

- •Contents
- •Introduction
- •Who This Book Is For
- •What This Book Covers
- •How This Book Is Structured
- •What You Need to Use This Book
- •Conventions
- •Source Code
- •Errata
- •p2p.wrox.com
- •The Basics of C++
- •The Obligatory Hello, World
- •Namespaces
- •Variables
- •Operators
- •Types
- •Conditionals
- •Loops
- •Arrays
- •Functions
- •Those Are the Basics
- •Diving Deeper into C++
- •Pointers and Dynamic Memory
- •Strings in C++
- •References
- •Exceptions
- •The Many Uses of const
- •C++ as an Object-Oriented Language
- •Declaring a Class
- •Your First Useful C++ Program
- •An Employee Records System
- •The Employee Class
- •The Database Class
- •The User Interface
- •Evaluating the Program
- •What Is Programming Design?
- •The Importance of Programming Design
- •Two Rules for C++ Design
- •Abstraction
- •Reuse
- •Designing a Chess Program
- •Requirements
- •Design Steps
- •An Object-Oriented View of the World
- •Am I Thinking Procedurally?
- •The Object-Oriented Philosophy
- •Living in a World of Objects
- •Object Relationships
- •Abstraction
- •Reusing Code
- •A Note on Terminology
- •Deciding Whether or Not to Reuse Code
- •Strategies for Reusing Code
- •Bundling Third-Party Applications
- •Open-Source Libraries
- •The C++ Standard Library
- •Designing with Patterns and Techniques
- •Design Techniques
- •Design Patterns
- •The Reuse Philosophy
- •How to Design Reusable Code
- •Use Abstraction
- •Structure Your Code for Optimal Reuse
- •Design Usable Interfaces
- •Reconciling Generality and Ease of Use
- •The Need for Process
- •Software Life-Cycle Models
- •The Stagewise and Waterfall Models
- •The Spiral Method
- •The Rational Unified Process
- •Software-Engineering Methodologies
- •Extreme Programming (XP)
- •Software Triage
- •Be Open to New Ideas
- •Bring New Ideas to the Table
- •Thinking Ahead
- •Keeping It Clear
- •Elements of Good Style
- •Documenting Your Code
- •Reasons to Write Comments
- •Commenting Styles
- •Comments in This Book
- •Decomposition
- •Decomposition through Refactoring
- •Decomposition by Design
- •Decomposition in This Book
- •Naming
- •Choosing a Good Name
- •Naming Conventions
- •Using Language Features with Style
- •Use Constants
- •Take Advantage of const Variables
- •Use References Instead of Pointers
- •Use Custom Exceptions
- •Formatting
- •The Curly Brace Alignment Debate
- •Coming to Blows over Spaces and Parentheses
- •Spaces and Tabs
- •Stylistic Challenges
- •Introducing the Spreadsheet Example
- •Writing Classes
- •Class Definitions
- •Defining Methods
- •Using Objects
- •Object Life Cycles
- •Object Creation
- •Object Destruction
- •Assigning to Objects
- •Distinguishing Copying from Assignment
- •The Spreadsheet Class
- •Freeing Memory with Destructors
- •Handling Copying and Assignment
- •Different Kinds of Data Members
- •Static Data Members
- •Const Data Members
- •Reference Data Members
- •Const Reference Data Members
- •More about Methods
- •Static Methods
- •Const Methods
- •Method Overloading
- •Default Parameters
- •Inline Methods
- •Nested Classes
- •Friends
- •Operator Overloading
- •Implementing Addition
- •Overloading Arithmetic Operators
- •Overloading Comparison Operators
- •Building Types with Operator Overloading
- •Pointers to Methods and Members
- •Building Abstract Classes
- •Using Interface and Implementation Classes
- •Building Classes with Inheritance
- •Extending Classes
