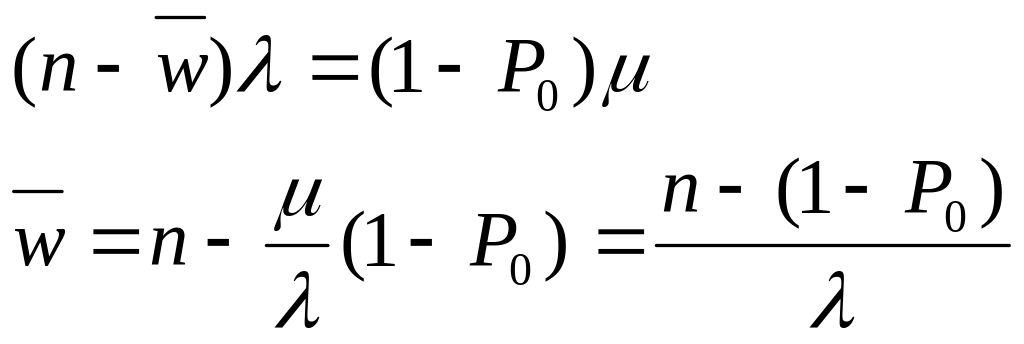
Количество станков, стоящих в очереди, или длина очереди.
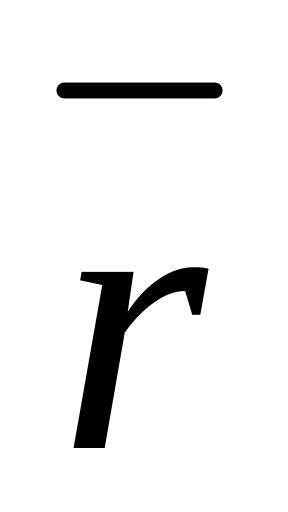 - среднее число станков, ожидающих в
очереди.
В любой момент времени w
– общее число станков, связанных с
обслуживанием,
R
– находящиеся в очереди станки,
- ремонтирующиеся.
- среднее число станков, ожидающих в
очереди.
В любой момент времени w
– общее число станков, связанных с
обслуживанием,
R
– находящиеся в очереди станки,
- ремонтирующиеся.
 - число станков, находящихся на
обслуживании.
- число станков, находящихся на
обслуживании.
 С
точки зрения теории вероятностей
- это индикатор событий. Тогда среднее
значение
С
точки зрения теории вероятностей
- это индикатор событий. Тогда среднее
значение
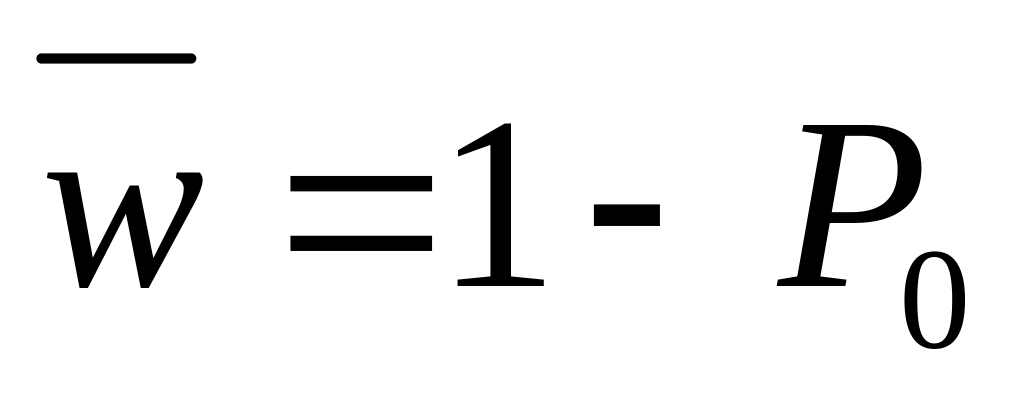
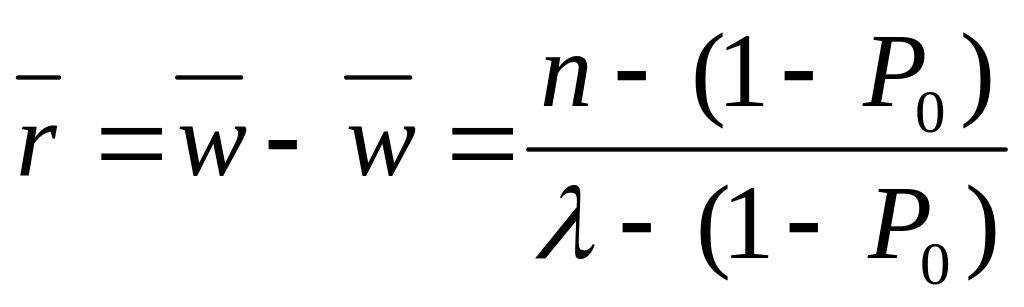
Многоканальные СМО.
