

Visual CSharp .NET Programming (2002) [eng]
.pdf•Provide an example using regular expressions that shows how the .NET regular expression classes interrelate.
This is an ambitious agenda-using regular expressions in C# is a subject that would easily fill an entire book-which implies that in the remainder of this chapter I can only scratch the surface of the topic. I invite you to use this material as a jumping off place, so that you can experiment with C# and regular expressions, and become a 'regex' master in your own right.
The Regular Expression Classes
The regular expression classes are located in the System.Text.RegularExpressions namespace, which means that you should add a using directive to the beginning of any module that involves regular expressions, like so:
using System.Text.RegularExpressions;
Figure 9.11 shows the regular expression classes in this namespace in the Object Browser.
Figure 9.11: The Regular Expression classes, shown in the Object Browser.
Here are brief descriptions of the regular expression classes (you may need to view online documentation or browse through the later parts of this chapter to understand some of the terminology):
Regex
This class can be used to instantiate an immutable regular expression object. It also provides a few static methods (for example, Escape and Unescape) that can be used with other classes.
Match
The results of a regular expression matching operation. The Match method of the Regex class returns a Match object.
MatchCollection
A sequence of nonoverlapping successful matches. The Matches method of the Regex class returns a MatchCollection object.
Capture
A single subexpression match.
Group
The results of a single capturing group, which contains a collection of Capture objects. Instances of Group are returned by the Match.Groups property.
CaptureCollection
A sequence of captured substrings. The Captures property of the Match and Group classes returns a CaptureCollection object.
GroupCollection
A collection of captured Group objects. The Groups property of the Match object returns a GroupCollection object.
Note The best way to find online documentation about regular expression classes and language is to set the Help Search filter to '.NET Framework SDK.' Next, search for 'Regular Expressions.' (You'll find details on using and configuring online help in the Appendix, 'Using C# .NET's Help System.')
A Regular Expression Test Bed
At a very basic level, you don't have to do much to use regular expressions. The general form is to create a Regex object that is a pattern. For example, the following regular expression will match any integer with between one and three digits:
Regex regex = new Regex (@"\d{1,3}");
Note The string verbatim symbol (@) is required before the regular expression patternotherwise the compiler will throw an exception because of an unrecognized escape character.
Note The \d{1,3} regular expression will be explained later in this section.
Next, provide a string to test against as an argument, and assign the results of the Regex instance's Match method to a Match object:
Match match = regex.Match ("42");
The properties of the Match object will then contain information about the first match: whether it was successful, the substring matched, the location of the match, and so on.
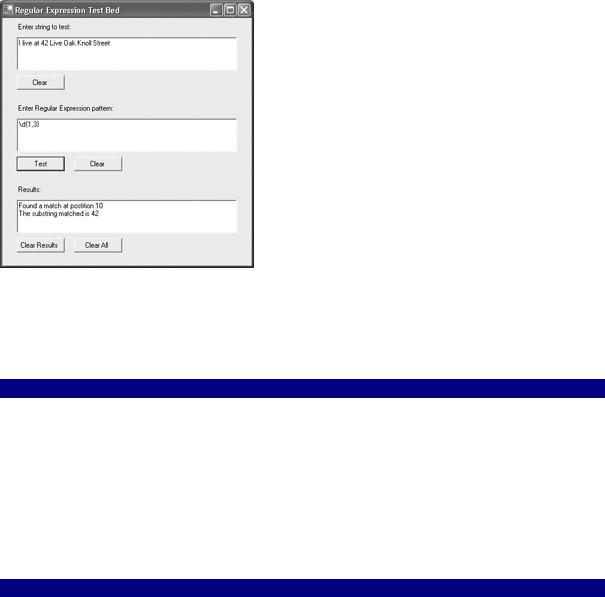
Figure 9.12 shows the user interface for a general regular expression test bed using this construction. Three multiline TextBoxes are intended for user entry of a test string and a pattern and to display the results.
Figure 9.12: It 's easy to set up a program that can be used to test regular expressions.
Listing 9.13 shows the click event code used to test for a regular expression match when the user enters a test string and pattern.
