

Порядок выполнения практического занятия
Выполнение практического занятия состоит в решении студентами задач в режиме интерактивного взаимодействия с преподавателем и с коллегами по группе, с анализом полученных результатов. Каждый из вариантов заданий предполагает решение следующего набора задач:
1. Построить таблицы истинности для заданных булевых функций.
2. Реализовать их в базисе И-НЕ и ИЛИ-НЕ.
-
Вариант 1
Вариант 2


-
Вариант 3
Вариант 4


-
Вариант 5
Вариант 6


-
Вариант 7
Вариант 8


-
Вариант 9
Вариант 10

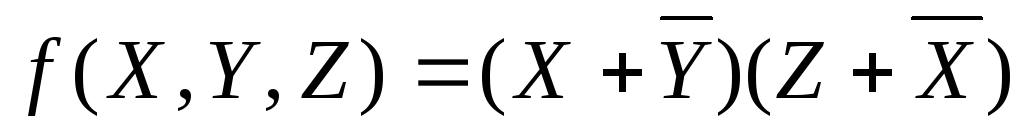
-
Вариант 11
Вариант 12


-
Вариант 13
Вариант 14


-
Вариант 15
Вариант 16


-
Вариант 17
Вариант 18

18.1)

-
Вариант 19
Вариант 20


-
Вариант 21
Вариант 22


-
Вариант 23
Вариант 24


Практическое занятие №5 Изучение примеров компактного кодирования данных в каналах связи
Цель занятия: практическое исследование простейших способов компактного кодирования (сжатия) цифровых данных.
Краткие теоретические сведения
Под сжатием данных понимается их представление, требующее минимального количества единиц информации (бит), необходимого для восстановления исходных данных с заданным уровнем их потерь (в ряде практических приложений – без потерь информации). Соответственно различают две основные группы методов сжатия:
- методы сжатия без потерь информации;
- методы сжатия с потерями информации.
Методы первой из перечисленных групп применяются для сжатия текстовой информации, технической документации (чертежей, диаграмм и т. п.), при передаче которых недопустимы никакие потери данных. Сжатие с потерями, в свою очередь, применяется при передаче мультимедийных данных, для которых допустимы незаметные или малозаметные для зрения и/или слуха искажения данных.
Основными методами сжатия без потерь информации являются вероятностные (энтропийные) и словарные а основными сжатия с потерями – спектральные и методы предсказания.
Вероятностные методы основываются на оптимальном неравномерном кодировании данных. Оно состоит в представлении символов сообщения двоичными словами, разрядность которых неодинакова от символа к символу и тем меньше, чем чаще встречается соответствующий символ в сообщении.
Словарные методы базируются на укрупнении алфавита сообщения, т. е. создании для каждого конкретного сообщения на этапе его сжатия собственного алфавита (словаря), который включает в себя не только стандартные символы (буквы, цифры и т. д.), но и ряд нестандартных, присваиваемых встречающимся в сообщении последовательностям стандартных символов.
Спектральные методы и методы предсказания применяются для компактного кодирования аудио- и видеоинформации и заключаются в представлении данных при сжатии их спектром или, соответственно, математической моделью, с восстановлением исходного массива данных при декодировании.
Настоящее практическое занятие посвящается наиболее простым для понимания и в то же время наиболее очевидно связанным с математическими основами теории информации вероятностным (энтропийным) методам сжатия.
По алгоритму формирования кодов символовразличают несколько методов, среди которых наиболее известными являютсяметод Шеннона – Фано иметод Хаффмана [1]. При этом каждый из них может основываться как на статических, так и на динамических способах расчета вероятностей появления символов.
