

7.2.2. Проверка гипотезы о наличии тренда
Для определения наличия тренда в исходном временном ряду применяется метод проверки разностей средних уровней. Реализация этого метода состоит из четырех этапов.
На
первом этапе исходный временной ряд
![]() разбивается на две примерно равные
по числу уровней части: в первой частиn1
первых уровней исходного ряда,
во второйn2
остальных уровней(n1
+ n2
= n).
разбивается на две примерно равные
по числу уровней части: в первой частиn1
первых уровней исходного ряда,
во второйn2
остальных уровней(n1
+ n2
= n).
На втором этапе для каждой из этих частей вычисляются средние значения и дисперсии:
 ;
;
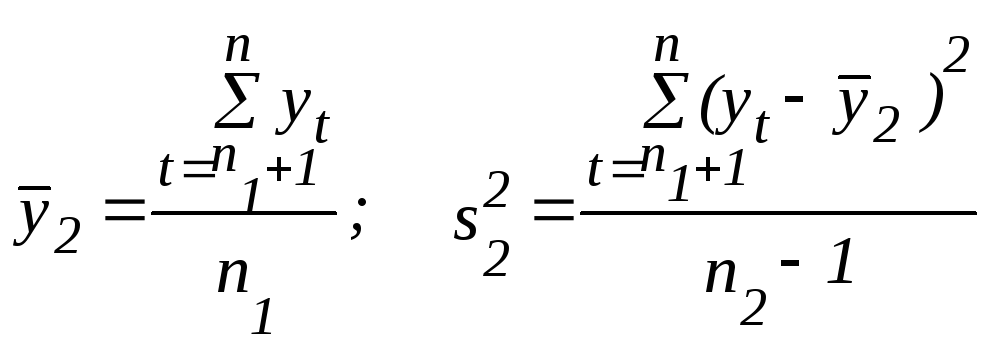 .
.
Третий этап заключается в проверке равенства (однородности) дисперсий обеих частей ряда с помощью F-критерия Фишера, которая основана на сравнении расчетного значения этого критерия:
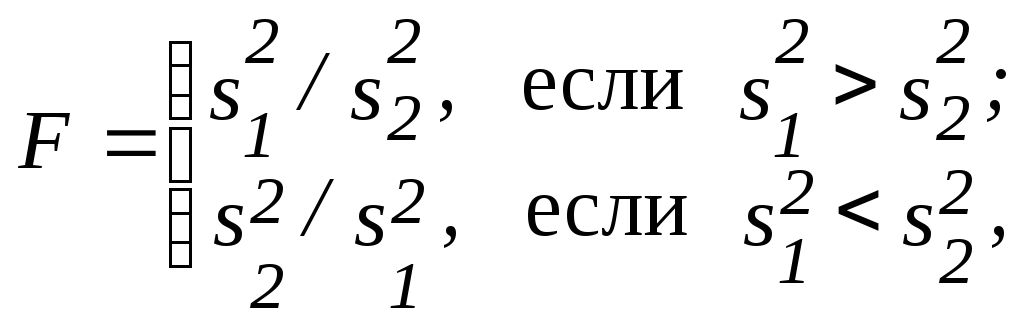
с табличным (критическим) значением критерия Фишера Fq с заданным уровнем значимости (уровнем ошибки) q. В качестве q чаще всего берут значения 0,1 (10 %-я ошибка), 0,05 (5 %-я ошибка), 0,01 (1 %-я ошибка). Величина Р = 1 – q называется доверительной вероятностью.
Если расчетное значение F меньше табличного Fq, то гипотеза о равенстве дисперсий принимается и переходят к четвертому этапу. Если F больше или равно Fq, гипотеза о равенстве дисперсий отклоняется и делается вывод, что данный метод для определения наличия тренда ответа не дает.
На четвертом этапе проверяется гипотеза об отсутствии тренда с использованием t-критерия Стьюдента.
