

УМК по ТВ и МС
.pdfГлава 7. Основы выборочного метода
Вэтой главе рассмотрим вопросы построения оценок случайных величин по выборочным данным и показатели качества этих оценок.
7.1.Общие сведения о выборочном методе
Впрактике статистических наблюдений различают два вида наблюдений: сплошное, когда изучаются все объекты, и выборочное, когда изучается часть объектов. Вся подлежащая изучению совокупность объектов называется генеральной совокупностью.
Генеральная совокупность – весь мыслимый набор данных, описывающих какое-либо явление. Более строго: генеральная совокупность – это случайная
величина ξ(ω), заданная на пространстве элементарных событий Ω с выделенным в нем полем событий S, для которых указаны их вероятности P. Понятие генеральной совокупности в определенном смысле аналогично понятию случайной величины (закону распределения вероятностей).
Выборка из объема n (или просто выборка) – ограниченный набор n реально наблюдаемых выборочных из генеральной совокупности значений, описывающих исследуемое явление.
Конкретная выборка x1, … , xn – это конечная последовательность n чисел
– реализация случайной величины ξ(ω).
Случайная выборка объема n из генеральной совокупности (или выборка из распределения случайной величины ξ) – это последовательность X1, … , Xn независимых одинаково распределенных случайных величин, распределение каждой из которых совпадает с распределением случайной величины ξ(ω). Случайная выборка имеет распределение
FX1 ,..., X n |
(x1,..., xn ) = P{X1 < x1, ... , X n < xn }= ∏n |
P{Xi < xi }= ∏n |
FX i (xi ) . |
|
i =1 |
i =1 |
|
Суть выборочного метода состоит в том, чтобы по некоторой части генеральной совокупности (по выборке) делать выводы о ее свойствах в целом.
Преимущества выборочного метода наблюдения по сравнению со сплошным:
-существенно экономит затраты ресурсов;
-является единственно возможным в случае бесконечной генеральной совокупности;
-при тех же затратах ресурсов дает возможность проведения углубленного анализа за счет расширения программы исследования;
-позволяет снизить ошибки регистрации, т.е. расхождения между истинным
и зарегистрированным значениями признака.
Основной недостаток выборочного метода – ошибки репрезентативности.
Выборка называется репрезентативной (или представительной), если она достаточно хорошо воспроизводит генеральную совокупность.
Чтобы по данным выборки иметь возможность судить о генеральной совокупности, она должна быть отобрана случайно.
81
7.2.Вариационные ряды и их характеристики
7.2.1.Вариационные ряды и их графическое изображение
Различные значения признака (случайной величины ξ) называются вариантами, обозначим как x. Для того чтобы рассмотреть и проанализировать исходные данные, их необходимо каким-то образом представить. Основные формы представления выборки из генеральной совокупности следующие.
Представление выборки в несгруппированном виде x = (x1,..., xn ) . Представление выборки в упорядоченном виде x(1) ≤ x(2) ≤ ... ≤ x(n) . В этом
случае x(i) − i-й член вариационного ряда (или i-я порядковая статистика). Члены вариационного ряда, в отличие от элементов исходной выборки, уже не являются взаимно независимыми (из-за предварительной упорядоченности).
Представление выборки в группированном виде. Здесь область задания случайной величины ξ разбивается на L интервалов группировки. При этом известны только количество элементов выборки ni , (i =1,..., L) , попавших в i-й ин-
тервал, и последовательность границ интервалов разбиения. Область задания случайной величины ξ, как правило, ограничена минимумом и максимумом выборки. Согласно формуле Старджесса рекомендуемое число L интервалов
L=1 + [3,322lg n],
авеличина интервала равна h = (xmax − xmin ) L , где xmax − xmin − разность между наибольшим и наименьшим значениями признака. Иногда интервалы группи-
L , где xmax − xmin − разность между наибольшим и наименьшим значениями признака. Иногда интервалы группи-
ровки могут быть неравными. Это определяется условиями проведения эксперимента и природой исследуемого явления.