Размножение состояний неисправностей осталось тем же
n – станции;
m – наладки.
S0 – все n станков работают и все m наладчиков свободны;
Sm – предположим, сломалось m станков. Все m станков обслуживаются и все рабочие заняты;
Sm+1 – сломался m+1 станок, m станков обслуживается и один стоит в очереди.
В состоянии Sn – m станков обслуживаются, остальные стоят в очереди.
Граф состояний системы:
Запишем уравнения Колмогорова для стационарного состояния этого графа. Выразим Pk через P0:
Среднее число занятых рабочих:
![]()
Абсолютная пропускная способность системы:
![]()
44. Корреляционный анализ
Для характеристики многомерного эмпирического распределения вычисляют его числовые параметры, позволяющие делать выводы о существовании зависимостей между компонентами.
Корелляционный
момент:
![]()
М – математическое ожидание произведения центрированных величин.
![]()
![]() ;
;
![]() ;
;
Dx, Dy – дисперсии величин х и у.
х,у – средние квадратические отклонения величин х и у.
![]() ;
;
![]() ;
;
![]() ;
;
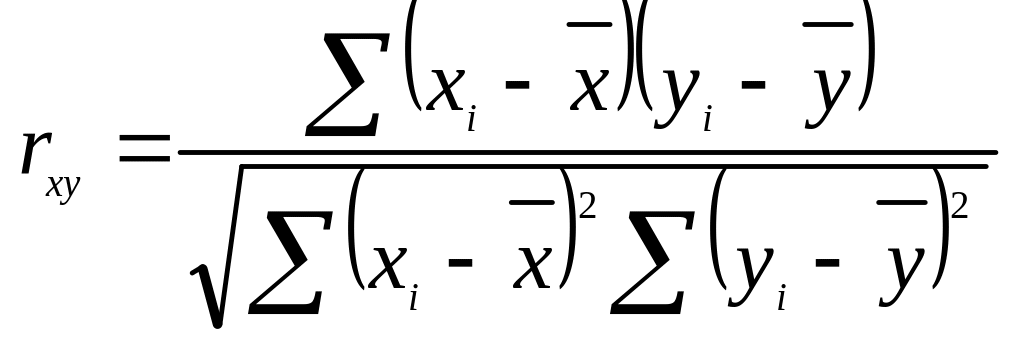 ,
,
![]() .
.
Коэффициент корреляции rxy является мерой силы (тесноты) и направления линейной связи между двумя переменными х и у, вычисленной по ряду из n пар значений (x1, y1), (x2, y2), … , (xn, yn).
Показывает степень значения:
Если rxy=0 , независимые случайные величины;
Если rxy =1, линейная положительная зависимость;
Если rxy=-1, отрицательная связь.
При пользовании коэффициентом корреляции подразумевается, что выборка (x1, y1), i=1,2,…n, получена из двумерной нормальной генеральной совокупности.
Проверка на значимость:
Н0: rxy=0 ; Н1: между х и у существует линейная зависимость.
Статистика
критерия
![]() , где
, где
![]() имеет распределение Стьюдента с V=n-2.
Н0
отвергается, если t
> tкр,
найденного по таблице для данных
и V.
имеет распределение Стьюдента с V=n-2.
Н0
отвергается, если t
> tкр,
найденного по таблице для данных
и V.
Для
n>3050
![]() (N
– нормальное распределение)
(N
– нормальное распределение)
![]()
![]()
Для того, чтобы вычислить меру зависимости между двумя переменными, исключая влияние остальных, используют частные коэффициенты корреляции, обозначаемые r12.3, r12.34 и т.п. Цифры перед точкой указывают, между какими переменными изучается зависимость, а цифры после точки -–влияние каких переменных исключается.
