


Chapter 6
the tasks it is supposed to or doesn’t work the way the user would expect. These issues all point to a common truism of software — writing software is hard.
One wonders why software engineering seems to differ from other forms of engineering in its frequency of failures. While cars do have their share of bugs, you rarely see them stop suddenly and demand a reboot due to a buffer overflow (though as more auto components become software-driven, you just may!) Your TV may not be perfect, but you don’t have to upgrade to version 2.3 to get Channel 6 to work.
Is it the case that other engineering disciplines are just more advanced than software? Is a civil engineer able to construct a working bridge by drawing upon the long history of bridge building? Are chemical engineers able to build a compound successfully because most of the bugs were worked out in earlier generations?
Is software simply too new, or is it really a different type of discipline with inherent qualities contributing to the occurrence of bugs, unusable results, and doomed projects?
It certainly seems as if there’s something different about software. For one thing, technology changes rapidly in software, creating uncertainty in the software development process. Even if an earth-shattering breakthrough does not occur during your project, the pace of the industry leads to paranoia. Software often needs to be developed quickly because competition is fierce.
Software development can also be unpredictable. Accurate scheduling is nearly impossible when a single gnarly bug can take days or even weeks to fix. Even when things seem to be going according to schedule, the widespread tendency of product definition changes (feature creep) can throw a wrench in the process.
Software is complex. There is no easy and accurate way to prove that a program is bug-free. Buggy or messy code can have an impact on software for years if it is maintained through several versions. Software systems are often so complex that when staff turnover occurs, nobody wants to get anywhere near the messy code that forgotten engineers have left behind. This leads to a cycle of endless patching, hacks, and workarounds.
Of course, standard business risks apply to software as well. Marketing pressures and miscommunication get in the way. Many programmers try to steer clear of corporate politics, but it’s not uncommon to have adversity between the development and product marketing groups.
All of these factors working against software-engineering products indicate the need for some sort of process. Software projects are big, complicated, and fast-paced. To avoid failure, engineering groups need to adopt a system to control this unwieldy process.
Software Life-Cycle Models
Complexity in software isn’t new. The need for formalized process was recognized decades ago. Several approaches to modeling the software life cycle have attempted to bring some order to the chaos
120

Maximizing Software-Engineering Methods
of software development by defining the software process in terms of steps from the initial idea to the final product. These models, refined over the years, guide much of software development today.
The Stagewise and Waterfall Models
The classic life cycle model for software is often referred to as the Stagewise Model. This model is based on the idea that software can be built almost like following a recipe. There is a set of steps that, if followed correctly, will yield a mighty fine chocolate cake, or program as the case may be. Each stage must be completed before the next stage can begin, as shown in Figure 6-1.
Planning
Design
Implementation
Unit Testing
Subsystem
Testing
Integration
Testing
Evaluation
Figure 6-1
The process starts with formal planning, including gathering an exhaustive list of requirements. This list defines feature completeness for the product. The more specific the requirements are, the more likely that the project will succeed. Next, the software is designed and fully specified. The design step, like the requirements step, needs to be as specific as possible to maximize the chance of success. All design decisions are made at this time, often including pseudocode and the definition of specific subsystems that will need to be written. Subsystem owners work out how their code will interact, and the team agrees on the specifics of the architecture. Implementation of the design occurs next. Because the design has been fully specified, the code needs to adhere strongly to the design or else the pieces won’t fit together. The final four stages are reserved for unit testing, subsystem testing, integration testing, and evaluation.
121
Chapter 6
The main problem with the Stagewise Model is that, in practice, it is nearly impossible to complete one stage without at least exploring the next stage. A design cannot be set in stone without at least writing some code. Furthermore, what is the point of testing if the model doesn’t provide a way to go back to the coding phase?