Числа, показывающие, сколько раз встречаются варианты из данного интервала, называются частотами ni , (i =1,..., L) , а отношения wi = ni / n − отно-
сительными частотами (или частостями).
Следует помнить, что от несгруппированной выборки всегда можно перейти к группированной, но не наоборот. Переход к группированной форме сопряжен с потерей информации об исследуемом явлении.
Определение 7.1. Вариационный ряд – это ранжированный в порядке возрастания или убывания ряд вариантов с соответствующими им частотами.
Вариационный ряд может быть дискретным или непрерывным. Вариационные ряды графически могут быть изображены в виде полигона, гистограммы и кумулятивной кривой.
Полигон служит для изображения, как правило, дискретного вариационного ряда и представляет собой ломанную, у которой концы отрезков имеют ко-
ординаты (xi , ni ), i =1,..., L .
Гистограмма используется только для изображения интервальных вариационных рядов и представляет собой ступенчатую фигуру из прямоугольников с основаниями, равными интервалам значений признака hi = xi+1 − xi , и высота-
82

ми, равными относительным частотам wi каждого из интервалов. Если соединить середины верхних оснований прямоугольников отрезками, то можно получить полигон того же распределения.
Кумулятивная кривая (кумулянта) – кривая накопленных частот (частостей). Для дискретного ряда кумулянта представляет собой ломанную, соединяющую точки (xi ,nis ) или (xi , wis ), i =1KL , где nis = ∑ij=1n j , wis = ∑ij=1 wj . Для интервального ряда ломаная начинается из точки, абсцисса которой равна началу первого интервала, а ордината – накопленной частоте (частости), равной нулю. Другие концы этой ломанной соответствуют концам интервалов.
Кхарактеристикам одномерного распределения частот относятся:
-меры положения, характеризующие среднее положение распределения;
-меры рассеяния, отражающие изменчивость распределения;
-меры формы, характеризующие отклонение распределения от нормального.
7.2.2. Средние величины
Средние величины характеризуют значения признака, вокруг которого концентрируются наблюдения. Наиболее распространенной из средних величин является средняя арифметическая.
Определение 7.2. Средняя арифметическая вариационного ряда – сумма произведений всех вариантов на соответствующие частоты, деленная на сумму частот:
|
∑L |
x j n j |
|
∑L |
x j n j |
|
|
x = |
j=1 |
|
= |
j=1 |
|
, |
|
∑Lj=1n j |
n |
||||||
|
|
|
|||||
где xi − варианты дискретного ряда или середины интервалов интервального вариационного ряда, ni − соответствующие им частоты.
Основные свойства средней арифметической аналогичны свойствам мате-
матического ожидания:
1.Средняя арифметическая константы равно этой константе, c = c .
2.cx = cx .
3.x +c = x +c .
4.Средняя арифметическая отклонений вариантов от средней арифметической
равна нулю: x − x = 0 .
5.Средняя арифметическая суммы признаков равно сумме средних арифметических этих признаков: x + y = x + y .
6.Общая средняя равна средней арифметической групповых средних, причем
весами являются объемы групп: x = |
∑Lj=1 x j n j |
, где |
x j |
− групповая средняя j-й |
|
n |
|||||
|
|
|
|
группы, объем которой равен nj, L − число групп.
83

Замечание 7.1. Можно показать, что средняя арифметическая – это оценка математического ожидания на основе метода наименьших квадратов.
При решении практических задач могут использоваться и иные формы средней, которые получаются из средней степенной k-го порядка:
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
∑L |
|
xkj n j |
|
|
|
|
|
x |
|
|
k |
, k Z, x |
|
>0 . |
||||
|
= |
j=1 |
|
|
|
|||||
|
(k ) |
|
|
n |
|
|
j |
|
||
|
|
|
|
|
|
|
|
|
|
|
Очевидно, что при k = 1 имеем формулу средней арифметической. При некоторых других значениях k получаем формулы:
k = −1: |
x(−1) = |
|
n |
|
|
|
− средняя гармоническая; |
|
|
L |
n |
j |
|
||||
|
|
|
∑ |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
j=1 x j |
|
|
|
||
|
x(0) = n |
|
L |
|
|
|
|
|
k =0 : |
∏xnj j |
|
|
− средняя геометрическая. |
||||
|
|
|
j=1 |
|
|
|
|
|
Рассмотренные выше средние величины называют аналитическими. Наряду с ними в статистике применяют структурные или порядковые средние, наиболее распространенными из которых являются медиана и мода.