- •Overriding Methods
- •Inheritance for Reuse
- •The WeatherPrediction Class
- •Adding Functionality in a Subclass
- •Replacing Functionality in a Subclass
- •Respect Your Parents
- •Parent Constructors
- •Parent Destructors
- •Referring to Parent Data
- •Casting Up and Down
- •Inheritance for Polymorphism
- •Return of the Spreadsheet
- •Designing the Polymorphic Spreadsheet Cell
- •The Spreadsheet Cell Base Class
- •The Individual Subclasses
- •Leveraging Polymorphism
- •Future Considerations
- •Multiple Inheritance
- •Inheriting from Multiple Classes
- •Naming Collisions and Ambiguous Base Classes
- •Interesting and Obscure Inheritance Issues
- •Special Cases in Overriding Methods
- •Copy Constructors and the Equals Operator
- •The Truth about Virtual
- •Runtime Type Facilities
- •Non-Public Inheritance
- •Virtual Base Classes
- •Class Templates
- •Writing a Class Template
- •How the Compiler Processes Templates
- •Distributing Template Code between Files
- •Template Parameters
- •Method Templates
- •Template Class Specialization
- •Subclassing Template Classes
- •Inheritance versus Specialization
- •Function Templates
- •Function Template Specialization
- •Function Template Overloading
- •Friend Function Templates of Class Templates
- •Advanced Templates
- •More about Template Parameters
- •Template Class Partial Specialization
- •Emulating Function Partial Specialization with Overloading
- •Template Recursion
- •References
- •Reference Variables
- •Reference Data Members
- •Reference Parameters
- •Reference Return Values
- •Deciding between References and Pointers
- •Keyword Confusion
- •The const Keyword
- •The static Keyword
- •Order of Initialization of Nonlocal Variables
- •Types and Casts
- •typedefs
- •Casts
- •Scope Resolution
- •Header Files
- •C Utilities
- •Variable-Length Argument Lists
- •Preprocessor Macros
- •How to Picture Memory
- •Allocation and Deallocation
- •Arrays
- •Working with Pointers
- •Array-Pointer Duality
- •Arrays Are Pointers!
- •Not All Pointers Are Arrays!
- •Dynamic Strings
- •C-Style Strings
- •String Literals
- •The C++ string Class
- •Pointer Arithmetic
- •Custom Memory Management
- •Garbage Collection
- •Object Pools
- •Function Pointers
- •Underallocating Strings
- •Memory Leaks
- •Double-Deleting and Invalid Pointers
- •Accessing Out-of-Bounds Memory
- •Using Streams
- •What Is a Stream, Anyway?
- •Stream Sources and Destinations
- •Output with Streams
- •Input with Streams
- •Input and Output with Objects
- •String Streams
- •File Streams
- •Jumping around with seek() and tell()
- •Linking Streams Together
- •Bidirectional I/O
- •Internationalization
- •Wide Characters
- •Non-Western Character Sets
- •Locales and Facets
- •Errors and Exceptions
- •What Are Exceptions, Anyway?
- •Why Exceptions in C++ Are a Good Thing
- •Why Exceptions in C++ Are a Bad Thing
- •Our Recommendation
- •Exception Mechanics
- •Throwing and Catching Exceptions
- •Exception Types
- •Throwing and Catching Multiple Exceptions
- •Uncaught Exceptions
- •Throw Lists
- •Exceptions and Polymorphism
- •The Standard Exception Hierarchy
- •Catching Exceptions in a Class Hierarchy
- •Writing Your Own Exception Classes
- •Stack Unwinding and Cleanup
- •Catch, Cleanup, and Rethrow
- •Use Smart Pointers
- •Common Error-Handling Issues
- •Memory Allocation Errors
- •Errors in Constructors
- •Errors in Destructors
- •Putting It All Together
- •Why Overload Operators?