 ;
;
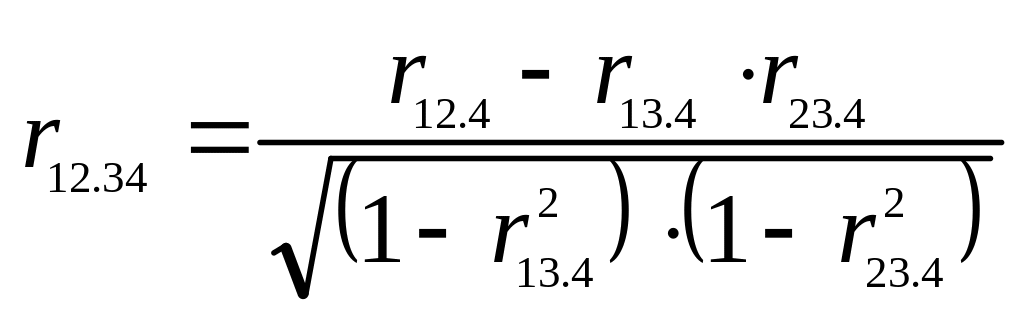 .
.
Проверка на значимость:
Проверим на значимость r12,3
Н0: r12,3=0 .
Статистика
критерия
, где
![]() (k-
количество переменных, n
– объем выборки).
(k-
количество переменных, n
– объем выборки).
Статистика имеет распределение Стьюдента с V=n-2. Н0 отвергается, если t>tкр, найденного по таблице для данных и V.
Для
выделения связи между одной из переменных
(выходной) и совокупностью других
(входных) используют множественный
коэффициент корреляции.
Для трех переменных: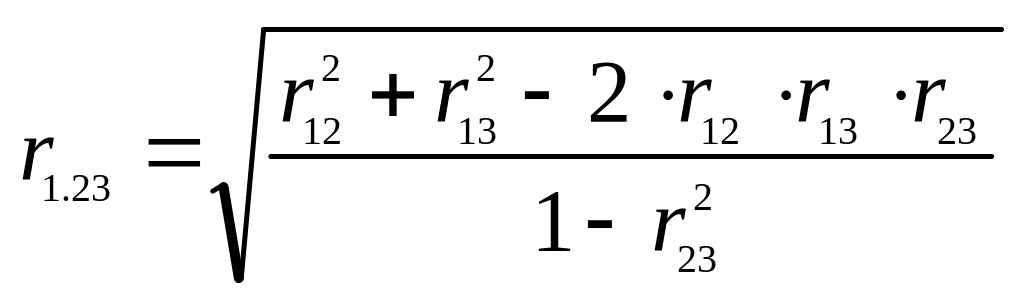 .
.
Проверка на значимость:
Н0: r1.(23…)=0 .
Статистика
критерия
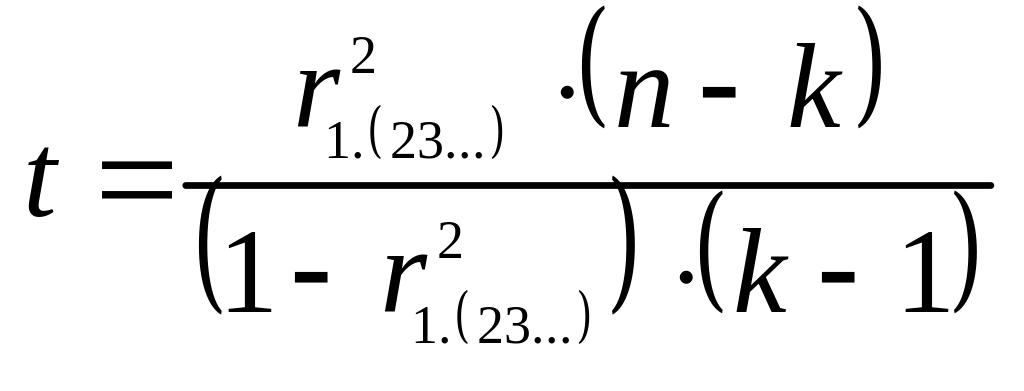 , где k
– количество переменных.
, где k
– количество переменных.
Статистика имеет распределение Фишера с V1=k-1, V2=n-k. Н0 отвергается, если t > tкр, найденного по таблице критерия Фишера для данных , V1 и V2.