Listing 9.13: Testing Regular Expressions
private void btnTest_Click(object sender, System.EventArgs e) { Regex regex = new Regex (txtPattern.Text);
Match match = regex.Match(txtStrTest.Text); if (match.Success) {
string str = "Found a match at postition " + match.Index; str += "The substring matched is " + match.Value; txtResults.Text = str;
}
else {
txtResults.Text = "Sorry, no regular expression pattern match!";
}
}
Warning It perhaps doesn't need to be said this late into this book, but-in the real world-you'd want to include exception handling in this code. It's fairly easy to throw exceptions in the Regex class by entering strings that are not recognized as well-formed patterns. For example, entering a backslash (\) by itself as a pattern will cause an exception to be thrown when the compiler attempts to instantiate a Regex object based upon it.
The Syntax of Regular Expressions
Now that we have a way to test our regular expressions, we can start looking generally at how they are constructed.
Options
First, you should know that there are some attributes, also called options, which impact the way that a match is made. (For a complete list of these options, search online help for the topic 'Regular Expression Options.')
These options are specified using inline characters. The most commonly used are:
|
|
|
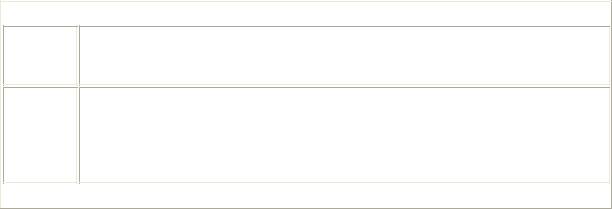
Character |
|
Meaning |
|
|
|
i |
|
Perform a case-insensitive match. |
|
|
|
x |
|
Ignore unescaped white space within a pattern, and enable |
|
|
commenting within a pattern following a pound sign (#). |
|
|
|
To enable an attribute inline, prefix the pattern with a question mark followed by the attribute character followed by a colon, and enclose the whole thing within parentheses. For example, the pattern:
(?i:saur)
matches the string 'ApatoSaUrus'. Of course, if you had tried to match the pattern 'saur' against the string, it would have behaved in a case-sensitive way, and there would have been no match.
Attributes can also be passed as an argument to an overloaded Regex constructor. For example,
Regex regex = new Regex ("saur", RegexOptions.IgnoreCase);
would create the same, case-insensitive pattern.
Literal Characters
You've already seen that an alphanumeric character within a regular expression matches itself. In addition, you can match many non-alphabetic characters using escape sequences.
Regular expression literal character matches are shown in Table 9.6.
Table 9.6: Regular Expression Characters and Character Sequences, and Their Matches
Character Matches or
Sequence
Alphabetic Itself (all characters other than . $ ^ { [ ( | ) * + ? \ match themselves) (az and
AZ) or numeric (09)
\b |
|
Backspace (see note following table) |
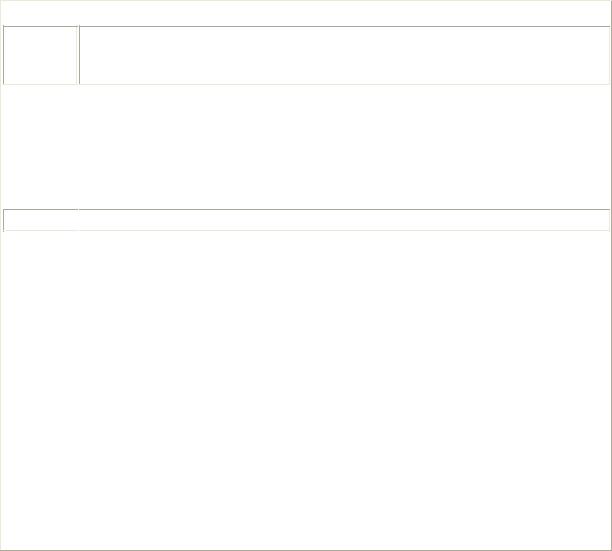
Table 9.6: Regular Expression Characters and Character Sequences, and Their Matches
Character Matches or
Sequence
\f |
|
Form feed |
|
|
|
\n |
|
New line |
|
|
|
\r |
|
Carriage return |
|
|
|
\t |
|
Tab |
|
|
|
\/ |
|
Slash ('forward slash,' literal /) |
\\
 Backslash (literal \)
Backslash (literal \)
\. |
|
. |
|
|
|
\* |
|
* |
|
|
|
\+ |
|
+ |
|
|
|
\? |
|
? |
|
|
|
\| |
|
| |
|
|
|
\( |
|
( |
|
|
|
\) |
|
) |
|
|
|
\[ |
|
[ |
|
|
|
\] |
|
] |
|
|
|
\{ |
|
{ |
|
|
|
\} |
|
} |
|
|
|
\xxx |
|
The ASCII character specified by the octal number xxx |
|
|
|
\uxxxx |
|
The Unicode character specified by the hexadecimal numberxxxx |
Note The escaped character \b is a special case. Within a regular expression, \b means a word boundary, except within a [] character class, where it means a backspace. (Character classes are explained in the next section.)
