

Глава 4 конструирование сканеров
4.1. Общая характеристика процесса сканирования
Лексический анализ ( или сканирование) образует первый этап процесса компиляции. На этом этапе символы, составляющие исходную программу, считываются и группируются в отдельные лексические элементы, называемые лексемами. Лексический анализ важен для процесса компиляции по следующим причинам:
- замена в программе идентификаторов и констант лексемами делает представление программы удобнее для дальнейшей обработки;
- уменьшается длина программы, т.к. из нее устраняются несущественные пробелы и комментарии.
С точки зрения реализации процесса сканирования различают два подхода - прямой и непрямой лексический анализ. При прямом лексическом анализе требуется найти одну из многих лексем, которые заданы в описании данного языка.
Моделью прямого лексического анализатора служит множество работающих параллельно конечных автоматов (КА), каждый из которых распознает лексемы заданного типа. Эти КА можно представить и реализовать как один конечный преобразователь, моделирующий работу всех КА и выдающий сигнал о том, какой из них распознал очередную лексему.
При непрямом лексическом анализе требуется, прочитав цепочку символов, определить, образует ли эта цепочка лексему некоторого конкретного типа. В этом случае сканер работает вместе с синтаксическим анализатором, как некоторая программная процедура SCAN (рис. 4.1)
Синтаксический анализатор обращается к SCAN всякий раз, когда ему нужен новый символ при анализе текста программы и построения ее внутреннего представления. В ответ на вызов, SCAN распознает очередную лексему в исходной программе и передает ее анализатору через таблицу лексем.
Непрямой сканер более экономичен ( в смысле экономии памяти), т.к. он не создает полной таблицы лексем для всего исходного текста программы.
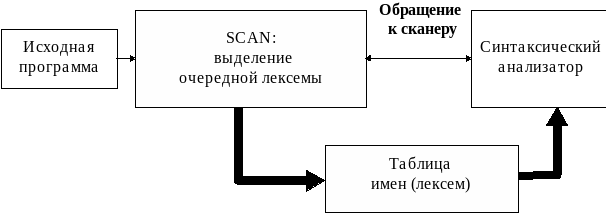
Рис.4.1
Большинство лексем в языках программирования могут быть описаны в виде регулярных выражений, а так же соответствующих регулярных грамматик. В п.2.7 мы говорили о соответствии между регулярными грамматиками и КА. Практическое значение этого соответствия состоит в том, что для распознавания лексем, описываемых регулярными выражениями, можно использовать соответствующие КА.
Распознавание лексем выполняется следующим образом:
- входная цепочка считывается до тех пор, пока КА не достигнет заключительного состояния;
- по достижению заключительного состояния КА сигнализирует о нахождению лексемы данного типа и сканер заносит информацию о ней в таблицу имен (символов).
Таким образом, проблему построения непрямого лексического анализатора для данного типа лексем можно представить как проблему построения и реализации КА, который по достижению заключительного состояния, выдает на выходе лексему ( в этом смысле его можно рассматривать и как конечный преобразователь). В общем случае, такой КА является недетерминированным (НКА), однако, как отмечалось в п.2.4 ,НКА можно преобразовать в эквивалентный ему детерминированный КА.
Рассмотрим способы описания лексем.