- •Limitations to Operator Overloading
- •Choices in Operator Overloading
- •Summary of Overloadable Operators
- •Overloading the Arithmetic Operators
- •Overloading Unary Minus and Unary Plus
- •Overloading Increment and Decrement
- •Overloading the Subscripting Operator
- •Providing Read-Only Access with operator[]
- •Non-Integral Array Indices
- •Overloading the Function Call Operator
- •Overloading the Dereferencing Operators
- •Implementing operator*
- •Implementing operator->
- •What in the World Is operator->* ?
- •Writing Conversion Operators
- •Ambiguity Problems with Conversion Operators
- •Conversions for Boolean Expressions
- •How new and delete Really Work
- •Overloading operator new and operator delete
- •Overloading operator new and operator delete with Extra Parameters
- •Two Approaches to Efficiency
- •Two Kinds of Programs
- •Is C++ an Inefficient Language?
- •Language-Level Efficiency
- •Handle Objects Efficiently
- •Use Inline Methods and Functions
- •Design-Level Efficiency
- •Cache as Much as Possible
- •Use Object Pools
- •Use Thread Pools
- •Profiling
- •Profiling Example with gprof
- •Cross-Platform Development
- •Architecture Issues
- •Implementation Issues
- •Platform-Specific Features
- •Cross-Language Development
- •Mixing C and C++
- •Shifting Paradigms
- •Linking with C Code
- •Mixing Java and C++ with JNI
- •Mixing C++ with Perl and Shell Scripts
- •Mixing C++ with Assembly Code
- •Quality Control
- •Whose Responsibility Is Testing?
- •The Life Cycle of a Bug
- •Bug-Tracking Tools
- •Unit Testing
- •Approaches to Unit Testing
- •The Unit Testing Process
- •Unit Testing in Action
- •Higher-Level Testing
- •Integration Tests
- •System Tests
- •Regression Tests
- •Tips for Successful Testing
- •The Fundamental Law of Debugging
- •Bug Taxonomies
- •Avoiding Bugs
- •Planning for Bugs
- •Error Logging
- •Debug Traces
- •Asserts
- •Debugging Techniques
- •Reproducing Bugs
- •Debugging Reproducible Bugs
- •Debugging Nonreproducible Bugs
- •Debugging Memory Problems
- •Debugging Multithreaded Programs
- •Debugging Example: Article Citations
- •Lessons from the ArticleCitations Example
- •Requirements on Elements
- •Exceptions and Error Checking
- •Iterators
- •Sequential Containers
- •Vector
- •The vector<bool> Specialization
- •deque
- •list
- •Container Adapters
- •queue
- •priority_queue
- •stack
- •Associative Containers
- •The pair Utility Class
- •multimap
- •multiset
- •Other Containers
- •Arrays as STL Containers
- •Strings as STL Containers
- •Streams as STL Containers
- •bitset
- •The find() and find_if() Algorithms
- •The accumulate() Algorithms
- •Function Objects
- •Arithmetic Function Objects
- •Comparison Function Objects
- •Logical Function Objects
- •Function Object Adapters
- •Writing Your Own Function Objects
- •Algorithm Details
- •Utility Algorithms
- •Nonmodifying Algorithms
- •Modifying Algorithms
- •Sorting Algorithms
- •Set Algorithms
- •The Voter Registration Audit Problem Statement
- •The auditVoterRolls() Function
- •The getDuplicates() Function
- •The RemoveNames Functor
- •The NameInList Functor
- •Testing the auditVoterRolls() Function
- •Allocators
- •Iterator Adapters
- •Reverse Iterators
- •Stream Iterators
- •Insert Iterators
- •Extending the STL
- •Why Extend the STL?
