

S1 (Кафедра, Занятия)
011 - 016, 019, 021
012 - 017, 018
013 - 020, 022,
014 - 024,
015 - 023.
S2 (3анятия, Кафедра)
016 - 011,
017 - 012,
018 - 012,
019 - 011,
020 - 013,
021 - 011,
022 - 013,
023 - 015,
024 - 014,
Задание №3.
Даны следующие два основных файла БД:
Сотрудники |
|
Фамилия |
Должность |
01 Зимин А.В. |
слесарь |
02 Крюков В.И. |
механик |
03 Вощин С.И. |
механик |
04 Робот Г.В. |
слесарь |
05 Рыков Л.Т. |
мастер |
06 Бобов К.Ш. |
механик |
07 Быков П.И. |
слесарь |
Зарплата |
||
Фамилия |
Дата |
Зарплата |
08 Рыков Л.Т. |
14.01 |
1500 |
09 Крюков В.И. |
15.01 |
1000 |
10 Крюков В.И. |
14.01 |
2000 |
11 Зимин А.В. |
11.01 |
1500 |
12 Крюков В.И. |
13.01 |
1000 |
13 Зимин А.В. |
14.01 |
2000 |
14 Вощин С.И. |
12.01 |
2500 |
15 Робот Г.В. |
15.01 |
1400 |
16 Робот Г.В. |
13.01 |
1500 |
17 Бобов К.Ш. |
14.01 |
1000 |
18 Быков П.И. |
15.01 |
3000 |
Запишите инвертированные файлы для атрибутов Должность, Дата, Зарплата. Составьте списки связи S1 (Сотрудники, Зарплата) и S2 (3арплата, Сотрудники).
7. Алгоритмы обработки данных
Данные, которые поступают в ЭИС, обычно имеют неупорядоченный вид. Перед обработкой их желательно упорядочить по значениям ключевых атрибутов, что и представляет собой одну из функций формирования данных называемую сортировкой.
Для последовательного метода организации данных можно выделить два вида сортировки: по возрастанию, когда каждое последующее значение ключевого атрибута больше предыдущего и по убыванию, когда каждое последующее значение ключевого атрибута меньше предыдущего.
Сортировка обеспечивает эффективный поиск данных, помимо этого выходные документы, полученные на основе сортировки данных, удобны для использования человеком.
Задание №1.
Самостоятельно разработайте программы на языке программирования Паскаль, которые обеспечат сортировку данных в одномерном массиве по возрастанию и убыванию.
Поиском называется процедура выделения из некоторого множества записей определенного подмножества, записи которого удовлетворяют заранее заданному условию. Данное условие обычно называют запросом на поиск.
Рассмотрим, алгоритмы поиска в последовательном массиве по совпадению, т.е. когда значение ключевого атрибута должно равняться некоторому заданному значению. Наиболее распространенным алгоритмом является алгоритм ступенчатого поиска. Этот метод предполагает упорядоченность обрабатываемых записей.
Перед выполнением поиска массив исходных данных должен быть отсортирован по возрастанию значений ключевого атрибута. Искомое значение q сравнивается с ключом первой записи р(1), если значения не совпадают, то происходит сравнение с последующей записью и т.д. пока искомое значение не станет больше ключа очередной записи.
Данный алгоритм является очень простым, но время его работы непосредственно пропорционально числу записей в массиве. Поэтому при значительном увеличении числа записей время работы алгоритма также значительно увеличивается
Второй алгоритм называется алгоритмом двухступенчатого поиска. Сущность его заключается в том, поиск разбивается на две ступени. На первой ступени для заданного массива значений выбирается некоторая константа т, называемая шагом поиска. При этом значение ключевого атрибута q последовательно сравнивается с рядом следующих значений р(1), р(1+m), р(1+2m), р(1+3m) и т.д. То есть не по порядку а, например, через три значения или пять, в зависимости от шага. Сравнение осуществляется до тех пор, пока не будет достигнуто следующее неравенство
p(1 + k * m) > q
На второй ступени значение ключевого атрибута q последовательно сравнивается со всеми ключами, которые имеют номер l+k*m и меньше, до тех пор, пока в процессе сравнений не будет достигнут ключ, равный или меньший чем q.
