

Информатика. Учебники. Современные компьютерные технологии
.pdfРис. 3
7.Установим курсор в ячейку В4 и выполним команду меню Встав-
ка ? Функция. В открывшемся окне Мастер функций выберем ка-
тегорию Статистические и в списке функций – НОРМРАСП.
8.Установим значения параметров функции НОРМРАСП: для па-
раметра х установим ссылку на ячейку А4, для параметра Сред-
нее – введем число 24,3, для параметра Стандартное_отклон -
число 1,5, для параметра Интегральное – число 0 (весовая).
9.Используя маркер буксировки, скопируем полученную формулу
вдиапазон ячеек В5:D22.
10.Выделим диапазон полученных табличных значений функции f(x) (В3:B22) и выполним команду меню Вставка / Диаграмма.
11.В окне Мастер диаграмм во вкладке Стандартные выберем Гра-
фик, а в окне Вид – вид графика, щелкнем на кнопке Далее.
12.В окне Мастер диаграмм (шаг 2) выберем закладку Ряд. В поле Подписи оси х укажем ссылку на диапазон, содержащий значе-
ния х (А3:А22). Щелкнем на кнопке Далее.
13.В окне Мастер диаграмм (шаг 3) введем подписи: Название диа-
граммы, Ось х, Ось y. Щелкнем на кнопке Готово. На рабочий лист будет выведена диаграмма плотности вероятности (Рис. 2).
6.5. Построение рядов в правовой статистике
151
Составная часть сводной обработки данных статистического наблюде-
ния (например, статистических карточек на подсудимых) — построение ря-
дов распределения по какому-либо признаку на группы (скажем, по тяжести совершенного преступления или числу судимостей) с указанием числа еди-
ниц, входящих в каждую такую группу (например, распределение числа под-
судимых на две группы — ранее судимых и несудимых).
Отсюда статистический ряд распределения — упорядоченное распре-
деление единиц совокупности на группы по определенному варьирующему признаку.
Цель построения рядов распределения — выявление основных свойств и закономерностей исследуемой статистической совокупности. Ряды распре-
деления упрощают определенные вычисления и дают наглядную картину ис-
следуемых наблюдений.
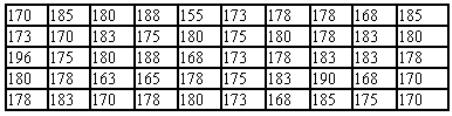
В качестве иллюстрации можно привести результаты измерения роста
50 студентов университета (табл. 1). Каждое индивидуальное измерение представлено в таблице отдельно, поэтому такие данные называют не сгруп-
пированными.
Таблица 1
Результаты измерения с точностью до 2 см роста 50 студентов
(не сгруппированные данные)
В противоположность данным, приведенным в таблице 1, значения, об-
разующие ряд распределения, называют сгруппированными. Таблица 2 пред-
ставляет собой ряд распределения измерений, содержащихся в табл. 1.
Таблица 2 Ряд распределения измерений с точностью до 2 см роста 50 студен-
тов (сгруппированные данные)
152

В зависимости от признака, положенного в основу образования ряда распределения, различают атрибутивные и вариационные ряды распределе-
ния.
Атрибутивным называют ряд распределения, построенный по качест-
венным признакам.
Примером атрибутивных рядов может служить распределение осуж-
денных по полу, занятиям, принадлежности к той или иной социальной груп-
пе, виду преступлений, форме их вины и т.д. Построение этих рядов относи-
тельно просто. В результате распределения образуется столько групп, сколь-
ко разновидностей атрибутивного признака имеет данная совокупность. Ряд распределения принято оформлять в виде таблиц. Ниже в таблице 3 приведен в качестве примера атрибутивный ряд распределения уличной преступности.
Таблица 3 Атрибутивный ряд распределения уличной преступности
Атрибутивные ряды распределения характеризуют состав совокупно-
сти по тем или иным существенным признакам. Взятые за несколько перио-
дов, эти данные позволяют исследовать изменение структуры явления.