Медианой вариационного ряда называется значение признака, приходящееся на середину упорядоченного по возрастанию ряда наблюдений. Если выборка состоит из (2N + 1) членов, то под медианой понимается (N + 1) -е по величине значение варианты. Если же выборка состоит из 2N членов, то медианой считают полусумму N-го и (N + 1)-го значений варианты.
Достоинство медианы как меры положения заключается в том, что на нее практически не влияют значения крайних членов вариационного ряда, особенно, когда они оказались чрезмерно большими по абсолютной величине в сравнении с остальными членами ряда.
Модой вариационного ряда называется вариант, которому соответствует наибольшая частота. Особенность моды как меры положения состоит в том, что она не изменяется при изменении членов ряда, отдаленных от центра ряда.
7.2.3. Показатели вариации и формы распределения
Средние величины не отражают изменчивости, степени рассеяния значений признака. Для оценки меры рассеяния используют показатели вариации.
Простейшей и весьма приближенной мерой рассеяния является вариационный размах R, равный разности между наибольшим и наименьшим вариантами
ряда: R = xmax − xmin .
Если выборка состоит только из двух значений, то вариационный размах является исчерпывающей характеристикой рассеяния. При увеличении объема выборки эта мера уже становится недостаточной, потому что учитывает только два крайних, экстремальных значения.
84

Разделим вариационный ряд девятью значениями на десять равных частей. Эти значения назовем децилями и обозначим DZ1,..., DZ9 . Мерой рассеяния
(которая, в противоположность вариационному размаху, почти не зависит от экстремальных значений и в то же время включает в себя 80% всего выборочного распределения и имеет очень малые колебания от выборки к выборке) яв-
ляется интердецильный размах, равный I80 = DZ9 − DZ1 .
Наибольший интерес представляют меры рассеяния наблюдений вокруг средних величин, в частности, вокруг средней арифметической.
Определение 7.3. Средним линейным отклонением вариационного ряда на-
зывается средняя арифметическая абсолютных величин отклонений вариантов
|
∑L |
|
x j |
− x |
|
n j |
|
|
|
|
|
||||
от их средней арифметической: d = |
j=1 |
|
|
|
|
|
. |
|
|
|
|
|
|||
|
|
n |
|
|
|
||
|
|
|
|
|
|
|
Определение 7.4. Дисперсией s2 вариационного ряда называется средняя арифметическая квадратов отклонений вариантов от их средней арифметиче-
ской: s |
2 |
= |
∑Lj=1 |
(x j − x)2 n j |
. |
|
|
|
n
В качестве меры рассеяния, наряду с выборочной дисперсией, используют
среднее квадратическое отклонение s, равное s =  s2 .
s2 .
Введенные выше меры рассеяния являются размерными величинами. Поэтому могут возникнуть трудности при их сравнении для выборок из разных генеральных совокупностей. Наиболее распространенной безразмерной меры
рассеяния является коэффициент вариации v, равный v = xs 100%, (x ≠ 0) .
Выборка является однородной, если v > 33 % . Коэффициент вариации особенно
пригоден для сравнения выборок из генеральных совокупностей одного типа, т.е. имеющих один и тот же тип закона распределения.
Начальный момент vk и центральный момент µk k-го порядка вариационного ряда определяются по формулам
vk = |
∑Lj=1 xkj |
n j |
, |
µk = |
∑Lj=1 |
(x j − x)k n j |
. |
n |
|
|
n |
||||
|
|
|
|
|
|
С помощью моментов распределения можно описать не только среднюю тенденцию и рассеяние, но и другие особенности вариации признака, в частности форму распределения. Как было указано в § 3.4, форму распределения характеризуют коэффициенты асимметрии и эксцесса. Данные коэффициенты определяют через центральные моменты.