It's not a bad idea to see that these escape sequences really do match as specified. Let's use the test environment developed earlier in this chapter to make sure that \r matches a carriage return. In the first box, as the string to test, just hit the Enter key. For a regular expression, use \r. When you click the Test button, you'll see that there is, indeed, a match.
Character Classes
Individual literal characters can be combined into character classes in regular expressions. Character classes are contained within square brackets. A match occurs when one or more of the characters contained in the class produces a match with the comparison string.
For example, the regular expression
[csharp]
matches against any string that contains at least one of the letters (such as 'abc'). If you run the pattern in the test environment against 'abc', you'll find that the first match is the letter ‘a'.
The characters within a class can be specified using ranges, rather than by specific enumeration. A hyphen is used to indicate a range. Here are some examples:
|
|
|
Sequence |
|
Meaning |
|
|
|
[a-z] |
|
All lowercase characters from a to z |
|
|
|
[a-zA-L] |
|
All lowercase characters from a to z and all uppercase characters |
|
|
from A to L |
|
|
|
[a-zA-Z0-9] |
|
All lowerand uppercase letters and all numerals |
|
|
|
Using this notation, [a-zA-L] does not produce a match with the string "XYZ" but does match the string "xyz". By the way, you may have noticed that you could use the case attribute instead of separately listing uppercase and lowercase ranges. (?i:[a-z]) is the equivalent to [a- zA-Z].
Negating a Character Class
A character class can be negated. A negated class matches any character except those defined within brackets. To negate a character class, place a caret (^) as the first character inside the left bracket of the class. For example, the regular expression [^a-zA-Z] will match if and only if the comparison string contains at least one nonalphabetic character. "abcABC123" contains a match, but "abcABC" does not.
Common Character Class Representations
Because some character classes are frequently used, the syntax of regular expressions provides special sequences that are shorthand representations of these classes. Square brackets are not used with most of these special character 'abbreviations.' The sequences that can be used for character classes are shown in Table 9.7.
|
|
Table 9.7: Character Class Sequences and Their Meanings |
|
|
|
Character |
|
Matches |
Sequence |
|
|
|
|
|
[...] |
|
Any one character between the square brackets. |
|
|
|
[^...] |
|
Any one character not between the brackets. |
|
|
|
. |
|
Any one character other than new line; equivalent to [^\n]. |
|
|
|
\w |
|
Any one letter, number, or underscore; equivalent to [a-zA-Z0-9_]. |
|
|
|
\W |
|
Any one character other than a letter, number, or underscore; equivalent to [^a- |
|
|
zA-Z0-9_]. |
|
|
|
\s |
|
Any one space character or other white-space character; equivalent to [\t\n\r\f\v]. |
|
|
|
\S |
|
Any one character other than a space or other white-space character; equiva lent |
|
|
to [^ \t\n\r\f\v]. |
|
|
|
\d |
|
Any one digit; equivalent to [0-9]. |
|
|
|
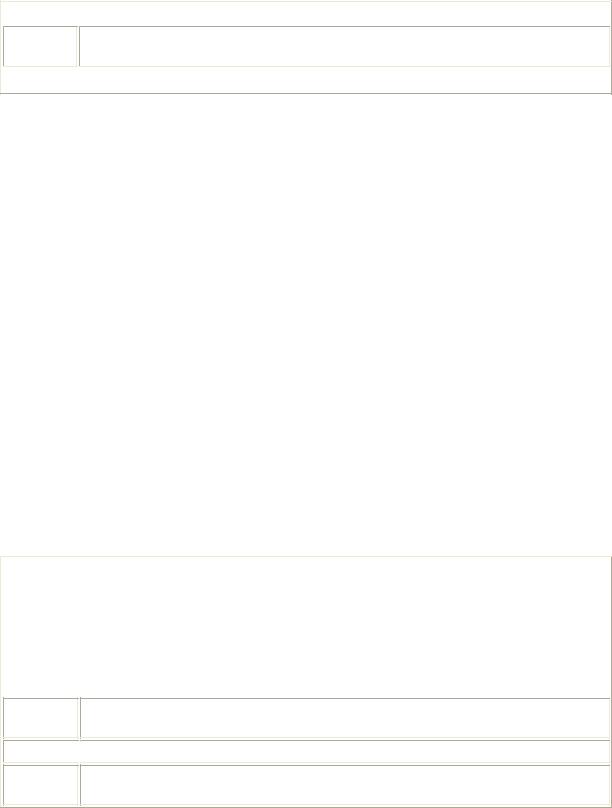
Table 9.7: Character Class Sequences and Their Meanings
Character Matches
Sequence
\D |
|