Для этого определяется расчетное значение критерия Стьюдента по формуле
|
|
(7.2) |
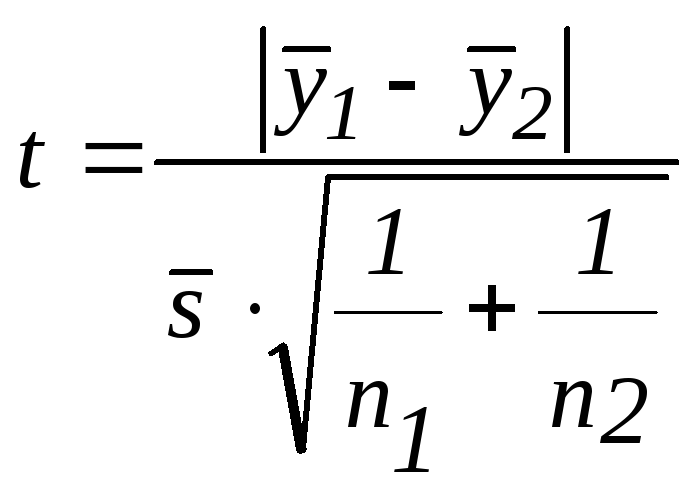 ,
,где – среднеквадратическое отклонение разности средних:
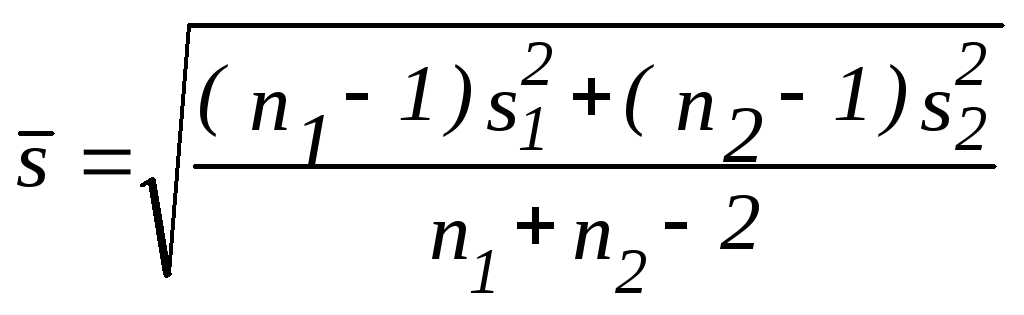 .
.
Если расчетное значение t меньше табличного значения статистики Стьюдента tq с заданным уровнем значимости q, гипотеза принимается, т.е. тренда нет, в противном случае тренд есть. Заметим, что в данном случае табличное значение tq берется для числа степеней свободы, равного n1 + n2 – 2, при этом данный метод применим только для рядов с монотонной тенденцией.
Пример 7.3. Требуется определить наличие тренда по данным временного ряда, описанного в примере 7.1. Результаты вычислений по формуле (7.2) представлены в табл.7.4.
Таблица 7.4. Результаты расчета к примеру 7.3
|
1-я выборка |
2-я выборка |
|
МО1 = 254,00 |
МО2 = 403,83 |
| ||
|
1 |
239 |
8 |
384 |
|
СКО1 = 50,91 |
СКО2 = 57,27 |
|
|
2 |
201 |
9 |
401 |
|
D1 = 2592,00 |
D2 = 3279,77 |
|
|
3 |
182 |
10 |
360 |
|
|
|
|
|
4 |
297 |
11 |
335 |
|
Среднее СКО двух выборок |
53,89 | |
|
5 |
324 |
12 |
462 |
|
t-критерий Стьюдента |
5,00 | |
|
6 |
278 |
13 |
481 |
|
Критическое значение критерия |
2,20 | |
|
7 |
257 |
|
|
|
|
| |
Вычисленное значение критерия (5,00)значительно превышает критическое(2,20),поэтому гипотезу о равенстве математических ожиданий двух выборок следует отвергнуть и согласиться с наличием тренда.
7.3. Сглаживание временного ряда
Рассмотрим
сглаживание временных рядов экономических
показателей. Очень часто уровни
экономических рядов динамики колеблются,
при этом тенденция развития экономического
явления во времени скрыта случайными
отклонениями уровней в ту или иную
сторону. С целью более четко выявить
тенденцию развития исследуемого
процесса, в том числе для дальнейшего
применения методов прогнозирования на
основе трендовых моделей, производят
сглаживание (выравнивание) временных
рядов. Таким образом, сглаживание можно
рассматривать как устранение случайной
составляющей tиз модели временного ряда:![]() .
.
Самым
простым методом механического сглаживания
является метод простой
скользящей средней.