153

Вариационный ряд показывает изменение (варьирование) количествен-
ного признака у какого-либо явления, например возраста у правонарушите-
лей, сроков расследования уголовных дел, сроков лишения свободы, размер материального ущерба, количество человеческих жертв от дорожно-
транспортных происшествий или пожаров и т.д.
Любой вариационный ряд состоит из двух элементов: вариантов и час-
тот.
Вариантами считаются отдельные значения признака, которые он при-
нимает в вариационном ряду, т.е. конкретное значение варьирующего при-
знака (например, варианты возраста — 14, 16, 18 и т.д.).
Частоты — это численности отдельных вариантов или каждой группы вариационного ряда, т.е. числа, показывающие, как ча-сто встречаются те или иные варианты в ряду распределения. Сумма всех частот определяет численность всей совокупности, ее объем. Частоты, выраженные в долях единицы или в процентах к итогу, называются частостями. Соответственно сумма частостей равна 1 или 100%.
В зависимости от характера вариации ряды подразделяются на два ви-
да: дискретные (прерывные) и интервальные (непрерывные).
В случае дискретной вариации величина количественного признака принимает только целые значения. Следовательно, дискретный вариацион-
ный ряд характеризует распределение единиц совокупности по дискретному признаку.
Примером дискретного вариационного ряда является распределение числа обвиняемых, приходящихся на одно уголовное дело (табл. 4).
Таблица 4. Распределение числа обвиняемых по одному уголовному делу
154
В первом ряду таблицы представлены варианты прерывного (дискрет-
ного) вариационного ряда, во втором — частоты вариационно-го ряда, а в третьем — частости. Ясно, что здесь не может быть 1,5 или 2,5 обвиняемого,
приходящегося на одно уголовное дело.
Построение интервальных вариационных рядов целесообразно прежде всего при непрерывной вариации признака, а также если дискретная вариа-
ция проявляется в широких пределах, т.е. число вариантов дискретного ряда достаточно велико.
Так, для исследования непрерывного варьирования всегда устанавли-
ваются интервалы (от — до). Интервал указывает определенные пределы значений варьирующего признака и обозначается нижней и верхней грани-
цами интервала. Такие распределения наиболее распространены в практике правовой статистики. Например, в аналитической практике следственных ап-
паратов сроки расследования уголовных дел разбивают на интервалы до 10
дней; от 10 до 30 дней; от 30 дней до двух месяцев включительно; свыше двух месяцев.
При построении интервальных рядов распределения необходимо преж-
де всего установить число групп (интервалов), на которые следует разбить все единицы изучаемой совокупности. Значение величины интервала позво-
ляет определить границы всех интервалов ряда распределения. Нижнюю гра-
ницу, первого интервала целесообразно принимать равной минимальному значению признака. В приведенном примере (табл. 5) шесть месяцев — ми-
нимальный срок лишения свободы (ст. 56 УК РФ).
При построении интервальных рядов для непрерывных при-знаков имеет место совпадение верхних границ предшествующих интервалов и нижних границ следующих за ними интервалов1. Кроме того, весьма важно,
чтобы число наблюдений в интервале не было бы слишком малым, а соответ-
ственно число групп слишком большим.
155
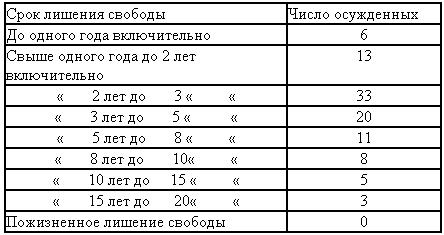
Предположим, имеется 100 карточек на осужденных к различным сро-
кам лишения свободы. Чтобы получить представление об изменении (варьи-
ровании) этих сроков, а вместе с тем о карательной практике судов, мы сгруппируем сроки лишения свободы по интервалам, установленным в ста-
тистической отчетности.
Таблица 5. Распределение числа осужденных по срокам лишения свободы
6.6.Технологии построения рядов распределения
В табличном процессоре для построения рядов распределения (иногда называют выборочной функцией распределения) используется специальная функция ЧАСТОТА или инструмент пакета анализа Гистограмма.
