Меры и единицы количества и объема информации
Единицы измерения информации служат для измерения объёма информации.
В простейшем случае чтобы отличить одно от других необходимо наличие двух информационных объектов. Причем сами такие объекты должны быть неделимыми, как атомы. В таком случае одному такому объекту можно ставить в соответствие, например, число, 0, а другому 1. Нельзя придумать иных элементарных отличий. К примеру, черно-белый объект может быть лишь в двух состояниях – черный или белый. Можно говорить о других бинарных состояниях объектов - включен/выключен, есть/нет. Такие состояния обладают минимальной информационной ёмкостью.
Для измерения количества информации необходима единица информации. За единицу количества информации приняли такое количество информации, при котором неопределённость уменьшается в два раза. Такая единица названа бит. Информационный объем сообщения - количество двоичных символов, используемое для кодирования этого сообщения. Информационная ёмкость одной ячейки памяти компьютера, способной находиться в двух различных состояниях, принята за единицу измерения количества информации - 1 бит.
Бит – это один двоичный разряд 1 или 0. Байт – 8 двоичных разрядов. 1 байт = 8 бит.
Каждое из 256 двоичных чисел
0000 0000
0000 0001
…………
1111 1111
имеет размер 1 байт.
С их помощью занумеровать и различать 256 различных объектов.
Производные единицы измерения информации и данных:
1 Кб (1 Килобайт) = 210 байт = 1024 байт
1 Мб (1 Мегабайт) = 220 байт = 1024 килобайт
1 Гб (1 Гигабайт) = 230 байт = 1024 мегабайт
1 Тб (1 Терабайт) = 240 байт = 1024 гигабайт.
1 Пб (1 Петабайт) = 250 байт = 1024 терабайт.
1 Эксабайт = 260 байт = 1024 петабайт.
1 Зеттабайт = 270 байт = 1024 эксабайт.
1 Йоттабайт = 280 байт = 1024 зеттабайт.
