

Глава 4. Статистическая обработка данных
4.1. Справочный материал по статистической обработке данных
Пусть мы имеем
массив экспериментальных данных,
состоящий из пчисел![]() .
Можно считать, что эти числа являются
значениями некоторой случайной величины
Х.
.
Можно считать, что эти числа являются
значениями некоторой случайной величины
Х.
Множество всех возможных значений рассматриваемой случайной величины называют генеральной совокупностью, а множество опытных данных − выборочной совокупностью.
Цель статистической обработки данных состоит в том, чтобы по характеристикам выборочных совокупностей судить о свойствах генеральных совокупностей.
Величину М, определяемую по формуле:
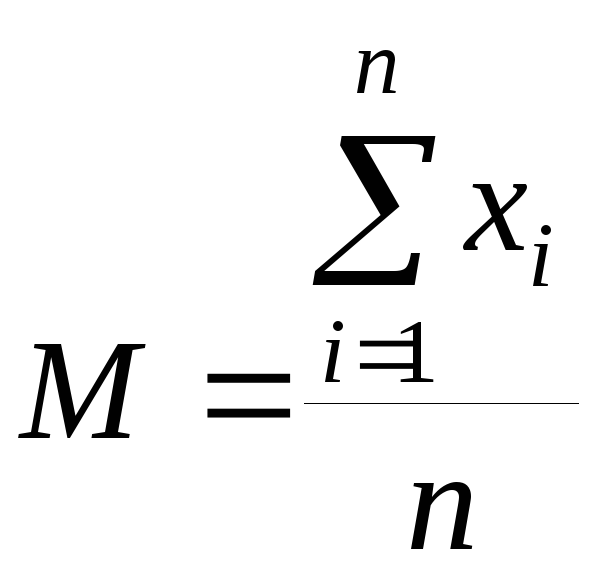 (4.1)
(4.1)
называют выборочным средним. Величина М даёт оценку математического ожидания (генеральной средней) случайной величины Х.
Оценку генеральной дисперсии даёт выборочная дисперсия. Она вычисляется по формуле:
 или
или
 .
(4.2)
.
(4.2)
Корень квадратный
из выборочной дисперсии называют
выборочным средним квадратическим
отклонением:
![]() .
.
Среднее квадратическое отклонение имеет ту же размерность, что и элементы исходного массива. Это не даёт возможности сравнивать между собой степень рассеяния (изменчивость) разнородных величин. Меру изменчивости, не зависящую от единиц измерения исходных величин, даёт коэффициент вариации С:
![]() .
.
Будем предполагать,
что в результате опыта мы имеем не только
массив данных
![]() , но и связанный с ним массив
, но и связанный с ним массив![]() .
.
Результаты такого
опыта можно рассматривать, как набор
экспериментальных точек, абсциссами
которых являются значения случайной
величины Х, а ординатами −
соответствующие им значения случайной
величиныУ:![]() .
.
Допустим, что у
нас есть основание предполагать, что
между переменными
![]() и
и![]() существует зависимость видаy=f(x).
существует зависимость видаy=f(x).
Выбор типа функции f(x)основывается на теоретических исследованиях и анализе взаимного расположения экспериментальных точек. Предполагаемая зависимость, как правило, не является строго функциональной. Поэтому при любом выборе параметров функцииf(x)вычисленные значенияf(xi)не совпадают с наблюдаемыми значениямиуi, т.е. разностьуi - f(xi)отлична от нуля.
Подберём параметры функции f(x)так, чтобы сумма квадратов была минимальна. Геометрически это означает, что мы хотим провести линию с уравнениемy=f(x)как можно "ближе" к имеющимся экспериментальным точкам. Предположим, что наша зависимость является линейной:
f(x)=ах + b.
Мы должны подобрать параметры а и bтак, чтобы минимизировать выражение:
![]() .
.
Для определения коэффициентов а и bнеобходимо решить систему уравнений
 .
.
После выполнения преобразований система примет вид:

Прямая
![]() называется линией регрессииунах, а коэффициентыа, b− коэффициентами регрессии.
называется линией регрессииунах, а коэффициентыа, b− коэффициентами регрессии.
Показателем, характеризующим тесноту линейной связи между хиу, является (выборочный) коэффициент корреляцииr:
 .