Замечание 7.2. Средняя арифметическая, дисперсия и другие рассмотренные характеристики вариационного ряда являются статистическими аналогами
85
математического ожидания M [ξ] , дисперсии D[ξ] и соответствующих характеристик случайной величины ξ.
7.3. Понятие оценки параметров
Сформулируем задачу оценки параметров в общем виде. Пусть распределение признака ξ – генеральной совокупности – задается функцией вероятностей pξ (xi , θ) = P(ξ = xi ) (для дискретной случайной величины ξ) или плотно-
стью вероятности pξ (x,θ) (для непрерывной случайной величины ξ), которая
содержит неизвестный параметр θ. Например, это параметр λ для показательного распределения, a и σ2 для нормального распределения и т.д. Параметр θ является величиной неслучайной, детерминированной.
Для вычисления параметра θ исследовать всю генеральную совокупность не представляется возможным. Поэтому о параметре θ судят по выборке, состоящей из значений x1, … , xn. Эти значения можно рассматривать как частные значения n независимых случайных величин X1, … , Xn, каждая из которых имеет тот же закон распределения, что и сама случайная величина θ.
Определение 7.5. Оценкой θn параметра θ называют всякую функцию результатов наблюдений над случайной величиной ξ, с помощью которой судят о значении параметра θ: θn = θn (X1,..., X n ) .
Т.к. X1, … , Xn − случайные величины, то и оценка θn − случайная величи-
на, зависящая от закона распределения случайной величины θ и числа n. Всегда существует множество функций от результатов наблюдений
X1, … , Xn, которые будут оценками параметра θ. Возникает проблема – как измерить «близость» оценки θn к истинному значению θ, или как определить ка-
чество оценки? Качество оценки определяется не по одной конкретной выборке, а по всему мыслимому набору конкретных выборок, т.е. по случайной выборке. Поэтому для установления качества полученных оценок следует в соответствующих формулах заменить конкретные выборочные значения xi на случайные выборочные значения Xi.
Качество оценки устанавливают, проверяя, выполняются ли следующие три свойства: состоятельность, несмещенность и эффективность.
Определение 7.6. Оценка θn называется состоятельной, если она сходится по вероятности к истинному значению θ:
ε > 0 lim P( |
|
θn − θ |
|
< ε)=1, или |
) |
P |
(7.1) |
|
|
θn |
→ θ. |
||||
n→∞ |
|
|
|
|
|
n→∞ |
|
|
|
|
|
Свойство состоятельности является обязательным для оценки.
86

Определение 7.7. Оценка θn называется несмещенной, если ее математическое ожидание равно истинному значению θ:
M[θn ] = θ. |
(7.2) |
Данное свойство желательно, но не обязательно. Часто полученная оценка бывает смещенной, но ее можно скорректировать так, чтобы она стала несмещенной. Иногда оценка бывает смещенной, но асимптотически несмещенной,
что означает: lim M[θn ] = θ.
n→∞
Определение 7.8. Оценка θn называется эффективной в определенном
классе оценок Θ, если она самая точная среди всех оценок этого класса, т.е. имеет минимальную дисперсию:
D[θn ] = min) D[θn ] . |
(7.3) |
||
|
θn Θ |
|
|
Эффективность является решающим свойством, определяющим качество |
|||
оценки. Эффективность оценки θn определяется отношением: |
|
||
) |
D[θ ] |
|
|
e(θn ) = |
)n |
. |
(7.4) |
|
D[θn ] |
|
|
Чем ближе e к 1, тем эффективнее оценка. Если e →1 при |
n → ∞, то такая |
||
оценка называется асимптотически эффективной. На практике в целях упро-
щения расчетов часто делается компромисс между несмещенностью и эффективностью – используют незначительно смещеннные оценки или оценки, обла-
дающие большей дисперсией D[θn ] по сравнению с эффективными оценками.
Ниже рассмотрим, какими из свойств обладают некоторые полученные выше оценки числовых характеристик.