- •Writing an STL Algorithm
- •Writing an STL Container
- •The Appeal of Distributed Computing
- •Distribution for Scalability
- •Distribution for Reliability
- •Distribution for Centrality
- •Distributed Content
- •Distributed versus Networked
- •Distributed Objects
- •Serialization and Marshalling
- •Remote Procedure Calls
- •CORBA
- •Interface Definition Language
- •Implementing the Class
- •Using the Objects
- •A Crash Course in XML
- •XML as a Distributed Object Technology
- •Generating and Parsing XML in C++
- •XML Validation
- •Building a Distributed Object with XML
- •SOAP (Simple Object Access Protocol)
- •. . . Write a Class
- •. . . Subclass an Existing Class
- •. . . Throw and Catch Exceptions
- •. . . Read from a File
- •. . . Write to a File
- •. . . Write a Template Class
- •There Must Be a Better Way
- •Smart Pointers with Reference Counting
- •Double Dispatch
- •Mix-In Classes
- •Object-Oriented Frameworks
- •Working with Frameworks
- •The Model-View-Controller Paradigm
- •The Singleton Pattern
- •Example: A Logging Mechanism
- •Implementation of a Singleton
- •Using a Singleton
- •Example: A Car Factory Simulation
- •Implementation of a Factory
- •Using a Factory
- •Other Uses of Factories
- •The Proxy Pattern
- •Example: Hiding Network Connectivity Issues
- •Implementation of a Proxy
- •Using a Proxy
- •The Adapter Pattern
- •Example: Adapting an XML Library
- •Implementation of an Adapter
- •Using an Adapter
- •The Decorator Pattern
- •Example: Defining Styles in Web Pages
- •Implementation of a Decorator
- •Using a Decorator
- •The Chain of Responsibility Pattern
- •Example: Event Handling
- •Implementation of a Chain of Responsibility
- •Using a Chain of Responsibility
- •Example: Event Handling
- •Implementation of an Observer
- •Using an Observer
- •Chapter 1: A Crash Course in C++
- •Chapter 3: Designing with Objects
- •Chapter 4: Designing with Libraries and Patterns
- •Chapter 5: Designing for Reuse
- •Chapter 7: Coding with Style
- •Chapters 8 and 9: Classes and Objects
- •Chapter 11: Writing Generic Code with Templates
- •Chapter 14: Demystifying C++ I/O
- •Chapter 15: Handling Errors
- •Chapter 16: Overloading C++ Operators
- •Chapter 17: Writing Efficient C++
- •Chapter 19: Becoming Adept at Testing
- •Chapter 20: Conquering Debugging
- •Chapter 24: Exploring Distributed Objects
- •Chapter 26: Applying Design Patterns
- •Beginning C++
- •General C++
- •I/O Streams
- •The C++ Standard Library
- •C++ Templates
- •Integrating C++ and Other Languages
- •Algorithms and Data Structures
- •Open-Source Software
- •Software-Engineering Methodology
- •Programming Style
- •Computer Architecture
- •Efficiency
- •Testing
- •Debugging
- •Distributed Objects
- •CORBA
- •XML and SOAP
- •Design Patterns
- •Index
Chapter 24
XML as a Distributed Object Technology
Since XML is simple and easy to work with, it has become popular as a mechanism for serialization. XML serialized objects can be sent across a network, and the sender can be confident that the recipient will be able to parse them, regardless of their platform. For example, consider the simple class shown here:
class Simple
{
public:
std::string mName;
int mPriority;
std::string mData;
};
An object of type Simple could be serialized to the following XML:
<Simple name=”some name” priority=”7”>this is the data</Simple>
Of course, since XML doesn’t specify how individual nodes should be used, you could just as easily serialize it as follows:
<Simple name=”some name” priority=”7” data=”this is the data” />
As long as the recipient of the serialized XML is aware of the rules you are using to serialize the object, they should be able to deserialize it.
XML serialization has increased in popularity as a simpler alternative to heavyweight distributed object technologies such as CORBA. XML has a much more gradual learning curve than CORBA and offers many of the same benefits, such as platform and language independence.
Generating and Parsing XML in C++
Because XML is merely a file format, and not an object description language, the task of converting data to and from XML is left to the programmer. In general, writing XML is the easy part. Reading XML is usually aided by a third-party XML library.