Третий алгоритм представляет собой частный случай ступенчатого поиска, когда шаг поиска равен 2, Данный алгоритм, называется алгоритмом бинарного поиска. Сущность его заключается в том, что для поиска задается левая граница интервала поиска А и правая граница В. Первоначально интервал охватывает весь массив, т.е. А=0, B=N+1, где N - число записей в массиве. Вычисляется середина интервала i по формуле i=(A+B)/2 с округлением в меньшую сторону. Ключ средней записи p(i) сравнивается с искомым значением q. Если p(i)=q, то поиск заканчивается. В случае p(i)>q интервал поиска сокращается в два раза и правая граница принимается раной B=i. В случае p(i)<q левая граница принимается равной A=i. Далее середина интервала вычисляется заново, и все действия повторяются. Если будет достигнут нулевой интервал, то требуемой записи в массиве нет.
Задание №2.
Самостоятельно разработайте программы на языке программирования Паскаль, которые обеспечивают поиск данных в одномерном последовательном массиве по трем рассмотренным выше алгоритмам.
Корректировкой массива называется процедура включения или исключения отдельной записи данных. Кроме этого, в записи могут быть внесены изменения значения отдельных атрибутов.
Допустим, что нам надо добавить новую запись со значением ключевого атрибута равного А. Включение новой записи в последовательный упорядоченный массив не должно нарушать его упорядоченность. Поэтому сначала необходимо найти положение новой записи в массиве, т.е. выполнить поиск ключа новой записи А. Если значения А в массиве нет, то поиск остановиться там, где должна находится запись с данным ключом. Однако новая запись не может сразу занять место в массиве, необходимо выполнить пересылку записей, чтобы освободить это место. Пересылка начинается с последней записи, которая занимает следующую позицию, затем предпоследняя запись пересылается на место последней и т.д. В результате освобождается место для новой записи. Если требуется исключить запись из массива, то сначала также находится запись со значением ключевого атрибута А, а затем выполняется пересылка записей в направлении к началу массива для уничтожения исключаемой записи в памяти.
Задание №3.
Самостоятельно разработайте программу на языке программирования Паскаль, которая обеспечивает корректное добавление и удаление записей в одномерном упорядоченном массиве.
Цепным каталогом называется сплошной участок памяти или несколько таких участков, в котором одновременно размещаются список обрабатываемых записей и список свободных позиций памяти.
По аналогии с предыдущим методом организации данных адрес связи, отмечающий первую обрабатываемую запись, называется указателем списка. Адрес связи последней записи списка называется концом списка и отмечается нулевым значением.
Адрес связи, отмечающий первую свободную позицию памяти, называется указателем свободной памяти.
Ниже приведен пример организации цепного каталога со свободными участками памяти:
Номер записи |
Ключевой атрибут |
Адрес связи |
1 |
30 |
4 |
2 |
20 |
1 |
3 |
|
7 |
4 |
40 |
6 |
5 |
60 |
9 |
6 |
50 |
5 |
7 |
|
0 |
8 |
10 |
2 |
9 |
70 |
0 |
Рассмотрим для данного метода организации данных процедуру корректировки записей, так как она обладает рядом особенностей. Включение и исключение записей предполагает поиск местоположения добавляемой или удаляемой записи и замену значений адресов связи для установления новой последовательности записей основного списка и списка свободной памяти.
Предположим, что нам необходимо добавить запись со значением ключевого атрибута А. Приведем алгоритм данных действий:
Найти в каталоге запись с ключом, значение которого меньше, чем А, т.е. предшествующую запись.
Поместить запись с ключом А в первую позицию свободной памяти.
