

Понятие адаптивного тестирования и принципы его реализации
Под адаптивным тестовым контролем понимают компьютеризованную систему научно обоснованной проверки и оценки результатов обучения, обладающую высокой эффективностью за счет оптимизации процедур генерации, предъявления и оценки результатов выполнения адаптивных тестов. Эффективность контрольно-оценочных процедур повышается при использовании многошаговой стратегии отбора и предъявления заданий, основанной на алгоритмах с полной контекстной зависимостью, в которых очередной шаг совершается только после оценки результатов выполнения предыдущего шага. После выполнения испытуемым очередного задания каждый раз возникает потребность в принятии решения о подборе трудности следующего задания в зависимости от того, верным или неверным был предыдущий ответ. Алгоритм отбора и предъявления заданий строится по принципу обратной связи, когда при правильном ответе испытуемого очередное задание выбирается более трудным, а неверный ответ влечет за собой предъявление последующего более легкого задания, чем то, на которое испытуемым был дан неверный ответ. Также есть возможность задания дополнительных вопросов по темам, которые обучаемый знает не очень хорошо для более тонкого выяснения уровня знаний в данных областях. Таким образом, можно сказать, что адаптивная модель напоминает преподавателя на экзамене – если обучаемый отвечает на задаваемые вопросы уверенно и правильно, преподаватель достаточно быстро ставит ему положительную оценку. Если обучаемый начинает «плавать», то преподаватель задает ему дополнительные или наводящие вопросы того же уровня сложности или по той же теме. И, наконец, если обучаемый с самого начала отвечает плохо, оценку преподаватель тоже ставит достаточно быстро, но отрицательную.
Достоинства:
Позволяет более гибко и точно измерять знания обучаемых;
Позволяет измерять знания меньшим количеством заданий, чем в классической модели;
Выявляет темы, которые обучаемый знает плохо и позволяет задать по ним ряд дополнительных вопросов.
Недостатки:
Заранее неизвестно, сколько вопросов необходимо задать обучаемому, чтобы определить его уровень знаний. Если вопросов, заложенных в систему тестирования, оказывается недостаточно, можно прервать тестирование и оценивать результат по тому количеству вопросов, на которое ответил обучаемый;
Возможно применение только на ЭВМ.
Классические шкалы оценки знаний и Item Response Theory.
Классическая теория тестирования (Clasical Test Theory — CTT) изначально создана для интерпретации диагностических процедур. Эта теория создавалась под чисто прикладные задачи, поэтому некоторые предположения, используемые в основаниях этой теории, необходимо прояснить, тем более что в литературе эти основания почти не обсуждаются.
В классической теории тестирования предполагается явно:
1. Одномерность, т.е. процедура тест измеряет только одно качество, готовность или способность.
2. Репрезентативность, в рамках CTT понимаемая как независимость вероятности той или иной оценки от того, какая подгруппа из общей популяции будет выполнять тест.
3. Независимость заданий, т.е. задания не зависят друг от друга.
4. Независимость ответов испытуемых.
Обе упомянутых независимости понимаются как минимум в статистическом смысле.
Поскольку диагностические процедуры в большинстве случаев проводились в виде тестов, причём в большинстве тестов в форме закрытых или, реже, открытых вопросов, то результат каждого ответа предполагался измеримым в баллах по некоторой шкале.
Кроме явных предположений, в этой теории заложены некоторые неявные предположения. В частности, неявно предполагается:
— измеримость всех возможных ответов, т.е. существование эффективной процедуры получения ответа на любой поставленный вопрос,
— полнота ответов, т.е. получение ответов на все поставленные вопросы, из чего следует, что отказы от ответов во внимание не принимаются,
— равнозначимость всех вопросов и, следовательно, равные веса всех поступивших ответов,
— равенство дисперсий при использовании параллельных форм ответов,
— нормальное распределение ответов .
Как и в случае технических измерений, неявно предполагается, что любой результат измерений складывается из истинного значения и ошибки измерения, и ошибки измерения предполагаются аддитивными, что нужно для корректности перехода от сумм ошибок к одной интегральной ошибке, причём интегральная ошибка тоже предполагается нормально распределённой.