7.3.1. Среднее арифметическое выборочных значений как оценка математического ожидания
Пусть случайная величина ξ имеет математическое ожидание и дисперсию, равные соответственно a и σ2. Для случайной выборки оценка математического
) |
1 |
n |
|
|
|
|
P |
|
|
|
|
||||
ожидания примет вид: an = |
|
∑X i = X . Согласно следствию 5.1 |
X → a , что |
||||
|
|||||||
|
n i=1 |
|
|
n→∞ |
|||
означает состоятельность оценки a)n = X . Несмещенность оценки a)n устанавливается прямой проверкой:
) |
1 |
n |
|
|
1 |
n |
1 |
n |
|
M[an ] = M |
|
|
∑X i |
|
= |
|
∑M[X i ] = |
|
∑a = a . |
|
|
|
|
||||||
|
n − |
|
n = |
n = |
|||||
|
|
i 1 |
|
|
|
i 1 |
|
i 1 |
|
Теперь докажем, что a)n |
эффективна в классе линейных несмещенных оце- |
|
нок. Линейная оценка имеет вид |
||
a)n = ∑n |
ci X i . |
(7.5) |
i=1 |
|
|
Для линейной несмещенной оценки выполняется условие M [a)n ] = a , поэтому
87

) |
|
n |
|
n |
|
n |
|
M[an ] = M |
∑ci X i |
= ∑ci M[X i ] = a∑ci , |
|||||
|
|
i=1 |
|
i=1 |
|
i=1 |
|
т.е. для ее несмещенности необходимо ∑n |
c =1. Найдем дисперсию |
||||||
|
|
|
|
|
|
i =1 |
i |
D[a) |
|
n |
|
n |
|
n |
|
] = D ∑c X |
= ∑c2 D[X |
] = σ2 ∑c2 . |
|||||
n |
|
i |
i |
i |
i |
i=1 |
i |
|
i=1 |
|
i=1 |
|
|
||
Поэтому для определения наиболее эффективной в классе линейных несмещенных оценок надо минимизировать дисперсию D[an ] при выполнении усло-
вия несмещенности
(c ,K,c |
|
) = arg |
min |
n |
|
(7.6) |
||
n |
∑c2 . |
|
||||||
1 |
|
|
|
|
i |
|
|
|
|
|
|
|
|
∑in=1ci =1 i=1 |
|
|
|
Задача (7.6) – задача на условный экстремум, которая сводится к задаче на |
||||||||
безусловный экстремум. Строим для (7.6) функцию Лагранжа: |
||||||||
L(c ,K, c |
|
|
n |
n |
|
|
||
n |
, λ) = ∑c2 |
− λ ∑c |
i |
−1 . |
||||
1 |
|
|
|
i |
i=1 |
|
||
|
|
|
|
|
i=1 |
|
||
Для определения точки экстремума находим частные производные и приравниваем их к нулю:
∂L |
n |
|
|
|
∂L |
|
|
|
|
= ∑ c |
i |
−1 = 0 |
; |
= 2c |
i |
− λ = 0, i =1,...,n , |
|||
|
|
||||||||
∂λ |
i=1 |
|
|
∂ci |
|
||||
|
|
|
|
(i = 1,..., n) , полученные из первых n уравнений, |
|||||
Подставляя значения ci = λ/ 2, |
|
||||||||
в последнее уравнение, получаем λ2 = 1n ci = λ2 , i =1,..., n .
Итак, при ci = 1/ n, (i =1,...,n) , оценка (7.5) имеет минимальную дисперсию, т.е. a)n = X является эффективной в классе линейных несмещенных оценок.