Метод Шеннона – Фаноявляется наиболее простым, но в то же время самым неэффективным из вероятностных методов сжатия. Поэтому он в настоящее время на практике не применяется. Его описание приведено, например, в [1].
Метод Хаффмана получил наибольшее распространение на практике среди вероятностных методов. Известны два основных варианта данного метода. Первый основывается на кодировании символов сжимаемого сообщения без учета наличия памяти у его источника. Код символа при этом является функцией только от частоты его появления. Второй вариант известен под названием кодирования по Хаффману сМарковским прогнозированием. Он предполагает, что источник сообщения обладает памятью, причем на практике обычно ограничиваются гипотезой о 1-м порядке данной памяти. При этом код каждого из символов зависит от предшествовавшего ему символа и от вероятности появления после него; естественно, чем она выше, тем меньше разрядность кода. При таком варианте сжатия один и тот же символ сообщения может представляться различными кодами, что обусловливает некоторые специфические требования к организации процесса декодирования (которые будут рассмотрены далее). Первый из вышеназванных вариантов метода Хаффмана более прост в реализации, но второй обеспечивает значительно большую эффективность сжатия.
Простейший из алгоритмов реализации первоговарианта метода Хаффмана следующий (кодирование осуществляется, начиная смладшегобита).
1. Символы ранжируются в порядке убывания вероятности их появления.
2. Очередному биту символа, оказавшегося последним по результатам ранжирования, присваивается нулевое значение, а очередному биту символа оказавшегося предпоследним – единичное. Если вероятности появления этих двух символов одинаковы, очередному биту какого-либо из них присваивается нулевое значение, а другого - единичное.
3. Символы, являющиеся последним и предпоследним по результатам ранжирования, объединяются в один, вероятность появления которого принимается равной сумме вероятностей появления объединяемых символов. При этом присваиваемые на последующих этапах кодирования значения очередных бит кода будут одинаковы для обоих объединенных символов.
4. Если после объединения очередной пары символов их общее количество остается большим единицы – переход к пункту 1. Если нет – кодирование завершено.
Поясним этот алгоритм следующим примером. Пусть необходимо методом Хаффмана без Марковского прогнозирования осуществить кодирование символов сообщенияMEET ME. Алфавит данного сообщения состоит из четырех символов – М, Е, Т и пробела (“sp”), их общее число в сообщении равно семи. Вероятности появления символов указанного алфавита в сообщении следующие:
p(Е) = 3/70,43;
p(M) = 2/70,29;
p(T) = 1/70,14;
p(“sp”) = 1/70,14.
Кодирование будем осуществлять в соответствии с вышеприведенным алгоритмом. Процесс формирования кодов символов по этому алгоритму удобно изображать в виде направленного графа, называемого кодовым деревом.На рисунке 5.1 представлено кодовое дерево, описывающее решение рассматриваемой задачи, там же приведены результирующие коды символов. Правила построения кодового дерева нетрудно понять из данного рисунка.