Кодирование данных Кодирование текстовых данных
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общеприменяемые специальные символы.
В таком случае всякий символ будет иметь информационный объем в 1 байт.
Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования символов.
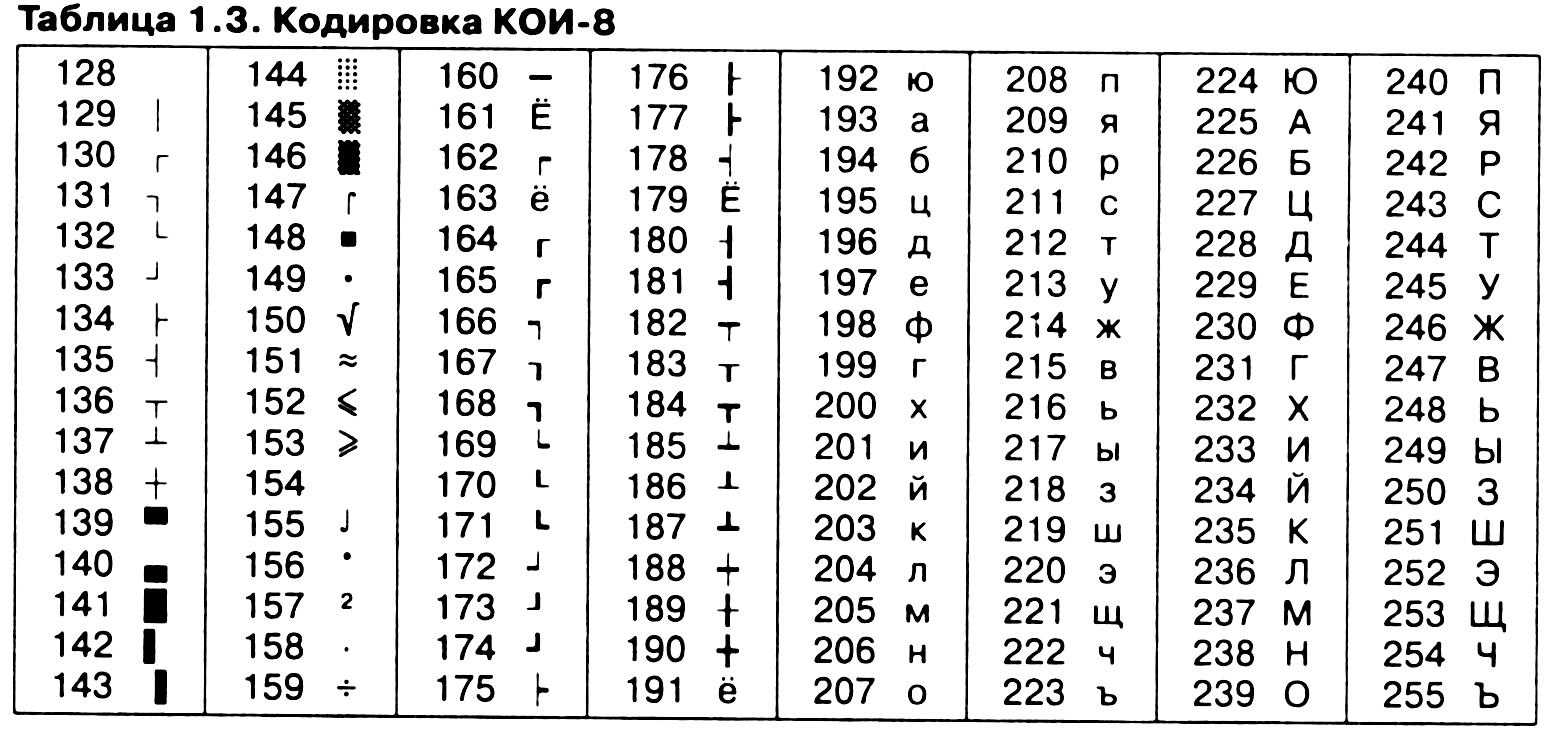
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI—American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования – базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 1.1.
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный).
Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
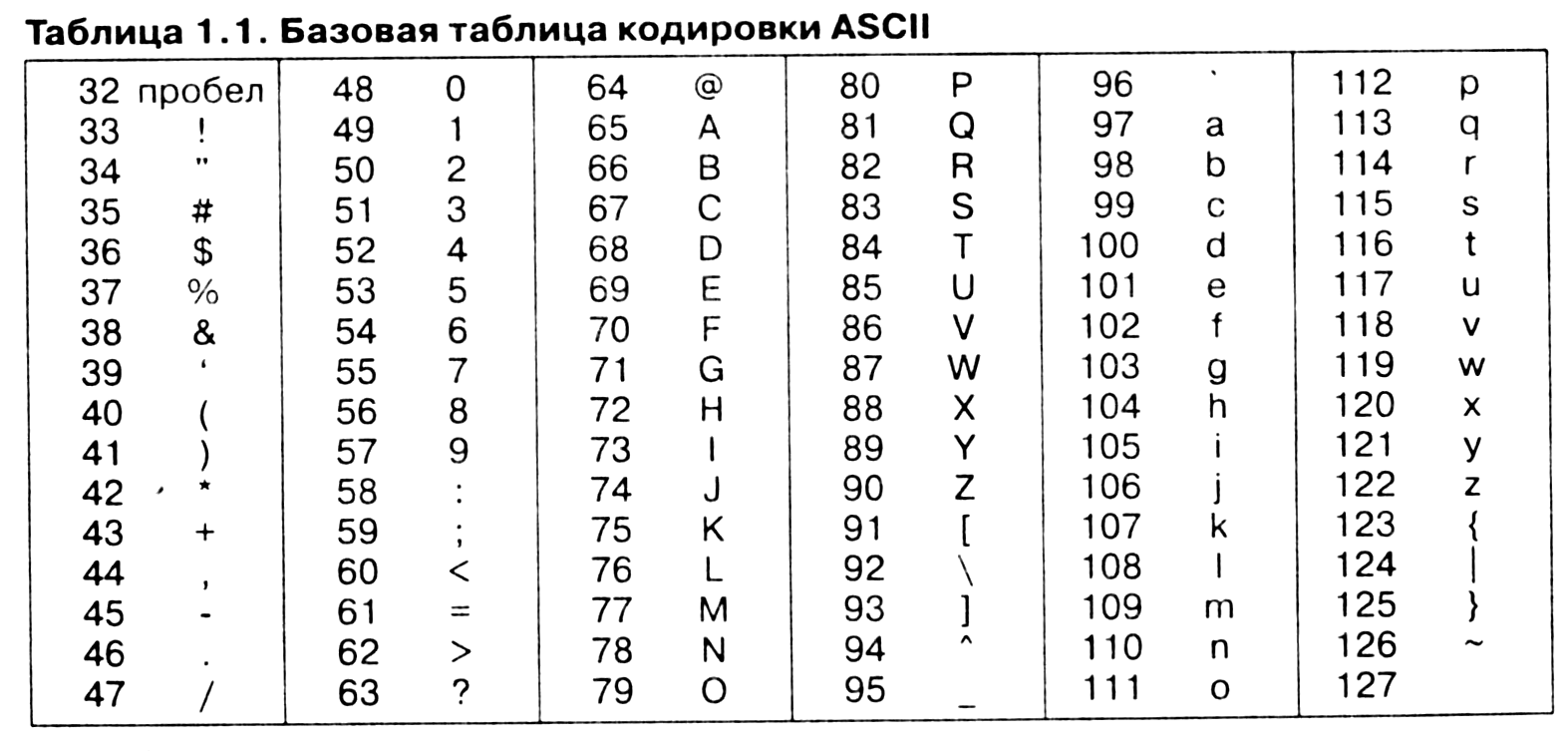
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
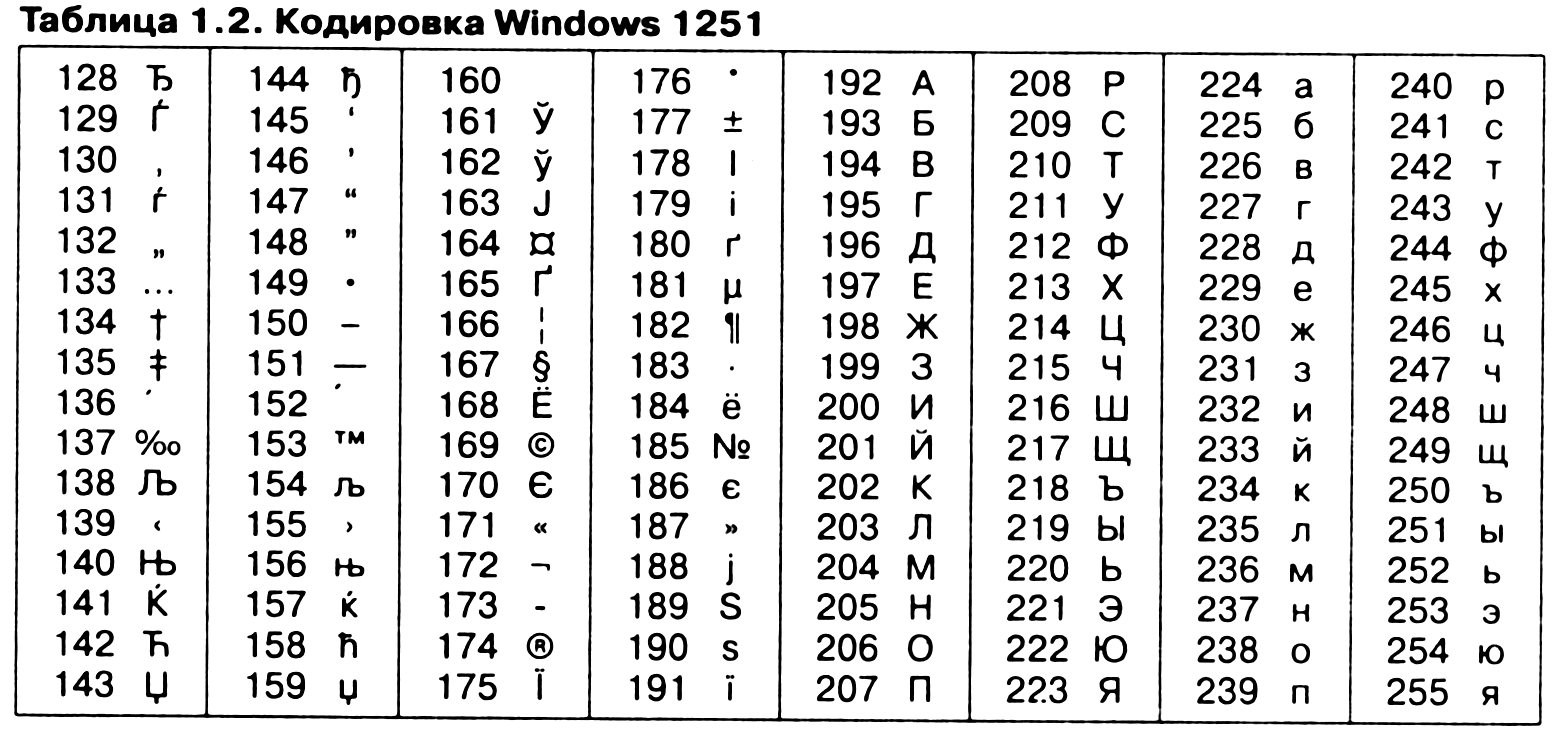
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный), таблица 1.3. Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.