Сначала для временного
ряда
![]() определяется интервал
сглаживания т (т <
п). Если необходимо
сгладить мелкие беспорядочные колебания,
то интервал сглаживания берут по
возможности большим; интервал сглаживания
уменьшают, если нужно сохранить более
мелкие колебания. При прочих равных
условиях интервал сглаживания
рекомендуется брать нечетным. Для первых
т уровней
временного ряда вычисляется их средняя
арифметическая; это будет сглаженное
значение уровня ряда, находящегося в
середине интервала сглаживания. Затем
интервал сглаживания сдвигается на
один уровень вправо, повторяется
вычисление средней арифметической и
т.д. Для вычисления сглаженных уровней
ряда
определяется интервал
сглаживания т (т <
п). Если необходимо
сгладить мелкие беспорядочные колебания,
то интервал сглаживания берут по
возможности большим; интервал сглаживания
уменьшают, если нужно сохранить более
мелкие колебания. При прочих равных
условиях интервал сглаживания
рекомендуется брать нечетным. Для первых
т уровней
временного ряда вычисляется их средняя
арифметическая; это будет сглаженное
значение уровня ряда, находящегося в
середине интервала сглаживания. Затем
интервал сглаживания сдвигается на
один уровень вправо, повторяется
вычисление средней арифметической и
т.д. Для вычисления сглаженных уровней
ряда
![]() применяется формула
применяется формула
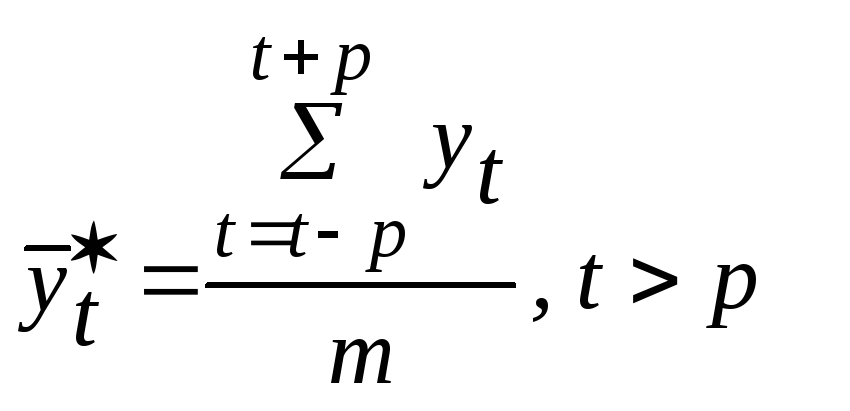 ,
,
где
![]() (при нечетномm);
для четных т формула
усложняется.
(при нечетномm);
для четных т формула
усложняется.
В результате такой процедуры получаются п–т+1 сглаженные значения уровней ряда; при этом первые р и последние р уровней ряда теряются (не сглаживаются).
Особенность
экспоненциального метода
сглаживания
заключается в том, что в процедуре
нахождения сглаживания уровня используются
значения только предшествующих уровней
ряда, взятые с определенным весом, причем
вес наблюдения уменьшается по мере
удаления его от момента времени, для
которого определяется сглаженное
значение уровня ряда. Если для исходного
временного ряда
![]() соответствующие сглаженные значения
уровней обозначить через St,
t = 1,2, …,n, то
экспоненциальное сглаживание
осуществляется по формуле
соответствующие сглаженные значения
уровней обозначить через St,
t = 1,2, …,n, то
экспоненциальное сглаживание
осуществляется по формуле
|
|
(7.3) |
где – параметр сглаживания (0 < < 1); величина 1– называется коэффициентом дисконтирования. Используя приведенное выше рекуррентное соотношение для всех уровней ряда, начиная с первого и кончая моментом времени t, можно получить, что экспоненциальная средняя, т.е. сглаженное данным методом значение уровня ряда, является взвешенной средней всех предшествующих уровней:
![]() ,
,
где S0 – величина, характеризующая начальные условия.
В практических задачах обработки временных рядов рекомендуется выбирать величину параметра сглаживания в интервале от 0,1 до 0,3.
Пример 7.4.Вернемся к примеру 7.1, в котором рассматриваются квартальные объемы продаж компанииLewplan. Мы уже выяснили, что этим данным отвечает аддитивная модель, т.е. фактически объемы продаж можно выразить следующим образом:
Y = U + V + E.
Для того чтобы элиминировать влияние сезонной компоненты, воспользуемся методом скользящей средней. Просуммировав первые четыре значения, получим общий объем продаж в 1998 г. Если поделить эту сумму на четыре, можно найти средний балл продаж в каждом квартале 1998 года, т.е.