.
Коэффициент корреляции rи коэффициент регрессииасвязаны соотношением:
![]() ,
,
где
![]() – средние квадратические отклонения
рассматриваемых значенийХиУсоответственно.
– средние квадратические отклонения
рассматриваемых значенийХиУсоответственно.
Значение коэффициента
корреляции удовлетворяет соотношению:
![]() .
Чем меньше отличается
.
Чем меньше отличается![]() от 1, тем ближе к линии регрессии
располагается экспериментальные точки.
от 1, тем ближе к линии регрессии
располагается экспериментальные точки.
Если
![]() ,
то переменныех, уназываются
некоррелированными. Для того чтобы
проверить, значимо ли отличается от
нуля выборочный коэффициент корреляции,
можно воспользоваться критерием
Стьюдента.
,
то переменныех, уназываются
некоррелированными. Для того чтобы
проверить, значимо ли отличается от
нуля выборочный коэффициент корреляции,
можно воспользоваться критерием
Стьюдента.
Вычисленное значение критерия определяется по формуле:
 .
.
Вычисленное значение t сравнивается со значением из таблицы распределения Стьюдента в соответствии с уровнем значимостиαи числом степени свободып - 2. Если вычисленное значение больше табличного, то выборочный коэффициент корреляции значимо отличен от нуля.
Пример 4.1:
Результаты статистических испытаний представлены и таблице 4.1.
Таблица 4.1.
|
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
xi |
1,81 |
2,21 |
2,09 |
1,55 |
1,60 |
1,52 |
1,63 |
1,58 |
1,81 |
2,27 |
0,97 |
1,04 |
|
yi |
6,41 |
7,53 |
7,46 |
5,52 |
5,77 |
5,56 |
5,92 |
5,62 |
6,42 |
7,85 |
3,72 |
4,30 |
|
i |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
|
xi |
1,08 |
1,22 |
0,86 |
1,33 |
1,01 |
1,09 |
0,62 |
1,47 |
|
yi |
4,20 |
4,79 |
3,57 |
4,99 |
3,73 |
4,04 |
3,08 |
5,43 |
Для заданных значений хиуопределить:
![]() коэффициент
корреляции r, коэффициенты
регрессииунахи выяснить
значимость отличая от нуля коэффициента
корреляции.
коэффициент
корреляции r, коэффициенты
регрессииунахи выяснить
значимость отличая от нуля коэффициента
корреляции.
Вычисляем:
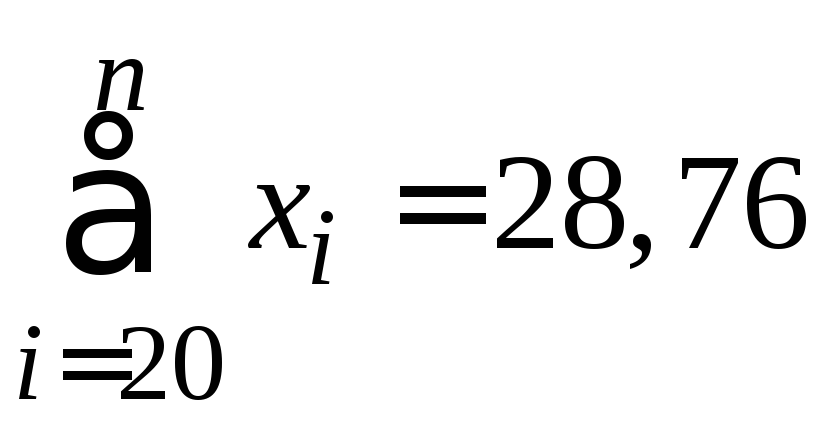 ,
,
 ,
, ,
,
 .
.
![]() ,
,
 ,
,![]() ,
,
![]() .
.
![]() ,
,
 ,
,![]() ,
,![]() 26,23.
26,23.
 b=5,30
- 3,03 ·1,44 = 0,937
b=5,30
- 3,03 ·1,44 = 0,937
![]() .
.
Вычисленное значение критерия Стьюдента равно:
![]() .
.
Значение критерия, взятое из таблицы при уровне значимости 0,05 равно 2,1. Таким образом, коэффициент корреляции значимо отличается от нуля.