

Южно-Российский государственный технический университет
М.М.Гавриков, А.Н.Иванченко, Д.В.Гринченков
ОСНОВЫ КОНСТРУИРОВАНИЯ КОМПИЛЯТОРОВ
Учебное пособие
Новочеркасск 1997
ББК 32.97
Г 12
УДК 681.3.068(075.8)
Рецензенты: канд.техн.наук А.Г.Вольвич,
канд.техн.наук Н.Б.Тушканов
Гавриков М.М., Иванченко А.Н., Гринченков Д.В.
Г 12 Основы конструирования компиляторов: Учеб.пособие. Новочерк.гос.техн.ун-т. -Новочеркасск: НГТУ,1997.- 80с.
ISBN 5-88998-059-9
Содержание настоящего учебного пособия соответствует основным разделам программы одноименной дисциплины, преподаваемой на кафедре “Программное обеспечение вычислительной техники” в Новочеркасском государственном техническом университете.
Цель пособия состоит в решении трех задач: кратком, но систематическом изложении основных понятий и определений, составляющих теоретическую базу для проектирования компиляторов; уяснении студентами структуры и алгоритмов работы моделей используемых для построения основных частей трансляторов и компиляторов; освоении техники практического конструирования простых компиляторов на примерах ограниченного набора языковых конструкций.
Значительная часть материала настоящего пособия может использоваться в курсе “Лингвистическое обеспечение САПР” (и других программных систем) в приложении к вопросам разработки языковых процессоров-интерпретаторов, препроцессоров и др. Пособие предназначено для студентов, преподавателей, а также для разработчиков программного обеспечения.
2401010000-
Г
 Без объявл. УДК
681.3.068(075.8)
Без объявл. УДК
681.3.068(075.8)
98П(03)-97
ISBN 5-88998-059-9

ОГЛАВЛЕНИЕ
|
|
Предисловие |
|
ГЛАВА 1.ВВЕДЕНИЕ В ПРОБЛЕМАТИКУ КОНСТРУИРОВАНИЯ КОМПИЛЯТОРОВ |
|
1.1. Понятие компилятора и его структура |
|
1.2. Применение компиляторов и задачи их pазработки |
|
ГЛАВА 2. СПОСОБЫ ЗАДАНИЯ ФОРМАЛЬНЫХ ЯЗЫКОВ |
|
2.1. Математический аппарат теории формальных языков, перевода и компиляции |
|
2.2. Цепочки и языки |
|
2.3. Грамматики |
|
2.4. Распознаватели |
|
2.5. Регулярные выражения и синтаксические диаграммы |
|
2.6. Автоматы с магазинной памятью |
|
2.7. Соответствия между способами описания языков |
|
ГЛАВА 3. ОСНОВЫ ТЕОРИИ ПЕРЕВОДА |
|
3.1. Определение перевода |
|
3.2. Модели простейших трансляторов |
|
ГЛАВА 4. КОНСТРУИРОВАНИЕ СКАНЕРОВ |
|
4.1. Общая характеристика процесса сканирования |
|
4.2. Описание лексем в языке расширенных регулярных выражений |
|
4.3. Построение недетерминированного конечного автомата по расширенному регулярному выражению |
|
4.4. Преобразование недетерминированного конечного автомата в детерминированный |
|
4.5. Преобразование синтаксической диаграммы в конечный автомат |
|
4.6. Представление результатов сканирования |
|
4.7. Методики конструирования сканеров |
|
ГЛАВА 5. КОНСТРУИРОВАНИЕ ОДНОПРОХОДНЫХ НИСХОДЯЩИХ АНАЛИЗАТОРОВ |
|
5.1. Определение синтаксического разбора. |
|
5.2. Нисходящий и восходящий разборы |
|
5.3. LL(k) - грамматики |
|
5.4. Предсказывающие алгоритмы разбора |
|
5.5. Алгоритмы построения управляющих таблиц для левых анализаторов |
|
5.6. Приведение грамматик к LL - форме |
|
ГЛАВА 6. ОСНОВЫ ГЕНЕРАЦИИ КОДА |
|
6.1. Перевод и генерация кода |
|
6.2. Представления промежуточной программы |
|
6.3. Преобразование промежуточной программы в ассемблерный код |
|
Литература |
|
Предисловие
Содержание настоящего учебного пособия соответствует основным разделам программы одноименной дисциплины, преподаваемой на кафедре “Программное обеспечение вычислительной техники” в Новочеркасском государственном техническом университете. Материал пособия в значительной мере базируется на фундаментальной монографии американских ученых А.Ахо и Дж.Ульмана, посвященной теории и практике конструирования компиляторов. По нашему мнению, в методологическом отношении это наиболее подходящая книга для чтения университетского курса лекций.