A number of refinements to the Stagewise Model were formalized as the Waterfall Model in the early 1970s. This model continues to be highly influential, if not downright dominant, in modern softwareengineering organizations. The main advancement that the Waterfall Model brought was a notion of feedback between stages. While it still stresses a rigorous process of planning, designing, coding, and testing, successive stages can overlap in part. Figure 6-2 shows an example of the Waterfall Model, illustrating the feedback and overlap refinements. Feedback allows lessons learned in one phase to result in changes to the previous phase. Overlap permits activity in two phases to occur simultaneously.
Planning
Design
Implementation
Unit Testing
Subsystem
Testing
Integration
Testing
Evaluation
Figure 6-2
Various incarnations of the waterfall method have refined the process in different ways. For example, some plans include a “feasibility” step where experiments are performed before formal requirements are even gathered.
Benefits of the Waterfall Model
The value of the Waterfall Model lies in its simplicity. You, or your manager, may have followed this approach in past projects without formalizing it or recognizing it by name. The underlying assumption behind the Stepwise and Waterfall Models is that as long as each step is accomplished as completely and accurately as possible, subsequent steps will go smoothly. As long as all of the requirements are carefully specified in the first step, and all the design decisions and problems are hashed out in the second step, implementation in the third step should be a simple matter of translating the designs into code.
122

Maximizing Software-Engineering Methods
The simplicity of the Waterfall Model makes project plans based on this system organized and easy to manage. Every project is started the same way: by exhaustively listing all the features that are necessary. Managers using this approach can require that by the end of the design phase, for example, all engineers in charge of a subsystem submit their design as a formal design document or a functional subsystem specification. The benefit for the manager is that by having engineers specify and design upfront, risks are, hopefully, minimized.
From the engineer’s point of view, the Waterfall Method forces resolution of major issues upfront. All engineers will need to understand their project and design their subsystem before writing a significant amount of code. Ideally, this means that code can be written once instead of hacked together or rewritten when the pieces don’t fit.
For small projects with very specific requirements, the Waterfall Method can work quite well. Particularly for consulting arrangements, it has the advantage of specifying specific metrics for success at the start of the project. Formalizing requirements helps the consultant to produce exactly what the client wants and forces the client to be specific about the goals for the project.
Drawbacks of the Waterfall Model
In many organizations, and almost all modern software-engineering texts, the Waterfall Method has fallen out of favor. Critics disparage its fundamental premise that software development tasks happen in discrete linear steps. While the Waterfall Method allows for the overlapping of phases, it does not allow backward movement to a large degree. In many projects today, requirements come in throughout the development of the product. Often, a potential customer will request a feature that is necessary for the sale or a competitor’s product will have a new feature that requires parity.
The upfront specification of all requirements makes the Waterfall Method unusable for many organizations because it simply is not dynamic enough.
Another drawback is that in an effort to minimize risk by making decisions as formally and early as possible, the Waterfall Model may actually be hiding risk. For example, a major design issue might be undiscovered, glossed over, forgotten, or purposely avoided in the design phase. By the time integration testing reveals the mismatch, it may be too late to save the project. A major design flaw has arisen
but, according to the Waterfall Model, the product is one step away from shipping! A mistake anywhere in the waterfall process will likely lead to failure at the end of the process. Early detection is difficult and rare.
While the Waterfall Model is still quite common and can be an effective way of visualizing the process, it is often necessary to make it more flexible by taking cues from other approaches.