(239 + 201 +182 + 297) /4 = 229,75.
Полученное значение уже не содержит сезонной компоненты, поскольку представляет собой среднюю величину за год. У нас появилась оценка значения тренда для середины года, т.е. для точки, лежащей в середине между кварталами 2 и 3. Если последовательно передвигаться вперед с интервалом в три месяца, можно рассчитать средние квартальные значения на промежутке апрель –март 1998 (251), июль – июнь 1998 (270,25) и т.д. Данная процедура позволяет генерировать скользящие средние по четырем точкам для исходного множества данных. Получаемое таким образом множество скользящих средних представляет наилучшую оценку искомого тренда.
Теперь полученные значения тренда можно использовать для нахождения оценок сезонной компоненты. Мы рассчитываем:
Y – U = V + E.
К сожалению, оценки значений тренда, полученные в результате расчета средних по четырем точкам, относятся к несколько иным моментам времени, чем фактические данные. Первая оценка, равная 229,75, представляет собой точку, совпадающую с серединой 1998 г., т.е. лежит в центре промежутка фактических значений объемов продаж во 2 и 3 кварталах. Вторая оценка, равная251, лежит между фактическими значениями в 3 и 4 кварталах. Нам же требуются десезонализированные средние значения, соответствующие тем же интервалам времени, что и фактические значения за квартал. Положение десезонализированных средних во времени сдвигается путем дальнейшего расчета средних для каждой пары значений. Найдем среднюю из первых оценок, центрируя их на июльсентябрь 1998 г., т.е.
(229,75 + 251)/2 = 240,4.
Это и есть десезонализированная средняя за июль сентябрь 1999 г. Эту десезонализированную величину, которая называется центрированной скользящей средней, можно непосредственно сравнивать с фактическим значением за июльсентябрь 1998 г., равным182. Отметим, что это означает отсутствие оценок тренда за первые два или последние два квартала временного ряда. Результаты этих расчетов приведены в табл. 7.5.
Таблица 7.5. Оценки скользящей средней и сезонной компоненты
|
Дата |
Объем продаж Y, тыс.шт. |
Итого за четыре квартала |
Скользящая cредняя за четыре квартала |
Центриро- ванная скользящая средняя U |
Оценка сезонной компоненты Y–U=V+E |
|
|
239 |
|
– |
|
|
|
Апрель-июнь |
201 |
|
– |
|
|
|
|
|
919 |
229,75 |
|
|
|
Июль-сентябрь |
182 |
|
|
240,4 |
–58,4 |
|
|
|
1004 |
251 |
|
|
|
Октябрь-декабрь |
297 |
|
|
260,6 |
+ 36,4 |
|
|
|
1081 |
270,25 |
|
|
|
Январь-март 1999 |
324 |
|
|
279,6 |
+ 44,4 |
|
|
|
1156 |
289 |
|
|
|
Апрель-июнь |
278 |
|
|
299,9 |
– 21,9 |
|
|
|
1243 |
310,5 |
|
|
|
Июль-сентябрь |
257 |
|
|
320,4 |
– 63,4 |
|
|
|
1320 |
330 |
|
|
|
Октябрь-декабрь |
384 |
|
|
340,3 |
+ 43,8 |
|
|
|
1402 |
350,5 |
|
|
|
Январь-март 2000 |
401 |
|
|
360,2 |
+ 40,8 |
|
|
|
1480 |
370 |
|
|
|
Апрель-июнь |
360 |
|
|
379,8 |
– 19,8 |
|
|
|
1558 |
389,5 |
|
|
|
Июль-сентябрь |
335 |
|
|
399,5 |
– 64,5 |
|
|
|
1638 |
409,5 |
|
|
|
Октябрь-декабрь |
462 |
|
– |
|
|
|
Январь-март 2001 |
481 |
|
– |
|
|
 Январь-март
1998
Январь-март
1998
Для каждого квартала мы имеем оценки сезонной компоненты, которые включают в себя ошибку или остаток. Прежде чем мы сможем использовать сезонную компоненту, нужно пройти два следующих этапа. Найдем средние значения сезонных оценок для каждого сезона года. Эта процедура позволит уменьшить некоторые значения ошибок. Наконец, скорректируем средние значения, увеличивая или уменьшая их на одно и то же число таким образом, чтобы общая их сумма была равна нулю. Это необходимо, чтобы усреднить значения сезонной компоненты в целом за год. Корректирующий фактор рассчитывается следующим образом: сумма оценок сезонных компонент делится на 4. В последнем столбце табл.7.5 эти оценки записаны под соответствующими квартальными значениями. Сама процедура приведена в табл.7.6.