Цель нашего небольшого по объему пособия мы видим в решении трех задач:
во-первых, в кратком, но систематическом изложении основных понятий и определений, составляющих теоретическую базу для проектирования компиляторов;
во-вторых, в уяснении студентами структуры и алгоритмов работы моделей (автоматов, преобразователей и их разновидностей), используемых для построения основных частей трансляторов и компиляторов;
в третьих, в освоении техники практического конструирования простых компиляторов на примерах ограниченного набора языковых конструкций - идентификаторов, выражений, операторов присваивания и т.п.
Получение навыков конструирования и реализации компиляторов не требует знания всех методов и алгоритмов, разработанных в теории, поэтому, излагая вопросы синтаксического анализа, мы ограничились рассмотрением методологии построения левых анализаторов, упомянув о правых анализаторах и соответствующих методах лишь в общих чертах. Кроме того, мы отказались от приведения теорем и доказательств, не имеющих непосредственного отношения к практическим вопросам, а технику преобразования грамматик и построения анализаторов для регулярных грамматик вынесли на практические занятия.
Пособие может использоваться для чтения одно- или двух-семестрового курса. В последнем случае предполагается, что большая часть материала усваивается студентами на лекционных и практических занятиях в первом семестре (первые четыре главы). Во втором семестре дочитывается оставшаяся часть, выполняются лабораторные и курсовые работы.
Значительная часть материала настоящего пособия может использоваться в курсе “Лингвистическое обеспечение САПР” (и других программных систем) в приложении к вопросам разработки языковых процессоров-интерпретаторов, препроцессоров и др. Мы надеемся, что пособие окажется полезным для студентов, преподавателей, а также для разработчиков программного обеспечения.
Глава 1 введение в проблематику конструирования компиляторов
1.1. Понятие компилятора и его структура
Любая прикладная программа, написанная на языке программирования высокого уровня или проблемно-ориентированном языке, должна быть переведена в эквивалентную программу на языке машинных команд. Эту эквивалентную программу называют объектной программой или объектным кодом.
Программа, которая переводит исходную программу в эквивалентную ей объектную программу, называется транслятором (поэтому термин "трансляция" эквивалентен термину "перевод").
Транслятор, выполняющий перевод программы с языка высокого уровня (Фортран, Паскаль, Си и др.) в объектную программу (в кодах Ассемблера и т.п.), называется компилятором. Например, процесс компиляции оператора Паскаля
S:=(a+b)*0.17

Рис. 1.1
На практике процесс компилирования исходной программы в объектную происходит в несколько этапов, называемых фазами компиляции.
Обычно выделяют три фазы:
- лексического анализа;
- фазу синтаксического и семантического анализов;
- фазу генерации кода.
Каждая фаза реализуются соответствующими частями компилятора (рис. 1.2):
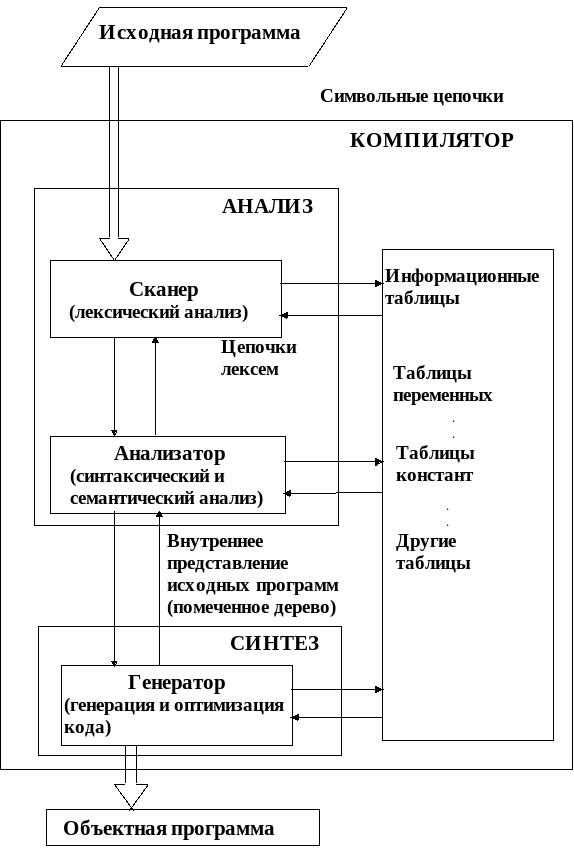
Рис.1.2
Лексический анализ реализуется частью компилятора, которая называется лексическим анализатором или сканером. Входом сканера является цепочка символов некоторого алфавита (текст исходной программы). С точки зрения смысла программы некоторые подцепочки этой входной цепочки представляют собой определенные объекты, которые должны рассматриваться как единое целое. Например: имена переменных, константы, зарезервированные слова и т.д. Такие цепочки принято называть лексемами. Задача сканера состоит в выделении лексем из входного текста. Так, после сканирования оператора S:=(a+b)*0.17 будет получена следующая цепочка лексем:
< переменная>1 :=( < переменная>2 + < переменная>3)*<константа>1
Кроме того, в результате работы сканера каждая лексема заменяется некоторым стандартным обозначением и ссылкой на таблицу, содержащую более подробные сведения о лексемах (мнемонические имена лексем, их типы и др.).