Any one character that is not a digit; equivalent to [^0-9]. |
For example, the pattern \W matches a string containing a hyphen (-) but fails against a string containing only letters (such as "abc").
In another example, \s matches a string containing a space, such as "lions and tigers, and bears". But \s fails against strings that do not contain white-space characters, such as "ineedsomespace".
Repeating Elements
So far, if you wanted to match a multiple number of characters, the only way to achieve this using a regular expression would be to enumerate each character. For example, \d\d would match any two-digit number. And \w\w\w\w\w would match any five-letter alphanumeric string, such as "string" or "94707".
This isn't good enough. In addition to being cumbersome, it doesn't allow complex pattern matches involving varied numbers of characters. For example, you might want to match a number between two and six digits in length, or a pair of letters followed by a number of any length.
This kind of 'wildcard' pattern is specified in regular expressions using curly braces ({}). The curly braces follow the pattern element that is to be repeated and specify the number of times it repeats. In addition, some special characters are used to specify common types of repetition. Both the curly-brace syntax and the special repetition characters are shown in Table 9.8.
|
|
Table 9.8: Syntax for Repeating Pattern Elements |
Repetition |
|
Meaning |
Syntax |
|
|
|
|
|
{n,m} |
|
Match the preceding element at least n times but no more than m times. |
|
|
|
{n,} |
|
Match the preceding element n or more times. |
|
|
|
{n} |
|
Match the preceding element exactly n times. |
?Match the preceding element zero or one timesin other words, the element is optional; equivalent to {0,1}.
+
 Match one or more occurrences of the preceding element; equivalent to {1,}.
Match one or more occurrences of the preceding element; equivalent to {1,}.
*Match zero or more occurrences of the preceding elementin other words, the element is optional, but can also appear multiple times; equivalent to {0,}.
As we've already seen, to match a number with one to three digits, you can use the regular expression \d{1,3}. Another example is that you can match a word surrounded by space characters by creating a pattern that sandwiches the word between \s+ sequences. For example,
\s+love\s+
matches 'I love you!' but not 'Iloveyou!'.
Organizing Patterns
Regular expression syntax provides special characters that allow you to organize patterns. These characters are shown in Table 9.9 and discussed below.
|
|
Table 9.9: Alternation, Grouping, and Reference Characters |
|
|
|
Character |
|
Meaning |
|
|
|
| |
|
Alternation. Matches the character or subexpression to the left or right of the | |
|
|
character. |
|
|
|
(...) |
|
Grouping. Groups several items into a unit, or subexpression, that can be used |
|
|
with repeated syntax and referred to later in an expression. |
|
|
|
\n |
|
Referenced subexpression match. Matches the same characters that were matched |
|
|
when the subexpression \n was first matched. |
|
|
|
Alternation
The pipe character (|) is used to indicate an alternative. For example, the regular expression jaws|that|bite matches the three strings jaws, that, or bite. In another example, \d{2}|[A-Z]{4} matches either two digits or four capital letters.