Насколько корректны эти допущения, обычно не обсуждается. Во всяком случае, самые серьёзные вопросы по поводу CTT связаны с обеспечением реальной независимости заданий. Не обсуждается также и вопрос о выборе оценочных шкал, в качестве исходного допущения предполагается, что «сырые баллы» уже получены.
Более тонкий вопрос связан с метрологическим смыслом категории «ошибка». В технических измерениях неявно предполагается, что ошибка и порождённая ею погрешность — свойство измерительной процедуры, и, следовательно, погрешность в принципе можно оценить и учесть по результатам поверки и калибровки. При измерениях эргатических элементов появляется ещё один источник ошибок — нестабильность самого измеряемого, возникающая вследствие действия различных факторов, к самым важным из которых можно отнести обучение, забывание, утомление и динамику функционального состояния. Поправки на эти факторы в метрологии не обсуждаются.
Для
получения итоговой оценки используются
различные вычислительные процедуры.
Чаще всего вычисляется средний балл по
обычной формуле среднего арифметического
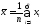 ,
где
,
где —
итоговый баллi-го
испытуемого, и квадрат отклонения от
среднего
—
итоговый баллi-го
испытуемого, и квадрат отклонения от
среднего
 или варианты этого показателя —
среднеквадратическое отклонение или
дисперсия. Для сравнения результатов
используется коэффициент корреляции
между заданиями и между испытуемыми.
или варианты этого показателя —
среднеквадратическое отклонение или
дисперсия. Для сравнения результатов
используется коэффициент корреляции
между заданиями и между испытуемыми.
Как
вариант, иногда используется взвешенный
средний балл вида
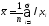 ,
где
,
где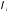 — соответствующие весовые коэффициенты.
— соответствующие весовые коэффициенты.
Из всех перечисленных выше предположений труднее всего доказывать равнозначимость ответов, поскольку это требует доказательств субъективного равенства всех трудностей соответствующих ответов и одновременно доказательств одинаковой важности всех поставленных вопросов. Предположение о вычислимости упомянутых статистических показателей требует содержательных доказательств корректности гомеоморфного вложения шкалы баллов в шкалу действительных чисел, в которой на самом деле выполняются подобные вычисления. Другими словами, вопросы как по критериальной, так и по конструктной валидности обычно остаются открытыми.
Кроме упомянутых стандартных статистических показателей (вопрос о математической корректности которых обычно не обсуждается) для испытуемых, оцениваются некоторые психометрические характеристики измерительных процедур с ясным прагматическим, но сомнительным математическим смыслом, например,
—
коэффициент
лёгкости задания
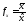 (или аналогичный коэффициент трудности
(или аналогичный коэффициент трудности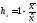 ),
где
),
где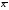 —
средняя оценка, полученная за задание
—
средняя оценка, полученная за задание ,
,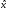 — максимально возможная оценка за это
же задание, при том, что минимальная
возможная оценка за любое задание по
умолчанию предполагается нулевой,
— максимально возможная оценка за это
же задание, при том, что минимальная
возможная оценка за любое задание по
умолчанию предполагается нулевой,
— коэффициент дискриминации задания, т. е. коэффициент корреляции между результатом задания и итоговым результатом, или считающийся более информативным вариант — коэффициент корреляции между результатом задания и итоговым результатом без учёта этого задания,
и некоторые другие коэффициенты, толкование которых в этой науке отличается от общепринятого.
В частности, надёжность здесь, в отличие от стандартного понимания, считается качеством не системы или объекта, а измерения, и оценивается не через время исправной работы или какие-либо варианты этого времени, например, в терминах наработки на отказ, а как возможность получения сопоставимых показателей, оцениваемых через коэффициент корреляции. Из такого толкования получаются последовательная надёжность, т. е. коэффициент корреляции между результатами выполнения двух заданий, расстояние по времени между которыми достаточно для того, чтобы эти задания можно было бы считать субъективно независимыми, параллельная надёжность, т.е. коэффициент корреляции между результатами вариантов заданий, надёжность частей, т.е. коэффициент корреляции между результатами всей процедуры измерений и какой-либо его части, и другие показатели. Другими словами, последовательной надёжностью в этой науке называют то, что в профессиональной теории измерений считают количественной мерой test-retest-валидности, параллельной надёжностью и надёжностью форм — мерой test-subtest-валидности, и в целом наблюдается путаница в терминологии, что приводит к смешиванию валидности и надёжности.