Generating XML
To use XML as a serialization technology, your objects will need to be able to convert themselves into XML. In many cases, building a stream of XML on the fly is the easiest way to output XML. In fact, the notion that XML elements are “wrapped” in other elements makes things even easier. You can build new XML documents as amalgams of existing ones. If that sounds a bit complicated, consider the following example. Assume that you have a function called getNextSentenceXML(), which asks the user for a sentence and returns it as an XML representation of the sentence. Because that function returns the sentence as a valid XML element, you could create a dialogue of sentences by wrapping the results of multiple calls to getNextSentenceXML() in a dialogue element tag:
712

Exploring Distributed Objects
string getDialogueXML()
{
sstringstream outStream;
// Begin the dialogue element. outStream << “<dialogue>”;
while (true) {
// Get the next sentence.
string sentenceXML = getNextSentenceXML(); if (sentenceXML == “”) break;
// Add the sentence element. outStream << sentenceXML;
}
// End the dialogue element. outStream << “</dialogue>”;
return outStream.toString();
}
If subsequent calls to getNextSentenceXML() returned the sentences from the preceding example, the result of this function would be:
<dialogue><sentence speaker=”Marni”>Let’s go get some ice cream.</sentence><sentence speaker=”Scott”>After I’m done writing this C++ book.</sentence></dialogue>
The output is a bit strange because it wasn’t formatted with line breaks and tabs. It is, however, valid XML. If you wanted to beautify the output a bit, you have a few options:
You could use a third-party tool after the fact. For example, the open-source command-line program tidy (http://tidy.sourceforge.net) has an XML pretty-print feature among its many useful tools.
You could include carriage returns and spaces manually in your code. This quickly gets complicated because inside of getNextSentenceXML(), the code has no idea how many tabs to use.
You could use (or write) a simple XML generation class library that is aware of nested elements and formats them appropriately.
An XML Output Class
Even though outputting XML is straightforward, there are several good reasons to factor XML output code into a separate class or set of classes. In addition to the formatting issue seen previously, separating out the code for XML generation provides the following benefits:
Cleaner code. Who wants < all over the place?!
A central location to implement escaping of special characters.
713

Chapter 24
A more object-oriented approach. XML elements could be objects, which can then be stored, passed to methods, and organized.
Reduction of the possibility of XML syntax errors by centralizing output.
Writing an XML generation class is also temptingly simple. The class definition of a simple XML Element class is shown here:
// XMLElement.h
#include <string> #include <vector> #include <map> #include <iostream>
class XMLElement
{
public:
XMLElement();
void setElementName(const std::string& inName);
void setAttribute(const std::string& inAttributeName, const std::string& inAttributeValue);
void addSubElement(const XMLElement* inElement);
// Setting a text node will override any nested elements. void setTextNode(const std::string& inValue);
friend std::ostream& operator<<(std::ostream& outStream, const XMLElement& inElem);
protected:
void writeToStream(std::ostream& outStream, int inIndentLevel = 0) const;
void indentStream(std::ostream& outStream, int inIndentLevel) const;
private: |
|
std::string |
mElementName; |
std::map<std::string, std::string> |
mAttributes; |
std::vector<const XMLElement*> |
mSubElements; |
std::string |
mTextNode; |
};
Using this class, a user could easily create XMLElement objects, set their attributes, and set text nodes or subelements. At any time, the client can call operator<< to get the XML representation of the current state of the element.
A sample implementation is shown next. Because it uses C++ syntax, which you’re a pro at by now, we won’t explain every single line. Take a look at the inline comments if it doesn’t make sense at first glance.