7.3.2. Свойства оценки дисперсии
Для случайной выборки оценка дисперсии примет вид
)2 |
|
1 n |
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
σn = |
|
|
|
∑(X i − X ) |
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
(7.7) |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
n i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Изучение свойств этой оценки начнем с проверки на несмещенность. Рас- |
||||||||||||||||||||||||||
крыв квадрат под знаком суммы в уравнении (7.7), имеем: |
|
|
|
|
|
|
|
|
||||||||||||||||||
) |
2 |
|
|
|
1 n |
|
|
2 |
|
|
|
|
|
2 |
]). |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
M[σn ] = |
|
∑(M[X i ] − 2M[X i X ] + M[X |
|
|
|
|
|
|
|
(7.8) |
||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
n i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Далее найдем каждое из слагаемых в скобках под знаком суммы: |
|
|
|
|
|
|||||||||||||||||||||
M[Xi2 ] = D[Xi ] + (M[Xi ])2 = σ2 + a2 , |
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
n |
|
1 |
2 |
|
n |
|
= |
σ2 |
+ |
n −1 |
a |
2 |
. |
||||
|
|
|
|
|
|
|
|
|||||||||||||||||||
M[X i X ] = M X i |
|
|
∑ X j = |
M[X i ] + |
∑M[X i ]M[X j ] |
n |
n |
|
||||||||||||||||||
|
|
|
|
|
|
|
|
n j=1 |
|
n |
|
|
j=1 |
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
j≠i |
|
|
|
|
|
|
|
|
||
88

|
|
2 1 n |
1 n |
|
1 |
n |
2 |
|
|
|
|
|
|
|
|
||||||||
M[X ] = M ∑ X i |
∑ X j = |
|
|
|
|
|
|
= |
|||
|
2 |
|
|
||||||||
n |
∑M[X i |
] + ∑M[X i ]N[X j ] |
|||||||||
|
|
n i=1 |
n j=1 |
|
|
i=1 |
|
i≠ j |
|
|
|
=σ2 + (n −1) a2 . n n
Подставив найденные выражения в (7.8), получим
)2 |
= σ |
2 |
− |
σ2 |
+ |
a2 |
= |
n |
−1 |
σ |
2 |
+ |
a2 |
, |
|
σn |
|
n |
n |
|
n |
|
|
n |
|||||||
|
|
|
|
|
|
|
)2 |
|
|
2 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
откуда видно, что оценка σn |
имеет систематическое смещение (–σ /n). Без ог- |
||||||||||||||
раничения общности будем считать, что M [ X i ] = 0 , т.к. мы всегда можем от-
нять X от всех Xi. Отметим, что это смещение стремится к нулю при n → ∞ . С целью устранения смещения скорректируем оценку следующим образом:
|
2 |
|
|
n |
|
|
)2 |
|
1 |
|
|
|
n |
|
|
|
|
|
|
2 |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
s |
|
|
= |
|
|
|
|
σn |
= |
|
|
|
|
∑(X i |
− X ) |
|
. |
|
(7.9) |
||||||||
|
|
n − |
1 |
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
n −1 i=1 |
|
n |
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
)2 |
|
2 |
|
||||
Действительно, |
M [σ |
|
] = |
|
|
|
|
M [σn |
] = σ |
|
, т.е. скорректированная по формуле |
||||||||||||||||
|
n −1 |
|
|||||||||||||||||||||||||
(7.9) оценка не смещена. |
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
Предложение 7.1. При увеличении объема случайной выборки |
|||||||||||||||||||||||||||
|
|
|
|
1 |
|
|
n |
|
|
|
|
|
|
|
|
|
P |
|
|
|
|
|
|
|
|
||
s2 = |
|
|
∑(X i − |
|
)2 |
→ σ2 , |
|
|
|
|
|||||||||||||||||
|
|
X |
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
n −1 i=1 |
|
|
|
|
|
|
|
|
|
n→∞ |
|
|
|
|
|
|
|
||||||
т.е. оценка (7.9) является состоятельной. |
|
|
|||||||||||||||||||||||||
Доказательство. Без ограничения общности считаем, что M [ X i ] = 0 . При |
|||||||||||||||||||||||||||
этом предположении M [ X i2 ] = D[X i ] = σ2 . Из (7.9) вытекает, что |
|||||||||||||||||||||||||||
|
|
2 |
|
|
n |
|
|
1 |
n |
|
2 |
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
σ |
|
= |
|
|
|
|
|
|
∑ X i |
|
− X |
. |
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
n −1 n i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Применяя закон больших чисел в форме Хинчина (предложение 5.2) к последо-
|
|
|
|
1 |
n |
P |
|
|
|
вательности X12 |
,..., X n2 , имеем: |
∑ X i2 |
→ σ2 . |
|
|
|
|||
|
|
|
|
||||||
|
|
|
|
n i=1 |
n→∞ |
|
|
|
|
В силу предположения M [ X i ] = 0 |
|
|
|
P |
|||||
по закону больших чисел |
X |
→ 0 . Сле- |
|||||||
|
|
|
|
|
|
|
|
|
n→∞ |
|
|
|
P |
|
|
|
P |
||
довательно, |
X |
2 |
→ 0 . Отсюда вытекает, что s2 |
→ σ2 . |
|||||
|
|
|
n→∞ |
|
|
|
n→∞ |
||
7.3.3. Сравнение оценок
Предположим, что у нас имеются две несмещенные оценки θ'(X1,..., X n ) и θ''(X1,..., X n ) для скалярного параметра θ R . Возникает дилемма, какую из
оценок предпочесть? Простой и разумный совет состоит в том, чтобы выбрать оценку с меньшей дисперсией.