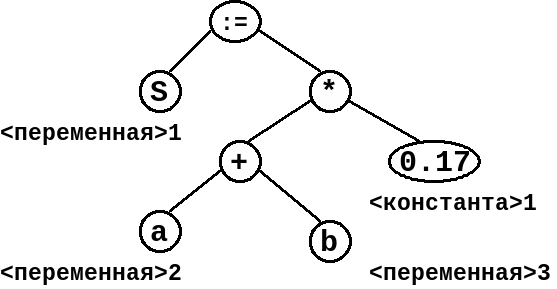
Рис.1.3
Синтаксическое дерево, закодированное и представленное в памяти ЭВМ тем или иным способом (например, в виде связной списочной структуры), называется промежуточной программой.
С фазой синтаксического анализа программы тесно связан ее семантический анализ. Если синтаксический анализ предназначен для распознавания и проверки правильности различных конструкций языка с точки зрения их синтаксиса (структуры), то семантический анализ предназначен для контроля этих конструкций с точки зрения их смыслового содержания. Так, если в программе встречается оператор присваивания, вида
<переменная>:=<выражение>,
то семантическая процедура проверяет переменную и выражение на соответствие типов. Обычно синтаксический и семантический анализаторы работают параллельно внутри одной фазы. Когда анализатор распознает в программе очередную языковую конструкцию, он вызывает соответствующую семантическую процедуру.
Фаза генерации кода предназначена для перевода промежуточной программы на машинный язык (мы будем предполагать коды Ассемблера). Алгоритмы генерации кода зависят от формы представления промежуточной программы, от набора команд используемого Ассемблера и других факторов. Так, если используется компилятор с языка Паскаль и соответствующий набор команд, то синтаксическое дерево, показанное на рис.1.3, может быть преобразовано в следующую последовательность команд:
LOAD =0.17 |
–загрузить в регистр константу 0.17, |
STORE S2 |
–запомнить содержимое регистра в ячейке S2, |
LOAD B |
–загрузить в регистр содержимое ячейки B, |
STORE S1 |
–запомнить содержимое регистра в ячейке S1, |
LOAD А |
–загрузить в регистр содержимое ячейки А, |
ADD S1 |
–сложить содержимое регистра с содержимым S1, |
MPY S2 |
–умножить содержимое регистра на содержимое S2, |
STORE S |
–запомнить содержимое регистра в ячейке S. |
Эта последовательность команд может быть оптимизирована за счет исключения команд запоминания промежуточных результатов в S1 и S2 и использования команды умножения непосредственно на число 0.17. После оптимизации будет получена следующая объектная программа:
LOAD A
ADD B
MPY =0.17
STORE S
Оптимизация может применяться как к промежуточной программе, так и к объектной – в процессе ее генерации или после получения неоптимальной версии.
Разбиение процесса компиляции на фазы скорее имеет методологическое значение, которое состоит в максимальном разделении функций компилятора. В реальных компиляторах эти функции выполняются как бы параллельно, т.е. сканер после распознавания очередной языковой конструкции вызывает необходимую процедуру анализатора, а тот, после завершения анализа, вызывает соответствующую процедуру генерации кода.
Рассмотренный "классический" вариант процесса компиляции
может иметь различные модификации. Мы остановимся на одной из разновидностей компиляторов - интерпретаторах.
Интерпретатор - это транслятор, который воспринимает исходную программу как входные данные и сам ее выполняет, не создавая объектной программы.
При программировании интерпретатор обычно разделяют на две фазы. Вначале интерпретатор анализирует исходную программу, почти так же, как это делает обычный компилятор, и транслирует ее в некоторое внутреннее представление(списковые структуры, таблицы и т.п.). Затем эта промежуточная программа интерпретируется или выполняется. В некоторых интерпретаторах при обработке исходной программы каждая ее инструкция транслируется во внутреннее представление и сразу выполняется(или предпринимается попытка выполнения), т.е. в памяти ЭВМ не создается целиком внутреннего представления всей программы.