Функция ЧАСТОТА вычисляет частоты появления случайных величин в интервалах значений и выводит их как массив чисел. Функция имеет пара-
метры:
ЧАСТОТА(массив_данных; массив_интервалов), где:
 массив_данных – массив или ссылка на диапазон данных, для ко-
массив_данных – массив или ссылка на диапазон данных, для ко-
торых вычисляются частоты;
 массив_интервалов – массив или ссылка на множество интерва-
массив_интервалов – массив или ссылка на множество интерва-
лов, в которые группируются значения аргумента мас-
сив_данных.
Количество элементов в возвращаемом массиве на единицу больше,
чем в задано в параметре массив_интервалов. Дополнительный элемент со-
156
держит количество значений больших, чем максимальное значение в интер-
валах.
Инструмент Гистограмма служит для вычисления выборочных и инте-
гральных частот попадания данных в указанные интервалы значений. Вы-
ходным результатом является таблица и гистограмма.
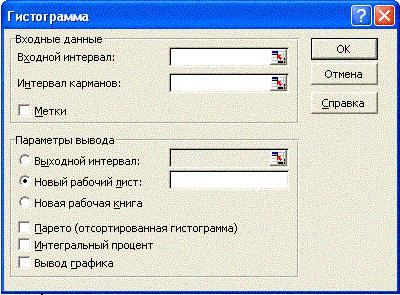
Чтобы включить инструмент Гистограмма следует выполнить команду меню Сервис - Анализ данных, и далее в раскрывшемся диалоговом окне Анализ данных из списка выбрать Гистограмма – откроется диалоговое окно Гистограмма. Вид диалогового окна Гистограмма приведен на рис. 4.
Рис. 4
Диалоговое окно имеет следующие поля:
 Входной диапазон – поле, предназначенное указания адресной ссылки на диапазон, содержащий исследуемые данные;
Входной диапазон – поле, предназначенное указания адресной ссылки на диапазон, содержащий исследуемые данные;
 Интервал карманов – поле, в котором может быть указана ссылка на диапазон ячеек, содержащий выбранные интервалы, в которые группируются значения аргумента Входной интервал;
Интервал карманов – поле, в котором может быть указана ссылка на диапазон ячеек, содержащий выбранные интервалы, в которые группируются значения аргумента Входной интервал;
 поле Выходной диапазон предназначено для ввода адресной ссылки на верхнюю левую ячейку выходного диапазона;
поле Выходной диапазон предназначено для ввода адресной ссылки на верхнюю левую ячейку выходного диапазона;
157

 флажок Интегральный процент устанавливает режим генерации интегральных процентных соотношений и включает в гисто-
флажок Интегральный процент устанавливает режим генерации интегральных процентных соотношений и включает в гисто-
грамму график интегральных процентов;
 флажок Вывод графика устанавливает режим автоматического вывода графика на рабочий лист, содержащий входной диапазон.
флажок Вывод графика устанавливает режим автоматического вывода графика на рабочий лист, содержащий входной диапазон.
Упражнение 4
Построить ряд распределения рейтинга студентов по результатам экза-
менов, оцененных в баллах для следующей произвольной выборки: 48, 51,
64, 62, 55, 71, 74, 79, 80, 86, 91, 99, 83, 50. Задачу решить двумя способами: с
применением функции ЧАСТОТА, с применением инструмента Гистограмма пакета анализа
Решение с применением функции ЧАСТОТА
 В ячейку А2 рабочего листа введем текст ―Наблюдения‖, а в диа-
В ячейку А2 рабочего листа введем текст ―Наблюдения‖, а в диа-
пазон А3:А16 – числа из заданной выборки (рис.5).
Рис. 5
158
 В ячейке В2 запишем текст ―Шкала баллов‖, а в ячейки диапазо-
В ячейке В2 запишем текст ―Шкала баллов‖, а в ячейки диапазо-
на В3:В6 – баллы, соответствующие шкале для вывода пяти-
балльной оценки – 50, 70, 85, 100. Это означает, что баллы диапа-
зона 1 – 50 эквивалентны оценке ―неудовлетворительно‖, баллы,
находящиеся в диапазоне 51 – 70 – оценке ―удовлетворительно‖ и
т.д.