714

Exploring Distributed Objects
#include “XMLElement.h”
using namespace std;
XMLElement::XMLElement() : mElementName(“unnamed”)
{
}
void XMLElement::setElementName(const string& inName)
{
mElementName = inName;
}
void XMLElement::setAttribute(const string& inAttributeName, const string& inAttributeValue)
{
// Set the key/value pair, replacing the existing one if it exists. mAttributes[inAttributeName] = inAttributeValue;
}
void XMLElement::addSubElement(const XMLElement* inElement)
{
// Add the new element to the vector of subelements. mSubElements.push_back(inElement);
}
void XMLElement::setTextNode(const string& inValue)
{
mTextNode = inValue;
}
ostream& operator<<(ostream& outStream, const XMLElement& inElem)
{
inElem.writeToStream(outStream); return (outStream);
}
void XMLElement::writeToStream(ostream& outStream, int inIndentLevel) const
{
indentStream(outStream, inIndentLevel);
outStream << “<” << mElementName; // open the start tag
// Output any attributes.
for (map<string, string>::const_iterator it = mAttributes.begin(); it != mAttributes.end(); ++it) {
outStream << “ “ << it->first << “=\”” << it->second << “\””;
}
// Close the start tag. outStream << “>”;
if (mTextNode != “”) {
// If there’s a text node, output it.
715

Chapter 24
outStream << mTextNode; } else {
outStream << endl;
// Call writeToStream at inIndentLevel+1 for any subelements.
for (vector<const XMLElement*>::const_iterator it = mSubElements.begin(); it != mSubElements.end(); ++it) {
(*it)->writeToStream(outStream, inIndentLevel + 1);
}
indentStream(outStream, inIndentLevel);
}
// Write the close tag.
outStream << “</” << mElementName << “>” << endl;
}
void XMLElement::indentStream(ostream& outStream, int inIndentLevel) const
{
for (int i = 0; i < inIndentLevel; i++) { outStream << “\t”;
}
}
The preceding implementation is a great starting point and is perfect for simple XML applications. One of the features that is missing is the escaping of special characters. For example, the character & needs to be escaped as & inside of an XML document. Here is a sample program that shows the use of the XMLElement class to build the document that was output manually in the previous example:
int main(int argc, char** argv)
{
XMLElement dialogueElement; dialogueElement.setElementName(“dialogue”);
XMLElement sentenceElement1; sentenceElement1.setElementName(“sentence”); sentenceElement1.setAttribute(“speaker”, “Marni”); sentenceElement1.setTextNode(“Let’s go get some ice cream.”);
XMLElement sentenceElement2; sentenceElement2.setElementName(“sentence”);
sentenceElement2.setAttribute(“speaker”, “Scott”); sentenceElement2.setTextNode(“After I’m done writing this C++ book.”);
//Add the sentence elements as subelements of the dialogue element. dialogueElement.addSubElement(&sentenceElement1); dialogueElement.addSubElement(&sentenceElement2);
//Output the dialogue element to stdout.
cout << dialogeElement;
return 0;
}
716

Exploring Distributed Objects
The output of this program is:
<dialogue>
<sentence speaker=”Marni”>Let’s go get some ice cream.</sentence> <sentence speaker=”Scott”>After I’m done writing this C++ book.</sentence>
</dialogue>
Many XML Parsing libraries also include XML output facilities. If you are using an XML parser for input (described next), check into its output capabilities before writing your own.
Parsing XML
To deserialize XML objects, you’ll need to interpret, or parse, the document. Unless the XML you are reading is extremely simple and rigidly defined, you will most likely want to use a third-party XML parsing library. XML parsing libraries typically come in two flavors, SAX and DOM.
A SAX (Simple API for XML) parser uses an event-based parsing model. To use a SAX parser, you register callback functions or an object that implements certain methods. As the document is parsed, the appropriate functions or methods are called, giving you a chance to perform an action. For example, if you wanted to look for duplicate XML element names in a document, you could register a callback that is triggered upon reaching an element start tag. Internally, you would keep a list of elements that had already been encountered. Using that list, you could detect the duplicates.
A DOM (Document Object Model) parser converts an XML document into a treelike structure that you can easily walk through in code. To programmers accustomed to object-oriented hierarchies and tree data structures, the DOM approach may seem more natural. The disadvantage of the DOM approach is performance. Because it parses the entire document and builds a structure, it is generally slower and more memory-intensive than SAX. Though the rest of this section deals only with DOM parsers, you will find that most XML parsers support both SAX and DOM.