Для определения взаимозависимости между переменными, имеюшими произвольное двумерное непрерывное распределение, можно пользоваться коэффициентом ранговой корреляции Спирмена. Ряды измерений xi и yi преобразуются с помощью рангов. Каждому значению xi ставится в соответствие ранг R1, т.е. номер элемента xi в вариационном ряду; аналогично определяютя ранги R’1 элементов yi. Таким образом, каждой паре (xi ,yi) соответствует пара рангов (R1, R’1). Коэффициент ранговой корреляции Спирмена вычисляется по формуле:
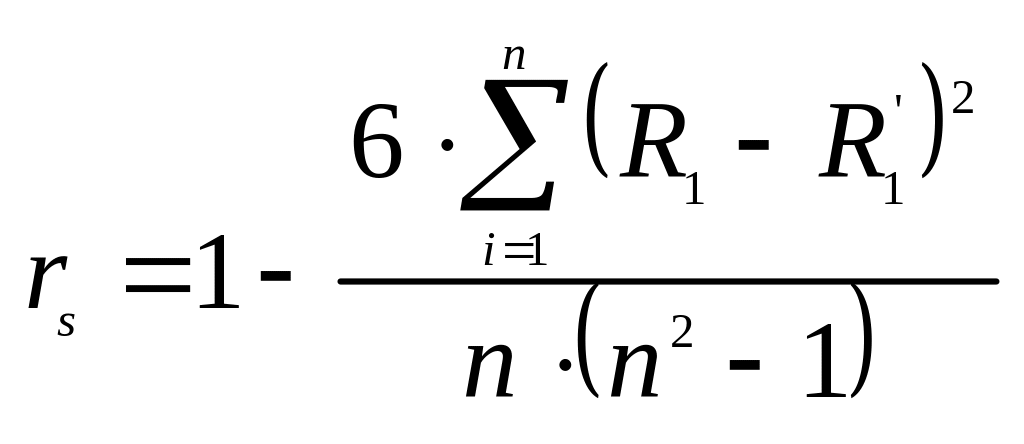 .
.
Проверка на значимость:
Н0: rs=0 .
Статистика
критерия
![]() .
.
При
n>30
статистика имеет приближенно стандартное
нормальное распределение N(0;1),
поэтому, если вычисленное значение
![]() ,
гипетеза Н0
отвергается. Если n<30,
то значимость определяется по специальным
таблицам.
,
гипетеза Н0
отвергается. Если n<30,
то значимость определяется по специальным
таблицам.
Доверительный
интервал при n>30:
![]()
46. Инвариантность и устойчивость в управлении. (Григорьев)
Инвариантность, в системах автоматического регулирования, независимость какой-либо системы от приложенных к ней внешних воздействий. Независимость одной из регулируемый координат системы от всех внешних воздействии или независимость всех координат от одного какого-либо воздействия называется полиинвариантностью. Часто условия И. не могут быть выполнены точно; в этом случае говорят об И. с точностью до некоторой наперёд заданной величины. Для реализуемости условий И. необходимо наличие в системе по меньшей мере двух каналов распространения воздействия между точкой приложения внешнего воздействия и координатой, И. которой должна быть обеспечена (принцип двухканальности Б. Н. Петрова). Идеи И. применяют в системах автоматического управления летательными аппаратами, судами, для управления химическими процессами при построении следящих систем и особенно комбинированных систем, в которых одновременно используются принципы регулирования по отклонению и по возмущению.
Одним из способов, позволяющих получить высокую точность в системах автоматического управления, является использование методов так называемой теории инвариантности [52]. Система является инвариантной по отношению к возмущающему воздействию, если после завершения переходного процесса, определяемого начальными условиями, управляемая величина и ошибка системы не зависят от этого воздействия. Система является инвариантной по отношению к задающему воздействию, если после завершения переходного процесса, определяемого начальными условиями, ошибка системы не зависят от этого воздействия.
Устойчивость системы автоматического управления, способность системы автоматического управления (САУ) нормально функционировать и противостоять различным неизбежным возмущениям (воздействиям). Состояние САУ называется устойчивым, если отклонение от него остаётся сколь угодно малым при любых достаточно малых изменениях входных сигналов. У. САУ разного типа определяется различными методами. Точная и строгая теория У. систем, описываемых обыкновенными дифференциальными уравнениями, создана А. М. Ляпуновым в 1892.
