

5.2. Прогнозирование экономических показателей с помощью кривых роста
При прогнозировании экономических показателей с помощью кривых роста необходимо выполнить следующие действия:
1) выбрать одну или несколько кривых, форма которых соответствует характеру изменения выбранного ряда (см. п. 2.2.2);
2) оценить параметры выбранных кривых (см. п. 2.2.2);
3) окончательно выбрать кривую роста и осуществить проверку адекватности выбранной кривой исследуемому процессу;
4) произвести расчет точечного и интервального прогнозов.
Проверка адекватности выбранных моделей реальному процессу строится на анализе случайной компоненты. Принято считать, что модель адекватна описываемому процессу, если значения остаточной компоненты εt удовлетворяют свойствам случайности, независимости, нормальности (см. п. 3.1 — 3.3). Если случайная компонента удовлетворяет этим свойствам, то выбранную кривую роста можно использовать для определения прогноза. В то же время применение кривых роста для прогнозирования должно базироваться на предположении о неизменности, сохранении тенденции как на всем периоде наблюдений, так и в прогнозируемом периоде [22]. Если есть основания принять эти допущения, то можно найти прогнозные значения путем подстановки в уравнение кривой значений времени t, соответствующих периоду упреждения. Полученный таким образом прогноз называют точечным. Но, как правило, при прогнозировании экономических показателей „попадание в точку" маловероятно, и поэтому прогноз должен быть определен в виде интервала значений.
Несовпадение фактических данных с точечным прогнозом, полученным путем экстраполяции, может быть вызвано: 1) ошибочностью выбора кривой; 2) погрешностью оценивания параметров кривой; 3) погрешностью, связанной с отклонениями отдельных наблюдений от тренда.
Погрешность, связанная со вторым и третьим источником, может быть отражена в виде доверительного интервала прогноза, который в общем виде определяется как
![]() ,
,
где
![]() — точечный прогноз на периодl;
— точечный прогноз на периодl;
tα — значение t-статистики Стьюдента;
Sp — средняя квадратическая ошибка прогноза.
Принимая во внимание, что параметры ai являются выборочными оценками, для линейного тренда доверительный интервал можно представить в виде
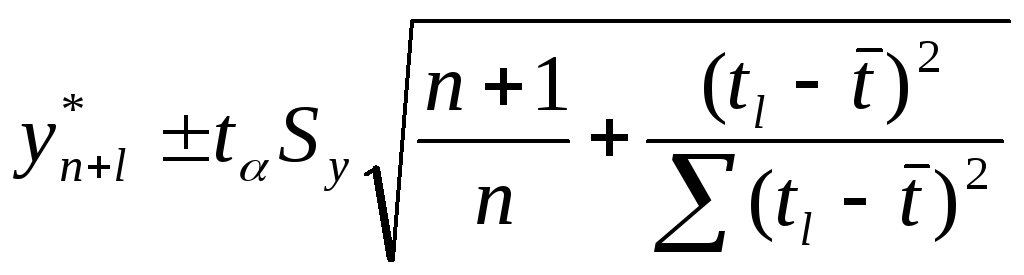 (5.4)
(5.4)
где Sy
— среднее квадратическое отклонение
фактических данных от расчетных,
![]() ,аk
— число оцениваемых параметров
выравнивающей кривой;
,аk
— число оцениваемых параметров
выравнивающей кривой;
tl —- время упреждения, для которого делается экстраполяция, tl = n + l;
t — порядковый номер уровня ряда;
![]() —-
порядковый номер уровня, стоящего в
середине ряда,
—-
порядковый номер уровня, стоящего в
середине ряда,
![]() .
.
Обозначив корень
в выражении (5.4) через К, можно определить
доверительный интервал индивидуальных
значений уi
следующим образом:
![]() ,
где
,
где![]() .
.
Для полинома 2-й степени доверительный интервал можно представить в виде
 ,
(5.5)
,
(5.5)
или
![]()
Доверительные интервалы прогнозов, полученных с использованием уравнений экспонент, определяют следующим выражением:
![]() ,
,
где К* — значения, рассчитанные для прямой (или параболы).
В табл. 3 (прил. 1) приведены значения К* в зависимости от длины n и периода упреждения l для прямой и параболы. Очевидно, что при увеличении длины ряда значения К* уменьшаются, с ростом периода упреждения l значения К* увеличиваются. При этом чем больше длина ряда, тем меньшее влияние оказывает период упреждения l.
Основными характеристиками качества модели, наряду с проверкой модели на адекватность процессу, являются показатели точности. Наиболее распространенным способом проверки точности прогноза является ретроспективный прогноз, т. е. когда рассчитывается прогноз для прошедшего периода времени и полученные результаты сравниваются с фактической динамикой. Чаще всего такое сравнение проводится по величине средней квадратической ошибки (2.11) или средней ошибки аппроксимации
![]() ,
(5.6)
,
(5.6)
где yt — фактические значения ряда;
![]() —теоретические
значения, полученные по выбранной
модели.
—теоретические
значения, полученные по выбранной
модели.
Чем меньше значения этих характеристик, тем выше считается точность прогноза. Очевидно, что все эти характеристики могут быть вычислены после того, когда период упреждения уже кончится и будут иметься фактические данные о прогнозируемом показателе или же когда по первой части ряда строится модель прогноза, а данные второй части ряда используются для проверки точности построенной модели (т. е. рассматривается ретроспективный прогноз). Но о точности модели нельзя судить только по одному значению ошибки прогноза. Надо учитывать, что единичный „хороший” прогноз может быть получен и по „плохой" модели, т. е. о качестве применяемых моделей можно судить лишь по совокупности сопоставлений прогнозных значений с фактическими.
Простой мерой качества прогнозов может стать относительное число случаев, когда фактическое значение охватывается интервальным прогнозом
![]() ,
,
где р — число прогнозов, подтвержденных фактическими данными;
q — число прогнозов, не подтвержденных фактическими данными.
Чем ближе значение µ к единице, тем надежнее считается модель. Сопоставление коэффициентов µ для разных моделей может иметь смысл только при условии, что доверительные вероятности приняты одинаковыми для всех моделей.
П р и м е р 5.3. При правильном выборе вида тренда отклонения от него должны носить случайный характер. Для проверки этого предположения можно использовать критерии серий (п. 2.1). Остатки et признаются случайными, если выполняются неравенства (2.2) для критерия серий, основанного на медиане выборки, или неравенства (2.1) для критерия „восходящих” и „нисходящих” серий. Расчеты для ряда остатков еt (см. пример 2.3) доказали, что они могут быть признаны случайными и выбор вида тренда был произведен правильно. Если предположить, что для ряда остатков выполняются условия независимости и нормальности, то при построении точечных и интервальных прогнозов можно использовать полученное уравнение параболы
![]() .
.
Точечный прогноз для t = 25 будет равен:
![]() .
.
На практике результат экстраполяции прогнозируемых уровней социально-экономических явлений обычно выполняется не точечным, а интервальным прогнозом (5.3).
В нашем примере
![]() ;
;
![]() ;
;
![]() ;
;
![]()
Тогда нижняя граница прогноза составит:
![]() ,
,
а верхняя граница прогноза —
![]() .
.
Таким образом, с вероятностью в 95 % прогноз на IV квартал находится в интервале
![]() .
.
Аналогичные расчеты выполняются и для последующих периодов прогноза.