The Spiral Method
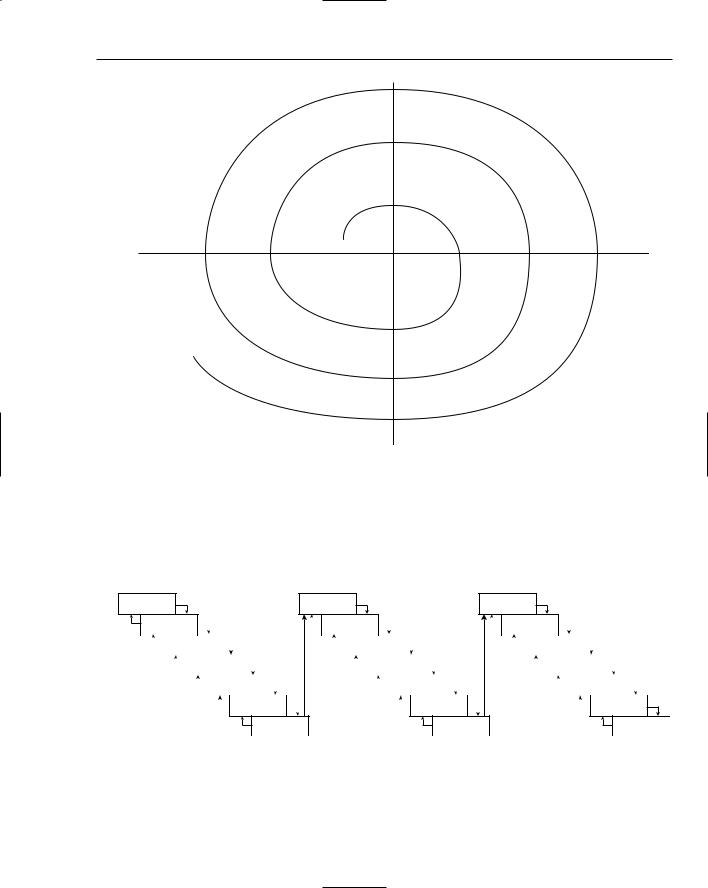
The Spiral Method was proposed by Barry W. Boehm in 1988 in recognition of the occurrence of unexpected problems and changing requirements in the software development process. This method is part
123

Chapter 6
of a family of techniques known as iterative processes. The fundamental idea is that it’s okay if something goes wrong because you’ll fix it the next time around. A single spin through the spiral method is shown in Figure 6-3.
Discovery |
Evaluation |
Analysis |
Development |
Figure 6-3
The phases of the Spiral Method are similar to the steps of the Waterfall Method. The discovery phase involves building requirements and determining objectives. During the evaluation phase, implementation alternatives are considered and prototypes may be built. In the Spiral Method, particular attention is paid to evaluating and resolving risks in the evaluation phase. The tasks deemed most risky are the ones that are implemented in the current cycle of the spiral. The tasks in the development phase are determined by the risks identified in the evaluation phase. For example, if evaluation reveals a risky algorithm that may be impossible to implement, the main task for development in the current cycle will be modeling, building, and testing that algorithm. The fourth phase is reserved for analysis and planning. Based on the results of the current cycle, the plan for the subsequent cycle is formed. Each iteration is expected to be fairly short in duration, taking only a few key features and risks into consideration.
Figure 6-4 shows an example of three cycles through the spiral in the development of an operating system. The first cycle yields a plan containing the major requirements for the product. The second cycle results in a prototype showing the user experience. The third cycle builds a component that is determined to be a high risk.
124
Maximizing Software-Engineering Methods |
|
Discovery |
Evaluation |
Feature A |
Feature A Risk |
Requirements |
Analysis |
3 |
Prototype |
Prototype |
|
Requirements |
Options |
2 |
|
Plan |
Plan |
Requirements |
Alternatives |
1 |
|
Prototype Plan |
Build Plan |
|
|
|
|
Feature A Plan |
Build Prototype |
Feature A Risk |
|
Elimination |
|
|
|
|
New Feature A Plan |
|
|
Analysis |
|
Development |
Figure 6-4
Benefits of the Spiral Method
The Spiral Method can be viewed as the application of an iterative approach to the best that the Waterfall Method has to offer. Figure 6-5 shows the Spiral Method as a waterfall process that has been modified to allow iteration. Hidden risks and a linear development path, the main drawbacks of the Waterfall Method, are resolved through short iterative cycles.
Planning |
Planning |
Planning |
|
Design |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Design |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Design |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Implementation |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Implementation |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Implementation |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Unit Testing |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Unit Testing |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Unit Testing |
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Subsystem |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Subsystem |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Subsystem |
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
Testing |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Testing |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Testing |
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Integration |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Integration |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Integration |
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
Testing |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Testing |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Testing |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||
Evaluation |
Evaluation |
Evaluation |
Figure 6-5
125