Все состояния линейной САУ либо устойчивы, либо неустойчивы, поэтому можно говорить об У. системы в целом. Для У. стационарной линейной СЛУ, описываемой обыкновенными дифференциальными уравнениями, необходимо и достаточно, чтобы все корни соответствующего характеристического уравнения имели отрицательные действительные части (тогда САУ асимптотически устойчива). Существуют различные критерии (условия), позволяющие судить о знаках корней характеристического уравнения, не решая это уравнение – непосредственно по его коэффициентам. При исследовании У. САУ, описываемых дифференциальными уравнениями невысокого порядка (до 4-го), пользуются критериями Рауса и Гурвица (Э. Раус, англ. механик; А. Гурвиц, нем. математик). Однако этими критериями пользоваться во многих случаях (например, в случае САУ, описываемых уравнениями высокого порядка) практически невозможно из-за необходимости проведения громоздких расчётов; кроме того, само нахождение характеристических уравнений сложных САУ сопряжено с трудоёмкими математическими выкладками. Между тем частотные характеристики любых сколь угодно сложных СЛУ легко находятся посредством простых графических и алгебраических операций. Поэтому при исследовании и проектировании линейных стационарных САУ обычно применяют частотные критерии Найквиста и Михайлова (Х. Найквист, амер. физик; А. В. Михайлов, сов. учёный в области автоматического управления). Особенно прост и удобен в практическом применении критерий Найквиста. Совокупность значений параметров САУ, при которых система устойчива, называется областью У. Близость САУ к границе области У. оценивается запасами У. по фазе и по амплитуде, которые определяют по амплитудно-фазовым характеристикам разомкнутой САУ. Современная теория линейных САУ даёт методы исследования У. систем с сосредоточенными и с распределёнными параметрами, непрерывных и дискретных (импульсных), стационарных и нестационарных.
Проблема У. нелинейных САУ имеет ряд существенных особенностей в сравнении с линейными. В зависимости от характера нелинейности в системе одни состояния могут быть устойчивыми, другие – неустойчивыми. В теории У. нелинейных систем говорят об У. данного состояния, а не системы как таковой. У. какого-либо состояния нелинейной САУ может сохраняться, если действующие возмущения достаточно малы, и нарушаться при больших возмущениях. Поэтому вводятся понятия У. в малом, большом и целом. Важное значение имеет понятие абсолютной У., т. е. У. САУ при произвольном ограниченном начальном возмущении и любой нелинейности системы (из определённого класса нелинейностей). Исследование У. нелинейных САУ оказывается довольно сложным даже при использовании ЭВМ. Для нахождения достаточных условий У. часто применяют метод функций Ляпунова. Достаточные частотные критерии абсолютной У. предложены рум. математиком В. М. Поповым и др. Наряду с точными методами исследования У. применяются приближённые методы, основанные на использовании описывающих функций, например методы гармонической или статистической линеаризации.
Устойчивость САУ при воздействии на неё случайных возмущений и помех изучается теорией У. стохастических систем.
Современная вычислительная техника позволяет решать многие проблемы У. линейных и нелинейных САУ различных классов как путём использования известных алгоритмов, так и на основе новых специфических алгоритмов, рассчитанных на возможности современных ЭВМ и вычислительных систем.
47. Проблема адекватности моделей . (Григорьев)
АДЕКВАТНОСТЬ МОДЕЛИ — соответствие модели моделируемому объекту или процессу. Адекватность — в какой-то мере условное понятие, так как полного соответствия модели реальному объекту быть не может, иначе это была бы не модель, а сам объект. При моделировании имеется в виду адекватность не вообще, а по тем свойствам модели, которые для исследования считаются существенными. Трудность измерения экономических величин осложняет проблему адекватности экономических моделей.
Адекватность — способность отражать нужные свойства объекта с погрешностью не выше допустимой;
Вместе с тем, создаваемая модель ориентирована, как правило, на исследование определенного подмножества свойств этого объекта. Поэтому можно считать, что адекватность модели определяется степенью ее соответствия не столько реальному объекту, сколько целям исследования. В наибольшей степени это утверждение справедливо относительно моделей проектируемых систем (то есть в ситуациях, когда реальная система вообще не существует).