 В ячейки С2, D2 и E2 введем тексты ―Абсолютные частоты‖, ―Относительные частоты‖ и ―Накопленные частоты‖ соответст-
В ячейки С2, D2 и E2 введем тексты ―Абсолютные частоты‖, ―Относительные частоты‖ и ―Накопленные частоты‖ соответст-
венно. Абсолютные частоты – это частота попадания случайной величины из выборки (количество попаданий) в соответствую-
щий интервал. Относительная частота представляет собой част-
ное от деления значения абсолютной частоты на количество эле-
ментов выборки. Накопленные частоты – это сумма относитель-
ных частот.
 Выделим диапазон С3:С7 и выполним команду меню Вставка -
Выделим диапазон С3:С7 и выполним команду меню Вставка -
Функция. В открывшемся окне диалога Мастер функций выберем категорию Статистические, а в списке функций – функцию ЧАС-
ТОТА. Раскроется диалоговое окно функции ЧАСТОТА.
Установим параметры функции:
 массив_данных – установим ссылку на диапазон, содержащий выборку случайных величин (А3:А16);
массив_данных – установим ссылку на диапазон, содержащий выборку случайных величин (А3:А16);
 массив_интервалов – установим ссылку на диапазон, содер-
массив_интервалов – установим ссылку на диапазон, содер-
жащий шкалу для вывода оценки (В3:В6).
 Так как функция ЧАСТОТА возвращает результат в диапазон в виде массива значений, нажмем комбинацию клавиш <Ctrl> + <Shift> + <Enter>. В ячейки диапазона С3:C7 будет выведен ре-
Так как функция ЧАСТОТА возвращает результат в диапазон в виде массива значений, нажмем комбинацию клавиш <Ctrl> + <Shift> + <Enter>. В ячейки диапазона С3:C7 будет выведен ре-
зультат – абсолютные частоты попадания случайных величин в интервалы, заданные в ячейках диапазона В3:B6.
159
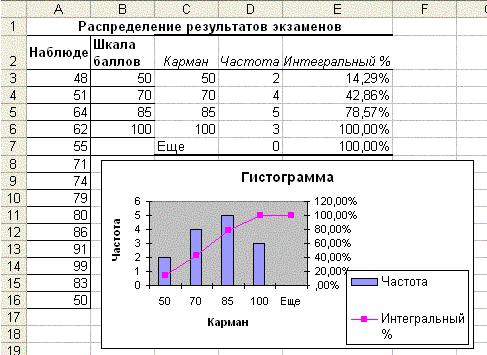
Таким образом, в результате проведенного исследования получены ста-
тистические оценки абсолютных частот по случайной выборке: неудовлетво-
рительно – 2, удовлетворительно – 4, хорошо – 5, отлично – 3.
Решение с применением инструмента Гистограмма
 В ячейку А2 рабочего листа введем текст ―Наблюдения‖, а в диа-
В ячейку А2 рабочего листа введем текст ―Наблюдения‖, а в диа-
пазон А3:А16 – числа из заданной выборки (рис.6).
Рис. 6
 В ячейке В2 запишем текст ―Шкала баллов‖, а в ячейки диапазо-
В ячейке В2 запишем текст ―Шкала баллов‖, а в ячейки диапазо-
на В3:В6 – баллы, соответствующие шкале для вывода пяти-
балльной оценки.
 Выполним команду меню Сервис - Анализ данных – откроется диалоговое окно Анализ данных.
Выполним команду меню Сервис - Анализ данных – откроется диалоговое окно Анализ данных.
 В окне диалога Анализ данных выберем из списка Гистограмма –
В окне диалога Анализ данных выберем из списка Гистограмма –
откроется диалоговое окно Гистограмма.
 Введем параметры в соответствующие поля диалогового окна
Введем параметры в соответствующие поля диалогового окна
Гистограмма:
160