sij–i–й по рангу символ наj–м этапе кодирования
Результирующие коды символов:
E– 0;M– 11;T– 100; «Пробел» - 101
Рис. 5.1.Кодовое дерево Хаффмана
Простейший алгоритм кодирования по Хаффману с Марковским прогнозированием 1-го порядка следующий.
1. Выявляется символ сжимаемого сообщения, отличающийся наибольшим разнообразием встречающихся после него символов, который обозначим хМ.
2. Все символы, встречающиеся после хМ, ранжируются в порядке убывания вероятностей р(хi/хМ). По результатам данного ранжирования, в соответствии с вышеприведенным алгоритмом первого варианта кодирования по Хаффману, формируются коды символов хiпри условии их следования после хМ, которые обозначимCd(хi/хМ).
3. Для каждого из хj (jM) осуществляется ранжирование следующих за ним символов в порядке убывания вероятностей р(хi/хj). По его результатам формируются кодыCd(хi/хj) в соответствии с правилом: код Cd(хi/хj) устанавливается идентичным кодуCd(хk/хМ) того из символов хk, ранг которого по вероятности следования после хМсовпадает с рангом символа хiпо вероятности следования после хj.
Рассмотрим пример реализации этого алгоритма. Пусть теперь необходимо осуществить кодирование символов сообщения из предыдущего примера методом Хаффмана с Марковским прогнозированием 1-го порядка. Кодирование реализуем в соответствии с простейшим алгоритмом сжатия по Хаффману с Марковским прогнозированием, представленным в теоретических сведениях по теме данного раздела. Выявляем символ сообщения, отличающийся наибольшим разнообразием символов, встречающихся после него. Таковым является буква «Е», после которой встречаются два типа символов, а именно буквы «Е» и «Т», причем вероятности р(Е/E) и р(Т/E) одинаковы и равны 0,5. Методом Хаффмана формируем кодыCd(E/E) иCd(T/E); принимаемCd(E/E) = 1,Cd(T/E) = 0. После остальных трех символов алфавита рассматриваемого сообщения, «М», «Т» и «Пробел», встречается только по одному типу символа – «Е», «Пробел» и «М» соответственно. Следовательно, ранги символов «Е», «Пробел» и «М» по вероятности их появления после символов «М», «Т» и «Пробел» соответственно совпадают с рангом как буквы «Е», так и буквы «Т» по вероятности их появления после буквы «Е». Поэтому кодамCd(Е/М),Cd(“sp”/Т) иCd(М/“sp”) могут быть присвоены значения, равные как 1, так и 0.
Несмотря на переменную разрядность символов, кодирование по Хаффману обеспечивает однозначнуюидентификацию приемником начала и конца каждого из них, даже при передаче символов без каких-либо пауз между ними (в этом нетрудно убедиться на вышеприведенных примерах). То же характерно и для других вероятностных методов сжатия.
Результатом кодирования сообщения методом Хаффмана является таблица кодов. При использовании первого из вышеприведенных алгоритмов эта таблица имеет только один входной параметр – стандартный код символа (например, егоASCII-код). При кодировании с Марковским прогнозированием 1-го порядка таких параметров два – стандартный код символа и стандартный код предшествовавшего ему символа. Выходным параметром таблицы в обоих случаях является нестандартный код соответствующего символа, сформированный методом Хаффмана. Нетрудно заметить, что в первом из данных случаев максимальное количество элементов таблицы равноn(гдеn– количество символов в алфавите сообщения), а во втором –n2.
Необходимо также остановиться на вопросах декодированиясообщений, сжатых методом Хаффмана. Для вышеописанных простейших алгоритмов характернанеоднозначность кодирования, которая вызвана произвольной установкой состояния очередного бита объединяемых символов при равных вероятностях их появления. Поэтому для корректного декодирования сжатого сообщения вместе с ним должна передаваться и полученная на этапе сжатия таблица кодов. Ввиду этого на практике применяются и усовершенствованные алгоритмы кодирования методом Хаффмана, обеспечивающие однозначное кодирование символов (при условии, что они принадлежат некоторому фиксированному и заранее известному алфавиту). Использование этих вариантов позволяет на приемной стороне однозначно восстановить (по частоте появления символов в сжатом сообщении) таблицу кодов, созданную на этапе сжатия, и, следовательно, исключить необходимость ее передачи. Указанные алгоритмы отличаются высокой сложностью, и их рассмотрение выходит за рамки данного пособия; их краткое описание приведено, например, в [1]. Следует также подчеркнуть, что при использовании алгоритмов кодирования с Марковским прогнозированием декодирование каждого очередного символа невозможно, если неизвестен предыдущий символ. Поэтому сообщения, сжатые с применением таких алгоритмов,обязательнодолжны начинаться с некоторого специально выделенного протоколом стартового символа, неизменного от сообщения к сообщению и “известного” декодеру по умолчанию.
Эффективность сжатия сообщений вероятностными методами с посимвольным кодированием (к которым относится и метод Хаффмана) обычно оценивается по выражению:
E=H(X) /BCP, (5.1)
где H(X) – априорная информационная энтропия источника сообщений;
ВСР– средняя разрядность символа сжатого сообщения.
При кодировании символов сообщения без учета наличия памяти у его источника ВСРопределяется следующим образом:
n
BCP=Bi*p(xi), (5.2)
i=1
где Bi – разрядностьi-го символа сообщения после его сжатия;
p(xi) – вероятность появленияi-го символа в сообщении.