Тем не менее, во многих случаях полезно иметь формальное подтверждение (или обоснование) адекватности разработанной модели. Один из наиболее распространенных способов такого обоснования — использование методов математической статистики. Суть этих методов заключается в проверке выдвинутой гипотезы (в данном случае — об адекватности модели) на основе некоторых статистических критериев.
При проверке гипотез методами математической статистики необходимо иметь в виду, что статистические критерии не могут доказать ни одной гипотезы — они могут лишь указать на отсутствие опровержения.
Итак, каким же образом можно оценить адекватность разработанной модели реально существующей системе?
Процедура оценки основана на сравнении измерений на реальной системе и результатов экспериментов на модели и может проводиться различными способами. Наиболее распространенные из них:
по средним значениям откликов модели и системы;
по дисперсиям отклонений откликов модели от среднего значения откликов системы;
по максимальному значению относительных отклонений откликов модели от откликов системы.
Названные способы оценки достаточно близки между собой по сути, поэтому ограничимся рассмотрением первого из них. При этом способе проверяется гипотеза о близости среднего значения наблюдаемой переменной Y среднему значению отклика реальной системы Y*.
В результате N0 опытов на реальной системе получают множество значений (выборку) Y*. Выполнив NM экспериментов на модели, также получают множество значений наблюдаемой переменной Y.
Затем вычисляются оценки математического ожидания и дисперсии откликов модели и системы, после чего выдвигается гипотеза о близости средних значений величин Y* и Y (в статистическом смысле). Основой для проверки гипотезы является t-статистика (распределение Стьюдента). Ее значение, вычисленное по результатам испытаний, сравнивается с критическим значением tКР взятым из справочной таблицы. Если выполняется неравенство tn<tKР, то гипотеза принимается. Необходимо еще раз подчеркнуть, что статистические методы применимы только в том случае, если оценивается адекватность модели существующей системе. На проектируемой системе провести измерения, естественно, не представляется возможным.
Единственный способ преодолеть это препятствие заключается в том, чтобы принять в качестве эталонного объекта концептуальную модель проектируемой системы. Тогда оценка адекватности программно реализованной модели заключается в проверке того, насколько корректно она отражает концептуальную модель. Данная проблема сходна с проверкой корректности любой компьютерной программы, и ее можно решать соответствующими методами, например с помощью тестирования.
Проблема адекватности моделей заключается в том, что, чем более эффективные решения можно предложить, тем в менее широком классе реальных систем их можно использовать – см. рисунок. Другими словами, вводя дополнительные предположения, можно повысить эффективность управленческих решений и облегчить решение задачи идентификации, но при этом сузится область их адекватности ("ширина охвата" – множество реальных систем, в которых решение, оптимальное в модели, также будет оптимальным).
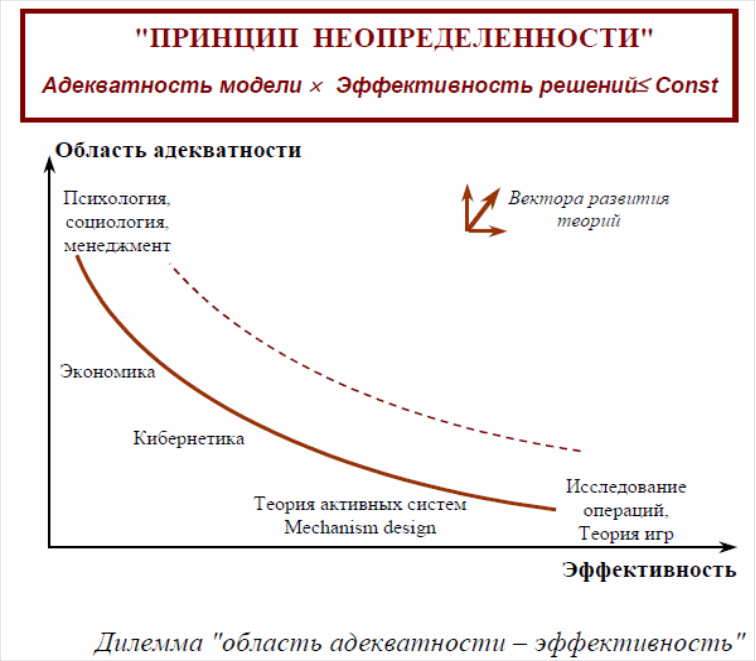
*