Grouping
Parentheses are used to group elements in a regular expression. Once items have been grouped into subexpressions, they can be treated as a single element using repetition syntax. For example, chocolate(donut)? matches chocolate with or without the optional donut.
Referring to Subexpressions
Parentheses are also used to refer back to a subexpression that is part of a regular expression. Each subexpression that has been grouped in parentheses is internally assigned an identification number. The subexpressions are numbered from left to right, using the position of the left parenthesis to determine order. Nesting of subexpressions is allowed.
Subexpressions are referred to using a backslash followed by a number. So \1 means the first subexpression, \2 the second, and so on.
A reference to a subexpression matches the same characters that were originally matched by the subexpression. For example, the regular expression
['"][^'"]*['"]
matches a string that starts with a single or double quote and ends with a single or double quote. (The middle element, [^'"]*, matches any number of characters, provided they are not single or double quotes.)
However, this expression doesn't distinguish between the two kinds of quotes. A comparison string that started with a double quote and ended with a single quote would match this expression. For example, the string
"We called him Tortoise because he taught us'
which starts with a double quote and ends with a single quote, matches the regular expression pattern.
A better result would be to have a match depend on which kind of quote the match began with. If it begins with a double quote, it should end with a double quote; likewise, if it starts with a single quote, it should end with a single quote.
This can be accomplished by referring to the earlier subexpression so that the same kind of quote that the string starts with is required for a match. Here's the regular expression pattern to accomplish this:
(['"])[^'"]*\1
As you'll see if you try running this in the test bed program, it matches 'CSharp' but not
'CSharp'.
Specifying a Position for a Match
Finally, you should know about the regular expression characters that are used to specify a match position. These characters, shown in Table 9.10, do not match characters; rather, they match boundaries, typically the beginning or end of a word or a string.
|
|
Table 9.10: Regular Expression Position-Matching Characters |
|
|
|
Character |
|
Matching Position |
|
|
|
^ |
|
The beginning of a string; in multiline searches, the beginning of a line. |
|
|
|
$ |
|
The end of a string; in multiline searches, the end of a line. |
|
|
|
\b |
|
A word boundary. In other words, it matches the position between a \w character |
|
|
and a \W character. Also see the note about \b in the "Literal Characters" section |
|
|
of this chapter. |
|
|
|
\B |
|
Not a word boundary. |
|
|
|
You'll find that many regular expressions use positioning characters. It's easier to get a sense of how to use them in the context of actual tasks. Here are two examples of regular expressions that match positions.
To match a word, you can use the regular expression
\b[A-Za-z'-]+\b
Note You have to think carefully about what exactly a 'word' is and what you need to accomplish in a given programming context. This regular expression defines a word to include apostrophes and hyphens but not digits or underscores (so 85th would fail the match).

To match a string by itself on a line, start the regular expression with a caret (^) and end with a dollar sign. For example, the regular expression
^Prospero$
matches the string Prospero if it is alone on a line, but not if any other characters (even spaces) are on the line.
Regular Expression Examples
The full power of regular expressions becomes apparent when you start to use their patternmatching abilities in combination with string and regular expression class methods in your programs.
But regular expressions can do a lot for you more or less on their own. So I'll start by showing you a few somewhat complicated regular expression patterns that may be useful-and that you can use to test your understanding of the syntax of regular expressions.
Pattern Matches
To match a date in mm/dd/yyyy format, use the pattern:
\b(\d{2})\/(\d{2})\/(\d{4})\b
To match a number in Roman notation, use the pattern:
(?i:^m*(d?c{0,3}|c[dm])(l?x{0,3}|x[lc])(v?i{0,3}|i[vx])$)
MDCCLXXVI, or 1776, is shown matching this pattern in Figure 9.13.
Figure 9.13: The regular expression shown here matches a Roman number.
Note Note that the pattern used in the Roman number example includes the i (caseinsensitivity) attribute. As explained earlier in this chapter, this could have been accomplished using the RegexOptions enumeration and the Regex constructor rather than as part of the pattern string.