Таблица 7.6. Расчетные значения сезонной компоненты
|
|
Год |
Номер квартала | ||||
|
1 |
2 |
3 |
4 | |||
|
|
1998 1999 2000 |
– + 44,4 + 40,8 |
– –21,9 –19,8 |
–58,4 –63,4 –64,5 |
+ 36,4 + 43,8 – | |
|
Итого |
|
+ 85,2 |
–41,7 |
–186,3 |
+80,2 | |
|
Среднее значение |
|
85,2/2 |
–41,7/2 |
–186,3/3 |
80,2/2 | |
|
Оценка сезонной компоненты |
|
42,6 |
–20,8 |
–62,1 |
+40,1 |
Сумма = –0,2 |
|
Скорректированная сезонная компонента1 |
|
+42,6 |
–20,7 |
–62,0 |
+40,1 |
Сумма = 0 |
Значение сезонной компоненты еще раз подтверждает наши выводы, сделанные в примере 7.1 на основе визуального анализа диаграммы. Объемы продаж за два зимних квартала превышают среднее трендовое значение приблизительно на 40 тыс. шт., а объемы продаж за два летних периода ниже средних на 21 и 62 тыс. шт. соответственно.
Аналогичная процедура применима при определении сезонной вариации за любой промежуток времени. Если, например, в качестве сезонов выступают дни недели, для элиминирования влияния ежедневной «сезонной компоненты» также рассчитывают скользящую среднюю, но уже не по четырем, а по семи точкам. Эта скользящая средняя представляет собой значение тренда в середине недели, т.е. в четверг; таким образом, необходимость в процедуре центрирования отпадает.
Десезонализация данных при расчете трендазаключается в вычитании соответствующих значений сезонной компонентыVиз фактических значений данных Y за каждый квартал, т.е Y – V = U + E, что показано в табл.7.7.
Таблица 7.7. Десезонализированные данные
|
Дата |
Номер квартала |
Объем продаж Y, тыс.шт. |
Сезонная компонента V |
Десезонализированный объем продаж Y–V=U+E, тыс.шт. |
|
Январь-март 1998 |
1 |
239 |
(+42,6) |
196,4 |
|
Апрель-июнь |
2 |
201 |
(–20,7) |
221,7 |
|
Июль-сентябрь |
3 |
182 |
(–62,0) |
244,0 |
|
Октябрь-декабрь |
4 |
297 |
(+40,1) |
256,9 |
|
|
|
|
|
|
|
Январь-март 1999 |
5 |
324 |
(+42,6) |
281,4 |
|
Апрель-июнь |
6 |
278 |
(–20,7) |
298,7 |
|
Июль-сентябрь |
7 |
257 |
(–62,0) |
319,0 |
|
Октябрь-декабрь |
8 |
384 |
(+40,1) |
343,9 |
|
|
|
|
|
|
|
Январь-март 2000 |
9 |
401 |
(+42,6) |
358,4 |
|
Апрель-июнь |
10 |
360 |
(–20,7) |
380,7 |
|
Июль-сентябрь |
11 |
335 |
(–62,0) |
397,0 |
|
Октябрь-декабрь |
12 |
462 |
(+40,1) |
421,9 |
|
|
|
|
|
|
|
Январь-март 2001 |
13 |
481 |
(+42,6) |
438,4 |
Новые оценки значений тренда, которые еще содержат ошибку, можно использовать для построения модели основного тренда. Если нанести эти значения на исходную диаграмму, можно сделать вывод о существовании явного линейного тренда (рис. 7.2).
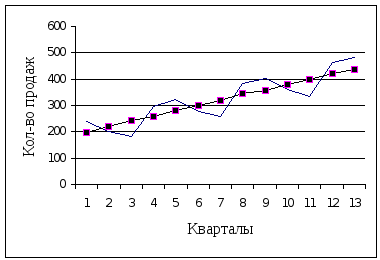
Рис. 7.2. График квартальных объемов продаж компании Lewplan:
 фактические
значения; десезонализированные
фактические
значения; десезонализированные