По
другой версии, коэффициент надёжности
определяется как
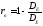 ,
где
,
где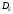 — дисперсия ошибок измерения,
— дисперсия ошибок измерения, —
дисперсия набранных баллов, т. е. время
в таком определении коэффициента
надёжности вообще не упоминается.
—
дисперсия набранных баллов, т. е. время
в таком определении коэффициента
надёжности вообще не упоминается.
Сомнительность подобных вычислений с математической точки зрения связана с тем, что исходные данные изначально получены по шкале баллов, на которой бывает задано отношение порядка, и даже линейного порядка, но не определены арифметические операции. Следовательно, сложение и вслед за ним вычисление средних, взвешенных средних, дисперсий и корреляций на шкале баллов не определено. Ещё одно предположение, понятное с прагматической точки зрения, но с явно неадекватным теоретическим обоснованием, сводится к утверждениям о нормальном распределении ответов и, следовательно, с распределением «сырых баллов» на шкале действительных чисел. Предположение о логнормальном распределении тех же баллов часто кажется более правдоподобным, но содержательно обычно тоже не обосновывается. Эти предположения позволяют использовать при статистической обработке результатов хорошо известные методы, но математическая корректность всех последующих вычислений после этого предположения не обсуждается.
В литературе широко обсуждаются многие проблемы традиционного подхода к построению шкал (метрик) знаний как баллов за выполнение некоторых специально подобранных наборов заданий.
Прежде всего, практически невозможно доказать test-to-test- и intertest-валидность, следовательно, вопрос о сравнении и тем более об общем учёте результатов измерений, выполненных по разным методам, остаётся открытым.
Многократно
отмечены «эффекты края», т. е. относительная
устойчивость результатов ближе к медиане
распределения ответов и неустойчивые
результаты по краям этого распределения,
что обычно объясняется возрастанием
роли инородных факторов как в «нижней»,
так и в «верхней» части распределения
. В качестве борьбы с этими эффектами
обычно предлагается эмпирически
обоснованная рекомендация задать
некоторый «доверительный квантиль»
распределения
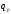 ,
обычно предлагается принять
,
обычно предлагается принять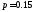 ,
,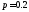 или
или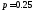 ,
и при попадании ответа ниже
,
и при попадании ответа ниже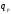 или выше
или выше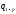 вносить поправки на нестабильность,
главным образом, завышать полученные
оценки по эмпирически подобранным
поправочным формулам.
вносить поправки на нестабильность,
главным образом, завышать полученные
оценки по эмпирически подобранным
поправочным формулам.
В
случае закрытых вопросов возможны
ситуации случайного угадывания, для
коррекции данных в этом случае предлагается
вносить поправки вида
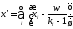 ,
где
,
где — результат после коррекции,
— результат после коррекции,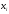 —
результат (в баллах или другим шкалам)
ответа на
—
результат (в баллах или другим шкалам)
ответа на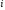 -й
вопрос до коррекции,
-й
вопрос до коррекции,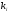 — количество возможных ответов на
— количество возможных ответов на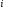 -й
вопрос,w
— количество невыполненных заданий в
серии измерений. Эта формула обосновывается
эмпирически, в частности, обсуждается
вопрос о целесообразности учёта в этой
формуле невыполненных заданий, для
которых соответствующее значение
-й
вопрос,w
— количество невыполненных заданий в
серии измерений. Эта формула обосновывается
эмпирически, в частности, обсуждается
вопрос о целесообразности учёта в этой
формуле невыполненных заданий, для
которых соответствующее значение
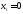 ,
что уменьшает значение
,
что уменьшает значение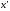 ,
и идут дискуссии о содержательном смысле
подобных поправок.
,
и идут дискуссии о содержательном смысле
подобных поправок.
В целом, метрики качества знаний при классическом подходе обоснованы статистической калибровкой методов по соответствующей популяции. Со времён создания IQ метрологическое обоснование измерений знаний проводится по распределениям баллов, вычисленных по соответствующему контингенту респондентов. Например, указываются средние значения IQ по возрастным, социальным или профессиональным группам. Однако из разницы IQ непонятно, какие принципиальные отличия в структуре знаний различают эти группы.