89
Пример 7.1. Предположим, что X1, … , Xn – независимая случайная выборка из равномерного распределения в отрезке [θ −1, θ +1], где θ – неизвестный
параметр. Рассмотрим две следующие оценки для θ:
θ'(X1,..., X n ) = X , θ''(X1,..., X n ) = (min X i + max X i ) 2 .
2 .
Нетрудно установить, что обе оценки являются несмещенными и D[θ'] =1/ 2n . Немного более сложное вычисление показывает, что D[θ''] = Ο(1/ n2 ) (n → ∞) .
Следовательно, при больших n дисперсия второй оценки стремится к нулю быстрее, чем дисперсия выборочного среднего. Другими словами, при достаточно большом объеме выборки оценка θ'' становится эффективней оценки θ' .
7.4. Оценка функций распределения и плотности
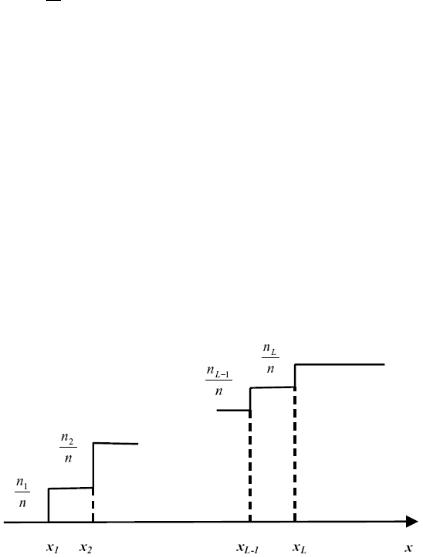
Оценку функции распределения вероятностей Fn(x) получаем по тому же принципу, который был применен при оценивании числовых характеристик: оценкой функции распределения генеральной случайной величины ξ служит функция распределения выборки x1, … , xn. На рис. 7.1 приведен пример эмпирической функции распределения.
Рис. 7.1.
Предложение 7.2. Выборочная функция распределения Fn(x) в каждой точке x, − ∞ < x < ∞, рассматриваемая как функция случайной выборки, схо-
дится по вероятности к теоретической функции распределения в этой точке:
P
Fn (x) → Fξ (x) . (7.10)
n→∞
Доказательство: Обозначим p = Fξ (x) = P{ξ < x}. Тогда случайная выбор-
ка X1 , … , Xn порождает схему Бернулли, на каждом шаге которой может произойти событие {Xi < x}, i = 1,…, n, или случиться противоположное {Xi ≥ x}, причем прямое событие на каждом шаге происходит с одинаковыми вероятностями p = P{Xi < x}, поскольку выборочные случайные величины Xi распределены как генеральная случайная величина ξ.
Тогда значение эмпирической функции распределения в любой точке x для конкретной выборки x1, … , xn является отношением числа положительных ис-
90