The Xerces XML Library
One of the most popular XML parsers is Xerces, which is part of the Apache XML project. Xerces is an open-source parser and is available for several languages, including C++. You can download the Xerces- C++ library from http://xml.apache.org/.
Once you have Xerces installed and added to your C++ project, you can offload the work of parsing XML. Xerces is easy to get started with even though it has a wealth of functionality — a sign of a welldesigned library!
The most important class in the Xerces DOM parser is DOMNode. A DOMNode is a single unit of XML data, possibly including other nodes. The subclasses of DOMNode include DOMDocument, DOMElement, DOMAttr, DOMText, an so on. Working with an Xerces DOM generally involves starting with the root node (a DOMDocument) and walking through the tree of nodes to find the desired data. Figure 24-4 shows a slightly simplified version of the node tree for the <dialogue> XML document. It is simplified in that it only shows nodes that actually contain data.
717
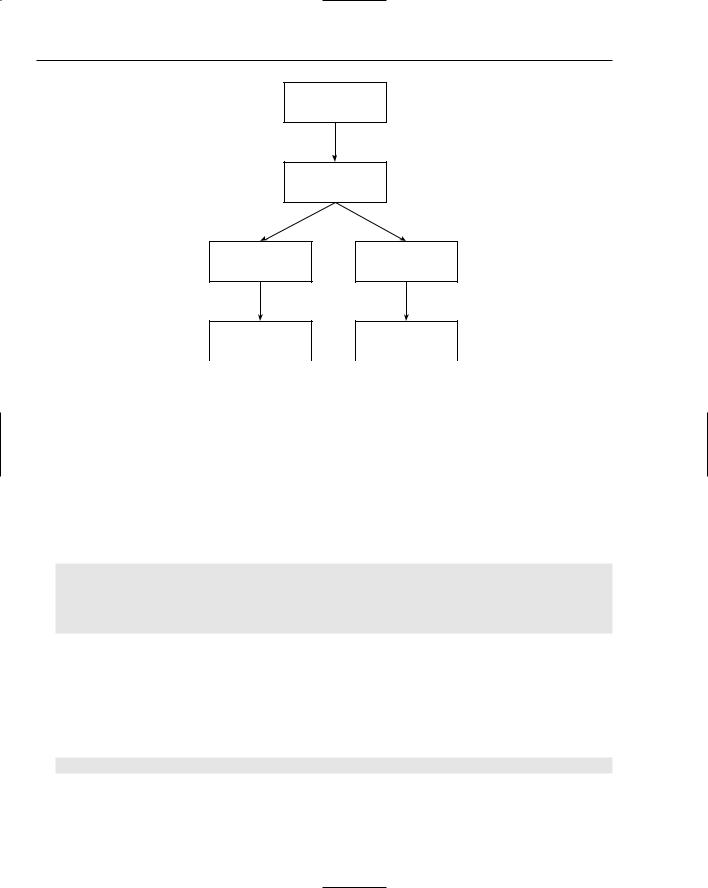
Chapter 24
DocumentRoot (DOMDocument)
<dialogue>
(DOMElement)
<sentence>
(DOMElement)
Let's go get...
(DOMText)
Figure 24-4
<sentence>
(DOMElement)
After I'm done...
(DOMText)
The XML attributes are not shown in Figure 24-4 because they are properties of an element, not children of the element.