В предшествующей записи (т.е. записи со значением ключа меньше А) записать адрес связи новой вставленной записи.
В новой записи с ключом А записать адрес связи следующей записи.
Соответственно изменить адреса связей пустых записей.
Например, нам потребовалось вставить запись с ключевым значением 65 в приведенный выше цепной каталог. Находим запись с непосредственно меньшим ключом - это запись с номером 5. Далее помещаем запись в свободное место под номером 3. Меняем адрес связи в 5-ой записи на 3, а в новой 3-ей записи на 9:
Номер записи |
Ключевой атрибут |
Адрес связи |
1 |
30 |
4 |
2 |
20 |
1 |
3 |
|
7 |
4 |
40 |
6 |
5 |
60 |
9 |
6 |
50 |
5 |
7 |
|
0 |
8 |
10 |
2 |
9 |
70 |
0 |

Номер записи |
Ключевой атрибут |
Адрес связи |
1 |
30 |
4 |
2 |
20 |
1 |
3 |
65 |
9 |
4 |
40 |
6 |
5 |
60 |
3 |
6 |
50 |
5 |
7 |
|
0 |
8 |
10 |
2 |
9 |
70 |
0 |
Задание №4.
Дан цепной каталог следующего вида:
-
Номер записи
Ключевой атрибут
Адрес связи
1
112
5
2
144
3
3
155
6
4
11
5
125
2
6
176
9
7
190
12
8
188
7
9
184
8
10
222
0
11
0
12
201
10
Сначала удалите последовательно в этом каталоге запись 6, а затем 8. После этого добавьте в каталог значение 195. Запишите все получаемые цепные каталоги при выполнении данных операций.
Древовидной организацией данных называется множество записей, расположенных на нескольких уровней таким образом, что на первом уровне расположена только одна запись (корень дерева), а к любой из записей следующих уровней ведет адрес связи только от одной записи предшествующего уровня.
Количество уровней в дереве называется рангом. Совокупность записей, которые адресуются от общей записи предшествующего уровня, называется группой. Максимальное число элементов в группе называется порядком дерева.
Деревья, которые имеют порядок равный 2, называются бинарными. В бинарном дереве записи, у которых заполнены два адреса связи, называются полными, записи с одним заполненным адресом называются неполными. Сами адреса связи делятся на левые и правые.
Бинарные деревья характеризуются возможностью упорядочивания, записей. В упорядоченном бинарном дереве значение ключевого атрибута каждой записи больше, чем значение ключа у любой записи на ее левой ветви (включая все низшие уровни) и меньше, чем ключ любой записи на ее правой ветви.
На рисунке приведен пример бинарного дерева. Внутри показаны значения ключевого атрибута.
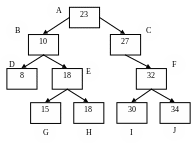
Рис. Бинарное дерево
Упорядоченное бинарное дерево формируется из неупорядоченного массива записей по следующему алгоритму.
Первая запись массива данных с ключом р(1) становится корнем дерева.
Значение ключа второй записи р(2) сравнивается с ключом р(1), находящимся в корне дерева. Если р(2)<р(1), то вторая запись помещается на левой от корня ветви, в противном случае - на правой ветви.
Далее выбирается следующая запись. Ключ этой записи сравнивается с корневым значением. Если р(1)>р(3), то происходит переход по левому адресу, а при р(1)<=р(3), то выполняется переход по правому адресу.
После перехода происходит сравнение ключей р(3) и р(2). В зависимости от результата сравнения снова организуется переход по левому или по правому адресу.
Затем выбирается следующая запись, и алгоритм повторяется до тех пор, пока не будут упорядочены все записи массива.
Задание №5.
Дан массив произвольных записей, ключевые атрибуты которых имеют следующие значения: 44, 13, 50, 35, 37, 40, 33, 55, 78, 90. Постройте по этим данным упорядоченное бинарное дерево.