Using Xerces
The one tricky aspect that you will face first is the way that Xerces represents strings. Because XML can be encoded in various ways, the library has its own character type: XMLch. It also has a utility class called XMLString that makes it easy to work with XMLch strings and convert them to more familiar chars. For example, if a Xerces method returns data as an XMLch* string, you can output it by using
XMLString::transcode() to get a C-style string:
void outputXercesString(XMLch* inXercesString)
{
char* familiarString = XMLString::transcode(inXercesString); cout << familiarString << endl;
}
Because transcode() allocates memory for the C-style string, you must also release it with XMLString::release(), which (in a somewhat bizarre design choice) takes a pointer to the C-style string. The modified version below avoids a memory leak:
void outputXercesString(XMLch* inXercesString)
{
char* familiarString = XMLString::transcode(inXercesString); cout << familiarString << endl; XMLString::release(&familiarString);
}
718

Exploring Distributed Objects
With that bit of oddness out of the way, it’s time to parse some XML. This example parses a file named test.xml into a DOM tree, and then loops through all of the nodes, printing out the names of all elements that are encountered, any attributes contained within those elements, and the contents of any text nodes.
The program begins by including the necessary standard headers and Xerces headers. It also declares XERCES_CPP_NAMESPACE_USE, which is a #define in Xerces that gives the correct namespace to the file.
#include <xercesc/util/PlatformUtils.hpp>
#include <xercesc/dom/DOM.hpp>
#include <xercesc/parsers/XercesDOMParser.hpp> #include <xercesc/util/XMLString.hpp>
#include <iostream>
XERCES_CPP_NAMESPACE_USE using namespace std;
void printNode(const DOMNode* inNode);
The program’s main() is fairly straightforward, even though this is where the actual parsing is taking place. It begins by initializing the Xerces library. Next, it creates a new DOM parser and tells it to parse the file. The result of this operation is a DOMNode that represents the document as a whole. To obtain the root element, getDocumentElement() is called. This value is passed to printNode(), which walks through the tree, printing out the data. Finally, the program cleans up the XML library before exiting.
int main(int argc, char** argv)
{
XMLPlatformUtils::Initialize();
XercesDOMParser* parser = new XercesDOMParser(); parser->parse(“test.xml”);
DOMNode* node = parser->getDocument();
DOMDocument* document = dynamic_cast<DOMDocument*>(node);
if (document != NULL) { printNode(document->getDocumentElement());
}
delete parser; XMLPlatformUtils::Terminate();
return 0;
}
The printNode() function is where things get interesting. Because the parameter inNode can be any type of XML node, the function tries its two known node types in sequence. It first attempts to dynamically cast the node into a text node, catching the cast error in case the node is a different type:
719

Chapter 24
void printNode(const DOMNode* inNode)
{
try {
const DOMText& textNode = dynamic_cast<const DOMText&>(*inNode); char* text = XMLString::transcode(textNode.getData());
cout << “Found text data: “ << text << endl; XMLString::release(&text);
}catch (bad_cast) {
//Not a text node . . .
Next, it tries to cast to an element node. If this cast is successful, the element’s name and any attributes are printed out.
try {
const DOMElement& elementNode = dynamic_cast<const DOMElement&>(*inNode); char* tagName = XMLString::transcode(elementNode.getTagName());
cout << “Found tag named: “ << tagName << endl; XMLString::release(&tagName);
// Look at the attribute list.
DOMNamedNodeMap* attributes = elementNode.getAttributes(); for (int i = 0; i < attributes->getLength(); i++) {
try {
const DOMAttr& attrNode =
dynamic_cast<const DOMAttr&>(*attributes->item(i));
char* name = XMLString::transcode(attrNode.getName()); char* value = XMLString::transcode(attrNode.getValue());
cout << “Found attribute pair: (“ << name << “=” << value << “)” << endl;
XMLString::release(&name);
XMLString::release(&value); } catch (bad_cast) {
cerr << “Error converting attribute!” << endl;
}
}
}catch (bad_cast) {
//Not an element node . . .
Finally, the function calls printNode() recursively on children nodes. In practice, children nodes will only exist on element nodes.
// Print any subelements.
DOMNodeList* children = inNode->getChildNodes(); for (int i = 0; i < children->getLength(); i++) {
printNode(children->item(i));
}
}
720